video diffusion pytorch
0.7.0
ดอกไม้ไฟเหล่านี้ไม่มีอยู่จริง
ข้อความเป็นวิดีโอ มันกำลังเกิดขึ้น! หน้าโครงการอย่างเป็นทางการ
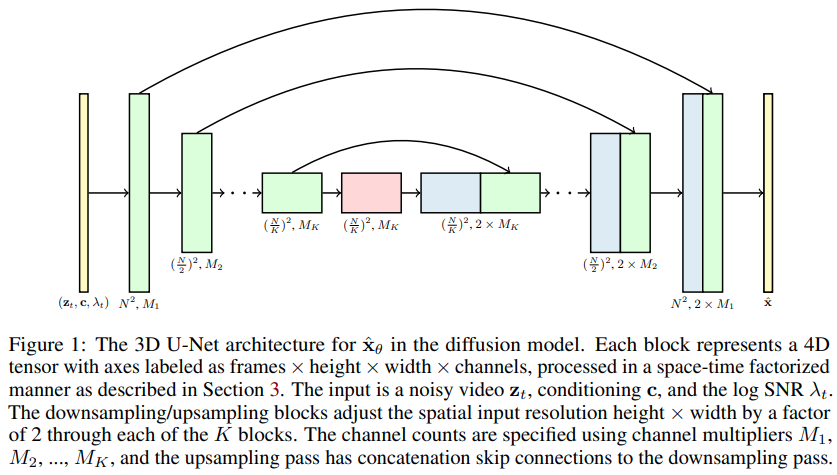
การใช้โมเดลการแพร่กระจายวิดีโอ เอกสารใหม่ของ Jonathan Ho ที่ขยาย DDPM ไปสู่การสร้างวิดีโอ - ใน Pytorch ใช้ U-net ที่เป็นปัจจัยอวกาศ-เวลาแบบพิเศษ ซึ่งขยายการสร้างจากภาพ 2 มิติไปเป็นวิดีโอ 3 มิติ
14k สำหรับการเคลื่อนไหวที่ยากลำบาก (มาบรรจบกันเร็วกว่าและดีกว่า NUWA มาก) - wip

การทดลองข้างต้นเป็นไปได้เนื่องจากทรัพยากรที่ Stability.ai จัดหาให้เท่านั้น
การพัฒนาใหม่ๆ สำหรับการสังเคราะห์ข้อความเป็นวิดีโอจะถูกรวมไว้ที่ Imagen-pytorch
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)สำหรับการปรับสภาพข้อความ พวกเขาได้รับการฝังข้อความโดยส่งข้อความโทเค็นผ่าน BERT-large ก่อน ถ้าอย่างนั้นคุณก็ต้องฝึกมันอย่างนั้น
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)คุณยังสามารถส่งคำอธิบายของวิดีโอเป็นสตริงได้โดยตรง หากคุณวางแผนที่จะใช้ฐาน BERT สำหรับการปรับข้อความ
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) พื้นที่เก็บข้อมูลนี้ยังมีคลาส Trainer ที่มีประโยชน์สำหรับการฝึกในโฟลเดอร์ gifs gif แต่ละอันจะต้องมีขนาดที่ถูกต้อง image_size และ num_frames
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train () วิดีโอตัวอย่าง (เป็นไฟล์ gif ) จะถูกบันทึกลงใน ./results เป็นระยะ เช่นเดียวกับพารามิเตอร์โมเดลการแพร่กระจาย
ข้อกล่าวอ้างประการหนึ่งในรายงานก็คือ โดยการคำนึงถึงกาล-อวกาศแยกเป็นปัจจัย เราสามารถบังคับให้เครือข่ายเข้าร่วมในปัจจุบันเพื่อฝึกอบรมรูปภาพและวิดีโอร่วมกัน ซึ่งนำไปสู่ผลลัพธ์ที่ดีกว่า
ไม่ชัดเจนว่าพวกเขาบรรลุเป้าหมายนี้ได้อย่างไร แต่ฉันคาดเดาเพิ่มเติม
หากต้องการดึงดูดความสนใจไปยังช่วงเวลาปัจจุบันสำหรับตัวอย่างวิดีโอเป็นชุดเป็นเปอร์เซ็นต์ เพียงส่ง prob_focus_present = <prob> ในวิธีการส่งต่อแบบแพร่กระจาย
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()หากคุณมีความคิดที่ดีกว่าว่าต้องทำอย่างไร เพียงเปิดปัญหา GitHub
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

