antialiased cnns
v0.3
การทำให้เครือข่าย Convolutional เปลี่ยนไปไม่แปรเปลี่ยนอีกครั้ง
ริชาร์ด จาง. ใน ICML, 2019.
รัน pip install antialiased-cnns
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True ) หากคุณมีโมเดลอยู่แล้วและต้องการลดรอยหยักและฝึกฝนต่อ ให้คัดลอกน้ำหนักเก่าของคุณไปที่:
import torchvision . models as models
old_model = models . resnet50 ( pretrained = True ) # old (aliased) model
antialiased_cnns . copy_params_buffers ( old_model , model ) # copy the weights overหากคุณต้องการแก้ไขโมเดลของคุณเอง ให้ใช้เลเยอร์ BlurPool ข้อมูลเพิ่มเติมเกี่ยวกับโมเดลที่เราให้ไว้และวิธีใช้ BlurPool อยู่ด้านล่าง
C = 10 # example feature channel size
blurpool = antialiased_cnns . BlurPool ( C , stride = 2 ) # BlurPool layer; use to downsample a feature map
ex_tens = torch . Tensor ( 1 , C , 128 , 128 )
print ( blurpool ( ex_tens ). shape ) # 1xCx64x64 tensorอัพเดท
pip install antialiased-cnns และโหลดโมเดลด้วยการตั้งค่าสถานะ pretrained=True แล้วBlurPoolPip ติดตั้งแพ็คเกจนี้
pip install antialiased-cnnsหรือโคลนพื้นที่เก็บข้อมูลนี้และติดตั้งข้อกำหนด (โดยเฉพาะ PyTorch)
https://github.com/adobe/antialiased-cnns.git
cd antialiased-cnns
pip install -r requirements.txtข้อมูลต่อไปนี้จะโหลดโมเดลลดรอยหยักที่ผ่านการฝึกอบรมมาแล้ว ซึ่งอาจใช้เป็นแกนหลักสำหรับแอปพลิเคชันของคุณ
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True , filter_size = 4 ) นอกจากนี้เรายังจัดเตรียมน้ำหนักสำหรับการลดรอยหยัก AlexNet , VGG16(bn) , Resnet18,34,50,101 , Densenet121 และ MobileNetv2 (ดู example_usage.py)
โมดูล antialiased_cnns มีคลาส BlurPool ซึ่งทำหน้าที่เบลอ+การสุ่มตัวอย่างย่อย เรียกใช้ pip install antialiased-cnns หรือคัดลอกไดเรกทอรี antialiased_cnns
ระเบียบวิธี วิธีการนั้นง่ายมาก -- ขั้นแรกประเมินด้วยก้าวย่างที่ 1 จากนั้นใช้เลเยอร์ BlurPool ของเราเพื่อทำการลดรอยหยักแบบลดรอยหยัก ทำการเปลี่ยนแปลงทางสถาปัตยกรรมต่อไปนี้
import antialiased_cnns
# MaxPool --> MaxBlurPool
baseline = nn . MaxPool2d ( kernel_size = 2 , stride = 2 )
antialiased = [ nn . MaxPool2d ( kernel_size = 2 , stride = 1 ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# Conv --> ConvBlurPool
baseline = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 2 , padding = 1 ),
nn . ReLU ( inplace = True )]
antialiased = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 1 , padding = 1 ),
nn . ReLU ( inplace = True ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# AvgPool --> BlurPool
baseline = nn . AvgPool2d ( kernel_size = 2 , stride = 2 )
antialiased = antialiased_cnns . BlurPool ( C , stride = 2 ) เราถือว่าเทนเซอร์ที่เข้ามามีช่อง C การคำนวณเลเยอร์ที่ก้าวย่างที่ 1 แทนที่จะเป็นก้าวที่ 2 จะเพิ่มหน่วยความจำและรันไทม์ ด้วยเหตุนี้ เรามักจะข้ามการลดรอยหยักที่ความละเอียดสูงสุด (ตั้งแต่ต้นในเครือข่าย) เพื่อป้องกันไม่ให้มีการเพิ่มขึ้นอย่างมาก
เพิ่มการลดรอยหยักแล้วฝึกต่อ หากคุณฝึกโมเดลแล้ว จากนั้นเพิ่มการลดรอยหยัก คุณสามารถปรับแต่งจากรุ่นเก่านั้นได้:
antialiased_cnns . copy_params_buffers ( old_model , antialiased_model )หากไม่ได้ผล คุณสามารถคัดลอกพารามิเตอร์ได้ (ไม่ใช่บัฟเฟอร์) การเพิ่มการลดรอยหยักไม่ได้เพิ่มพารามิเตอร์ใดๆ ดังนั้นรายการพารามิเตอร์จึงเหมือนกัน (มันเพิ่มบัฟเฟอร์ ดังนั้นจึงใช้การวิเคราะห์พฤติกรรมบางอย่างเพื่อจับคู่บัฟเฟอร์ ซึ่งอาจทำให้เกิดข้อผิดพลาด)
antialiased_cnns . copy_params ( old_model , antialiased_model )เราสังเกตการปรับปรุงทั้งในด้าน ความแม่นยำ (ความถี่ในการจัดประเภทรูปภาพอย่างถูกต้อง) และ ความสม่ำเสมอ (ความถี่ในการจัดประเภทรูปภาพเดียวกันสองกะที่เหมือนกัน)
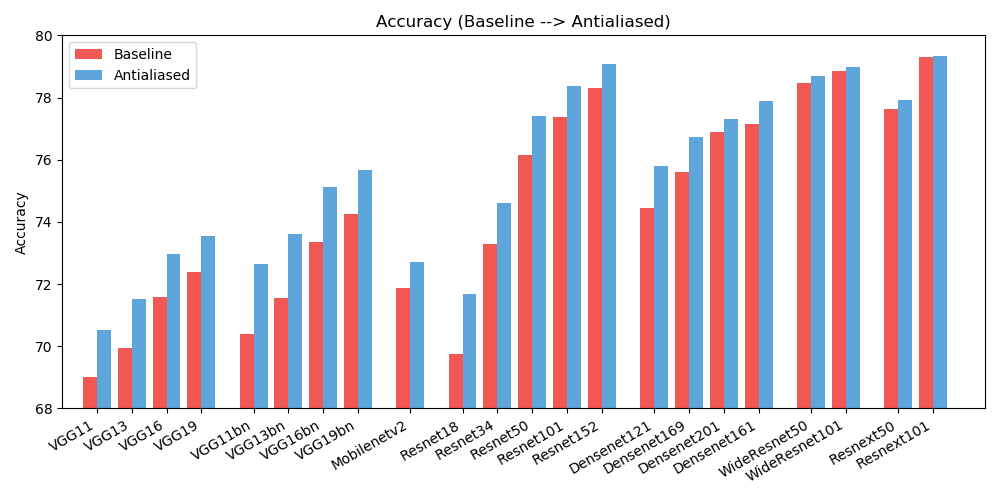
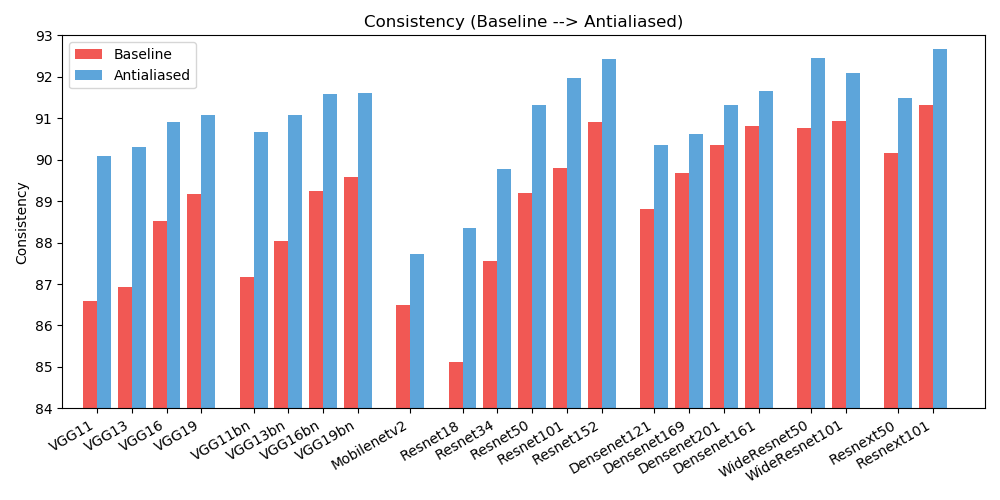
| ความแม่นยำ | พื้นฐาน | ลดรอยหยัก | เดลต้า |
|---|---|---|---|
| อเล็กซ์เน็ต | 56.55 | 56.94 | +0.39 |
| vgg11 | 69.02 | 70.51 | +1.49 |
| vgg13 | 69.93 | 71.52 | +1.59 |
| vgg16 | 71.59 | 72.96 | +1.37 |
| vgg19 | 72.38 | 73.54 | +1.16 |
| vgg11_bn | 70.38 | 72.63 | +2.25 |
| vgg13_bn | 71.55 | 73.61 | +2.06 |
| vgg16_bn | 73.36 | 75.13 | +1.77 |
| vgg19_bn | 74.24 | 75.68 | +1.44 |
| รีเซ็ต18 | 69.74 | 71.67 | +1.93 |
| รีเซ็ต34 | 73.30 | 74.60 | +1.30 |
| รีเซ็ต50 | 76.16 | 77.41 | +1.25 |
| เรสเน็ต101 | 77.37 | 78.38 | +1.01 |
| รีเซ็ต152 | 78.31 | 79.07 | +0.76 |
| resnext50_32x4d | 77.62 | 77.93 | +0.31 |
| resnext101_32x8d | 79.31 | 79.33 | +0.02 |
| wide_resnet50_2 | 78.47 | 78.70 | +0.23 |
| wide_resnet101_2 | 78.85 | 78.99 | +0.14 |
| หนาแน่นเน็ต121 | 74.43 | 75.79 | +1.36 |
| หนาแน่นเน็ต169 | 75.60 | 76.73 | +1.13 |
| หนาแน่นเน็ต201 | 76.90 | 77.31 | +0.41 |
| หนาแน่นเน็ต161 | 77.14 | 77.88 | +0.74 |
| โมบายเน็ต_v2 | 71.88 | 72.72 | +0.84 |
| ความสม่ำเสมอ | พื้นฐาน | ลดรอยหยัก | เดลต้า |
|---|---|---|---|
| อเล็กซ์เน็ต | 78.18 | 83.31 | +5.13 |
| vgg11 | 86.58 | 90.09 | +3.51 |
| vgg13 | 86.92 | 90.31 | +3.39 |
| vgg16 | 88.52 | 90.91 | +2.39 |
| vgg19 | 89.17 | 91.08 | +1.91 |
| vgg11_bn | 87.16 | 90.67 | +3.51 |
| vgg13_bn | 88.03 | 91.09 | +3.06 |
| vgg16_bn | 89.24 | 91.58 | +2.34 |
| vgg19_bn | 89.59 | 91.60 | +2.01 |
| รีเซ็ต18 | 85.11 | 88.36 | +3.25 |
| รีเซ็ต34 | 87.56 | 89.77 | +2.21 |
| รีเซ็ต50 | 89.20 | 91.32 | +2.12 |
| เรสเน็ต101 | 89.81 | 91.97 | +2.16 |
| รีเซ็ต152 | 90.92 | 92.42 | +1.50 |
| resnext50_32x4d | 90.17 | 91.48 | +1.31 |
| resnext101_32x8d | 91.33 | 92.67 | +1.34 |
| wide_resnet50_2 | 90.77 | 92.46 | +1.69 |
| wide_resnet101_2 | 90.93 | 92.10 | +1.17 |
| หนาแน่นเน็ต121 | 88.81 | 90.35 | +1.54 |
| หนาแน่นเน็ต169 | 89.68 | 90.61 | +0.93 |
| หนาแน่นเน็ต201 | 90.36 | 91.32 | +0.96 |
| หนาแน่นเน็ต161 | 90.82 | 91.66 | +0.84 |
| โมบายเน็ต_v2 | 86.50 | 87.73 | +1.23 |
เพื่อลดความยุ่งเหยิง เราจึงแสดงผลลัพธ์เพิ่มเติม (ตัวกรองขนาดต่างๆ) ไว้ที่นี่ ช่วยปรับปรุงผลลัพธ์!
งานนี้ได้รับอนุญาตภายใต้ Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License
เนื้อหาทั้งหมดจัดทำขึ้นภายใต้ใบอนุญาต Creative Commons BY-NC-SA 4.0 โดย Adobe Inc. คุณสามารถ ใช้ แจกจ่าย และดัดแปลง เนื้อหาเพื่อ วัตถุประสงค์ที่ไม่ใช่เชิงพาณิชย์ ตราบใดที่คุณให้เครดิตที่เหมาะสมโดย การอ้างอิงเอกสารของเรา และ ระบุการเปลี่ยนแปลงใดๆ ที่คุณได้ทำ
พื้นที่เก็บข้อมูลสร้างจากพื้นที่เก็บข้อมูลตัวอย่าง PyTorch และที่เก็บโมเดล torchvision สิ่งเหล่านี้ได้รับอนุญาตแบบ BSD
หากคุณพบว่าสิ่งนี้มีประโยชน์สำหรับการวิจัยของคุณ โปรดพิจารณาอ้างอิง bibtex นี้ โปรดติดต่อ Richard Zhang <rizhang ที่ Adobe dot com> หากมีความคิดเห็นหรือข้อเสนอแนะ


