sinkhorn transformer
0.11.4
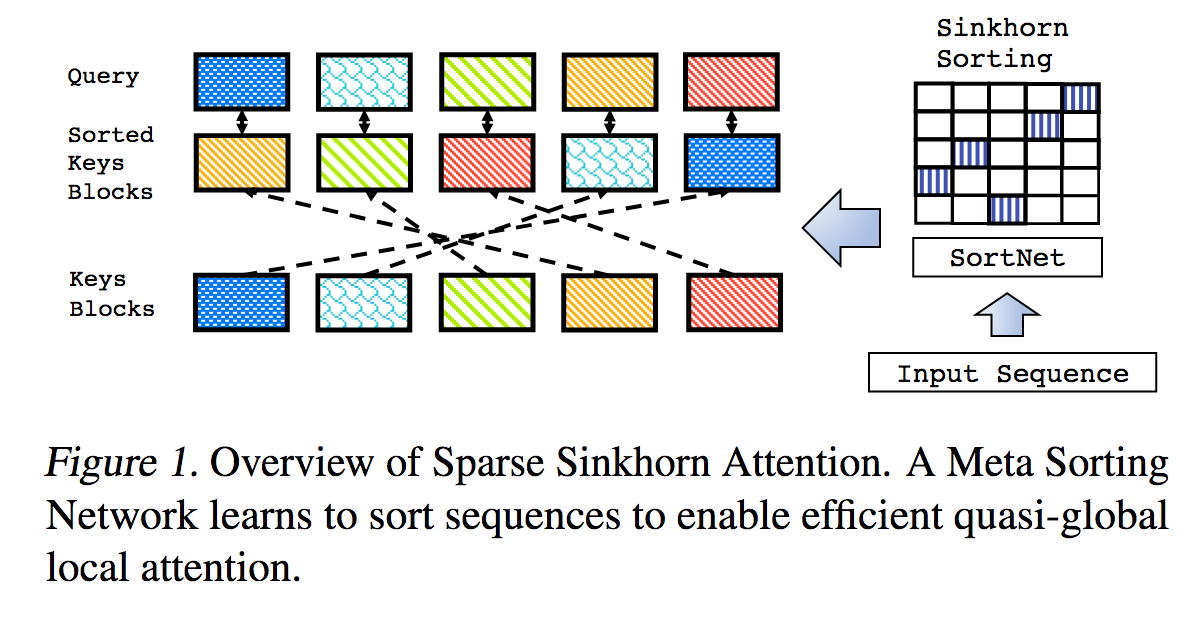
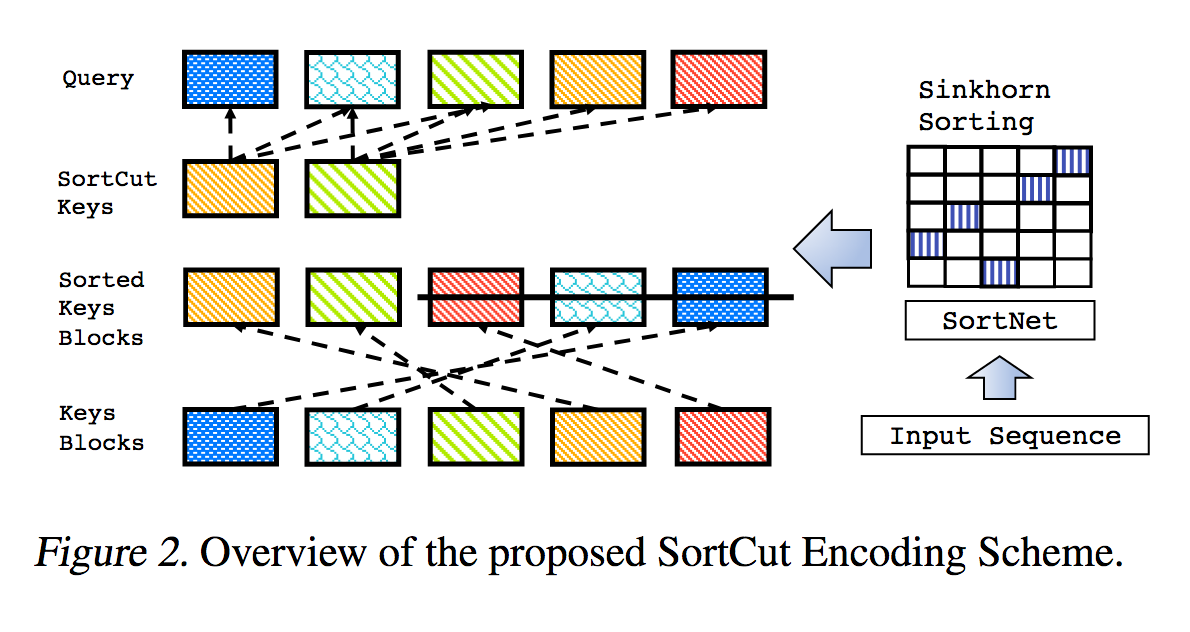
นี่เป็นการทำซ้ำผลงานที่ระบุไว้ใน Sparse Sinkhorn Attention พร้อมการปรับปรุงเพิ่มเติม
ประกอบด้วยเครือข่ายการเรียงลำดับแบบกำหนดพารามิเตอร์ โดยใช้การทำให้เป็นมาตรฐานแบบซิงก์ฮอร์นเพื่อสุ่มตัวอย่างเมทริกซ์การเรียงสับเปลี่ยนที่ตรงกับกลุ่มคีย์ที่เกี่ยวข้องมากที่สุดกับกลุ่มข้อความค้นหา
งานนี้ยังนำเครือข่ายแบบพลิกกลับได้และฟีดไปข้างหน้าเป็นก้อน (แนวคิดที่แนะนำจาก Reformer) เพื่อนำมาซึ่งการประหยัดหน่วยความจำเพิ่มเติม
โทเค็น 204,000 อัน (เพื่อการสาธิต)
$ pip install sinkhorn_transformerโมเดลภาษาที่ใช้ Sinkhorn Transformer
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
bucket_size = 128 , # size of the buckets
causal = False , # auto-regressive or not
n_sortcut = 2 , # use sortcut to reduce memory complexity to linear
n_top_buckets = 2 , # sort specified number of key/value buckets to one query bucket. paper is at 1, defaults to 2
ff_chunks = 10 , # feedforward chunking, from Reformer paper
reversible = True , # make network reversible, from Reformer paper
emb_dropout = 0.1 , # embedding dropout
ff_dropout = 0.1 , # feedforward dropout
attn_dropout = 0.1 , # post attention dropout
attn_layer_dropout = 0.1 , # post attention layer dropout
layer_dropout = 0.1 , # add layer dropout, from 'Reducing Transformer Depth on Demand' paper
weight_tie = True , # tie layer parameters, from Albert paper
emb_dim = 128 , # embedding factorization, from Albert paper
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
ff_glu = True , # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
n_local_attn_heads = 2 , # replace N heads with local attention, suggested to work well from Routing Transformer paper
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
)
x = torch . randint ( 0 , 20000 , ( 1 , 2048 ))
model ( x ) # (1, 2048, 20000)Transformer Sinkhorn ธรรมดา ชั้นของ sinkhorn ความสนใจ
import torch
from sinkhorn_transformer import SinkhornTransformer
model = SinkhornTransformer (
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128
)
x = torch . randn ( 1 , 2048 , 1024 )
model ( x ) # (1, 2048, 1024)Sinkhorn Encoder / หม้อแปลงถอดรหัส
import torch
from sinkhorn_transformer import SinkhornTransformerLM
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
enc = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
heads = 8 ,
bucket_size = 128 ,
max_seq_len = DE_SEQ_LEN ,
reversible = True ,
return_embeddings = True
). cuda ()
dec = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
causal = True ,
bucket_size = 128 ,
max_seq_len = EN_SEQ_LEN ,
receives_context = True ,
context_bucket_size = 128 , # context key / values can be bucketed differently
reversible = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). cuda ()
y = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). cuda ()
x_mask = torch . ones_like ( x ). bool (). cuda ()
y_mask = torch . ones_like ( y ). bool (). cuda ()
context = enc ( x , input_mask = x_mask )
dec ( y , context = context , input_mask = y_mask , context_mask = x_mask ) # (1, 4096, 20000) ตามค่าเริ่มต้น โมเดลจะบ่นหากได้รับอินพุตที่ไม่ใช่ขนาดบัคเก็ตหลายเท่า เพื่อหลีกเลี่ยงไม่ให้ต้องคำนวณช่องว่างภายในเดียวกันในแต่ละครั้ง คุณสามารถใช้คลาสตัวช่วย Autopadder มันจะดูแล input_mask ให้คุณเช่นกันหากได้รับ รองรับคีย์/ค่าตามบริบทและมาสก์ด้วยเช่นกัน
import torch
from sinkhorn_transformer import SinkhornTransformerLM
from sinkhorn_transformer import Autopadder
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 2048 ,
bucket_size = 128 ,
causal = True
)
model = Autopadder ( model , pad_left = True ) # autopadder will fetch the bucket size and autopad input
x = torch . randint ( 0 , 20000 , ( 1 , 1117 )) # odd sequence length
model ( x ) # (1, 1117, 20000) พื้นที่เก็บข้อมูลนี้แยกออกจากกระดาษ และขณะนี้กำลังใช้ความสนใจแทนตาข่ายคัดแยกแบบเดิม + การสุ่มตัวอย่างแบบกัมเบลซิงฮอร์น ฉันยังไม่พบความแตกต่างที่เห็นได้ชัดเจนในด้านประสิทธิภาพ และรูปแบบใหม่ช่วยให้ฉันสามารถสรุปเครือข่ายให้มีความยาวลำดับที่ยืดหยุ่นได้ หากคุณต้องการลองใช้ Sinkhorn โปรดใช้การตั้งค่าต่อไปนี้ ซึ่งจะใช้ได้กับเครือข่ายที่ไม่ใช่สาเหตุเท่านั้น
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128 ,
max_seq_len = 8192 ,
use_simple_sort_net = True , # turn off attention sort net
sinkhorn_iter = 7 , # number of sinkhorn iterations - default is set at reported best in paper
n_sortcut = 2 , # use sortcut to reduce complexity to linear time
temperature = 0.75 , # gumbel temperature - default is set at reported best in paper
non_permutative = False , # allow buckets of keys to be sorted to queries more than once
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
model ( x ) # (1, 8192, 20000) หากต้องการดูประโยชน์ของการใช้ PKM ต้องตั้งค่าอัตราการเรียนรู้ของค่าให้สูงกว่าพารามิเตอร์ที่เหลือ (แนะนำเป็น 1e-2 )
คุณสามารถทำตามคำแนะนำที่นี่เพื่อตั้งค่าอย่างถูกต้อง https://github.com/lucidrains/product-key-memory#learning-rates
Sinkhorn เมื่อได้รับการฝึกฝนเกี่ยวกับลำดับความยาวคงที่ ดูเหมือนว่าจะมีปัญหาในการถอดรหัสลำดับตั้งแต่เริ่มต้น สาเหตุหลักมาจากความจริงที่ว่าตาข่ายคัดแยกมีปัญหาในการสรุปเมื่อที่ฝากข้อมูลเต็มไปด้วยโทเค็นการเสริมบางส่วน
โชคดีที่ฉันคิดว่าฉันพบวิธีแก้ปัญหาง่ายๆ แล้ว ในระหว่างการฝึก สำหรับเครือข่ายเชิงสาเหตุ ให้สุ่มตัดลำดับและบังคับให้เครือข่ายการเรียงลำดับสรุป ฉันได้จัดเตรียมแฟล็ก ( randomly_truncate_sequence ) สำหรับอินสแตนซ์ AutoregressiveWrapper เพื่อให้ง่ายขึ้น
import torch
from sinkhorn_transformer import SinkhornTransformerLM , AutoregressiveWrapper
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 75 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000)ฉันเปิดรับข้อเสนอแนะหากมีคนพบวิธีแก้ปัญหาที่ดีกว่า
มีปัญหาที่อาจเกิดขึ้นกับเครือข่ายการเรียงลำดับสาเหตุ ซึ่งการตัดสินใจว่าจะเก็บคีย์/ค่าใดของการเรียงลำดับในอดีตไปยังที่เก็บข้อมูลจะขึ้นอยู่กับโทเค็นแรกเท่านั้น ไม่ใช่ส่วนที่เหลือ (เนื่องจากรูปแบบการเก็บข้อมูลและป้องกันการรั่วไหลของอนาคต อดีต).
ฉันได้พยายามที่จะบรรเทาปัญหานี้โดยหมุนครึ่งหัวไปทางซ้ายตามขนาดที่เก็บข้อมูล - 1 ดังนั้นจึงเลื่อนโทเค็นสุดท้ายให้เป็นโทเค็นแรก นี่เป็นเหตุผลว่าทำไม AutoregressiveWrapper จึงมีค่าเริ่มต้นที่การเติมด้านซ้ายระหว่างการฝึก เพื่อให้แน่ใจว่าโทเค็นสุดท้ายในลำดับจะมีสิทธิ์เลือกว่าจะดึงข้อมูลอะไร
หากใครพบวิธีแก้ปัญหาที่สะอาดกว่า โปรดแจ้งให้เราทราบในปัญหา
@misc { tay2020sparse ,
title = { Sparse Sinkhorn Attention } ,
author = { Yi Tay and Dara Bahri and Liu Yang and Donald Metzler and Da-Cheng Juan } ,
year = { 2020 } ,
url. = { https://arxiv.org/abs/2002.11296 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=B1gjs6EtDr }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
}


