RobustSAM
1.0.0
พื้นที่เก็บข้อมูลอย่างเป็นทางการสำหรับ RobustSAM: แบ่งส่วนสิ่งใดก็ตามที่แข็งแกร่งบนรูปภาพที่เสื่อมคุณภาพ
หน้าโครงการ | กระดาษ | วิดีโอ | ชุดข้อมูล
ส.ค. 2024: คุณสามารถดูการ์ดโมเดล Hugging Face และการสาธิตที่สร้างโดย @jadechoghari เพื่อการใช้งานที่ง่ายขึ้นผ่านลิงก์นี้
กรกฎาคม 2024: รหัสการฝึกอบรม ข้อมูล และจุดตรวจสอบแบบจำลองสำหรับแกนหลัก ViT ต่างๆ ได้รับการเผยแพร่แล้ว!
มิถุนายน 2024: เปิดตัวรหัสการอนุมานแล้ว!
กุมภาพันธ์ 2024: RobustSAM ได้รับการยอมรับใน CVPR 2024!
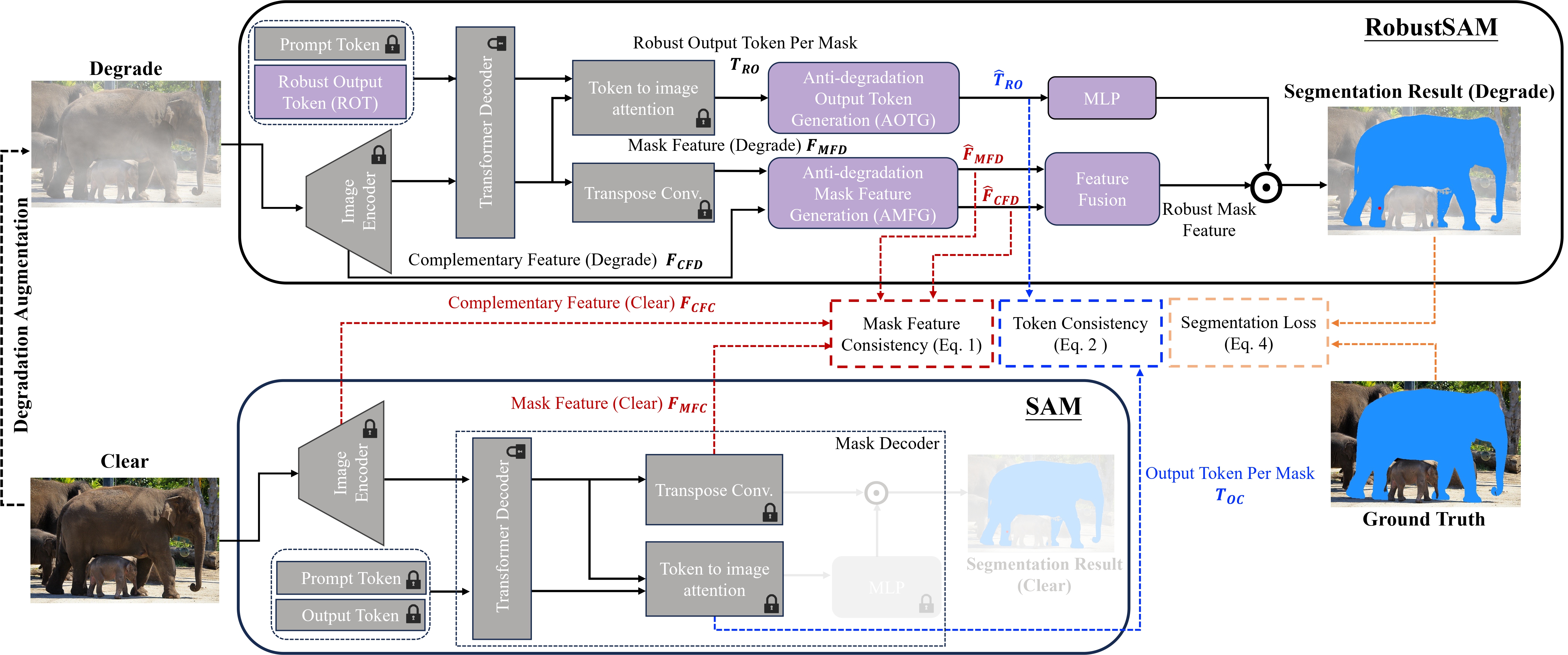
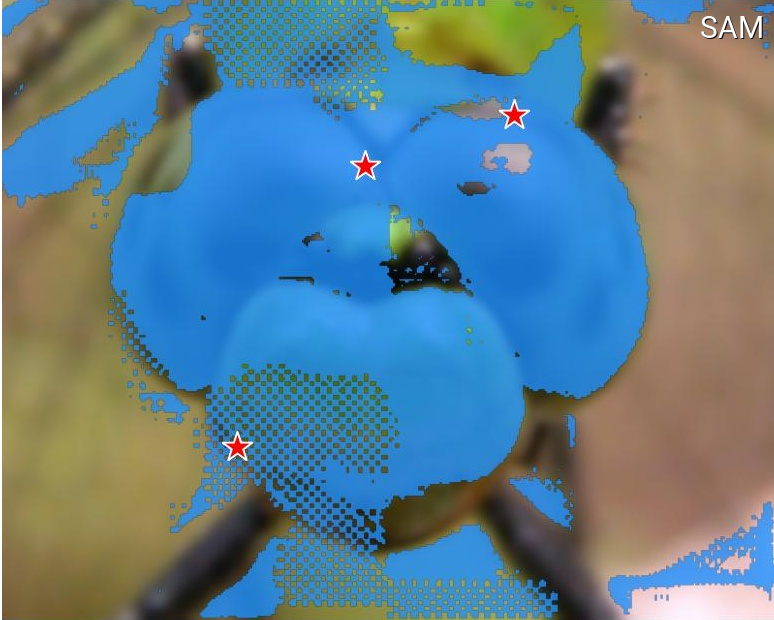
Segment Anything Model (SAM) ได้กลายเป็นแนวทางการเปลี่ยนแปลงในการแบ่งส่วนรูปภาพ โดยได้รับการยกย่องจากความสามารถในการแบ่งส่วนแบบ Zero-shot ที่แข็งแกร่งและระบบแจ้งที่ยืดหยุ่น อย่างไรก็ตาม ประสิทธิภาพการทำงานถูกท้าทายด้วยภาพที่มีคุณภาพลดลง เพื่อจัดการกับข้อจำกัดนี้ เราขอเสนอ Robust Segment Anything Model (RobustSAM) ซึ่งช่วยเพิ่มประสิทธิภาพการทำงานของ SAM บนรูปภาพคุณภาพต่ำ ในขณะที่ยังคงรักษาความรวดเร็วและภาพรวมเป็นศูนย์
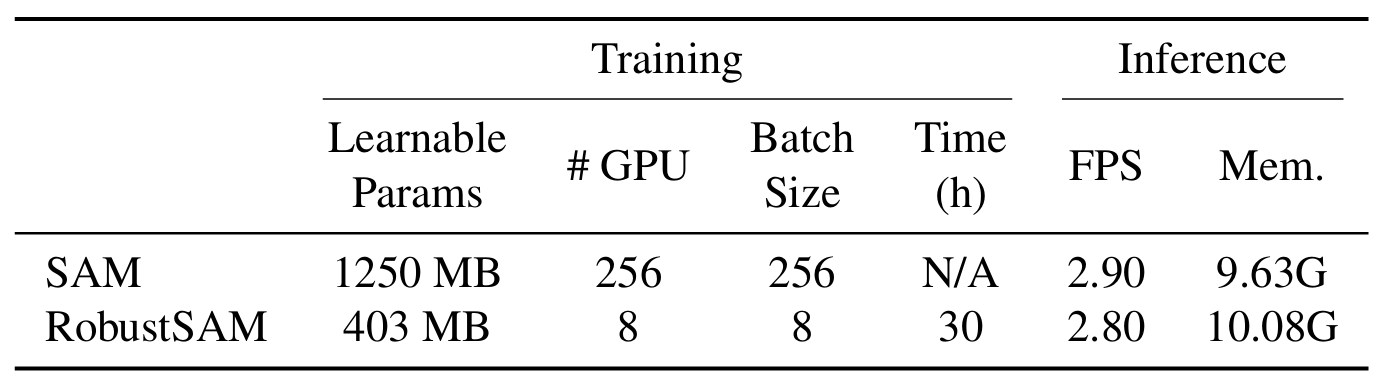
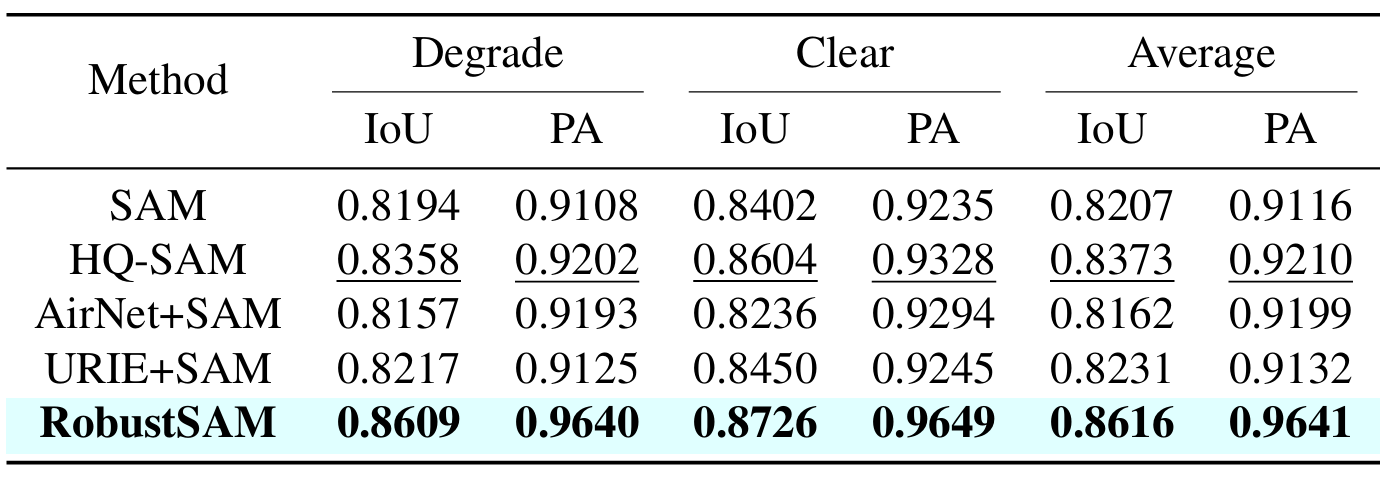
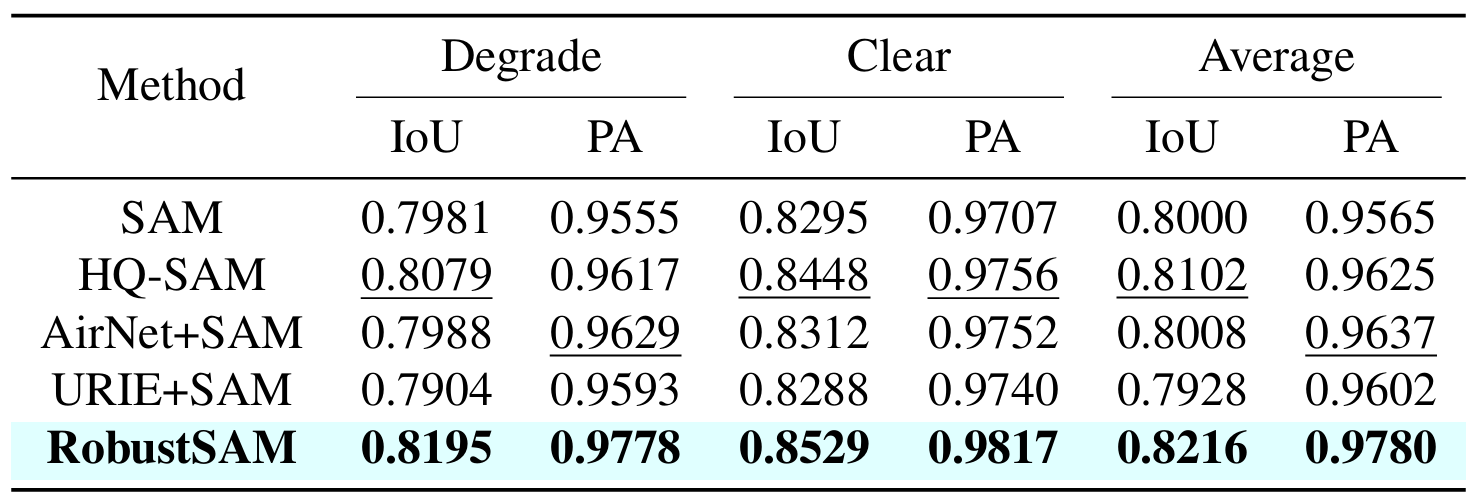
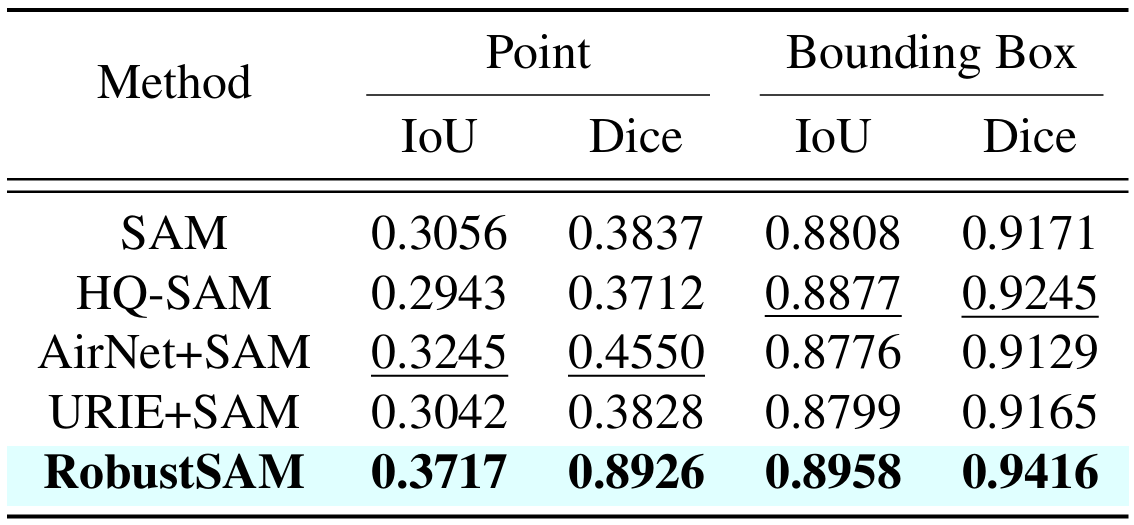
วิธีการของเราใช้ประโยชน์จากโมเดล SAM ที่ได้รับการฝึกอบรมล่วงหน้าโดยเพิ่มพารามิเตอร์เพียงเล็กน้อยและข้อกำหนดในการคำนวณเท่านั้น พารามิเตอร์เพิ่มเติมของ RobustSAM สามารถปรับให้เหมาะสมได้ภายใน 30 ชั่วโมงบน GPU 8 ตัว ซึ่งแสดงให้เห็นถึงความเป็นไปได้และการใช้งานได้จริงสำหรับห้องปฏิบัติการวิจัยทั่วไป นอกจากนี้เรายังแนะนำชุดข้อมูล Robust-Seg ซึ่งเป็นคอลเลกชันของคู่อิมเมจมาสก์ 688K พร้อมการย่อยสลายที่แตกต่างกันซึ่งออกแบบมาเพื่อฝึกและประเมินแบบจำลองของเราอย่างเหมาะสมที่สุด การทดลองที่ครอบคลุมในงานแบ่งเซ็กเมนต์และชุดข้อมูลต่างๆ ยืนยันประสิทธิภาพที่เหนือกว่าของ RobustSAM โดยเฉพาะอย่างยิ่งภายใต้สภาวะที่ไม่มีช็อต ซึ่งตอกย้ำศักยภาพสำหรับการใช้งานในโลกแห่งความเป็นจริงอย่างกว้างขวาง นอกจากนี้ วิธีการของเรายังแสดงให้เห็นประสิทธิภาพในการปรับปรุงประสิทธิภาพของงานดาวน์สตรีมที่ใช้ SAM เช่น การลดความเบลอของภาพเดี่ยวและการลบภาพเบลอได้อย่างมีประสิทธิภาพ
สร้างสภาพแวดล้อม conda และเปิดใช้งาน
conda create --name robustsam python=3.10 -y conda activate robustsam
โคลนและเข้าสู่ไดเร็กทอรี repo
git clone https://github.com/robustsam/RobustSAM cd RobustSAM
ใช้คำสั่งด้านล่างเพื่อตรวจสอบเวอร์ชัน CUDA ของคุณ
nvidia-smi
แทนที่เวอร์ชัน CUDA ด้วยคำสั่งของคุณด้านล่าง
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu[$YOUR_CUDA_VERSION] # For example: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 # cu117 = CUDA_version_11.7
ติดตั้งการพึ่งพาที่เหลืออยู่
pip install -r requirements.txt
ดาวน์โหลดจุดตรวจสอบ RobustSAM ที่ได้รับการฝึกล่วงหน้าในขนาดต่างๆ และวางลงในไดเร็กทอรีปัจจุบัน
จุดตรวจ ViT-B RobustSAM
จุดตรวจ ViT-L RobustSAM
จุดตรวจ ViT-H RobustSAM
เปลี่ยนไดเร็กทอรีปัจจุบันเป็นไดเร็กทอรี "data"
cd data
ดาวน์โหลด train, val, test และชุดข้อมูล COCO & LVIS เพิ่มเติม (หมายเหตุ: รูปภาพในชุดข้อมูล Train, Val และ Test ประกอบด้วยรูปภาพจาก LVIS, MSRA10K, ThinObject-5k, NDD20, STREETS และ FSS-1000)
bash download.sh
มีเพียงภาพที่คมชัดที่ดาวน์โหลดในขั้นตอนก่อนหน้า ใช้คำสั่งด้านล่างเพื่อสร้างรูปภาพที่เสื่อมคุณภาพที่สอดคล้องกัน
bash gen_data.sh
หากคุณต้องการฝึกตั้งแต่เริ่มต้น ให้ใช้คำสั่งด้านล่าง
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l
หากต้องการฝึกจากด่านฝึกให้ใช้คำสั่งด้านล่าง
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] --load_model [$CHECKPOINT_PATH] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l --load_model robustsam_checkpoint_l.pth
python gradio_app.py
เราได้เตรียมรูปภาพบางส่วนไว้ในโฟลเดอร์ demo_images เพื่อวัตถุประสงค์ในการสาธิต นอกจากนี้ยังมีโหมดพร้อมท์สองโหมดให้เลือก (พร้อมท์กล่องและพร้อมท์ชี้)
สำหรับพรอมต์กล่อง:
python eval.py --bbox --model_size l
สำหรับพรอมต์จุด:
python eval.py --model_size l
ตามค่าเริ่มต้น ผลการสาธิตจะถูกบันทึกไปที่ demo_result/[$PROMPT_TYPE]
 |  |
 |  |

หากคุณพบว่างานนี้มีประโยชน์ โปรดพิจารณาอ้างอิงถึงเรา!
@inproceedings{chen2024robustsam, title={RobustSAM: Segment Anything Robustly on Degraded Images}, author={Chen, Wei-Ting และ Vong, Yu-Jiet และ Kuo, Sy-Yen และ Ma, Sizhou และ Wang, Jian}, วารสาร= {CVPR} ปี={2024}}เราขอขอบคุณผู้เขียน SAM ซึ่งเป็นที่มาของ repo ของเรา


