meshgpt pytorch
1.8.1
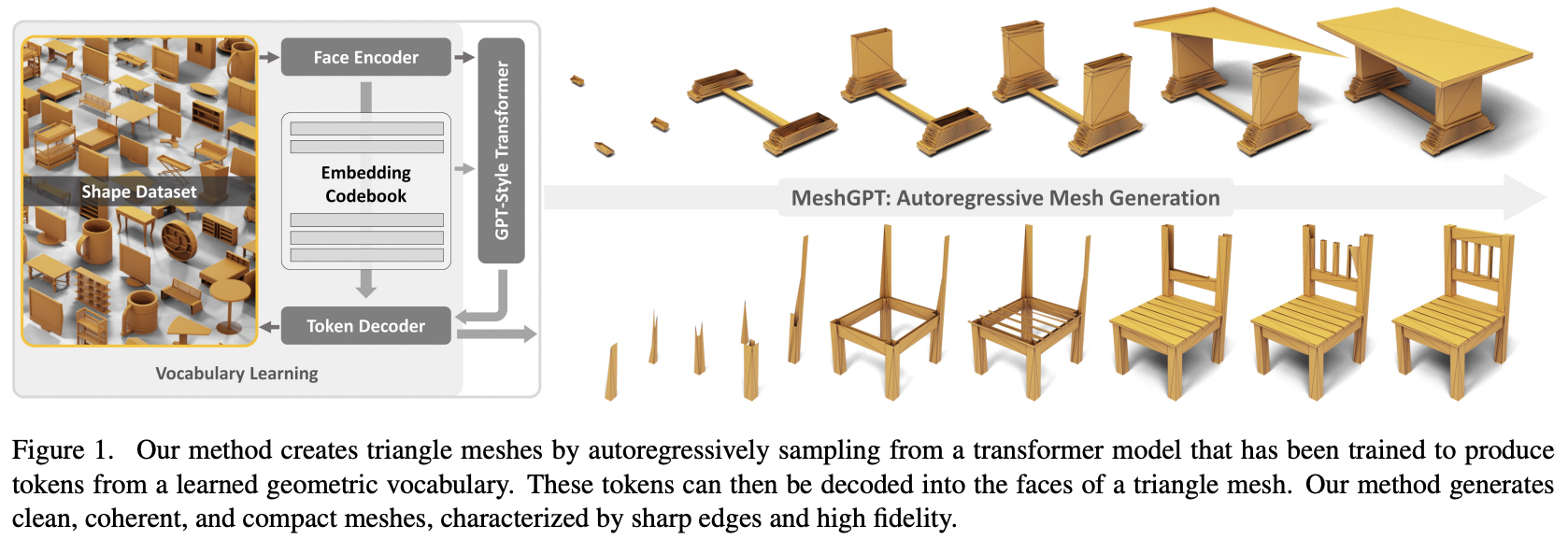
การใช้งาน MeshGPT, การสร้าง SOTA Mesh โดยใช้ Attention ใน Pytorch
จะเพิ่มการปรับสภาพข้อความสำหรับเนื้อหาที่เป็นข้อความเป็น 3 มิติในที่สุด
โปรดเข้าร่วมหากคุณสนใจที่จะร่วมมือกับผู้อื่นเพื่อทำซ้ำงานนี้
Update: Marcus ได้เทรนและอัพโหลดโมเดลการทำงานไปที่ ? กอดหน้า!
StabilityAI, โปรแกรม A16Z Open Source AI Grant และ ? Huggingface สำหรับการสนับสนุนที่มีน้ำใจตลอดจนผู้สนับสนุนอื่นๆ ของฉัน เพื่อให้ฉันมีอิสระในการวิจัยปัญญาประดิษฐ์แบบโอเพ่นซอร์สในปัจจุบัน
Einops ที่ทำให้ชีวิตของฉันง่ายขึ้น
Marcus สำหรับการตรวจสอบโค้ดเบื้องต้น (ชี้ให้เห็นคุณสมบัติที่ได้รับที่ขาดหายไป) รวมถึงดำเนินการทดสอบแบบ end-to-end ครั้งแรกที่ประสบความสำเร็จ
Marcus สำหรับการฝึกอบรมคอลเลกชันรูปทรงที่มีเงื่อนไขบนฉลากที่ประสบความสำเร็จเป็นครั้งแรก
Quexi Ma สำหรับการค้นหาข้อบกพร่องมากมายด้วยการจัดการ eos อัตโนมัติ
Yingtian เพื่อค้นหาจุดบกพร่องด้วยการเบลอตำแหน่งแบบเกาส์เซียนเพื่อทำให้ฉลากเชิงพื้นที่เรียบขึ้น
มาร์คัสทำการทดลองอีกครั้งเพื่อยืนยันว่ามีความเป็นไปได้ที่จะขยายระบบจากสามเหลี่ยมเป็นสี่ส่วน
Marcus สำหรับการระบุปัญหาเกี่ยวกับการปรับสภาพข้อความและดำเนินการทดสอบทั้งหมดที่นำไปสู่การแก้ไข
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d asset สำหรับการสังเคราะห์รูปร่าง 3 มิติที่มีเงื่อนไขข้อความ เพียงตั้งค่า condition_on_text = True บน MeshTransformer ของคุณ จากนั้นส่งผ่านรายการคำอธิบายของคุณเป็นอาร์กิวเมนต์คีย์เวิร์ด texts
อดีต.
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
) หากคุณต้องการสร้างโทเค็นเมช เพื่อใช้ในหม้อแปลงหลายรูปแบบของคุณ เพียงเรียกใช้ .tokenize บนตัวเข้ารหัสอัตโนมัติของคุณ (หรือวิธีการเดียวกันบนอินสแตนซ์ตัวฝึกการเข้ารหัสอัตโนมัติสำหรับโมเดลที่ปรับให้เรียบแบบเอกซ์โปเนนเชียล)
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) ที่รูทโปรเจ็กต์ ให้รัน
$ cp .env.sample .envโปรแกรมเข้ารหัสอัตโนมัติ
face_edges โดยตรงจากใบหน้าและจุดยอดโดยอัตโนมัติ หม้อแปลงไฟฟ้า
เครื่องห่อเทรนเนอร์พร้อมตัวเร่งความเร็ว hf
การปรับสภาพข้อความโดยใช้ไลบรารี CFG ของตัวเอง
หม้อแปลงแบบลำดับชั้น (ใช้หม้อแปลง RQ)
แก้ไขแคชในเลเยอร์ gateloop แบบง่ายใน repo อื่น
ความสนใจในท้องถิ่น
แก้ไขการแคช kv สำหรับหม้อแปลงแบบลำดับชั้นแบบสองขั้นตอน - เร็วขึ้น 7 เท่าในขณะนี้ และเร็วกว่าหม้อแปลงแบบไม่มีลำดับชั้นดั้งเดิม
แก้ไขแคชสำหรับเลเยอร์ Gateloop
อนุญาตให้ปรับแต่งขนาดแบบจำลองของเครือข่ายความสนใจแบบละเอียดและแบบหยาบ
ค้นหาว่าโปรแกรมเข้ารหัสอัตโนมัติจำเป็นจริงๆ หรือไม่ - จำเป็น การระเหยอยู่ในกระดาษ
ทำให้หม้อแปลงมีประสิทธิภาพ
ตัวเลือกการถอดรหัสเก็งกำไร
ใช้เวลาหนึ่งวันกับเอกสาร
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

