q transformer
0.3.0
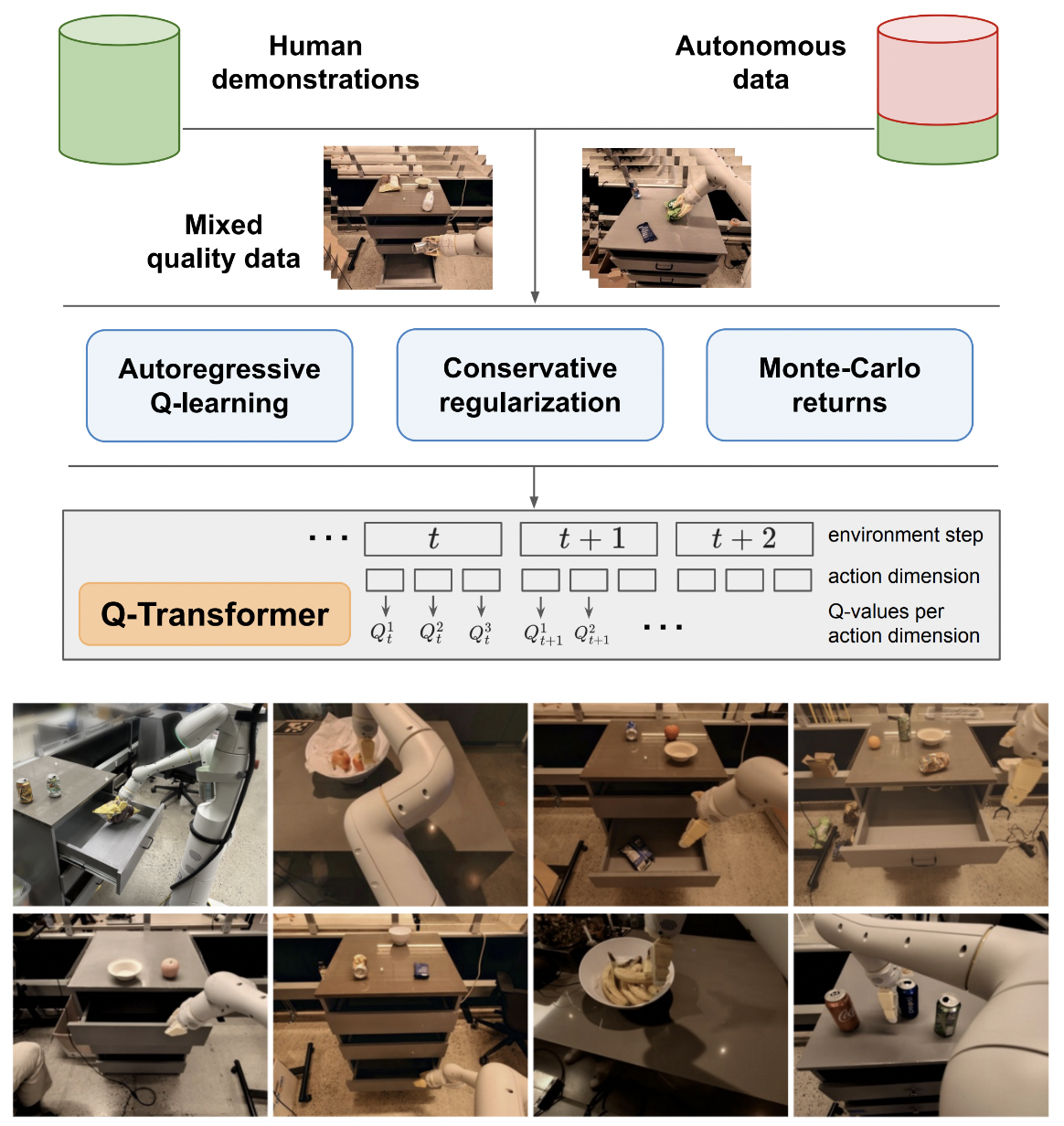
การใช้งาน Q-Transformer การเรียนรู้การเสริมกำลังแบบออฟไลน์ที่ปรับขนาดได้ผ่านฟังก์ชั่น Q-Autoregressive จาก Google Deepmind
ฉันจะรักษาตรรกะสำหรับการเรียนรู้ Q ในการกระทำเดี่ยวเพียงเพื่อการเปรียบเทียบขั้นสุดท้ายกับการเรียนรู้ Q-learning แบบ autoregressive ที่เสนอในการกระทำหลายอย่าง เพื่อเป็นการศึกษาแก่ตนเองและส่วนรวมด้วย
สูตร Q-learning แบบ autoregressive ได้รับการทำซ้ำโดย Kotb และคณะ
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )แนวทางการทำงานแรกสู่การสนับสนุนการดำเนินการเดี่ยว
เสนอ maxvit เวอร์ชันที่ไม่มีแบทช์นอร์ม เช่นเดียวกับที่ทำในโมเดลสภาพอากาศ SOTA metnet3
เพิ่มสถาปัตยกรรมการดวลลึกที่เป็นทางเลือก
เพิ่มการเรียนรู้ Q แบบ n-step
สร้างการทำให้เป็นมาตรฐานแบบอนุรักษ์นิยม
สร้างข้อเสนอหลักในกระดาษ (การกระทำแบบไม่ต่อเนื่องแบบ autoregressive จนถึงการกระทำสุดท้าย ให้รางวัลเฉพาะในครั้งสุดท้าย)
ตัวแปรส่วนหัวของตัวถอดรหัสแบบด้นสด แทนที่จะเชื่อมโยงการกระทำก่อนหน้านี้ที่เฟรม + ระยะโทเค็นที่เรียนรู้ กล่าวอีกนัยหนึ่งให้ใช้ตัวเข้ารหัสแบบคลาสสิก - ตัวถอดรหัส
ทำซ้ำ maxvit ด้วยการฝังแบบหมุนตามแนวแกน + เกต sigmoid เพื่อไม่ให้ไม่มีอะไรเกิดขึ้น เปิดใช้งานการสนใจแบบแฟลชสำหรับ maxvit ด้วยการเปลี่ยนแปลงนี้
สร้างคลาสผู้สร้างชุดข้อมูลอย่างง่าย โดยคำนึงถึงสภาพแวดล้อมและโมเดล และส่งคืนโฟลเดอร์ที่ชุด ReplayDataset ยอมรับได้
ReplayDataset ที่รับในโฟลเดอร์ จัดการคำสั่งต่างๆ ได้อย่างถูกต้อง
แสดงตัวอย่างตั้งแต่ต้นจนจบแบบง่ายๆ ในรูปแบบเดียวกับ repos อื่นๆ ทั้งหมด
จัดการไม่มีคำแนะนำ ใช้ประโยชน์จากครีมนวดผมแบบ null ในไลบรารี CFG
แคช kv สำหรับการถอดรหัสการดำเนินการ
สำหรับการสำรวจ อนุญาตให้สุ่มชุดย่อยของการกระทำอย่างละเอียด ไม่ใช่การกระทำทั้งหมดพร้อมกัน
ปรึกษาผู้เชี่ยวชาญ RL และดูว่ามีแนวทางใหม่ในการแก้ไขอคติที่หลงผิดหรือไม่
ค้นหาว่าใครสามารถฝึกด้วยลำดับการกระทำแบบสุ่มได้หรือไม่ - ลำดับสามารถส่งเป็นเงื่อนไขที่ต่อกันหรือสรุปก่อนชั้นความสนใจได้
ฟังก์ชั่นค้นหาลำแสงอย่างง่ายเพื่อการดำเนินการที่เหมาะสมที่สุด
เน้นความสนใจแบบด้นสดต่อการกระทำในอดีตและสถานะของการจับเวลา, แฟชั่นของ Transformer-xl (พร้อมการเลื่อนหน่วยความจำที่มีโครงสร้าง)
ดูว่าแนวคิดหลักในบทความนี้ใช้ได้กับโมเดลภาษาที่นี่หรือไม่
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

