RoboFlamingo
1.0.0
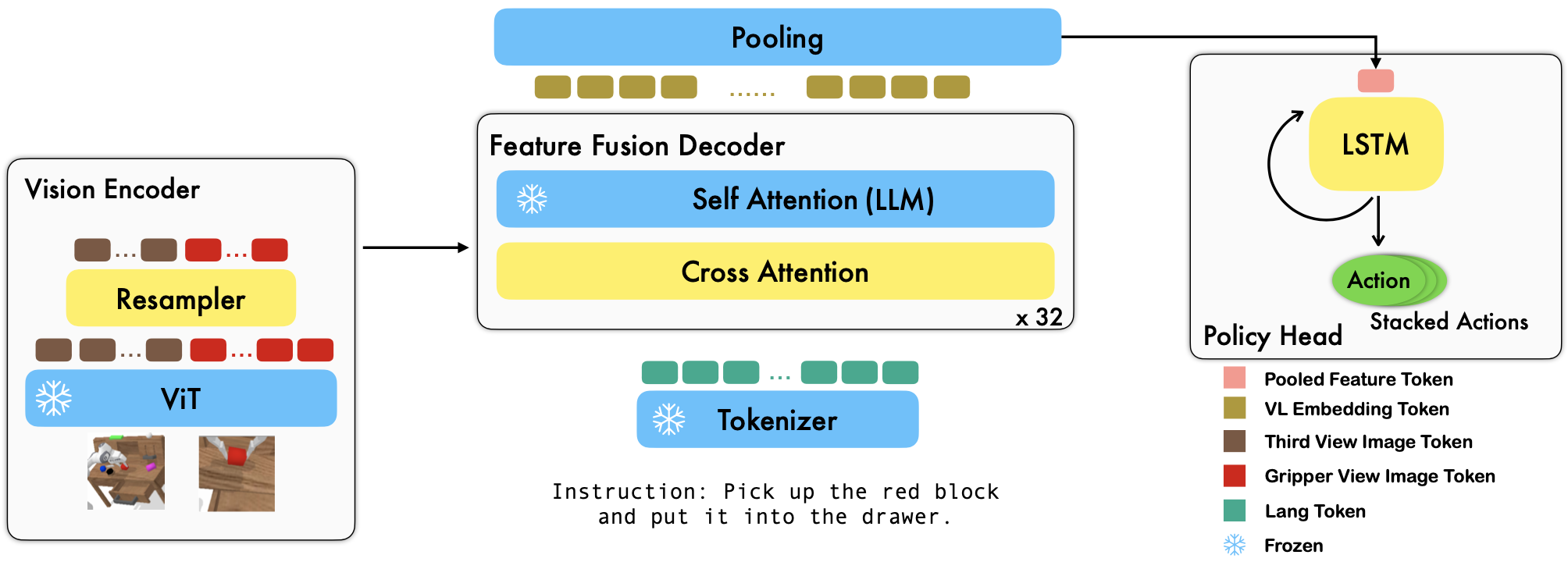
RoboFlamingo เป็นเฟรมเวิร์กการเรียนรู้หุ่นยนต์ที่ใช้ VLM ที่ได้รับการฝึกอบรมล่วงหน้า ซึ่งเรียนรู้ทักษะหุ่นยนต์ที่มีเงื่อนไขทางภาษาที่หลากหลายโดยการปรับแต่งชุดข้อมูลเลียนแบบรูปแบบอิสระออฟไลน์อย่างละเอียด ด้วยการก้าวข้ามประสิทธิภาพที่ล้ำสมัยด้วยอัตรากำไรขั้นต้นที่สูงจากเกณฑ์มาตรฐาน CALVIN เราแสดงให้เห็นว่า RoboFlamingo สามารถเป็นทางเลือกที่มีประสิทธิภาพและแข่งขันได้ในการปรับ VLM ให้เข้ากับการควบคุมหุ่นยนต์ ผลการทดลองที่ครอบคลุมของเรายังเผยให้เห็นข้อสรุปที่น่าสนใจหลายประการเกี่ยวกับพฤติกรรมของ VLM ที่ได้รับการฝึกอบรมล่วงหน้าต่างๆ ในงานการจัดการ RoboFlamingo สามารถฝึกอบรมหรือประเมินผลได้บนเซิร์ฟเวอร์ GPU เดียว (ข้อกำหนดหน่วยความจำ GPU ขึ้นอยู่กับขนาดของรุ่น) และเราเชื่อว่า RoboFlamingo มีศักยภาพที่จะเป็นโซลูชันที่คุ้มค่าและใช้งานง่ายสำหรับการจัดการหุ่นยนต์ เสริมศักยภาพทุกคนด้วย ความสามารถในการปรับแต่งนโยบายวิทยาการหุ่นยนต์ของตนเอง
นี่เป็นแหล่งซื้อคืนโค้ดอย่างเป็นทางการสำหรับโมเดลพื้นฐานภาษาวิสัยทัศน์ในฐานะผู้เลียนแบบหุ่นยนต์ที่มีประสิทธิภาพ
การทดลองทั้งหมดของเราดำเนินการบนเซิร์ฟเวอร์ GPU เดียวที่มี GPU Nvidia A100 (80G) 8 ตัว
โมเดลที่ได้รับการฝึกล่วงหน้ามีอยู่ใน Hugging Face
เรารองรับตัวเข้ารหัสการมองเห็นที่ได้รับการฝึกอบรมล่วงหน้าจากแพ็คเกจ OpenCLIP ซึ่งรวมถึงโมเดลที่ได้รับการฝึกอบรมล่วงหน้าของ OpenAI นอกจากนี้เรายังรองรับโมเดลภาษาที่ได้รับการฝึกอบรมล่วงหน้าจากแพ็คเกจ transformers เช่น โมเดล MPT, RedPajama, LLaMA, OPT, GPT-Neo, GPT-J และ Pythia
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) อาร์กิวเมนต์ cross_attn_every_n_layers ควบคุมความถี่ในการใช้เลเยอร์การสนใจข้าม และควรสอดคล้องกับ VLM อาร์กิวเมนต์ decoder_type ควบคุมประเภทของตัวถอดรหัส ขณะนี้เรารองรับ lstm , fc , diffusion (มีข้อบกพร่องสำหรับ dataloader) และ GPT
เรารายงานผลลัพธ์ตามเกณฑ์มาตรฐาน CALVIN
| วิธี | ข้อมูลการฝึกอบรม | ทดสอบแยก | 1 | 2 | 3 | 4 | 5 | เฉลี่ยเลน |
|---|---|---|---|---|---|---|---|---|
| เอ็มซิล | เอบีซีดี (ฉบับเต็ม) | ดี | 0.373 | 0.027 | 0.002 | 0.000 | 0.000 | 0.40 |
| ฮัลค์ | เอบีซีดี (ฉบับเต็ม) | ดี | 0.889 | 0.733 | 0.587 | 0.475 | 0.383 | 3.06 |
| HULC (ฝึกอบรมใหม่) | ABCD (หลาง) | ดี | 0.892 | 0.701 | 0.548 | 0.420 | 0.335 | 2.90 |
| RT-1 (ฝึกใหม่) | ABCD (หลาง) | ดี | 0.844 | 0.617 | 0.438 | 0.323 | 0.227 | 2.45 |
| ของเรา | ABCD (หลาง) | ดี | 0.964 | 0.896 | 0.824 | 0.740 | 0.66 | 4.09 |
| เอ็มซิล | เอบีซี (เต็ม) | ดี | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0.31 |
| ฮัลค์ | เอบีซี (เต็ม) | ดี | 0.418 | 0.165 | 0.057 | 0.019 | 0.011 | 0.67 |
| RT-1 (ฝึกใหม่) | เอบีซี (หลาง) | ดี | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 |
| ของเรา | เอบีซี (หลาง) | ดี | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.48 |
| ฮัลค์ | เอบีซีดี (ฉบับเต็ม) | D (เพิ่มคุณค่า) | 0.715 | 0.470 | 0.308 | 0.199 | 0.130 | 1.82 |
| RT-1 (ฝึกใหม่) | ABCD (หลาง) | D (เพิ่มคุณค่า) | 0.494 | 0.222 | 0.086 | 0.036 | 0.017 | 0.86 |
| ของเรา | ABCD (หลาง) | D (เพิ่มคุณค่า) | 0.720 | 0.480 | 0.299 | 0.211 | 0.144 | 1.85 |
| ของเรา (freeze-emb) | ABCD (หลาง) | D (เพิ่มคุณค่า) | 0.737 | 0.530 | 0.385 | 0.275 | 0.192 | 2.12 |
ทำตามคำแนะนำใน OpenFlamingo และ CALVIN เพื่อดาวน์โหลดชุดข้อมูลที่จำเป็นและโมเดล VLM ที่ได้รับการฝึกล่วงหน้า
ดาวน์โหลดชุดข้อมูล CALVIN เลือกแยกด้วย:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugดาวน์โหลดโมเดล OpenFlamingo ที่วางจำหน่าย:
| #พารามิเตอร์ | แบบจำลองภาษา | ตัวเข้ารหัสการมองเห็น | ช่วงเวลา Xattn* | COCO ไซเดอร์ 4 ช็อต | VQAv2 ความแม่นยำ 4 ช็อต | เฉลี่ยเลน | ตุ้มน้ำหนัก |
|---|---|---|---|---|---|---|---|
| 3B | อนัส-awadalla/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | 77.3 | 45.8 | 3.94 | ลิงค์ |
| 3B | อนัส-awadalla/mpt-1b-redpajama-200b-ดอลลี่ | openai CLIP ViT-L/14 | 1 | 82.7 | 45.7 | 4.09 | ลิงค์ |
| 4B | ร่วมกันคอมพิวเตอร์/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81.8 | 49.0 | 3.67 | ลิงค์ |
| 4B | togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85.8 | 49.0 | 3.79 | ลิงค์ |
| 9B | อนัส-awadalla/mpt-7b | openai CLIP ViT-L/14 | 4 | 89.0 | 54.8 | 3.97 | ลิงค์ |
แทนที่ ${lang_encoder_path} และ ${tokenizer_path} ของพจนานุกรมเส้นทาง (เช่น mpt_dict ) ใน robot_flamingo/models/factory.py สำหรับ VLM ที่ได้รับการฝึกล่วงหน้าแต่ละรายการด้วยเส้นทางของคุณเอง
โคลนที่เก็บนี้
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
ติดตั้งแพ็คเกจที่จำเป็น:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} เป็นเส้นทางไปยังชุดข้อมูล CALVIN
${lm_path} เป็นเส้นทางไปยัง LLM ที่ได้รับการฝึกอบรมล่วงหน้า
${tokenizer_path} เป็นเส้นทางไปยังโทเค็น VLM
${openflamingo_checkpoint} เป็นเส้นทางไปยังโมเดลที่ผ่านการฝึกอบรมล่วงหน้าของ OpenFlamingo
${log_file} คือเส้นทางไปยังไฟล์บันทึก
นอกจากนี้เรายังจัดเตรียม robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash เพื่อเริ่มการฝึกอบรมอีกด้วย การทุบตีนี้จะปรับแต่งเวอร์ชัน MPT-3B-IFT ของโมเดล OpenFlamingo ซึ่งมีไฮเปอร์พารามิเตอร์ เริ่มต้น เพื่อฝึกโมเดล และสอดคล้องกับผลลัพธ์ที่ดีที่สุดในรายงาน
python eval_ckpts.py
ด้วยการเพิ่มชื่อจุดตรวจสอบและไดเร็กทอรีลงใน eval_ckpts.py สคริปต์จะโหลดโมเดลและประเมินผลโดยอัตโนมัติ ตัวอย่างเช่น หากคุณต้องการประเมินจุดตรวจสอบที่เส้นทาง 'your-checkpoint-path' คุณสามารถแก้ไขตัวแปร ckpt_dir และ ckpt_names ใน eval_ckpts.py และผลการประเมินจะถูกบันทึกเป็น 'logs/your-checkpoint-prefix บันทึก'.
ผลลัพธ์ที่แสดงด้านล่างบ่งชี้ว่าการฝึกอบรมร่วมสามารถรักษาความสามารถส่วนใหญ่ของแกนหลัก VLM ในงาน VL ในขณะที่สูญเสียประสิทธิภาพเล็กน้อยในงานหุ่นยนต์
ใช้
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
เพื่อเปิดตัว RoboFlamingo ฝึกร่วมกับ CoCO, VQAV2 และ CALVIN คุณควรอัปเดตเส้นทาง CoCO และ VQA ใน get_coco_dataset และ get_vqa_dataset ใน robot_flamingo/data/data.py
| แยก | เอสอาร์ 1 | เอสอาร์ 2 | เอสอาร์ 3 | เอสอาร์ 4 | เอสอาร์ 5 | เฉลี่ยเลน |
|---|---|---|---|---|---|---|
| ร่วมรถไฟ | เอบีซี -> ง | 82.9% | 63.6% | 45.3% | 32.1% | 23.4% |
| ปรับแต่ง | เอบีซี -> ง | 82.4% | 61.9% | 46.6% | 33.1% | 23.5% |
| ร่วมรถไฟ | เอบีซี->ดี | 95.7% | 85.8% | 73.7% | 64.5% | 56.1% |
| ปรับแต่ง | เอบีซี->ดี | 96.4% | 89.6% | 82.4% | 74.0% | 66.2% |
| ร่วมรถไฟ | ABCD->D (เสริมคุณค่า) | 67.8% | 45.2% | 29.4% | 18.9% | 11.7% |
| ปรับแต่ง | ABCD->D (เสริมคุณค่า) | 72.0% | 48.0% | 29.9% | 21.1% | 14.4% |
| โกโก้ | วีคิวเอ | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| เบลอ-1 | เบลอ-2 | เบลอ-3 | เบลอ-4 | ดาวตก | ROUGE_L | ไซเดอร์ | เครื่องเทศ | บัญชี | |
| การปรับแต่งแบบละเอียด (3B, ซีโร่ช็อต) | 0.156 | 0.051 | 0.018 | 0.007 | 0.038 | 0.148 | 0.004 | 0.006 | 4.09 |
| การปรับแต่งแบบละเอียด (3B, 4 ช็อต) | 0.166 | 0.056 | 0.020 | 0.008 | 0.042 | 0.158 | 0.004 | 0.008 | 3.87 |
| รถไฟร่วม (3B, ซีโร่ช็อต) | 0.225 | 0.158 | 0.107 | 0.072 | 0.124 | 0.334 | 0.345 | 0.085 | 36.37 |
| นกฟลามิงโก้ดั้งเดิม (80B ปรับแต่งอย่างละเอียด) | - | - | - | - | - | - | 1.381 | - | 82.0 |
โลโก้ถูกสร้างขึ้นโดยใช้ MidJourney
งานนี้ใช้โค้ดจากโครงการโอเพ่นซอร์สและชุดข้อมูลต่อไปนี้:
ต้นฉบับ: https://github.com/mees/calvin ใบอนุญาต: MIT
ต้นฉบับ: https://github.com/openai/CLIP ใบอนุญาต: MIT
ต้นฉบับ: https://github.com/mlfoundations/open_flamingo ใบอนุญาต: MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


