algebraic nnhw
1.0.0
พื้นที่เก็บข้อมูลนี้ประกอบด้วยซอร์สโค้ดสำหรับสถาปัตยกรรมฮาร์ดแวร์ ML ที่ต้องใช้เกือบครึ่งหนึ่งของจำนวนหน่วยตัวคูณเพื่อให้ได้ประสิทธิภาพเดียวกัน โดยการเรียกใช้อัลกอริธึมผลิตภัณฑ์ภายในทางเลือกที่แลกเปลี่ยนเกือบครึ่งหนึ่งของการคูณสำหรับการเพิ่มบิตความกว้างต่ำราคาถูก ในขณะที่ยังคงให้ผลลัพธ์ที่เหมือนกัน เป็นผลิตภัณฑ์ภายในทั่วไป สิ่งนี้จะเพิ่มปริมาณงานทางทฤษฎีและขีดจำกัดประสิทธิภาพการประมวลผลของตัวเร่งความเร็ว ML ดูสิ่งพิมพ์วารสารต่อไปนี้สำหรับรายละเอียดทั้งหมด:
TE Pogue และ N. Nicolici "อัลกอริธึมและสถาปัตยกรรมผลิตภัณฑ์ภายในที่รวดเร็วสำหรับตัวเร่งเครือข่ายประสาทเทียมระดับลึก" ในธุรกรรม IEEE บนคอมพิวเตอร์ ฉบับที่ 1 73, ไม่ใช่. 2 หน้า 495-509 ก.พ. 2024 ดอย: 10.1109/TC.2023.3334140
URL บทความ: https://ieeexplore.ieee.org/document/10323219
เวอร์ชันแบบเปิด: https://arxiv.org/abs/2311.12224
บทคัดย่อ: เราแนะนำอัลกอริธึมใหม่ที่เรียกว่า Free-pipeline Fast Inner Product (FFIP) และสถาปัตยกรรมฮาร์ดแวร์ที่ปรับปรุงอัลกอริธึมผลิตภัณฑ์ภายในแบบเร็ว (FIP) ที่ยังไม่ได้สำรวจซึ่งเสนอโดย Winograd ในปี 1968 แตกต่างจากอัลกอริธึมการกรองขั้นต่ำของ Winograd ที่ไม่เกี่ยวข้องสำหรับ Convolutional Layers, FIP สามารถใช้ได้กับเลเยอร์โมเดล Machine Learning (ML) ทั้งหมดที่สามารถแยกย่อยเป็นการคูณเมทริกซ์เป็นหลัก รวมถึงการเชื่อมต่อแบบสมบูรณ์ การ Convolutional การเกิดขึ้นซ้ำ และ Attention/Transformer ชั้น เราใช้ FIP เป็นครั้งแรกในตัวเร่ง ML จากนั้นนำเสนออัลกอริธึม FFIP และสถาปัตยกรรมทั่วไปของเราซึ่งปรับปรุงความถี่สัญญาณนาฬิกาของ FIP โดยธรรมชาติ และผลที่ตามมาก็คือปริมาณงานสำหรับต้นทุนฮาร์ดแวร์ที่ใกล้เคียงกัน สุดท้ายนี้ เราสนับสนุนการเพิ่มประสิทธิภาพเฉพาะ ML สำหรับอัลกอริทึมและสถาปัตยกรรม FIP และ FFIP เราแสดงให้เห็นว่า FFIP สามารถรวมเข้ากับตัวเร่งความเร็ว ML ของอาร์เรย์ซิสโตลิกแบบจุดคงที่แบบดั้งเดิมได้อย่างราบรื่น เพื่อให้ได้ปริมาณงานเดียวกันด้วยจำนวนหน่วยการสะสมทวีคูณ (MAC) เพียงครึ่งหนึ่ง หรือสามารถเพิ่มขนาดอาร์เรย์ซิสโตลิกสูงสุดเป็นสองเท่าที่สามารถติดตั้งบนอุปกรณ์ที่มี งบประมาณฮาร์ดแวร์คงที่ การใช้งาน FFIP ของเราสำหรับโมเดล ML ที่ไม่กระจัดกระจายซึ่งมีอินพุตแบบจุดคงที่ 8 ถึง 16 บิตทำให้ได้รับทรูพุตและประสิทธิภาพการประมวลผลที่สูงกว่าโซลูชันที่ดีที่สุดในระดับเดียวกันก่อนหน้านี้บนแพลตฟอร์มการประมวลผลประเภทเดียวกัน
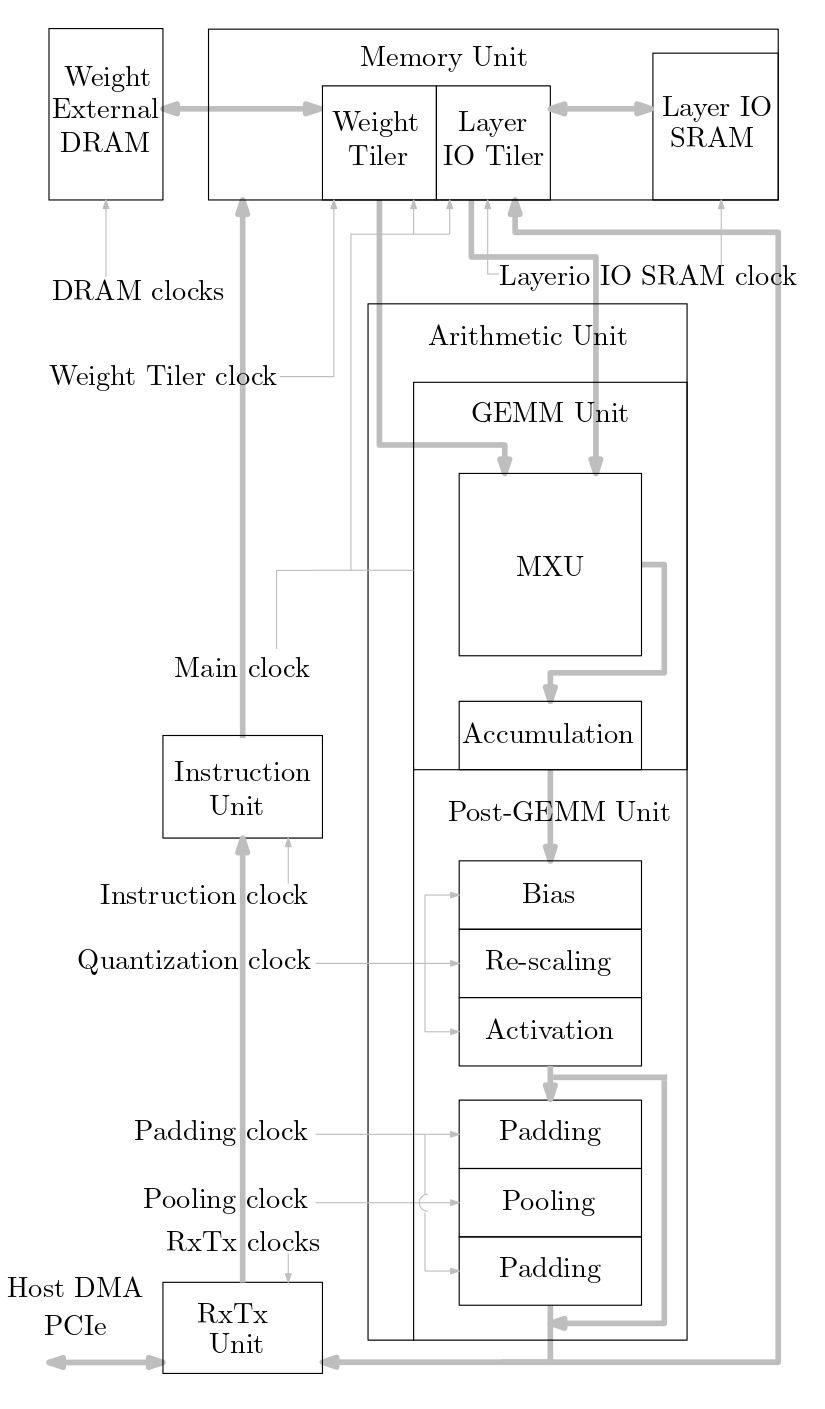
แผนภาพต่อไปนี้แสดงภาพรวมของระบบเร่งความเร็ว ML ที่นำมาใช้ในซอร์สโค้ดนี้:
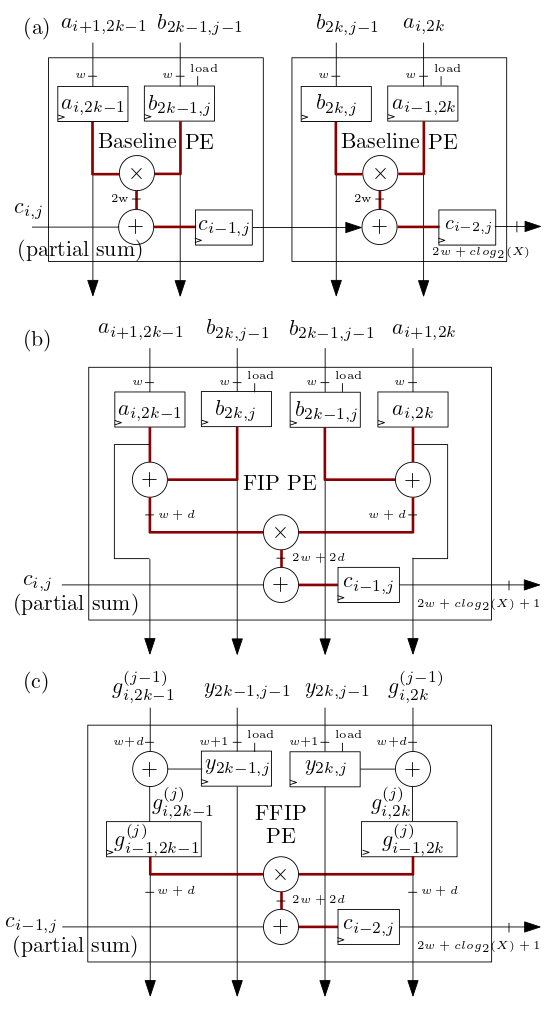
องค์ประกอบการประมวลผลอาร์เรย์ซิสโตลิก/MXU ของ FIP และ FFIP ที่แสดงด้านล่างใน (b) และ (c) ใช้อัลกอริธึมผลิตภัณฑ์ภายในของ FIP และ FFIP และแต่ละรายการจะให้พลังการคำนวณที่มีประสิทธิภาพเท่ากันกับ PE พื้นฐานสองตัวที่แสดงใน ( ก) รวมกันซึ่งใช้ผลิตภัณฑ์ภายในพื้นฐานเช่นเดียวกับในตัวเร่งความเร็ว ML systolic-array ก่อนหน้า:
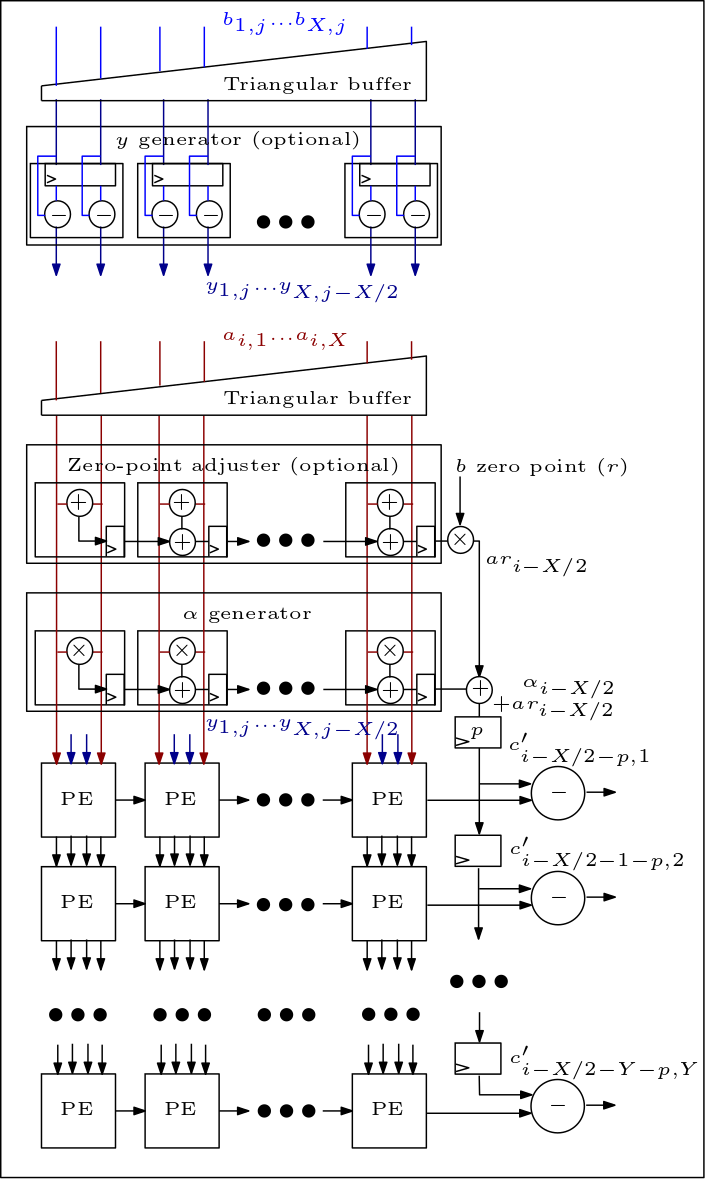
ต่อไปนี้เป็นไดอะแกรมของอาร์เรย์ MXU/ซิสโตลิก และแสดงวิธีการเชื่อมต่อ PE:
องค์กรซอร์สโค้ดมีดังนี้:
ไฟล์ rtl/top/define.svh และ rtl/top/pkg.sv มีพารามิเตอร์ที่กำหนดค่าได้จำนวนหนึ่ง เช่น FIP_METHOD ใน Define.svh ซึ่งกำหนดประเภทอาร์เรย์ซิสโตลิก (พื้นฐาน, FIP หรือ FFIP), SZI และ SZJ ซึ่งกำหนด ความสูง/ความกว้างของอาร์เรย์ซิสโตลิก และ LAYERIO_WIDTH/WEIGHT_WIDTH ซึ่งกำหนดบิตความกว้างอินพุต
ไดเรกทอรี rtl/arith ประกอบด้วย mxu.sv และ mac_array.sv ซึ่งมี RTL สำหรับพื้นฐาน, FIP และสถาปัตยกรรมอาร์เรย์ซิสโตลิก FFIP (ขึ้นอยู่กับค่าของพารามิเตอร์ FIP_METHOD)


