perfusion pytorch
0.1.23
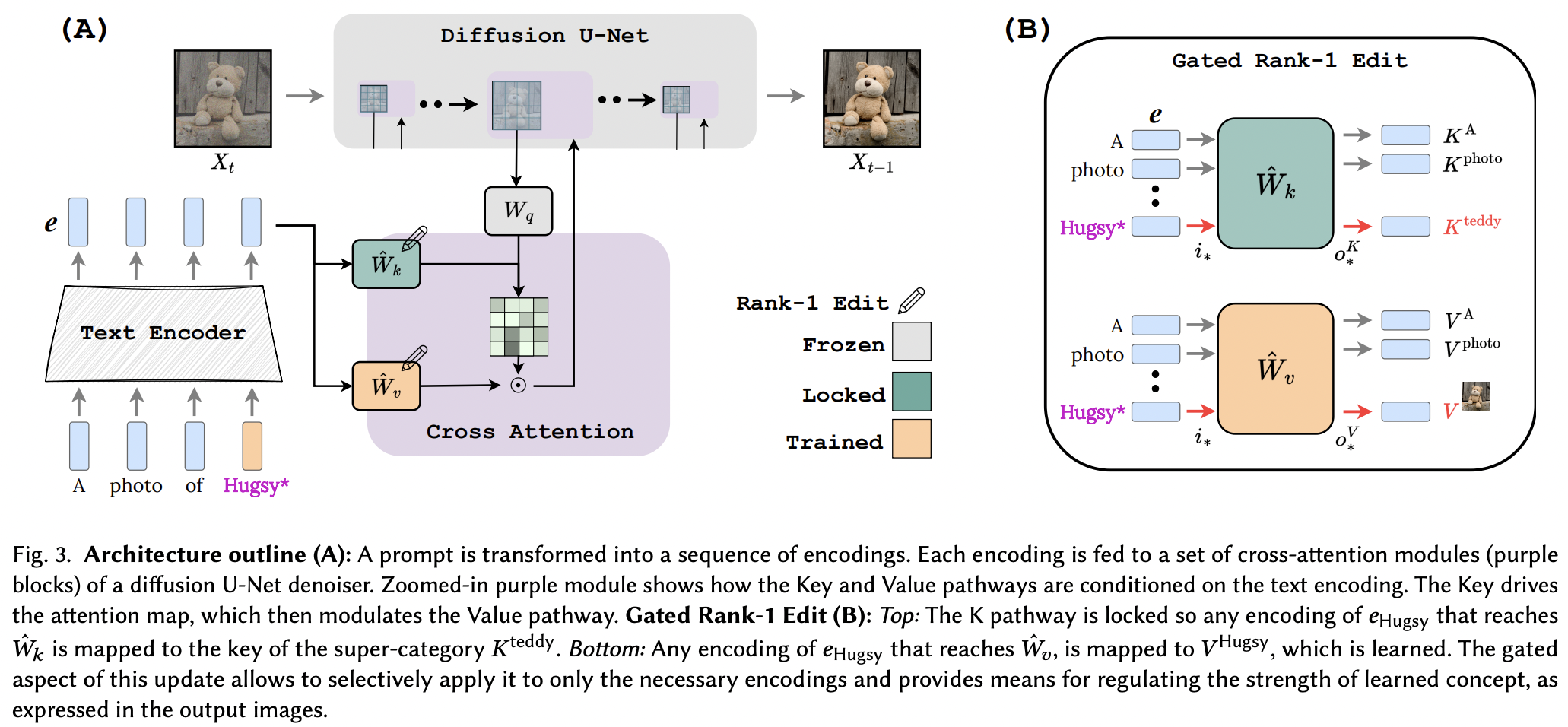
การดำเนินการแก้ไขอันดับ 1 แบบล็อคด้วยคีย์ หน้าโครงการ
จุดขายของบทความนี้คือพารามิเตอร์พิเศษต่อแนวคิดที่เพิ่มต่ำมาก เหลือเพียง 100kb
ดูเหมือนว่าพวกเขาจะใช้เทคนิคการแก้ไขอันดับ 1 จากเอกสารแก้ไขหน่วยความจำสำหรับ LLM ได้สำเร็จ โดยมีการปรับปรุงเล็กน้อย พวกเขายังระบุด้วยว่าคีย์จะกำหนด "ที่ไหน" ของแนวคิดใหม่ ในขณะที่ค่าจะกำหนด "อะไร" และเสนอการล็อกคีย์ท้องถิ่น / โกลบอลให้กับแนวคิดซูเปอร์คลาส (ในขณะที่เรียนรู้ค่า)
สำหรับนักวิจัยภายนอก หากรายงานฉบับนี้ตรวจสอบ เครื่องมือในพื้นที่เก็บข้อมูลนี้ควรใช้งานได้กับเครือข่ายข้อความเป็น <insert modality> อื่นๆ โดยใช้การปรับสภาพความสนใจแบบข้าม แค่ความคิด
StabilityAI สำหรับผู้สนับสนุนที่มีน้ำใจ เช่นเดียวกับผู้สนับสนุนคนอื่นๆ ของฉัน
Yoad Tewel สำหรับการตรวจสอบโค้ดหลายรายการและชี้แจงอีเมล
Brad Vidler สำหรับการคำนวณล่วงหน้าเมทริกซ์ความแปรปรวนร่วมสำหรับ CLIP ที่ใช้ใน Stable Diffusion 1.5!
ผู้ดูแลทุกคนที่ OpenClip สำหรับโมเดลข้อความรูปภาพการเรียนรู้เชิงเปรียบเทียบแบบโอเพ่นซอร์สของ SOTA
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc ) พื้นที่เก็บข้อมูลยังมี EmbeddingWrapper ที่ทำให้ง่ายต่อการฝึกฝนแนวคิดใหม่ (และสำหรับการอนุมานในที่สุดด้วยหลายแนวคิด)
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask หากคุณสามารถระบุอินสแตนซ์ CLIP ภายในอินสแตนซ์การแพร่กระจายที่เสถียรได้ คุณยังสามารถส่งต่อโดยตรงไปยัง OpenClipEmbedWrapper เพื่อรับทุกสิ่งที่คุณต้องการส่งต่อสำหรับเลเยอร์ความสนใจแบบข้าม
อดีต.
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) เชื่อมต่อด้วย SD 1.5 โดยเริ่มจาก xiao's dreambooth-sd
แสดงตัวอย่างใน readme เพื่อการอนุมานที่มีหลายแนวคิด
อนุมานตำแหน่งการฉายคีย์และค่าโดยอัตโนมัติหากไม่ได้ระบุสำหรับฟังก์ชัน make_key_value_proj_rank1_edit_modules_
Wrapper ที่ฝังควรดูแลการแทนที่ด้วยรหัสโทเค็นคลาส super และส่งคืนการฝังด้วย super class
ทบทวนแนวคิดหลายประการ - ขอบคุณ Yoad
นำเสนอฟังก์ชันที่เชื่อมโยงความสนใจแบบไขว้
จัดการหลายแนวคิดในพรอมต์เดียวที่การอนุมาน - ผลรวมของเทอม sigmoid + เอาต์พุต
เสนอวิธีการรวมแนวคิดที่เรียนรู้แยกกันจาก Rank1EditModule หลายรายการเข้าเป็นหนึ่งเดียวเพื่อการอนุมาน
Rank1EditModule s เพิ่มการปกปิดแนวคิดแบบ Zero-shot ที่เสนอในกระดาษ
ดูแลฟังก์ชันที่รับชุดข้อมูลและตัวเข้ารหัสข้อความและคำนวณเมทริกซ์ความแปรปรวนร่วมล่วงหน้าที่จำเป็นสำหรับการอัปเดตอันดับ 1
แทนที่จะให้ผู้วิจัยกังวลเกี่ยวกับอัตราการเรียนรู้ที่แตกต่างกัน ให้เสนอเคล็ดลับการไล่ระดับเศษส่วนจากรายงานอื่นๆ (เพื่อเรียนรู้การฝังแนวคิด)
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

