rtdl revisiting models
1.0.0
สำคัญ
ลองดูโมเดล DL แบบตารางใหม่: TabM
อาร์เอ็กซ์ ? แพ็คเกจ Python โครงการ DL แบบตารางอื่น ๆ
นี่คือการดำเนินการอย่างเป็นทางการของรายงาน "การทบทวนโมเดลการเรียนรู้เชิงลึกสำหรับข้อมูลแบบตาราง"
ในประโยคเดียว: โมเดลที่คล้าย MLP ยังคงเป็นพื้นฐานที่ดีและ FT-Transformer เป็นการดัดแปลงสถาปัตยกรรม Transformer ที่ทรงพลังใหม่สำหรับปัญหาข้อมูลแบบตาราง
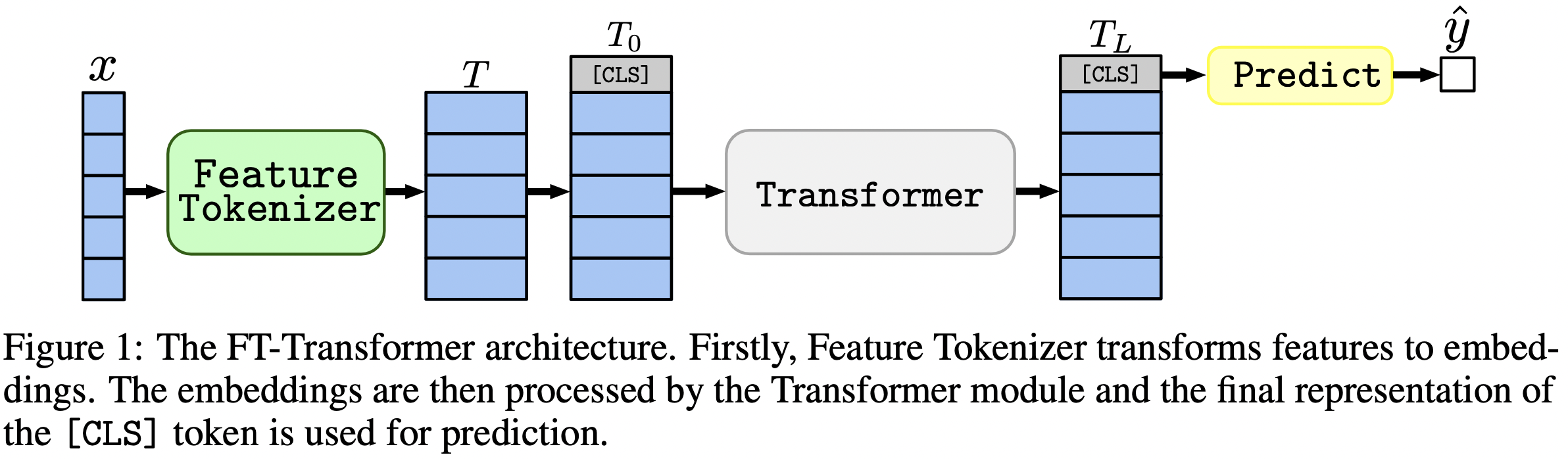
บทความนี้มุ่งเน้นไปที่สถาปัตยกรรมสำหรับปัญหาข้อมูลแบบตาราง ผลลัพธ์:
แพ็คเกจ Python ในไดเร็กทอรี package/ เป็นวิธีที่แนะนำในการใช้กระดาษในทางปฏิบัติและสำหรับการทำงานในอนาคต
เอกสารที่เหลือ :
ไดเร็กทอรี output/ ประกอบด้วยผลลัพธ์จำนวนมากและไฮเปอร์พารามิเตอร์ (ปรับแต่ง) สำหรับโมเดลและชุดข้อมูลต่างๆ ที่ใช้ในรายงาน
ตัวอย่างเช่น เรามาสำรวจเมตริกสำหรับโมเดล MLP กัน ขั้นแรก มาโหลดรายงานกันก่อน (ไฟล์ stats.json )
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])ตอนนี้ สำหรับแต่ละชุดข้อมูล มาคำนวณคะแนนการทดสอบโดยเฉลี่ยจากเมล็ดสุ่มทั้งหมด:
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))ผลลัพธ์ตรงกับตารางที่ 2 จากกระดาษทุกประการ:
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
วิธีการข้างต้นยังสามารถใช้เพื่อสำรวจไฮเปอร์พารามิเตอร์เพื่อให้ได้สัญชาตญาณเกี่ยวกับค่าไฮเปอร์พารามิเตอร์ทั่วไปสำหรับอัลกอริทึมต่างๆ ตัวอย่างเช่น นี่คือวิธีที่เราสามารถคำนวณอัตราการเรียนรู้ที่ปรับค่ามัธยฐานสำหรับโมเดล MLP:
บันทึก
สำหรับอัลกอริธึมบางอย่าง (เช่น MLP) โปรเจ็กต์ล่าสุดจะให้ผลลัพธ์มากกว่าซึ่งสามารถสำรวจได้ในลักษณะเดียวกัน ตัวอย่างเช่น ดูบทความนี้ใน TabR
คำเตือน
ใช้แนวทางนี้ด้วยความระมัดระวัง เมื่อศึกษาค่าไฮเปอร์พารามิเตอร์:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536บันทึก
ส่วนนี้ยาว ใช้ฟีเจอร์ "โครงร่าง" บน GitHub ในโปรแกรมแก้ไขข้อความเพื่อดูภาพรวมของส่วนนี้
รหัสถูกจัดระเบียบดังนี้:
bin :ensemble.py ดำเนินการประกอบtune.py ทำการปรับแต่งไฮเปอร์พารามิเตอร์analysis_gbdt_vs_nn.py รันการทดสอบcreate_synthetic_data_plots.py สร้างแปลงlib มีเครื่องมือทั่วไปที่ใช้โดยโปรแกรมใน binoutput ประกอบด้วยไฟล์การกำหนดค่า (อินพุตสำหรับโปรแกรมใน bin ) และผลลัพธ์ (เมตริก การกำหนดค่าที่ปรับ ฯลฯ)package ประกอบด้วยแพ็คเกจ Python สำหรับเอกสารนี้ ติดตั้งคอนดา
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-modelsสภาพแวดล้อมนี้จำเป็นสำหรับการทดลองกับ TabNet เท่านั้น สำหรับกรณีอื่นๆ ทั้งหมด ให้ใช้สภาพแวดล้อม PyTorch
คำแนะนำจะเหมือนกับสภาพแวดล้อม PyTorch (รวมถึงการติดตั้ง PyTorch ด้วย!) แต่:
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt ให้ทำดังต่อไปนี้:pip install tensorflow-gpu==1.14tensorboard ใน requirements.txtใบอนุญาต : โดยการดาวน์โหลดชุดข้อมูลของเรา คุณยอมรับใบอนุญาตของส่วนประกอบทั้งหมด เราไม่ได้กำหนดข้อจำกัดใหม่ใด ๆ นอกเหนือจากใบอนุญาตเหล่านั้น คุณสามารถดูรายชื่อแหล่งที่มาได้ในส่วน "ข้อมูลอ้างอิง" ของรายงานของเรา
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz ส่วนนี้จะแสดงเฉพาะคำสั่งเฉพาะพร้อมข้อคิดเห็นเล็กน้อย หลังจากเสร็จสิ้นบทช่วยสอน เราขอแนะนำให้ตรวจสอบส่วนถัดไปเพื่อความเข้าใจที่ดีขึ้นเกี่ยวกับวิธีการทำงานกับพื้นที่เก็บข้อมูล นอกจากนี้ยังจะช่วยให้เข้าใจบทช่วยสอนได้ดีขึ้น
ในบทช่วยสอนนี้ เราจะทำซ้ำผลลัพธ์สำหรับ MLP บนชุดข้อมูล California Housing เราจะครอบคลุมถึง:
โปรดทราบว่าโอกาสที่จะได้ผลลัพธ์ที่เหมือนกัน ทุกประการ นั้นค่อนข้างต่ำ แต่ก็ไม่ควรแตกต่างจากของเรามากนัก ก่อนที่จะรันสิ่งใด ให้ไปที่รูทของที่เก็บและตั้งค่า CUDA_VISIBLE_DEVICES อย่างชัดเจน (หากคุณวางแผนที่จะใช้ GPU):
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0ก่อนที่เราจะเริ่ม เรามาตรวจสอบว่ากำหนดค่าสภาพแวดล้อมสำเร็จแล้ว คำสั่งต่อไปนี้ควรฝึก MLP หนึ่งรายการบนชุดข้อมูล California Housing:
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml ผลลัพธ์ควรอยู่ในไดเร็กทอรี draft/check_environment สำหรับตอนนี้เนื้อหาของผลลัพธ์ไม่สำคัญ
การกำหนดค่าของเราสำหรับการปรับแต่ง MLP บนชุดข้อมูล California Housing อยู่ที่ output/california_housing/mlp/tuning/0.toml เพื่อที่จะทำซ้ำการปรับแต่ง ให้คัดลอกการกำหนดค่าของเราและดำเนินการปรับแต่งของคุณ:
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml ผลลัพธ์ของการปรับแต่งของคุณจะอยู่ที่ output/california_housing/mlp/tuning/reproduced คุณสามารถเปรียบเทียบกับของเราได้: output/california_housing/mlp/tuning/0 ไฟล์ best.toml มีการกำหนดค่าที่ดีที่สุดที่เราจะประเมินในส่วนถัดไป
ตอนนี้เราต้องประเมินการกำหนดค่าที่ได้รับการปรับแต่งด้วยเมล็ดสุ่มที่แตกต่างกัน 15 ชนิด
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done ไดเรกทอรีของเราพร้อมผลการประเมินตั้งอยู่ติดกับของคุณ กล่าวคือ ที่ output/california_housing/mlp/tuned
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced ผลลัพธ์ของคุณจะอยู่ที่ output/california_housing/mlp/tuned_reproduced_ensemble คุณสามารถเปรียบเทียบกับของเรา: output/california_housing/mlp/tuned_ensemble
ใช้วิธีการที่อธิบายไว้ที่นี่เพื่อสรุปผลลัพธ์ของการทดสอบที่ดำเนินการ (แก้ไขตัวกรองเส้นทางใน .glob(...) ตาม: tuned -> tuned_reproduced )
ขั้นตอนที่คล้ายกันนี้สามารถดำเนินการได้กับทุกรุ่นและชุดข้อมูล กระบวนการปรับแต่งจะแตกต่างกันเล็กน้อยในกรณีของการค้นหากริด: คุณต้องเรียกใช้การกำหนดค่าที่ต้องการทั้งหมด และเลือกการกำหนดค่าที่ดีที่สุดด้วยตนเอง ตามประสิทธิภาพการตรวจสอบ ตัวอย่างเช่น ดู output/epsilon/ft_transformer
คุณควรรันสคริปต์ Python จากรูทของที่เก็บ โปรแกรมส่วนใหญ่คาดหวังให้ไฟล์คอนฟิกูเรชันเป็นอาร์กิวเมนต์เดียว ผลลัพธ์จะเป็นไดเร็กทอรีที่มีชื่อเดียวกับการกำหนดค่า แต่ไม่มีส่วนขยาย การกำหนดค่าเขียนด้วย TOML ไม่มีการระบุรายการอาร์กิวเมนต์ที่เป็นไปได้สำหรับโปรแกรม และควรอนุมานจากสคริปต์ (โดยปกติแล้ว การกำหนดค่าจะแสดงด้วยตัวแปร args ในสคริปต์) หากคุณต้องการใช้ CUDA คุณต้องตั้งค่าตัวแปรสภาพแวดล้อม CUDA_VISIBLE_DEVICES อย่างชัดเจน ตัวอย่างเช่น:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.tomlหากคุณกำลังจะใช้ CUDA ตลอดเวลา คุณสามารถบันทึกตัวแปรสภาพแวดล้อมในสภาพแวดล้อม Conda ได้:
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " ตัวเลือก -f ( --force ) จะลบผลลัพธ์ที่มีอยู่และเรียกใช้สคริปต์ตั้งแต่เริ่มต้น:
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py รองรับความต่อเนื่อง:
python bin/tune.py path/to/config.toml --continuestats.json และผลลัพธ์อื่นๆ สำหรับสคริปต์ทั้งหมด stats.json เป็นส่วนที่สำคัญที่สุดของเอาต์พุต เนื้อหาแตกต่างกันไปในแต่ละโปรแกรม สามารถประกอบด้วย:
โดยปกติแล้วการทำนายสำหรับชุดรถไฟ การตรวจสอบความถูกต้อง และชุดการทดสอบจะถูกบันทึกไว้ด้วย
ตอนนี้คุณรู้ทุกสิ่งที่คุณต้องการเพื่อสร้างผลลัพธ์ทั้งหมดและขยายพื้นที่เก็บข้อมูลนี้ตามความต้องการของคุณ บทช่วยสอนควรมีความชัดเจนมากขึ้นในตอนนี้ อย่าลังเลที่จะเปิดประเด็นและถามคำถาม
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


