self rewarding lm pytorch
0.2.12
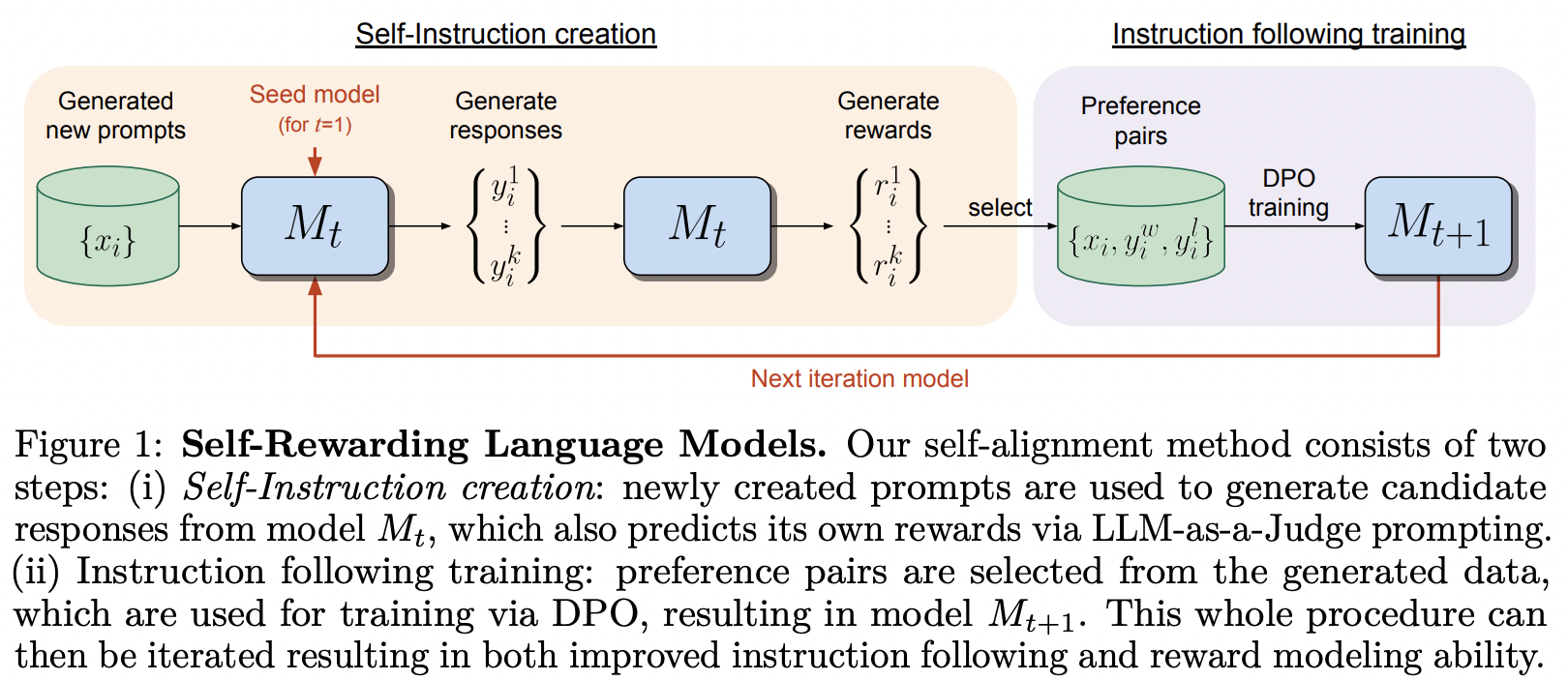
การดำเนินการตามกรอบการฝึกอบรมที่เสนอในโมเดลภาษาการให้รางวัลตนเองจาก MetaAI
พวกเขาคำนึงถึงชื่อเอกสารของ DPO เป็นอย่างยิ่ง
ห้องสมุดนี้ยังมีการปรับใช้ SPIN ซึ่ง Teknium of Nous Research ได้แสดงทัศนคติในแง่ดี
$ pip install self-rewarding-lm-pytorch import torch
from torch import Tensor
from self_rewarding_lm_pytorch import (
SelfRewardingTrainer ,
create_mock_dataset
)
from x_transformers import TransformerWrapper , Decoder
transformer = TransformerWrapper (
num_tokens = 256 ,
max_seq_len = 1024 ,
attn_layers = Decoder (
dim = 512 ,
depth = 1 ,
heads = 8
)
)
sft_dataset = create_mock_dataset ( 100 , lambda : ( torch . randint ( 0 , 256 , ( 256 ,)), torch . tensor ( 1 )))
prompt_dataset = create_mock_dataset ( 100 , lambda : 'mock prompt' )
def decode_tokens ( tokens : Tensor ) -> str :
decode_token = lambda token : str ( chr ( max ( 32 , token )))
return '' . join ( list ( map ( decode_token , tokens )))
def encode_str ( seq_str : str ) -> Tensor :
return Tensor ( list ( map ( ord , seq_str )))
trainer = SelfRewardingTrainer (
transformer ,
finetune_configs = dict (
train_sft_dataset = sft_dataset ,
self_reward_prompt_dataset = prompt_dataset ,
dpo_num_train_steps = 1000
),
tokenizer_decode = decode_tokens ,
tokenizer_encode = encode_str ,
accelerate_kwargs = dict (
cpu = True
)
)
trainer ( overwrite_checkpoints = True )
# checkpoints after each finetuning stage will be saved to ./checkpointsสามารถฝึก SPIN ได้ดังต่อไปนี้ - นอกจากนี้ยังสามารถเพิ่มไปยังไปป์ไลน์การปรับแต่งแบบละเอียดได้ดังที่แสดงในตัวอย่างสุดท้ายใน readme
import torch
from self_rewarding_lm_pytorch import (
SPINTrainer ,
create_mock_dataset
)
from x_transformers import TransformerWrapper , Decoder
transformer = TransformerWrapper (
num_tokens = 256 ,
max_seq_len = 1024 ,
attn_layers = Decoder (
dim = 512 ,
depth = 6 ,
heads = 8
)
)
sft_dataset = create_mock_dataset ( 100 , lambda : ( torch . randint ( 0 , 256 , ( 256 ,)), torch . tensor ( 1 )))
spin_trainer = SPINTrainer (
transformer ,
max_seq_len = 16 ,
train_sft_dataset = sft_dataset ,
checkpoint_every = 100 ,
spin_kwargs = dict (
λ = 0.1 ,
),
)
spin_trainer () สมมติว่าคุณต้องการทดสอบด้วยการแจ้งรางวัลของคุณเอง (นอกเหนือจาก LLM-as-Judge) ก่อนอื่นคุณต้องนำเข้า RewardConfig จากนั้นส่งต่อไปยังเทรนเนอร์เป็น reward_prompt_config
# first import
from self_rewarding_lm_pytorch import RewardConfig
# then say you want to try asking the transformer nicely
# reward_regex_template is the string that will be looked for in the LLM response, for parsing out the reward where {{ reward }} is defined as a number
trainer = SelfRewardingTrainer (
transformer ,
...,
self_reward_prompt_config = RewardConfig (
prompt_template = """
Pretty please rate the following user prompt and response
User: {{ prompt }}
Response: {{ response }}
Format your score as follows:
Rating: <rating as integer from 0 - 10>
""" ,
reward_regex_template = """
Rating: {{ reward }}
"""
)
) สุดท้ายนี้ หากคุณต้องการทดลองใช้คำสั่งการปรับแต่งอย่างละเอียดตามอำเภอใจ คุณจะมีความยืดหยุ่นดังกล่าวด้วย โดยส่งผ่านอินสแตนซ์ FinetuneConfig ไปยัง finetune_configs เป็นรายการ
อดีต. บอกว่าคุณต้องการวิจัยเกี่ยวกับ SPIN แบบสลับ การให้รางวัลจากภายนอก และการให้รางวัลตนเอง
แนวคิดนี้เกิดขึ้นจาก Teknium จากช่องความขัดแย้งส่วนตัว
# import the configs
from self_rewarding_lm_pytorch import (
SFTConfig ,
SelfRewardDPOConfig ,
ExternalRewardDPOConfig ,
SelfPlayConfig ,
)
trainer = SelfRewardingTrainer (
model ,
finetune_configs = [
SFTConfig (...),
SelfPlayConfig (...),
ExternalRewardDPOConfig (...),
SelfRewardDPOConfig (...),
SelfPlayConfig (...),
SelfRewardDPOConfig (...)
],
...
)
trainer ()
# checkpoints after each finetuning stage will be saved to ./checkpoints สรุปการสุ่มตัวอย่างเพื่อให้สามารถดำเนินการในตำแหน่งที่แตกต่างกันในชุดงาน แก้ไขการสุ่มตัวอย่างทั้งหมดให้เป็นชุด อนุญาตให้มีลำดับเบาะด้านซ้าย ในกรณีที่บางคนมีหม้อแปลงที่มีตำแหน่งสัมพัทธ์ที่อนุญาต
จัดการ eos
แสดงตัวอย่างการใช้พร้อมท์การให้รางวัลของคุณเองแทนการใช้ llm-as-judge เริ่มต้น
อนุญาตให้ใช้กลยุทธ์ที่แตกต่างกันในการสุ่มตัวอย่างคู่
อุดต้น
คำสั่งใด ๆ ของ sft, spin, dpo ให้รางวัลตัวเอง, dpo พร้อมโมเดลการให้รางวัลภายนอก
อนุญาตให้ใช้ฟังก์ชันตรวจสอบความถูกต้องของรางวัล (เช่น รางวัลต้องเป็นจำนวนเต็ม, ลอยตัว, อยู่ระหว่างบางช่วง ฯลฯ)
หาวิธีที่ดีที่สุดในการจัดการแคช kv ที่แตกต่างกัน ตอนนี้ทำโดยไม่ต้องทำอะไรเลย
การตั้งค่าสถานะสภาพแวดล้อมที่จะล้างโฟลเดอร์จุดตรวจสอบทั้งหมดโดยอัตโนมัติ
@misc { yuan2024selfrewarding ,
title = { Self-Rewarding Language Models } ,
author = { Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston } ,
year = { 2024 } ,
eprint = { 2401.10020 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @article { Chen2024SelfPlayFC ,
title = { Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models } ,
author = { Zixiang Chen and Yihe Deng and Huizhuo Yuan and Kaixuan Ji and Quanquan Gu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.01335 } ,
url = { https://api.semanticscholar.org/CorpusID:266725672 }
} @article { Rafailov2023DirectPO ,
title = { Direct Preference Optimization: Your Language Model is Secretly a Reward Model } ,
author = { Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.18290 } ,
url = { https://api.semanticscholar.org/CorpusID:258959321 }
} @inproceedings { Guo2024DirectLM ,
title = { Direct Language Model Alignment from Online AI Feedback } ,
author = { Shangmin Guo and Biao Zhang and Tianlin Liu and Tianqi Liu and Misha Khalman and Felipe Llinares and Alexandre Rame and Thomas Mesnard and Yao Zhao and Bilal Piot and Johan Ferret and Mathieu Blondel } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267522951 }
}

