LongNet
0.4.8

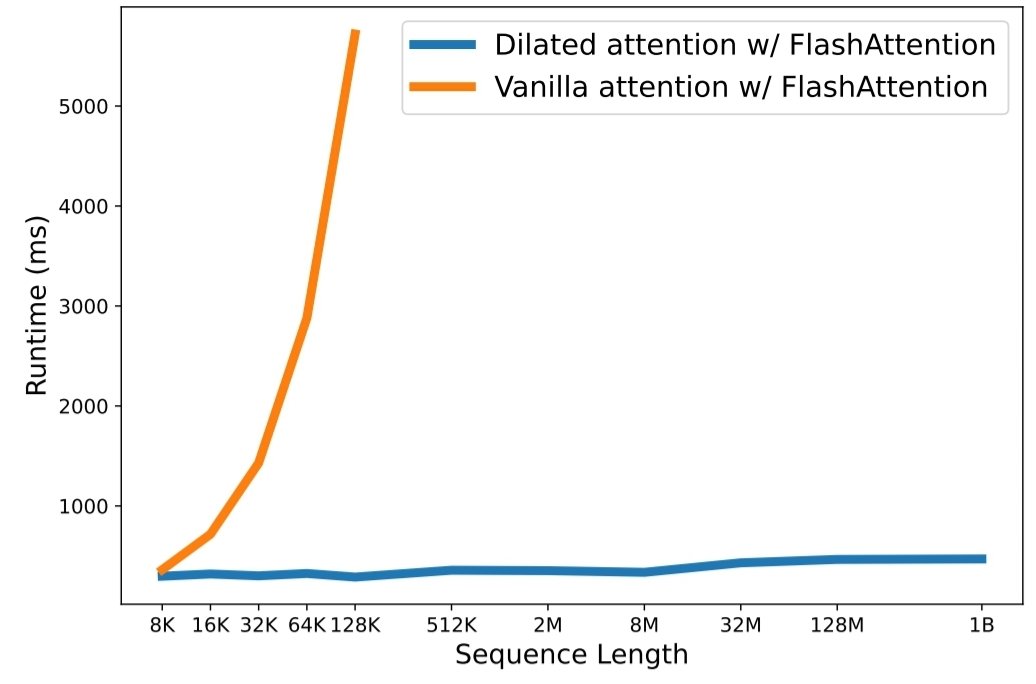
นี่เป็นการใช้งานโอเพ่นซอร์สสำหรับบทความ LongNet: Scaling Transformers to 1,000,000,000 Tokens โดย Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei LongNet เป็นรุ่น Transformer ที่ออกแบบมาเพื่อปรับขนาดความยาวของลำดับได้สูงสุดถึงมากกว่า 1 พันล้านโทเค็น โดยไม่กระทบต่อประสิทธิภาพในลำดับที่สั้นกว่า
pip install longnet เมื่อคุณติดตั้ง LongNet แล้ว คุณสามารถใช้คลาส DilatedAttention ได้ดังนี้:
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerโมเดลหม้อแปลงที่พร้อมสำหรับการฝึกเต็มรูปแบบด้วยบล็อกหม้อแปลงแบบขยายพร้อม Feedforwards พร้อม layernorm, SWIGLU และบล็อกหม้อแปลงแบบขนาน
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
python3 train.py ความยาวของลำดับการปรับขนาดกลายเป็นปัญหาคอขวดที่สำคัญในยุคของโมเดลภาษาขนาดใหญ่ อย่างไรก็ตาม วิธีการที่มีอยู่ต่อสู้กับความซับซ้อนในการคำนวณหรือการแสดงออกของโมเดล ทำให้ความยาวลำดับสูงสุดถูกจำกัด ในบทความนี้ พวกเขาแนะนำ LongNet ซึ่งเป็นตัวแปร Transformer ที่สามารถปรับขนาดความยาวของลำดับเป็นมากกว่า 1 พันล้านโทเค็น โดยไม่กระทบต่อประสิทธิภาพของลำดับที่สั้นกว่า โดยเฉพาะอย่างยิ่ง พวกเขาเสนอความสนใจแบบขยาย ซึ่งจะขยายขอบเขตความสนใจแบบทวีคูณเมื่อระยะทางเพิ่มขึ้น
LongNet มีข้อได้เปรียบที่สำคัญ:
ผลการทดลองแสดงให้เห็นว่า LongNet ให้ประสิทธิภาพที่ดีเยี่ยมทั้งในด้านการสร้างแบบจำลองลำดับยาวและงานภาษาทั่วไป งานของพวกเขาเปิดโอกาสใหม่ๆ สำหรับการสร้างแบบจำลองลำดับที่ยาวมาก เช่น การปฏิบัติต่อคลังข้อมูลทั้งหมด หรือแม้แต่อินเทอร์เน็ตทั้งหมดเป็นลำดับ
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

