igel
v1.0.0
เครื่องมือแมชชีนเลิร์นนิงอันน่ารื่นรมย์ที่ช่วยให้คุณสามารถฝึกฝน/ปรับแต่ง ทดสอบ และใช้โมเดลต่างๆ ได้โดยไม่ต้องเขียนโค้ด
บันทึก
ฉันยังทำงานกับแอปเดสก์ท็อป GUI สำหรับ igel ตามคำขอของผู้คน คุณสามารถค้นหาได้ภายใต้ Igel-UI
สารบัญ
เป้าหมายของโปรเจ็กต์คือการมอบการเรียนรู้ของเครื่องให้กับ ทุกคน ทั้งผู้ใช้ด้านเทคนิคและไม่ใช่ด้านเทคนิค
บางครั้งฉันก็ต้องการเครื่องมือ ซึ่งฉันสามารถใช้สร้างต้นแบบแมชชีนเลิร์นนิงได้อย่างรวดเร็ว ไม่ว่าจะสร้างการพิสูจน์แนวคิด สร้างโมเดลแบบร่างที่รวดเร็วเพื่อพิสูจน์ประเด็น หรือใช้ ML อัตโนมัติ ฉันพบว่าตัวเองติดอยู่กับการเขียนโค้ดสำเร็จรูปและคิดมากเกินไปว่าจะเริ่มต้นจากตรงไหน ดังนั้นฉันจึงตัดสินใจสร้างเครื่องมือนี้
igel ถูกสร้างขึ้นบนเฟรมเวิร์ก ML อื่นๆ โดยมอบวิธีง่ายๆ ในการใช้ Machine Learning โดยไม่ต้องเขียน โค้ดแม้แต่บรรทัดเดียว Igel สามารถปรับแต่งได้สูง แต่ถ้าคุณต้องการเท่านั้น Igel ไม่ได้บังคับให้คุณปรับแต่งอะไรเลย นอกจากค่าเริ่มต้นแล้ว igel ยังสามารถใช้คุณสมบัติ auto-ml เพื่อค้นหาโมเดลที่สามารถทำงานได้ดีกับข้อมูลของคุณ
สิ่งที่คุณต้องมีคือไฟล์ yaml (หรือ json ) ซึ่งคุณต้องอธิบายสิ่งที่คุณพยายามทำ แค่นั้นแหละ!
Igel รองรับการถดถอย การจำแนกประเภท และการจัดกลุ่ม Igel รองรับคุณสมบัติ auto-ml เช่น ImageClassification และ TextClassification
Igel รองรับประเภทชุดข้อมูลที่ใช้มากที่สุดในสาขาวิทยาศาสตร์ข้อมูล ตัวอย่างเช่น ชุดข้อมูลอินพุตของคุณอาจเป็นไฟล์ csv, txt, excel sheet, json หรือแม้แต่ไฟล์ html ที่คุณต้องการดึงข้อมูล หากคุณใช้คุณสมบัติ auto-ml คุณสามารถป้อนข้อมูลดิบไปยัง igel ได้ และมันจะหาวิธีจัดการกับมัน ข้อมูลเพิ่มเติมเกี่ยวกับเรื่องนี้ในภายหลังในตัวอย่าง
$ pip install -U igel รุ่นที่รองรับของ Igel:
+--------------------+----------------------------+-------------------------+
| regression | classification | clustering |
+--------------------+----------------------------+-------------------------+
| LinearRegression | LogisticRegression | KMeans |
| Lasso | Ridge | AffinityPropagation |
| LassoLars | DecisionTree | Birch |
| BayesianRegression | ExtraTree | AgglomerativeClustering |
| HuberRegression | RandomForest | FeatureAgglomeration |
| Ridge | ExtraTrees | DBSCAN |
| PoissonRegression | SVM | MiniBatchKMeans |
| ARDRegression | LinearSVM | SpectralBiclustering |
| TweedieRegression | NuSVM | SpectralCoclustering |
| TheilSenRegression | NearestNeighbor | SpectralClustering |
| GammaRegression | NeuralNetwork | MeanShift |
| RANSACRegression | PassiveAgressiveClassifier | OPTICS |
| DecisionTree | Perceptron | KMedoids |
| ExtraTree | BernoulliRBM | ---- |
| RandomForest | BoltzmannMachine | ---- |
| ExtraTrees | CalibratedClassifier | ---- |
| SVM | Adaboost | ---- |
| LinearSVM | Bagging | ---- |
| NuSVM | GradientBoosting | ---- |
| NearestNeighbor | BernoulliNaiveBayes | ---- |
| NeuralNetwork | CategoricalNaiveBayes | ---- |
| ElasticNet | ComplementNaiveBayes | ---- |
| BernoulliRBM | GaussianNaiveBayes | ---- |
| BoltzmannMachine | MultinomialNaiveBayes | ---- |
| Adaboost | ---- | ---- |
| Bagging | ---- | ---- |
| GradientBoosting | ---- | ---- |
+--------------------+----------------------------+-------------------------+สำหรับ ML อัตโนมัติ:
คำสั่ง help มีประโยชน์มากในการตรวจสอบคำสั่งที่รองรับและ args/ตัวเลือกที่เกี่ยวข้อง
$ igel --helpคุณยังสามารถรันวิธีใช้บนคำสั่งย่อยได้ เช่น:
$ igel fit --helpIgel สามารถปรับแต่งได้สูง หากคุณรู้ว่าคุณต้องการอะไรและต้องการกำหนดค่าโมเดลของคุณด้วยตนเอง ให้ตรวจสอบส่วนถัดไป ซึ่งจะแนะนำคุณเกี่ยวกับวิธีเขียนไฟล์กำหนดค่า yaml หรือ json หลังจากนั้น คุณเพียงแค่ต้องบอก igel ว่าต้องทำอย่างไร และจะหาข้อมูลและไฟล์กำหนดค่าได้จากที่ไหน นี่คือตัวอย่าง:
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml 'อย่างไรก็ตาม คุณยังสามารถใช้คุณสมบัติ auto-ml และปล่อยให้ igel ทำทุกอย่างให้คุณได้ ตัวอย่างที่ดีสำหรับสิ่งนี้คือการจัดหมวดหมู่รูปภาพ สมมติว่าคุณมีชุดข้อมูลของรูปภาพดิบที่จัดเก็บไว้ในโฟลเดอร์ชื่อ รูปภาพ อยู่แล้ว
สิ่งที่คุณต้องทำคือเรียกใช้:
$ igel auto-train --data_path ' path_to_your_images_folder ' --task ImageClassificationแค่นั้นแหละ! Igel จะอ่านรูปภาพจากไดเร็กทอรี ประมวลผลชุดข้อมูล (แปลงเป็นเมทริกซ์ ลดขนาด แบ่ง ฯลฯ...) และเริ่มฝึกอบรม/ปรับแต่งโมเดลที่เหมาะกับข้อมูลของคุณ อย่างที่คุณเห็นว่ามันค่อนข้างง่าย คุณเพียงแค่ต้องระบุเส้นทางไปยังข้อมูลของคุณและงานที่คุณต้องการทำ
บันทึก
คุณลักษณะนี้มีราคาแพงในการคำนวณ เนื่องจาก igel จะลองใช้รุ่นต่างๆ มากมายและเปรียบเทียบประสิทธิภาพเพื่อค้นหารุ่นที่ "ดีที่สุด"
คุณสามารถรันคำสั่ง help เพื่อรับคำแนะนำได้ คุณยังสามารถเรียกใช้ help บนคำสั่งย่อยได้!
$ igel --helpขั้นตอนแรกคือการจัดเตรียมไฟล์ yaml (คุณสามารถใช้ json ได้หากต้องการ)
คุณสามารถทำได้ด้วยตนเองโดยสร้างไฟล์ .yaml (เรียกว่า igel.yaml ตามแบบแผน แต่คุณสามารถตั้งชื่อได้ตามต้องการ) แล้วแก้ไขด้วยตนเอง อย่างไรก็ตาม หากคุณขี้เกียจ (และคุณก็อาจเป็นเช่นฉัน :D) คุณสามารถใช้คำสั่ง igel init เพื่อเริ่มต้นอย่างรวดเร็ว ซึ่งจะสร้างไฟล์กำหนดค่าพื้นฐานสำหรับคุณได้ทันที
"""
igel init --help
Example:
If I want to use neural networks to classify whether someone is sick or not using the indian-diabetes dataset,
then I would use this command to initialize a yaml file n.b. you may need to rename outcome column in .csv to sick:
$ igel init -type " classification " -model " NeuralNetwork " -target " sick "
"""
$ igel initหลังจากรันคำสั่ง ไฟล์ igel.yaml จะถูกสร้างขึ้นสำหรับคุณในไดเร็กทอรีการทำงานปัจจุบัน คุณสามารถตรวจสอบและแก้ไขได้หากต้องการ ไม่เช่นนั้นคุณสามารถสร้างทุกอย่างตั้งแต่เริ่มต้นได้
# model definition
model :
# in the type field, you can write the type of problem you want to solve. Whether regression, classification or clustering
# Then, provide the algorithm you want to use on the data. Here I'm using the random forest algorithm
type : classification
algorithm : RandomForest # make sure you write the name of the algorithm in pascal case
arguments :
n_estimators : 100 # here, I set the number of estimators (or trees) to 100
max_depth : 30 # set the max_depth of the tree
# target you want to predict
# Here, as an example, I'm using the famous indians-diabetes dataset, where I want to predict whether someone have diabetes or not.
# Depending on your data, you need to provide the target(s) you want to predict here
target :
- sickในตัวอย่างด้านบน ฉันใช้ Random Forest เพื่อจำแนกว่ามีคนเป็นโรคเบาหวานหรือไม่ ขึ้นอยู่กับคุณลักษณะบางอย่างในชุดข้อมูลที่ฉันใช้โรคเบาหวานของอินเดียที่มีชื่อเสียงในชุดข้อมูลโรคเบาหวานของอินเดียตัวอย่างนี้)
โปรดสังเกตว่าฉันส่ง n_estimators และ max_depth เป็นอาร์กิวเมนต์เพิ่มเติมให้กับโมเดล หากคุณไม่ระบุอาร์กิวเมนต์ ระบบจะใช้ค่าเริ่มต้น คุณไม่จำเป็นต้องจำข้อโต้แย้งของแต่ละโมเดล คุณสามารถรัน igel models ในเทอร์มินัลของคุณได้ตลอดเวลา ซึ่งจะพาคุณเข้าสู่โหมดโต้ตอบ ซึ่งคุณจะได้รับแจ้งให้ป้อนโมเดลที่คุณต้องการใช้และประเภทของปัญหาที่คุณต้องการแก้ไข จากนั้น Igel จะแสดงข้อมูลเกี่ยวกับโมเดลและลิงก์ที่คุณสามารถติดตามเพื่อดูรายการอาร์กิวเมนต์ที่มีอยู่และวิธีใช้งาน
เรียกใช้คำสั่งนี้ในเทอร์มินัลเพื่อปรับ/ฝึกโมเดล โดยที่คุณระบุ เส้นทางไปยังชุดข้อมูล และ เส้นทางไปยังไฟล์ yaml
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml '
# or shorter
$ igel fit -dp ' path_to_your_csv_dataset.csv ' -yml ' path_to_your_yaml_file.yaml '
"""
That's it. Your "trained" model can be now found in the model_results folder
(automatically created for you in your current working directory).
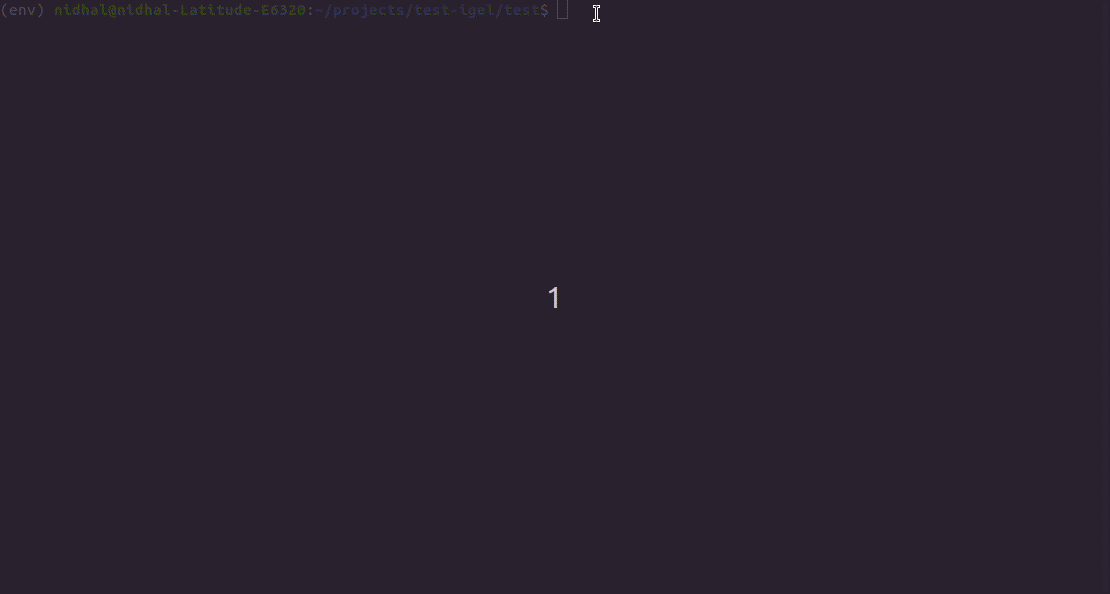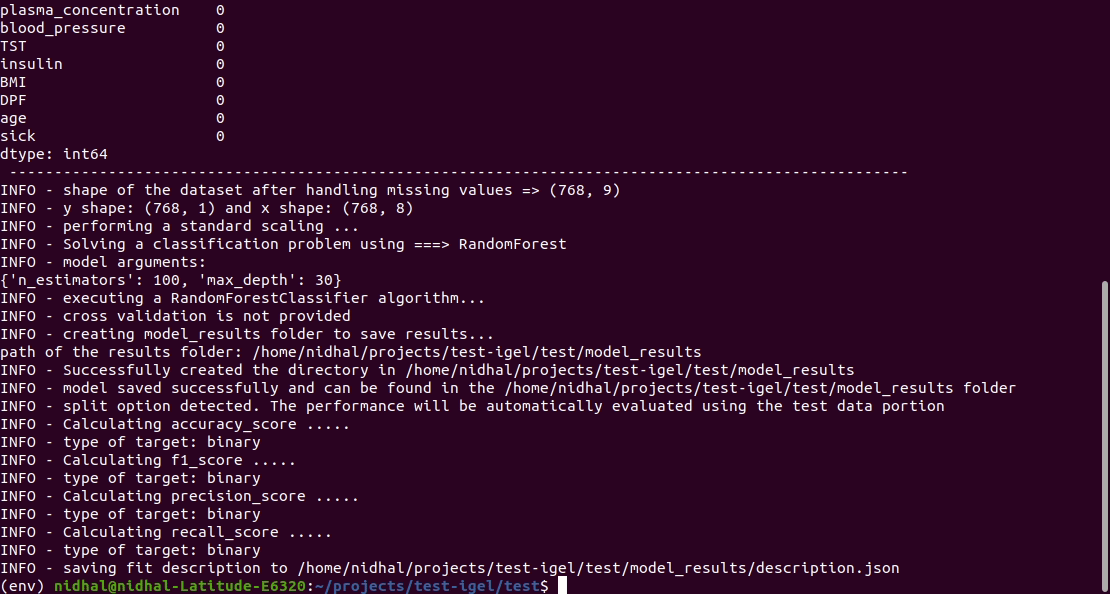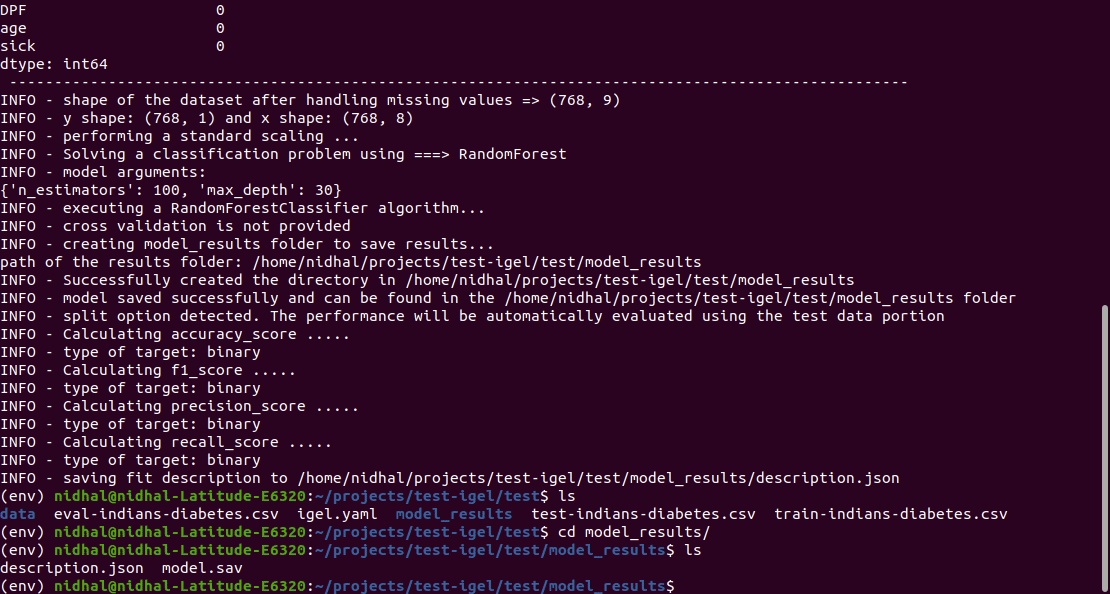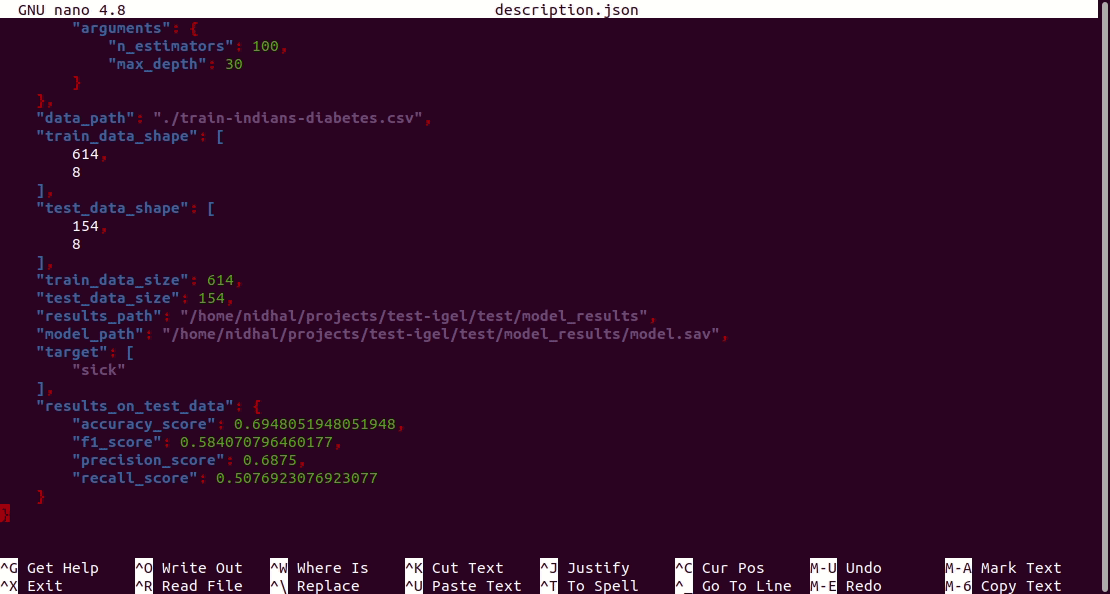
Furthermore, a description can be found in the description.json file inside the model_results folder.
"""
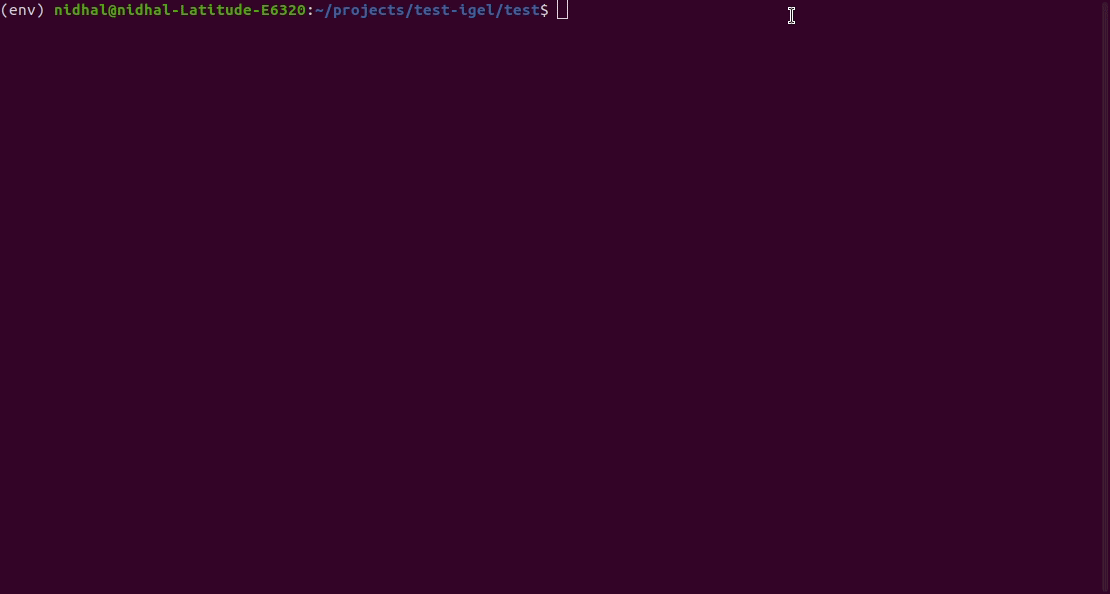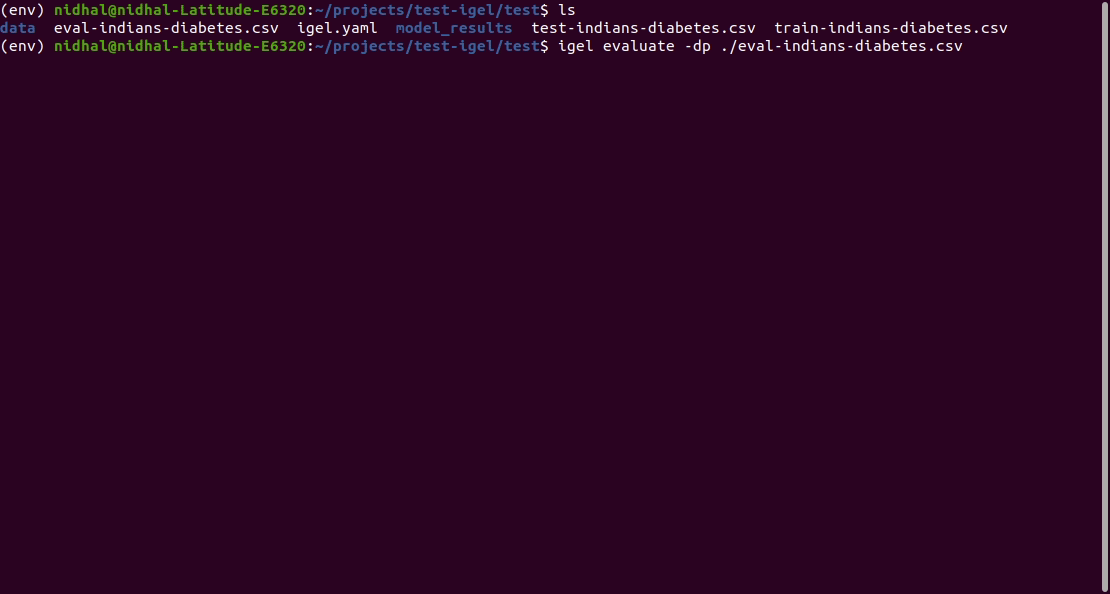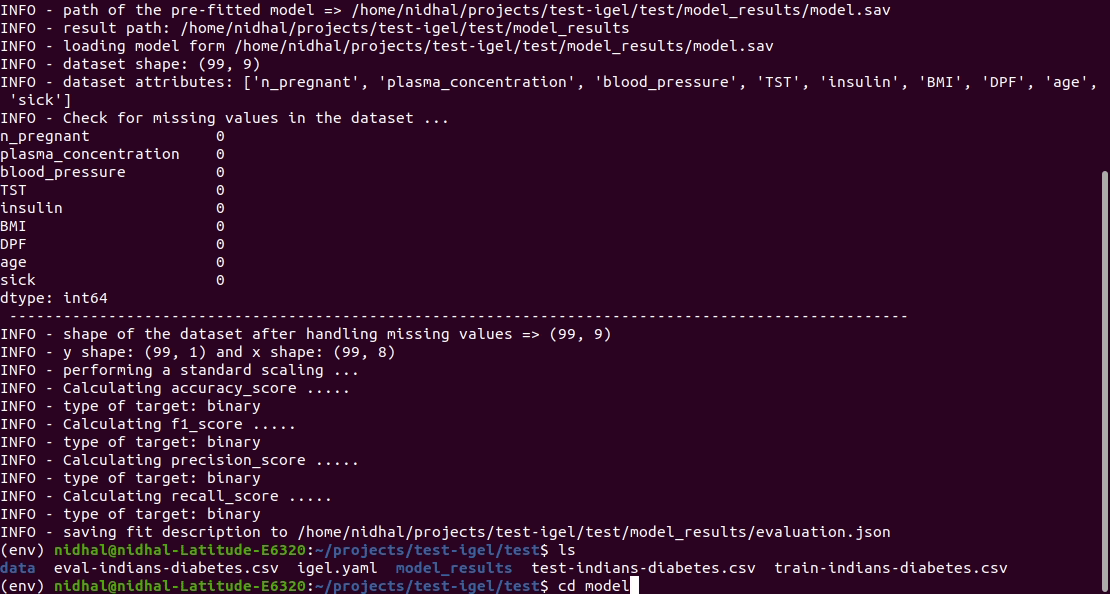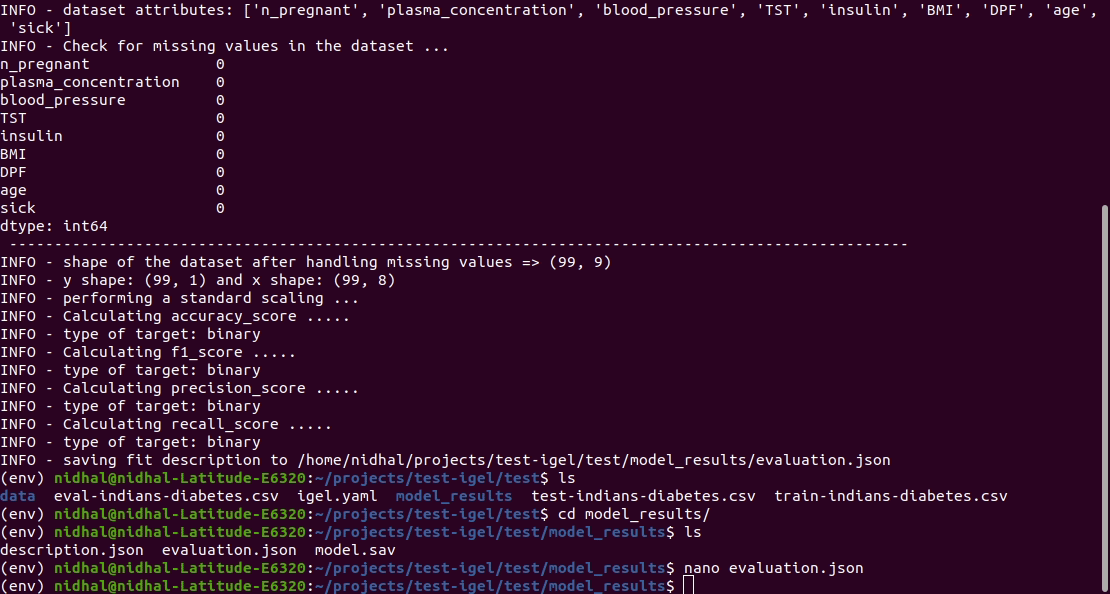
จากนั้น คุณสามารถประเมินแบบจำลองที่ผ่านการฝึกอบรม/ติดตั้งไว้ล่วงหน้าได้:
$ igel evaluate -dp ' path_to_your_evaluation_dataset.csv '
"""
This will automatically generate an evaluation.json file in the current directory, where all evaluation results are stored
"""
สุดท้ายนี้ คุณสามารถใช้แบบจำลองที่ได้รับการฝึก/ติดตั้งไว้ล่วงหน้าเพื่อคาดการณ์ได้ หากคุณพอใจกับผลการประเมิน:
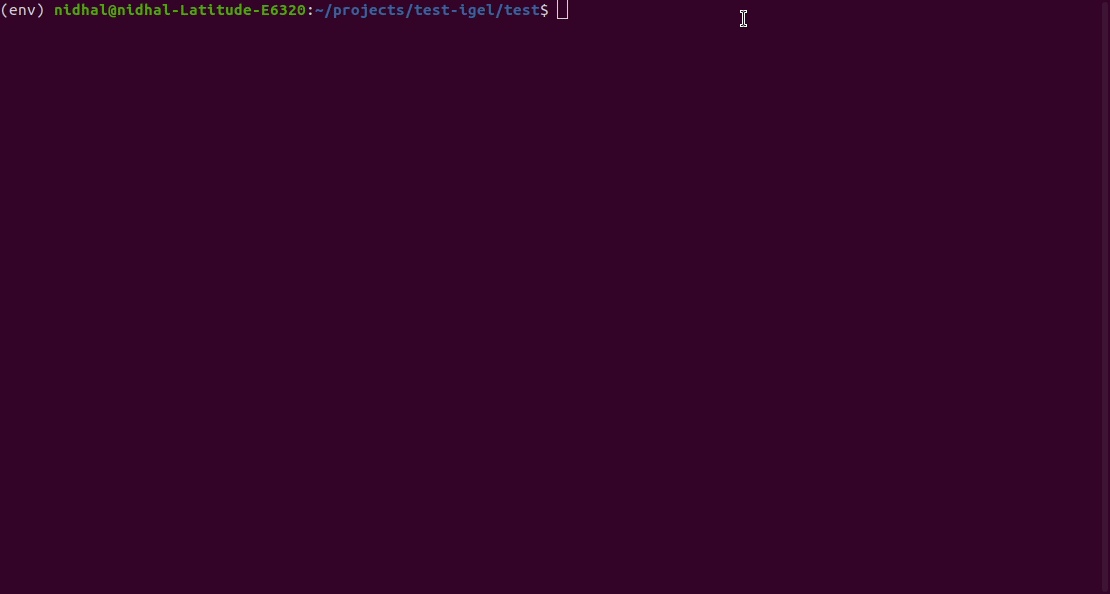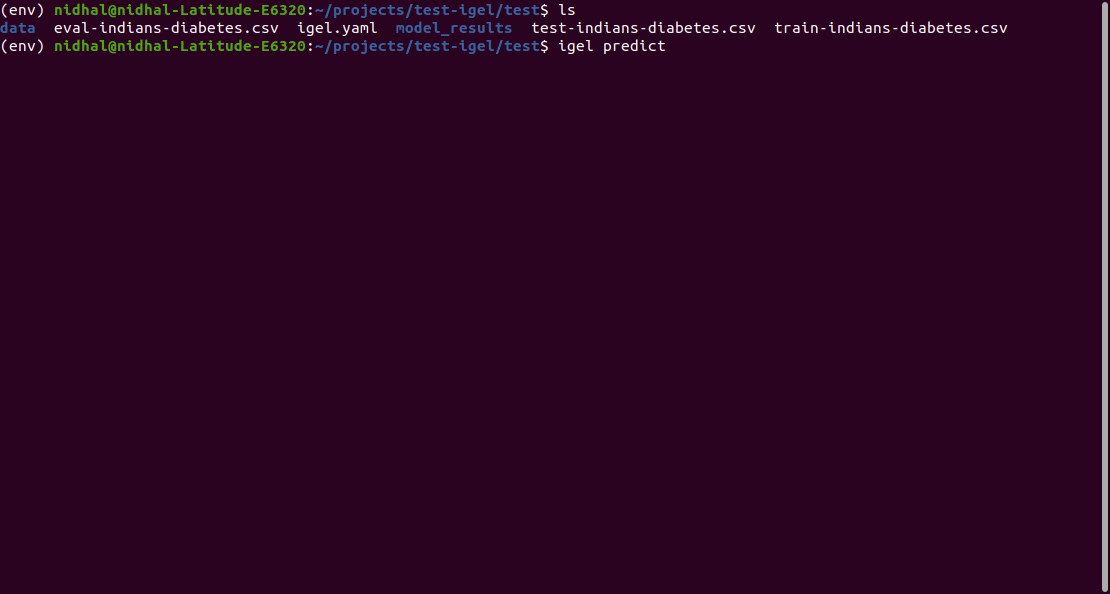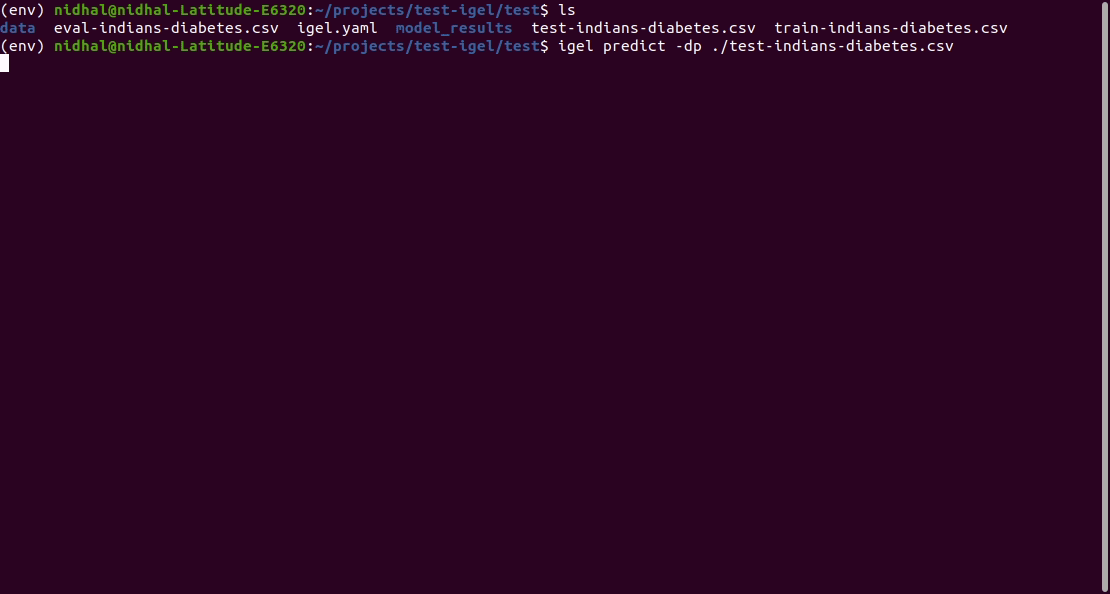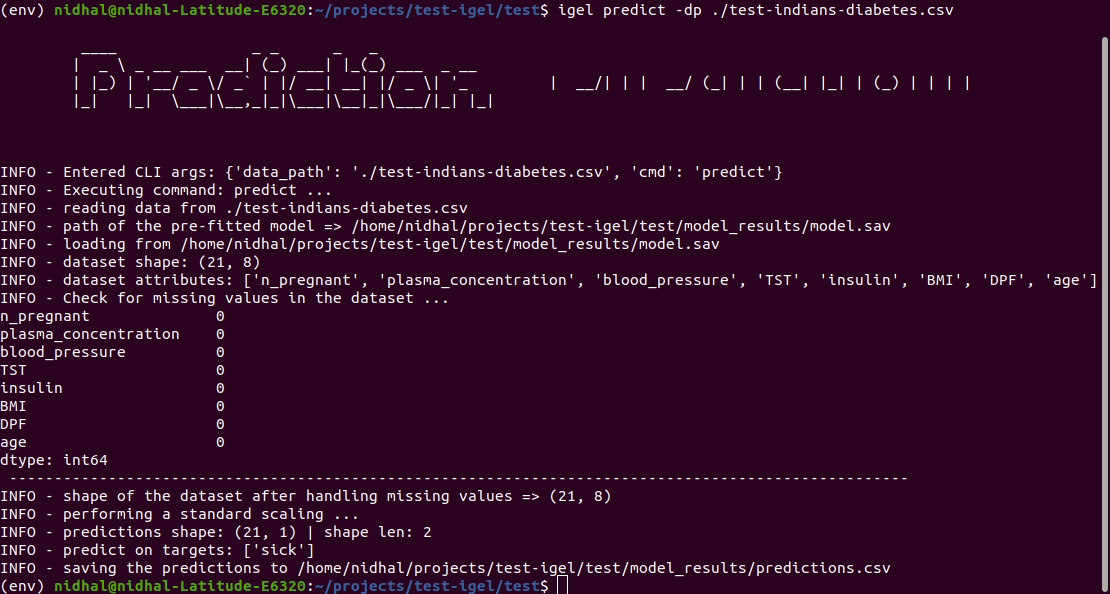
$ igel predict -dp ' path_to_your_test_dataset.csv '
"""
This will generate a predictions.csv file in your current directory, where all predictions are stored in a csv file
"""
คุณสามารถรวมการฝึก ประเมิน และทำนายเฟสได้โดยใช้คำสั่งเดียวที่เรียกว่าการทดลอง:
$ igel experiment -DP " path_to_train_data path_to_eval_data path_to_test_data " -yml " path_to_yaml_file "
"""
This will run fit using train_data, evaluate using eval_data and further generate predictions using the test_data
"""
คุณสามารถส่งออกโมเดล sklearn ที่ผ่านการฝึกอบรม/ติดตั้งไว้ล่วงหน้าไปยัง ONNX ได้:
$ igel export -dp " path_to_pre-fitted_sklearn_model "
"""
This will convert the sklearn model into ONNX
""" from igel import Igel
Igel ( cmd = "fit" , data_path = "path_to_your_dataset" , yaml_path = "path_to_your_yaml_file" )
"""
check the examples folder for more
"""ขั้นตอนต่อไปคือการใช้แบบจำลองของคุณในการผลิต Igel ช่วยคุณในงานนี้ด้วยโดยการจัดเตรียมคำสั่งเสิร์ฟ การรันคำสั่งเสิร์ฟจะบอก igel ให้ให้บริการโมเดลของคุณ แน่นอนว่า igel จะสร้างเซิร์ฟเวอร์ REST โดยอัตโนมัติและให้บริการโมเดลของคุณบนโฮสต์และพอร์ตเฉพาะ ซึ่งคุณสามารถกำหนดค่าได้โดยส่งสิ่งเหล่านี้เป็นตัวเลือก cli
วิธีที่ง่ายที่สุดคือการรัน:
$ igel serve --model_results_dir " path_to_model_results_directory "โปรดสังเกตว่า igel ต้องการตัวเลือก --model_results_dir หรือ shortly -res_dir cli เพื่อโหลดโมเดลและเริ่มต้นเซิร์ฟเวอร์ ตามค่าเริ่มต้น igel จะให้บริการโมเดลของคุณบน localhost:8000 อย่างไรก็ตาม คุณสามารถแทนที่สิ่งนี้ได้อย่างง่ายดายโดยระบุตัวเลือกโฮสต์และพอร์ต cli
$ igel serve --model_results_dir " path_to_model_results_directory " --host " 127.0.0.1 " --port 8000Igel ใช้ FastAPI เพื่อสร้างเซิร์ฟเวอร์ REST ซึ่งเป็นเฟรมเวิร์กประสิทธิภาพสูงที่ทันสมัย และ uvicorn เพื่อรันภายใต้ประทุน
ตัวอย่างนี้ดำเนินการโดยใช้แบบจำลองที่ได้รับการฝึกอบรมล่วงหน้า (สร้างโดยการรัน igel init --target Patient -type การจำแนกประเภท) และชุดข้อมูล Indian Diabetes ภายใต้ตัวอย่าง/ข้อมูล ส่วนหัวของคอลัมน์ใน CSV ต้นฉบับคือ 'preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi' และ 'age'
ขด:
$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": 1, "plas": 180, "pres": 50, "skin": 12, "test": 1, "mass": 456, "pedi": 0.442, "age": 50} '
Outputs: {"prediction":[[0.0]]}$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": [1, 6, 10], "plas":[192, 52, 180], "pres": [40, 30, 50], "skin": [25, 35, 12], "test": [0, 1, 1], "mass": [456, 123, 155], "pedi": [0.442, 0.22, 0.19], "age": [50, 40, 29]} '
Outputs: {"prediction":[[1.0],[0.0],[0.0]]}คำเตือน/ข้อจำกัด:
ตัวอย่างการใช้งานไคลเอนต์ Python:
from python_client import IgelClient
# the client allows additional args with defaults:
# scheme="http", endpoint="predict", missing_values="mean"
client = IgelClient ( host = 'localhost' , port = 8080 )
# you can post other types of files compatible with what Igel data reading allows
client . post ( "my_batch_file_for_predicting.csv" )
Outputs : < Response 200 > : { "prediction" :[[ 1.0 ],[ 0.0 ],[ 0.0 ]]}เป้าหมายหลักของ igel คือการจัดหาวิธีการฝึกฝน/ปรับแต่ง ประเมิน และใช้โมเดลโดยไม่ต้องเขียนโค้ด สิ่งที่คุณต้องทำก็แค่ระบุ/อธิบายสิ่งที่คุณต้องการทำในไฟล์ yaml แบบง่ายๆ
โดยพื้นฐานแล้ว คุณจะระบุคำอธิบายหรือการกำหนดค่าในไฟล์ yaml ให้เป็นคู่ของค่าคีย์ นี่คือภาพรวมของการกำหนดค่าที่รองรับทั้งหมด (ในขณะนี้):
# dataset operations
dataset :
type : csv # [str] -> type of your dataset
read_data_options : # options you want to supply for reading your data (See the detailed overview about this in the next section)
sep : # [str] -> Delimiter to use.
delimiter : # [str] -> Alias for sep.
header : # [int, list of int] -> Row number(s) to use as the column names, and the start of the data.
names : # [list] -> List of column names to use
index_col : # [int, str, list of int, list of str, False] -> Column(s) to use as the row labels of the DataFrame,
usecols : # [list, callable] -> Return a subset of the columns
squeeze : # [bool] -> If the parsed data only contains one column then return a Series.
prefix : # [str] -> Prefix to add to column numbers when no header, e.g. ‘X’ for X0, X1, …
mangle_dupe_cols : # [bool] -> Duplicate columns will be specified as ‘X’, ‘X.1’, …’X.N’, rather than ‘X’…’X’. Passing in False will cause data to be overwritten if there are duplicate names in the columns.
dtype : # [Type name, dict maping column name to type] -> Data type for data or columns
engine : # [str] -> Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
converters : # [dict] -> Dict of functions for converting values in certain columns. Keys can either be integers or column labels.
true_values : # [list] -> Values to consider as True.
false_values : # [list] -> Values to consider as False.
skipinitialspace : # [bool] -> Skip spaces after delimiter.
skiprows : # [list-like] -> Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file.
skipfooter : # [int] -> Number of lines at bottom of file to skip
nrows : # [int] -> Number of rows of file to read. Useful for reading pieces of large files.
na_values : # [scalar, str, list, dict] -> Additional strings to recognize as NA/NaN.
keep_default_na : # [bool] -> Whether or not to include the default NaN values when parsing the data.
na_filter : # [bool] -> Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file.
verbose : # [bool] -> Indicate number of NA values placed in non-numeric columns.
skip_blank_lines : # [bool] -> If True, skip over blank lines rather than interpreting as NaN values.
parse_dates : # [bool, list of int, list of str, list of lists, dict] -> try parsing the dates
infer_datetime_format : # [bool] -> If True and parse_dates is enabled, pandas will attempt to infer the format of the datetime strings in the columns, and if it can be inferred, switch to a faster method of parsing them.
keep_date_col : # [bool] -> If True and parse_dates specifies combining multiple columns then keep the original columns.
dayfirst : # [bool] -> DD/MM format dates, international and European format.
cache_dates : # [bool] -> If True, use a cache of unique, converted dates to apply the datetime conversion.
thousands : # [str] -> the thousands operator
decimal : # [str] -> Character to recognize as decimal point (e.g. use ‘,’ for European data).
lineterminator : # [str] -> Character to break file into lines.
escapechar : # [str] -> One-character string used to escape other characters.
comment : # [str] -> Indicates remainder of line should not be parsed. If found at the beginning of a line, the line will be ignored altogether. This parameter must be a single character.
encoding : # [str] -> Encoding to use for UTF when reading/writing (ex. ‘utf-8’).
dialect : # [str, csv.Dialect] -> If provided, this parameter will override values (default or not) for the following parameters: delimiter, doublequote, escapechar, skipinitialspace, quotechar, and quoting
delim_whitespace : # [bool] -> Specifies whether or not whitespace (e.g. ' ' or ' ') will be used as the sep
low_memory : # [bool] -> Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
memory_map : # [bool] -> If a filepath is provided for filepath_or_buffer, map the file object directly onto memory and access the data directly from there. Using this option can improve performance because there is no longer any I/O overhead.
random_numbers : # random numbers options in case you wanted to generate the same random numbers on each run
generate_reproducible : # [bool] -> set this to true to generate reproducible results
seed : # [int] -> the seed number is optional. A seed will be set up for you if you didn't provide any
split : # split options
test_size : 0.2 # [float] -> 0.2 means 20% for the test data, so 80% are automatically for training
shuffle : true # [bool] -> whether to shuffle the data before/while splitting
stratify : None # [list, None] -> If not None, data is split in a stratified fashion, using this as the class labels.
preprocess : # preprocessing options
missing_values : mean # [str] -> other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # [str] -> other possible values: [labelEncoding]
scale : # scaling options
method : standard # [str] -> standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # [str] -> scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification # [str] -> type of the problem you want to solve. | possible values: [regression, classification, clustering]
algorithm : NeuralNetwork # [str (notice the pascal case)] -> which algorithm you want to use. | type igel algorithms in the Terminal to know more
arguments : # model arguments: you can check the available arguments for each model by running igel help in your terminal
use_cv_estimator : false # [bool] -> if this is true, the CV class of the specific model will be used if it is supported
cross_validate :
cv : # [int] -> number of kfold (default 5)
n_jobs : # [signed int] -> The number of CPUs to use to do the computation (default None)
verbose : # [int] -> The verbosity level. (default 0)
hyperparameter_search :
method : grid_search # method you want to use: grid_search and random_search are supported
parameter_grid : # put your parameters grid here that you want to use, an example is provided below
param1 : [val1, val2]
param2 : [val1, val2]
arguments : # additional arguments you want to provide for the hyperparameter search
cv : 5 # number of folds
refit : true # whether to refit the model after the search
return_train_score : false # whether to return the train score
verbose : 0 # verbosity level
# target you want to predict
target : # list of strings: basically put here the column(s), you want to predict that exist in your csv dataset
- put the target you want to predict here
- you can assign many target if you are making a multioutput prediction บันทึก
igel ใช้แพนด้าเพื่ออ่านและแยกวิเคราะห์ข้อมูล ดังนั้น คุณสามารถค้นหาพารามิเตอร์ทางเลือกของข้อมูลนี้ได้ในเอกสารอย่างเป็นทางการของแพนด้า
ภาพรวมโดยละเอียดของการกำหนดค่าที่คุณสามารถระบุได้ในไฟล์ yaml (หรือ json) มีดังต่อไปนี้ โปรดสังเกตว่าคุณไม่จำเป็นต้องใช้ค่าการกำหนดค่าทั้งหมดสำหรับชุดข้อมูลอย่างแน่นอน พวกเขาเป็นทางเลือก โดยทั่วไป igel จะทราบวิธีการอ่านชุดข้อมูลของคุณ
อย่างไรก็ตาม คุณสามารถช่วยได้โดยการระบุช่องเพิ่มเติมโดยใช้ส่วน read_data_options นี้ ตัวอย่างเช่น ค่าที่เป็นประโยชน์อย่างหนึ่งในความคิดของฉันคือ "sep" ซึ่งกำหนดวิธีแยกคอลัมน์ในชุดข้อมูล csv โดยทั่วไป ชุดข้อมูล CSV จะถูกคั่นด้วยเครื่องหมายจุลภาค ซึ่งเป็นค่าเริ่มต้นที่นี่เช่นกัน อย่างไรก็ตาม ในกรณีของคุณอาจคั่นด้วยเครื่องหมายอัฒภาค
ดังนั้น คุณสามารถระบุสิ่งนี้ได้ใน read_data_options เพียงเพิ่ม sep: ";" ภายใต้ read_data_options
| พารามิเตอร์ | พิมพ์ | คำอธิบาย |
|---|---|---|
| ก.ย | STR ค่าเริ่มต้น ',' | ตัวคั่นที่จะใช้ หาก sep เป็น None กลไก C จะไม่สามารถตรวจพบตัวคั่นได้โดยอัตโนมัติ แต่กลไกการแยกวิเคราะห์ของ Python สามารถทำได้ ซึ่งหมายความว่ากลไกหลังจะถูกใช้และตรวจจับตัวคั่นโดยอัตโนมัติด้วยเครื่องมือดมกลิ่นในตัวของ Python csv.Sniffer นอกจากนี้ ตัวคั่นที่ยาวกว่า 1 อักขระและแตกต่างจาก 's+' จะถูกตีความว่าเป็นนิพจน์ทั่วไป และจะบังคับใช้กลไกการแยกวิเคราะห์ Python ด้วย โปรดทราบว่าตัวคั่น regex มักจะเพิกเฉยต่อข้อมูลที่ยกมา ตัวอย่าง Regex: 'rt' |
| ตัวคั่น | ค่าเริ่มต้นไม่มี | นามแฝงสำหรับเดือนกันยายน |
| ส่วนหัว | int, รายการ int, ค่าเริ่มต้น 'อนุมาน' | หมายเลขแถวที่จะใช้เป็นชื่อคอลัมน์ และจุดเริ่มต้นของข้อมูล พฤติกรรมเริ่มต้นคือการอนุมานชื่อคอลัมน์: หากไม่มีการส่งชื่อใด ๆ พฤติกรรมจะเหมือนกับ header=0 และชื่อคอลัมน์จะถูกอนุมานจากบรรทัดแรกของไฟล์ หากชื่อคอลัมน์ถูกส่งอย่างชัดเจน พฤติกรรมจะเหมือนกับ header=None . ส่ง header=0 อย่างชัดเจนเพื่อให้สามารถแทนที่ชื่อที่มีอยู่ได้ ส่วนหัวอาจเป็นรายการจำนวนเต็มที่ระบุตำแหน่งของแถวสำหรับหลายดัชนีในคอลัมน์ เช่น [0,1,3] แถวแทรกแซงที่ไม่ได้ระบุจะถูกข้าม (เช่น 2 ในตัวอย่างนี้ถูกข้าม) โปรดทราบว่าพารามิเตอร์นี้จะละเว้นบรรทัดที่มีข้อคิดเห็นและบรรทัดว่างหาก skid_blank_lines=True ดังนั้น header=0 จะหมายถึงบรรทัดแรกของข้อมูล แทนที่จะเป็นบรรทัดแรกของไฟล์ |
| ชื่อ | เหมือนอาเรย์ไม่จำเป็น | รายชื่อคอลัมน์ที่จะใช้ หากไฟล์มีแถวส่วนหัว คุณควรส่ง header=0 อย่างชัดเจนเพื่อแทนที่ชื่อคอลัมน์ ไม่อนุญาตให้ทำซ้ำในรายการนี้ |
| อินเด็กซ์_คอล | int, str, ลำดับของ int / str หรือ False, ค่าเริ่มต้นไม่มี | คอลัมน์ที่จะใช้เป็นป้ายกำกับแถวของ DataFrame ไม่ว่าจะกำหนดเป็นชื่อสตริงหรือดัชนีคอลัมน์ หากได้รับลำดับของ int / str จะใช้ MultiIndex หมายเหตุ: index_col=False สามารถใช้เพื่อบังคับให้แพนด้าไม่ใช้คอลัมน์แรกเป็นดัชนี เช่น เมื่อคุณมีไฟล์ที่มีรูปแบบไม่ถูกต้องโดยมีตัวคั่นที่ส่วนท้ายของแต่ละบรรทัด |
| ใช้คอล | เหมือนรายการหรือเรียกได้ ไม่จำเป็น | ส่งกลับชุดย่อยของคอลัมน์ หากมีลักษณะเหมือนรายการ องค์ประกอบทั้งหมดจะต้องอยู่ในตำแหน่ง (เช่น ดัชนีจำนวนเต็มในคอลัมน์เอกสาร) หรือสตริงที่สอดคล้องกับชื่อคอลัมน์ที่ผู้ใช้ระบุในชื่อหรืออนุมานจากแถวส่วนหัวของเอกสาร ตัวอย่างเช่น พารามิเตอร์ usecols ที่เหมือนรายการที่ถูกต้องจะเป็น [0, 1, 2] หรือ ['foo', 'bar', 'baz'] ลำดับองค์ประกอบจะถูกละเว้น ดังนั้น usecols=[0, 1] จึงเหมือนกับ [1, 0] หากต้องการสร้างอินสแตนซ์ DataFrame จากข้อมูลที่มีลำดับองค์ประกอบที่สงวนไว้ให้ใช้ pd.read_csv(data, usecols=['foo', 'bar'])[['foo', 'bar']] สำหรับคอลัมน์ใน ['foo', 'bar '] สั่งซื้อหรือ pd.read_csv(data, usecols=['foo', 'bar'])[['bar', 'foo']] สำหรับ ['bar', 'foo'] ลำดับ หากเรียกได้ ฟังก์ชันที่เรียกได้จะถูกประเมินตามชื่อคอลัมน์ โดยส่งคืนชื่อที่ฟังก์ชันที่เรียกได้ประเมินเป็น True ตัวอย่างของอาร์กิวเมนต์ที่สามารถเรียกได้ที่ถูกต้องคือ lambda x: x.upper() ใน ['AAA', 'BBB', 'DDD'] การใช้พารามิเตอร์นี้ส่งผลให้ใช้เวลาในการแยกวิเคราะห์เร็วขึ้นมากและลดการใช้หน่วยความจำ |
| บีบ | บูล ค่าเริ่มต้นเป็นเท็จ | หากข้อมูลที่แยกวิเคราะห์มีเพียงคอลัมน์เดียว ให้ส่งคืน Series |
| คำนำหน้า | STR ไม่จำเป็น | คำนำหน้าเพื่อเพิ่มหมายเลขคอลัมน์เมื่อไม่มีส่วนหัว เช่น 'X' สำหรับ X0, X1, … |
| mangle_dupe_cols | บูล ค่าเริ่มต้นเป็น True | คอลัมน์ที่ซ้ำกันจะถูกระบุเป็น 'X', 'X.1', …'X.N' แทนที่จะเป็น 'X'...'X' การส่งผ่านค่าเท็จจะทำให้ข้อมูลถูกเขียนทับหากมีชื่อซ้ำกันในคอลัมน์ |
| ประเภท | {'c', 'python'} ไม่จำเป็น | โปรแกรมแยกวิเคราะห์ที่จะใช้ เอ็นจิ้น C นั้นเร็วกว่าในขณะที่เอ็นจิ้น python นั้นมีคุณสมบัติครบถ้วนมากกว่าในปัจจุบัน |
| ตัวแปลง | dict ไม่จำเป็น | ฟังก์ชันสำหรับการแปลงค่าในบางคอลัมน์ คีย์อาจเป็นเลขจำนวนเต็มหรือป้ายกำกับคอลัมน์ก็ได้ |
| true_values | รายการ ไม่จำเป็น | ค่าที่ต้องพิจารณาว่าเป็นจริง |
| false_values | รายการ ไม่จำเป็น | ค่าที่ต้องพิจารณาว่าเป็นเท็จ |
| ข้ามช่องว่างเริ่มต้น | บูล ค่าเริ่มต้นเป็นเท็จ | ข้ามช่องว่างหลังตัวคั่น |
| ข้าม | เหมือนรายการ int หรือ callable ไม่จำเป็น | หมายเลขบรรทัดที่จะข้าม (ดัชนี 0) หรือจำนวนบรรทัดที่จะข้าม (int) ที่จุดเริ่มต้นของไฟล์ หากเรียกใช้ได้ ฟังก์ชันที่เรียกใช้ได้จะถูกประเมินเทียบกับดัชนีแถว โดยจะส่งคืนค่า True หากควรข้ามแถว และคืนค่าเป็น False หากไม่เป็นเช่นนั้น ตัวอย่างของอาร์กิวเมนต์ที่สามารถเรียกได้ที่ถูกต้องคือ lambda x: x ใน [0, 2] |
| ข้ามฟุตเตอร์ | int ค่าเริ่มต้นคือ 0 | จำนวนบรรทัดที่ด้านล่างของไฟล์ที่จะข้าม (ไม่รองรับด้วย engine='c') |
| โนว์ | int ไม่จำเป็น | จำนวนแถวของไฟล์ที่จะอ่าน มีประโยชน์สำหรับการอ่านไฟล์ขนาดใหญ่ |
| na_values | สเกลาร์, str, รายการเหมือนหรือ dict เป็นทางเลือก | สตริงเพิ่มเติมที่จะจดจำเป็น NA/NaN หากผ่านคำสั่ง ค่า NA เฉพาะต่อคอลัมน์ ตามค่าเริ่มต้น ค่าต่อไปนี้จะถูกตีความว่าเป็น NaN: '', '#N/A', '#N/AN/A', '#NA', '-1.#IND', '-1.#QNAN', '-NaN', '-nan', '1.#IND', '1.#QNAN', '<NA>', 'N/A', 'NA', 'NULL', 'น่าน', 'ไม่มี', 'น่าน', 'โมฆะ' |
| Keep_default_na | บูล ค่าเริ่มต้นเป็น True | ไม่ว่าจะรวมค่า NaN เริ่มต้นเมื่อแยกวิเคราะห์ข้อมูลหรือไม่ ขึ้นอยู่กับว่าส่งค่า na_values หรือไม่ ลักษณะการทำงานจะเป็นดังนี้: หาก Keep_default_na เป็น True และระบุค่า na_values ค่า na_values จะถูกผนวกเข้ากับค่า NaN เริ่มต้นที่ใช้สำหรับการแยกวิเคราะห์ หาก keep_default_na เป็น True และไม่ได้ระบุ na_values ระบบจะใช้เฉพาะค่า NaN เริ่มต้นในการแยกวิเคราะห์ หาก keep_default_na เป็นเท็จ และระบุ na_values จะใช้เฉพาะค่า NaN ที่ระบุ na_values เท่านั้นในการแยกวิเคราะห์ หาก keep_default_na เป็น False และไม่ได้ระบุ na_values จะไม่มีการแยกวิเคราะห์สตริงเป็น NaN โปรดทราบว่าหากส่งผ่าน na_filter เป็น False พารามิเตอร์ Keep_default_na และ na_values จะถูกละเว้น |
| na_filter | บูล ค่าเริ่มต้นเป็น True | ตรวจหาเครื่องหมายค่าที่หายไป (สตริงว่างและค่าของ na_values) ในข้อมูลที่ไม่มี NA การส่ง na_filter=False สามารถปรับปรุงประสิทธิภาพการอ่านไฟล์ขนาดใหญ่ได้ |
| รายละเอียด | บูล ค่าเริ่มต้นเป็นเท็จ | ระบุจำนวนค่า NA ที่อยู่ในคอลัมน์ที่ไม่ใช่ตัวเลข |
| ข้าม_blank_lines | บูล ค่าเริ่มต้นเป็น True | หากเป็น True ให้ข้ามบรรทัดว่างแทนที่จะตีความว่าเป็นค่า NaN |
| parse_dates | บูลหรือรายการของ int หรือชื่อหรือรายการของรายการหรือ dict ค่าเริ่มต้นเป็นเท็จ | ลักษณะการทำงานจะเป็นดังนี้: บูลีน หากเป็น True -> ลองแยกวิเคราะห์ดัชนี รายชื่อ int หรือชื่อ เช่น ถ้า [1, 2, 3] -> ลองแยกวิเคราะห์คอลัมน์ 1, 2, 3 แต่ละคอลัมน์เป็นคอลัมน์วันที่แยกกัน รายการของรายการ เช่น ถ้า [[1, 3]] -> รวมคอลัมน์ 1 และ 3 และแยกวิเคราะห์เป็นคอลัมน์วันที่เดียว dict เช่น {'foo' : [1, 3]} -> แยกคอลัมน์ 1, 3 เป็นวันที่และผลลัพธ์การโทร 'foo' หากคอลัมน์หรือดัชนีไม่สามารถแสดงเป็นอาร์เรย์ของ datetime ได้ ให้พูดเนื่องจากค่าที่ไม่สามารถแยกวิเคราะห์ได้หรือ การผสมผสานของเขตเวลา คอลัมน์หรือดัชนีจะถูกส่งกลับโดยไม่มีการเปลี่ยนแปลงเป็นประเภทข้อมูลออบเจ็กต์ |
| infer_datetime_format | บูล ค่าเริ่มต้นเป็นเท็จ | หากเปิดใช้งาน True และ parse_dates แพนด้าจะพยายามอนุมานรูปแบบของสตริงวันที่และเวลาในคอลัมน์ และหากสามารถอนุมานได้ ให้เปลี่ยนไปใช้วิธีแยกวิเคราะห์ที่เร็วกว่า ในบางกรณีอาจเพิ่มความเร็วในการแยกวิเคราะห์ได้ 5-10 เท่า |
| Keep_date_col | บูล ค่าเริ่มต้นเป็นเท็จ | หาก True และ parse_dates ระบุการรวมหลายคอลัมน์ ให้คงคอลัมน์เดิมไว้ |
| date_parser | ฟังก์ชั่นไม่จำเป็น | ฟังก์ชันที่ใช้สำหรับแปลงลำดับของคอลัมน์สตริงเป็นอาร์เรย์ของอินสแตนซ์วันที่และเวลา ค่าเริ่มต้นใช้ dateutil.parser.parser เพื่อทำการแปลง Pandas จะพยายามเรียก date_parser ด้วยสามวิธีที่แตกต่างกัน โดยจะเลื่อนไปยังขั้นตอนถัดไปหากมีข้อยกเว้นเกิดขึ้น: 1) ส่งผ่านอาร์เรย์ตั้งแต่หนึ่งอาร์เรย์ขึ้นไป (ตามที่กำหนดโดย parse_dates) เป็นอาร์กิวเมนต์; 2) เชื่อมต่อ (ตามแถว) ค่าสตริงจากคอลัมน์ที่กำหนดโดย parse_dates ลงในอาร์เรย์เดียวและส่งผ่านสิ่งนั้น และ 3) เรียก date_parser หนึ่งครั้งสำหรับแต่ละแถวโดยใช้สตริงตั้งแต่หนึ่งสตริงขึ้นไป (ตรงกับคอลัมน์ที่กำหนดโดย parse_dates) เป็นอาร์กิวเมนต์ |
| วันแรก | บูล ค่าเริ่มต้นเป็นเท็จ | วันที่ในรูปแบบ DD/MM รูปแบบสากลและยุโรป |
| cache_dates | บูล ค่าเริ่มต้นเป็น True | หากเป็น True ให้ใช้แคชของวันที่ที่แปลงแล้วไม่ซ้ำกันเพื่อใช้การแปลงวันที่และเวลา อาจสร้างความเร็วเพิ่มขึ้นอย่างมากเมื่อแยกวิเคราะห์สตริงวันที่ที่ซ้ำกัน โดยเฉพาะสตริงที่มีการชดเชยเขตเวลา |
| หลายพัน | STR ไม่จำเป็น | ตัวคั่นหลักพัน |
| ทศนิยม | STR ค่าเริ่มต้น '.' | อักขระที่ต้องจดจำเป็นจุดทศนิยม (เช่น ใช้ ',' สำหรับข้อมูลยุโรป) |
| ไลน์เทอร์มิเนเตอร์ | str (ความยาว 1) ไม่จำเป็น | ตัวละครที่จะแบ่งไฟล์ออกเป็นบรรทัด ใช้ได้กับ C parser เท่านั้น |
| Escapechar | str (ความยาว 1) ไม่จำเป็น | สตริงหนึ่งอักขระที่ใช้เพื่อหลีกอักขระอื่น |
| ความคิดเห็น | STR ไม่จำเป็น | บ่งชี้ว่าไม่ควรแยกวิเคราะห์ส่วนที่เหลือของบรรทัด หากพบที่จุดเริ่มต้นของบรรทัด บรรทัดนั้นจะถูกละเว้นโดยสิ้นเชิง |
| การเข้ารหัส | STR ไม่จำเป็น | การเข้ารหัสเพื่อใช้สำหรับ UTF เมื่ออ่าน/เขียน (เช่น 'utf-8') |
| ภาษาถิ่น | str หรือ csv.Dialect เป็นทางเลือก | หากระบุไว้ พารามิเตอร์นี้จะแทนที่ค่า (ดีฟอลต์หรือไม่) สำหรับพารามิเตอร์ต่อไปนี้: delimiter, doublequote, Escapechar, skiginitialspace, quotechar และ quoting |
| หน่วยความจำต่ำ | บูล ค่าเริ่มต้นเป็น True | ประมวลผลไฟล์ภายในเป็นชิ้นๆ ส่งผลให้ใช้หน่วยความจำน้อยลงขณะแยกวิเคราะห์ แต่อาจเป็นการอนุมานประเภทผสมกัน เพื่อให้แน่ใจว่าไม่มีประเภทผสม ให้ตั้งค่า False หรือระบุประเภทด้วยพารามิเตอร์ dtype โปรดทราบว่าไฟล์ทั้งหมดจะถูกอ่านใน DataFrame เดียวโดยไม่คำนึงถึง |
| หน่วยความจำ_แผนที่ | บูล ค่าเริ่มต้นเป็นเท็จ | แมปวัตถุไฟล์โดยตรงไปยังหน่วยความจำและเข้าถึงข้อมูลได้โดยตรงจากที่นั่น การใช้ตัวเลือกนี้สามารถปรับปรุงประสิทธิภาพได้ เนื่องจากไม่มีค่าใช้จ่าย I/O อีกต่อไป |
ในส่วนนี้จะมีโซลูชันแบบครบวงจรที่สมบูรณ์เพื่อพิสูจน์ความสามารถของ igel ตามที่อธิบายไว้ก่อนหน้านี้ คุณต้องสร้างไฟล์การกำหนดค่า yaml นี่คือตัวอย่างตั้งแต่ต้นจนจบสำหรับการทำนายว่ามีคนเป็นโรคเบาหวานหรือไม่ โดยใช้อัลกอริทึม แบบต้นไม้ตัดสินใจ ชุดข้อมูลสามารถพบได้ในโฟลเดอร์ตัวอย่าง
model :
type : classification
algorithm : DecisionTree
target :
- sick $ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileเพียงเท่านี้ igel จะปรับโมเดลให้เหมาะกับคุณและบันทึกไว้ในโฟลเดอร์ model_results ในไดเร็กทอรีปัจจุบันของคุณ
ประเมินโมเดลที่ติดตั้งไว้ล่วงหน้า Igel จะโหลดโมเดลที่ติดตั้งไว้ล่วงหน้าจากไดเร็กทอรี model_results และประเมินผลให้คุณ คุณเพียงแค่ต้องรันคำสั่งประเมินและระบุเส้นทางไปยังข้อมูลการประเมินของคุณ
$ igel evaluate -dp path_to_the_evaluation_datasetแค่นั้นแหละ! Igel จะประเมินโมเดลและจัดเก็บสถิติ/ผลลัพธ์ไว้ในไฟล์ EFFECTIVE.JSON ภายในโฟลเดอร์ model_results
ใช้แบบจำลองที่ติดตั้งไว้ล่วงหน้าเพื่อคาดการณ์ข้อมูลใหม่ igel จะดำเนินการโดยอัตโนมัติ คุณเพียงแค่ต้องระบุเส้นทางไปยังข้อมูลของคุณที่คุณต้องการใช้การคาดการณ์
$ igel predict -dp path_to_the_new_datasetแค่นั้นแหละ! Igel จะใช้โมเดลที่ติดตั้งไว้ล่วงหน้าเพื่อทำการคาดการณ์และบันทึกลงในไฟล์ Predicts.csv ภายในโฟลเดอร์ model_results
คุณยังสามารถดำเนินการวิธีประมวลผลล่วงหน้าหรือการดำเนินการอื่นๆ ได้ด้วยการระบุไว้ในไฟล์ yaml นี่คือตัวอย่าง โดยที่ข้อมูลจะถูกแบ่งออกเป็น 80% สำหรับการฝึก และ 20% สำหรับการตรวจสอบ/การทดสอบ นอกจากนี้ข้อมูลยังถูกสับเปลี่ยนขณะแยกอีกด้วย
นอกจากนี้ ข้อมูลจะได้รับการประมวลผลล่วงหน้าโดยการแทนที่ค่าที่หายไปด้วยค่าเฉลี่ย (คุณยังสามารถใช้ค่ามัธยฐาน โหมด ฯลฯ) ตรวจสอบลิงค์นี้เพื่อดูข้อมูลเพิ่มเติม
# dataset operations
dataset :
split :
test_size : 0.2
shuffle : True
stratify : default
preprocess : # preprocessing options
missing_values : mean # other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # other possible values: [labelEncoding]
scale : # scaling options
method : standard # standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification
algorithm : RandomForest
arguments :
# notice that this is the available args for the random forest model. check different available args for all supported models by running igel help
n_estimators : 100
max_depth : 20
# target you want to predict
target :
- sickจากนั้น คุณสามารถปรับโมเดลให้พอดีได้โดยการรันคำสั่ง igel ดังที่แสดงในตัวอย่างอื่นๆ
$ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileสำหรับการประเมินผล
$ igel evaluate -dp path_to_the_evaluation_datasetสำหรับการผลิต
$ igel predict -dp path_to_the_new_dataset ในโฟลเดอร์ตัวอย่างในพื้นที่เก็บข้อมูล คุณจะพบโฟลเดอร์ข้อมูลที่เก็บชุดข้อมูลโรคเบาหวานอินเดีย ม่านตา และชุดข้อมูล linnerud (จาก sklearn) ที่มีชื่อเสียงไว้ นอกจากนี้ยังมีตัวอย่างตั้งแต่ต้นจนจบในแต่ละโฟลเดอร์ ซึ่งมีสคริปต์และไฟล์ yaml ที่จะช่วยให้คุณเริ่มต้นได้
โฟลเดอร์ indian-diabetes-example มีสองตัวอย่างเพื่อช่วยคุณในการเริ่มต้น:
โฟลเดอร์ iris-example มีตัวอย่าง การถดถอยโลจิสติก โดยที่การประมวลผลล่วงหน้าบางอย่าง (การเข้ารหัสแบบ hot หนึ่งครั้ง) จะถูกดำเนินการในคอลัมน์เป้าหมายเพื่อแสดงให้คุณเห็นถึงความสามารถของ igel มากขึ้น
นอกจากนี้ multioutput-example ยังมีตัวอย่าง การถดถอย multioutput ในที่สุด ตัวอย่าง CV มีตัวอย่างโดยใช้ตัวแยกประเภท Ridge โดยใช้การตรวจสอบความถูกต้องแบบข้าม
คุณยังสามารถค้นหาการตรวจสอบข้ามและตัวอย่างการค้นหาไฮเปอร์พารามิเตอร์ได้ในโฟลเดอร์
ฉันขอแนะนำให้คุณลองใช้ตัวอย่างและ igel cli อย่างไรก็ตาม คุณยังสามารถดำเนินการ fit.py,asset.py และ Predict.py ได้โดยตรงหากต้องการ
ขั้นแรก สร้างหรือแก้ไขชุดข้อมูลของรูปภาพที่จัดหมวดหมู่เป็นโฟลเดอร์ย่อยตามป้ายกำกับ/คลาสรูปภาพ ตัวอย่างเช่น หากคุณมีรูปภาพสุนัขและแมว คุณจะต้องมี 2 โฟลเดอร์ย่อย:
สมมติว่าโฟลเดอร์ย่อยทั้งสองนี้อยู่ในโฟลเดอร์หลักโฟลเดอร์เดียวที่เรียกว่า image เพียงป้อนข้อมูลไปที่ igel:
$ igel auto-train -dp ./images --task ImageClassificationIgel จะจัดการทุกอย่างตั้งแต่การประมวลผลข้อมูลล่วงหน้าไปจนถึงการปรับไฮเปอร์พารามิเตอร์ให้เหมาะสม ในตอนท้าย โมเดลที่ดีที่สุดจะถูกจัดเก็บไว้ในเวิร์กโฟลว์ปัจจุบัน
ขั้นแรก สร้างหรือแก้ไขชุดข้อมูลข้อความที่จัดหมวดหมู่เป็นโฟลเดอร์ย่อยตามป้ายกำกับ/คลาสข้อความ ตัวอย่างเช่น หากคุณมีชุดข้อมูลข้อความที่มีการตอบรับเชิงบวกและเชิงลบ คุณจะต้องมี 2 โฟลเดอร์ย่อย:
สมมติว่าโฟลเดอร์ย่อยทั้งสองนี้อยู่ในโฟลเดอร์หลักโฟลเดอร์เดียวที่เรียกว่า texts เพียงป้อนข้อมูลไปที่ igel:
$ igel auto-train -dp ./texts --task TextClassificationIgel จะจัดการทุกอย่างตั้งแต่การประมวลผลข้อมูลล่วงหน้าไปจนถึงการปรับไฮเปอร์พารามิเตอร์ให้เหมาะสม ในตอนท้าย โมเดลที่ดีที่สุดจะถูกจัดเก็บไว้ใน dir การทำงานปัจจุบัน
คุณยังสามารถเรียกใช้ igel UI ได้หากคุณไม่คุ้นเคยกับเทอร์มินัล เพียงติดตั้ง igel บนเครื่องของคุณตามที่กล่าวไว้ข้างต้น จากนั้นรันคำสั่งเดียวนี้ในเทอร์มินัลของคุณ
$ igel guiนี่จะเป็นการเปิด gui ซึ่งใช้งานง่ายมาก ตรวจสอบตัวอย่างลักษณะของ gui และวิธีใช้งานได้ที่นี่: https://github.com/nidhaloff/igel-ui
คุณสามารถดึงภาพจากฮับนักเทียบท่าก่อน
$ docker pull nidhaloff/igelจากนั้นใช้มัน:
$ docker run -it --rm -v $( pwd ) :/data nidhaloff/igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv 'คุณสามารถรัน igel ภายใน docker ได้ด้วยการสร้างอิมเมจก่อน:
$ docker build -t igel .จากนั้นเรียกใช้และแนบไดเร็กทอรีปัจจุบันของคุณ (ไม่จำเป็นต้องเป็นไดเร็กทอรี igel) เป็น /data (workdir) ภายในคอนเทนเนอร์:
$ docker run -it --rm -v $( pwd ) :/data igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv ' หากคุณกำลังประสบปัญหาใด ๆ โปรดอย่าลังเลที่จะเปิดปัญหา นอกจากนี้ คุณสามารถติดต่อกับผู้เขียนเพื่อขอข้อมูล/คำถามเพิ่มเติมได้
คุณชอบไอเจลไหม? คุณสามารถช่วยพัฒนาโครงการนี้ได้เสมอโดย:
คุณคิดว่าโปรเจ็กต์นี้มีประโยชน์และคุณต้องการนำเสนอแนวคิดใหม่ คุณสมบัติใหม่ การแก้ไขข้อบกพร่อง และขยายเอกสารหรือไม่
ยินดีต้อนรับเสมอ อย่าลืมอ่านหลักเกณฑ์ก่อน
ใบอนุญาตเอ็มไอที
ลิขสิทธิ์ (c) 2020-ปัจจุบัน Nidhal Baccouri


