toyCarIRL
1.0.0
การเรียนรู้แบบเสริมกำลัง (RL) เป็นรูปแบบการเรียนรู้แบบลองผิดลองถูกขั้นพื้นฐานและใช้งานง่ายที่สุด โดยเป็นวิธีการที่สิ่งมีชีวิตส่วนใหญ่ที่มีความสามารถในการคิดบางรูปแบบเรียนรู้ มักเรียกกันว่าการเรียนรู้จากการสำรวจ เป็นวิธีการที่ทารกเกิดใหม่เรียนรู้ที่จะเริ่มก้าวแรก นั่นคือโดยลงมือสุ่มในขั้นต้น แล้วค่อย ๆ ค้นหาการกระทำที่นำไปสู่การเดินไปข้างหน้า
หมายเหตุ โพสต์นี้ถือว่ามีความเข้าใจที่ดีเกี่ยวกับกรอบการเรียนรู้การเสริมกำลัง โปรดทำความคุ้นเคยกับ RL จนถึงสัปดาห์ที่ 5 และ 6 ของหลักสูตรออนไลน์ที่ยอดเยี่ยม AI_Berkeley
คำถามที่ฉันเอาแต่ถามตัวเองคือ อะไรเป็นแรงผลักดันสำหรับการเรียนรู้ประเภทนี้ อะไรบังคับให้ตัวแทนเรียนรู้พฤติกรรมเฉพาะ ในแบบที่มันทำอยู่ เมื่อเรียนรู้เพิ่มเติมเกี่ยวกับ RL ฉันได้พบกับแนวคิดเรื่อง การให้รางวัล โดยพื้นฐานแล้วตัวแทนจะพยายามเลือกการกระทำของตนในลักษณะที่จะให้รางวัลที่ได้รับจากพฤติกรรมนั้นได้รับการขยายให้สูงสุด ตอนนี้เพื่อให้ตัวแทนดำเนินการพฤติกรรมที่แตกต่างกัน โครงสร้างรางวัลที่ต้องแก้ไข/ใช้ประโยชน์ แต่สมมติว่าเรามีความรู้เกี่ยวกับพฤติกรรมของผู้เชี่ยวชาญเท่านั้น แล้วเราจะประมาณโครงสร้างรางวัลตามพฤติกรรมเฉพาะในสภาพแวดล้อมได้อย่างไร นี่เป็นปัญหาของ การเรียนรู้การเสริมกำลังแบบผกผัน (IRL) โดยที่นโยบายผู้เชี่ยวชาญที่เหมาะสมที่สุด (จริง ๆ แล้วถือว่าเหมาะสมที่สุด) เราต้องการกำหนดโครงสร้างรางวัลพื้นฐาน
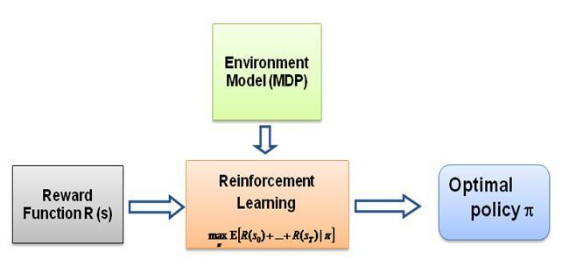
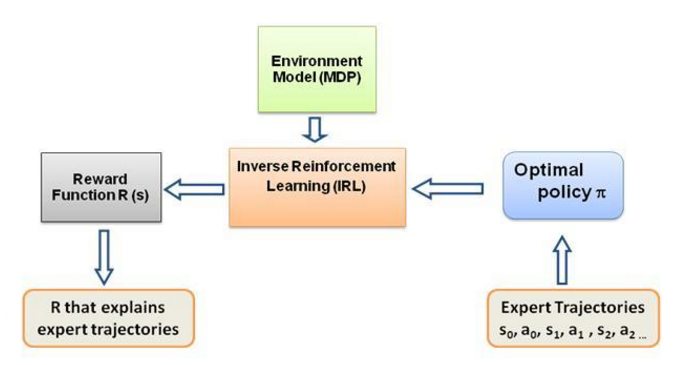
ขอย้ำอีกครั้งว่านี่ไม่ใช่โพสต์บทนำของการเรียนรู้การเสริมแรงแบบผกผัน แต่เป็นบทช่วยสอนเกี่ยวกับวิธีใช้/เขียนโค้ดกรอบการเรียนรู้การเสริมแรงแบบผกผันสำหรับปัญหาของคุณเอง แต่ IRL อยู่ที่แกนกลางของมัน และเป็นสิ่งสำคัญที่ต้องรู้ มันก่อน IRL ได้รับการศึกษาอย่างกว้างขวางในอดีตและมีการพัฒนาอัลกอริธึมสำหรับข้อมูลเพิ่มเติม โปรดดูเอกสาร Ng และ Russell, 2000 และ Abbeel และ Ng, 2004 สำหรับข้อมูลเพิ่มเติม
โพสต์นี้ปรับอัลกอริทึมจาก Abbeel และ Ng, 2004 สำหรับการแก้ปัญหา IRL
แนวคิดที่นี่คือการเขียนโปรแกรมเอเจนต์ง่ายๆ ในโลก 2 มิติที่เต็มไปด้วยอุปสรรคในการคัดลอก/โคลนพฤติกรรมต่างๆ ในสภาพแวดล้อม พฤติกรรมต่างๆ จะถูกป้อนเข้าด้วยความช่วยเหลือจากวิถีผู้เชี่ยวชาญที่กำหนดด้วยตนเองโดยผู้เชี่ยวชาญที่เป็นมนุษย์/คอมพิวเตอร์ รูปแบบการเรียนรู้จากการสาธิตของผู้เชี่ยวชาญนี้เรียกว่าการเรียนรู้การฝึกงานในวรรณกรรมทางวิทยาศาสตร์ โดยแก่นของการเรียนรู้คือการเสริมกำลังแบบผกผัน และเราแค่พยายามหาฟังก์ชันการให้รางวัลที่แตกต่างกันสำหรับพฤติกรรมที่แตกต่างกันเหล่านี้
โดยทั่วไปแล้ว ใช่ เป็นสิ่งเดียวกัน ซึ่งหมายถึงการเรียนรู้จากการสาธิต (LfD) ทั้งสองวิธีเรียนรู้จากการสาธิต แต่เรียนรู้ต่างกัน:
การเรียนรู้การฝึกงานผ่านการเรียนรู้แบบเสริมกำลังแบบผกผันจะพยายาม อนุมานเป้าหมายของครู กล่าวอีกนัยหนึ่ง มันจะเรียนรู้ฟังก์ชันการให้รางวัลจากการสังเกต ซึ่งสามารถนำไปใช้ในการเรียนรู้แบบเสริมกำลังได้ หากพบว่าเป้าหมายคือการตอกตะปูด้วยค้อน ก็จะไม่สนใจการกระพริบตาและรอยขีดข่วนจากครู เนื่องจากไม่เกี่ยวข้องกับเป้าหมาย
การเรียนรู้ด้วยการเลียนแบบ (หรือที่เรียกว่า การโคลนนิ่งเชิงพฤติกรรม) จะพยายาม ลอกเลียนแบบครูโดยตรง สิ่งนี้สามารถทำได้โดยการเรียนรู้แบบมีผู้สอนเพียงอย่างเดียว AI จะพยายามคัดลอกทุกการกระทำ แม้กระทั่งการกระทำที่ไม่เกี่ยวข้อง เช่น การกระพริบตา การข่วน หรือแม้แต่ความผิดพลาด คุณสามารถใช้ RL ที่นี่ได้เช่นกัน แต่ถ้าคุณมีฟังก์ชันการให้รางวัลเท่านั้น
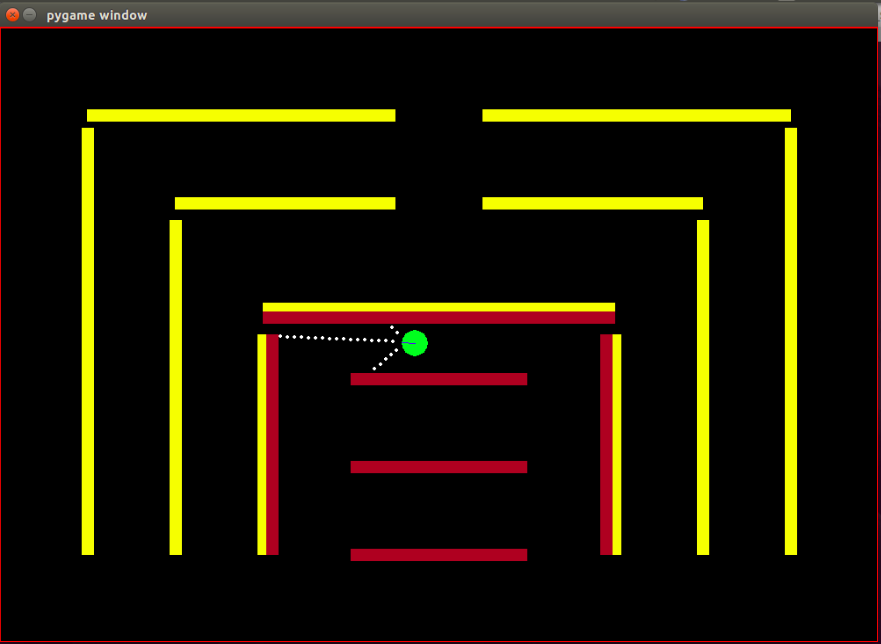
ตัวแทน: ตัวแทนเป็นวงกลมสีเขียวเล็กๆ ที่มีทิศทางที่มุ่งหน้าไปโดยระบุด้วยเส้นสีน้ำเงิน
เซ็นเซอร์: เจ้าหน้าที่ติดตั้งเซ็นเซอร์สีรวมระยะห่าง 3 ตัว และนี่เป็นข้อมูลเดียวที่เจ้าหน้าที่มีเกี่ยวกับสภาพแวดล้อม
State Space: สถานะของตัวแทนประกอบด้วยคุณสมบัติที่สังเกตได้ 8 ประการ -
หมายเหตุ การทำให้เป็นมาตรฐานเสร็จสิ้นเพื่อให้แน่ใจว่าค่าคุณลักษณะที่สังเกตได้ทุกค่าอยู่ในช่วง [0,1] ซึ่งเป็นเงื่อนไขที่จำเป็นสำหรับรางวัลสำหรับอัลกอริทึม IRL ที่จะมาบรรจบกัน
รางวัล: รางวัลหลังจากทุกเฟรมจะถูกคำนวณเป็นชุดค่าผสมเชิงเส้นแบบถ่วงน้ำหนักของค่าคุณสมบัติที่สังเกตได้ในเฟรมนั้น ๆ ในที่นี้ รางวัล r_t ในเฟรมที่ t คำนวณโดยดอทโปรดัคของเวกเตอร์น้ำหนัก w กับเวกเตอร์ของค่าคุณลักษณะในเฟรมที่ t นั่นคือเวกเตอร์สถานะ phi_t เช่นนั้น r_t = w^T x phi_t
การดำเนินการที่ใช้งานได้: ในทุกเฟรมใหม่ เจ้าหน้าที่จะก้าว ไปข้างหน้า โดยอัตโนมัติ การกระทำที่มีอยู่สามารถเลี้ยวเจ้าหน้าที่ไป ทางซ้าย ขวา หรือ ไม่ทำอะไรเลย ที่เป็นก้าวไปข้างหน้าแบบธรรมดา โปรดทราบว่าการกระทำที่หมุนนั้นรวมถึงการเคลื่อนไปข้างหน้าด้วย ไม่ใช่การหมุนแบบแทนที่
อุปสรรค: สภาพแวดล้อมประกอบด้วยผนังแข็งๆ ซึ่งจงใจระบายสีด้วยสีต่างๆ เอเจนต์มีความสามารถในการตรวจจับสีที่ช่วยแยกแยะระหว่างสิ่งกีดขวางประเภทต่างๆ สภาพแวดล้อมได้รับการออกแบบในลักษณะนี้เพื่อให้ทดสอบอัลกอริธึม IRL ได้ง่าย
ตำแหน่งเริ่มต้น (สถานะ) ของบอทได้รับการแก้ไขแล้ว ตามอัลกอริทึม IRL จำเป็นที่สถานะเริ่มต้นจะเหมือนกันสำหรับการวนซ้ำทั้งหมด
โปรดทราบว่าแมตต์ ฮาร์วีย์นำอัลกอริธึม RL มาใช้อย่างสมบูรณ์จากโพสต์นี้โดยมีการเปลี่ยนแปลงเล็กน้อย ดังนั้นจึงสมเหตุสมผลอย่างยิ่งที่จะพูดคุยเกี่ยวกับการเปลี่ยนแปลงที่ฉันทำ แม้ว่าผู้อ่านจะพอใจกับ RL ฉันขอแนะนำให้ดูอย่างรวดเร็ว โพสต์นั้นเพื่อทำความเข้าใจว่าการเรียนรู้แบบเสริมกำลังเกิดขึ้นได้อย่างไร
สภาพแวดล้อมมีการเปลี่ยนแปลงไปอย่างมาก โดยที่เจ้าหน้าที่ไม่เพียงแต่สามารถรับรู้ระยะห่างจากเซ็นเซอร์ทั้ง 3 ตัวเท่านั้น แต่ยังรับรู้ถึงสีของสิ่งกีดขวาง ทำให้แยกแยะระหว่างสิ่งกีดขวางได้ นอกจากนี้ ขณะนี้เอเจนต์มีขนาดเล็กลง และจุดตรวจจับก็อยู่ใกล้ยิ่งขึ้น เพื่อให้ได้ความละเอียดและประสิทธิภาพที่ดีขึ้น อุปสรรคต่างๆ จะต้องได้รับการแก้ไขในตอนนี้ เพื่อลดความซับซ้อนของกระบวนการทดสอบอัลกอริทึม IRL สิ่งนี้อาจนำไปสู่การปรับข้อมูลมากเกินไป แต่ฉันไม่ได้กังวลเกี่ยวกับเรื่องนั้นในขณะนี้ ตามที่กล่าวไว้ข้างต้น ชุดการสังเกตหรือสถานะของตัวแทนได้เพิ่มขึ้นจาก 3 เป็น 8 โดยมีการรวมคุณลักษณะ ข้อขัดข้อง ไว้ในสถานะของตัวแทนด้วย โครงสร้างรางวัลมีการเปลี่ยนแปลงโดยสิ้นเชิง ตอนนี้รางวัลเป็นการผสมผสานเชิงเส้นแบบถ่วงน้ำหนักของคุณสมบัติทั้ง 8 ประการนี้ เจ้าหน้าที่จะไม่ได้รับรางวัล -500 อีกต่อไปเมื่อชนเข้ากับสิ่งกีดขวาง แต่ค่าคุณสมบัติสำหรับ การชน คือ +1 และไม่ชนเป็น 0 และ อยู่ในอัลกอริธึมในการตัดสินใจว่าควรกำหนดน้ำหนักใดให้กับคุณลักษณะนี้โดยพิจารณาจากพฤติกรรมของผู้เชี่ยวชาญ
ตามที่ระบุไว้ในบล็อกของ Matt เป้าหมายที่นี่คือไม่เพียงแค่สอนตัวแทน RL ให้หลีกเลี่ยงอุปสรรค ฉันหมายถึงทำไมต้องยอมรับอะไรเกี่ยวกับโครงสร้างรางวัล ปล่อยให้โครงสร้างรางวัลได้รับการตัดสินใจอย่างสมบูรณ์โดยอัลกอริธึมจากการสาธิตของผู้เชี่ยวชาญ และดูว่าพฤติกรรมใด การตั้งค่ารางวัลพิเศษบรรลุผลสำเร็จ!
คุณสมบัติ หรือ ฟังก์ชันพื้นฐาน phi_i ซึ่งโดยพื้นฐานแล้วสามารถสังเกตได้ในสถานะ คุณลักษณะในปัญหาปัจจุบันมีการกล่าวถึงข้างต้นในส่วนพื้นที่สถานะ เรากำหนดให้ phi(s_t) เป็นผลรวมของความคาดหวังฟีเจอร์ทั้งหมด phi_i ดังนี้:
รางวัล r_t - การรวมกันเชิงเส้นของค่าคุณลักษณะเหล่านี้ที่สังเกตได้ในแต่ละสถานะ s_t
ความคาดหวังของคุณลักษณะ mu(pi) ของนโยบาย pi คือผลรวมของค่าคุณลักษณะที่มีส่วนลด phi(s_t)
ความคาดหวังคุณลักษณะของนโยบายไม่ขึ้นกับน้ำหนัก โดยขึ้นอยู่กับสถานะที่เยี่ยมชมระหว่างการดำเนินการเท่านั้น (ตามนโยบาย) และแกมม่าตัวประกอบส่วนลดเป็นตัวเลขระหว่าง 0 ถึง 1 (เช่น 0.9 ในกรณีของเรา) เพื่อให้ได้ความคาดหวังด้านคุณลักษณะของนโยบาย เราจะต้องดำเนินการตามนโยบายแบบเรียลไทม์กับตัวแทน และบันทึกสถานะที่เยี่ยมชมและค่าคุณลักษณะที่ได้รับ
ความคาดหวังคุณลักษณะนโยบายของผู้เชี่ยวชาญหรือ ความคาดหวังคุณลักษณะของผู้เชี่ยวชาญ mu(pi_E) ได้มาจากการดำเนินการที่ดำเนินการตามพฤติกรรมของผู้เชี่ยวชาญ โดยพื้นฐานแล้วเราจะดำเนินการตามนโยบายนี้และรับความคาดหวังเกี่ยวกับคุณลักษณะเช่นเดียวกับที่เราทำกับนโยบายอื่นๆ ความคาดหวังของฟีเจอร์ของผู้เชี่ยวชาญนั้นมอบให้กับอัลกอริธึม IRL เพื่อค้นหาน้ำหนักที่ฟังก์ชันการให้รางวัลที่สอดคล้องกับน้ำหนักนั้นคล้ายกับฟังก์ชันการให้รางวัลที่ซ่อนอยู่ซึ่งผู้เชี่ยวชาญพยายามเพิ่มให้สูงสุด (ในภาษา RL ปกติ)
ความคาดหวังคุณลักษณะนโยบายแบบสุ่ม - ดำเนินการนโยบายแบบสุ่มและใช้ความคาดหวังคุณลักษณะที่ได้รับเพื่อเริ่มต้น IRL
รักษารายการความคาดหวังคุณลักษณะนโยบายที่เราได้รับหลังจากการวนซ้ำทุกครั้ง
ในช่วงเริ่มต้นเรามีเพียง pi^1 -> ความคาดหวังของคุณสมบัตินโยบายแบบสุ่ม
ค้นหาน้ำหนักชุดแรกของ w^1 โดยการเพิ่มประสิทธิภาพนูน ปัญหาจะคล้ายกับตัวแยกประเภท SVM ซึ่งพยายามให้ป้ายกำกับ +1 แก่คุณสมบัติผู้เชี่ยวชาญ expec และ -1 ป้ายกำกับสำหรับคุณสมบัตินโยบายอื่น ๆ ทั้งหมด expecs.-
เช่นนั้น
เงื่อนไขการสิ้นสุด:
ตอนนี้ เมื่อเราได้รับน้ำหนักหลังจากการเพิ่มประสิทธิภาพซ้ำหนึ่งครั้ง นั่นคือเมื่อเราได้รับฟังก์ชันการให้รางวัลใหม่ เราต้องเรียนรู้นโยบายที่ฟังก์ชันการให้รางวัลนี้ก่อให้เกิด นี่เหมือนกับการพูดว่า ค้นหานโยบายที่พยายามเพิ่มฟังก์ชั่นรางวัลที่ได้รับให้สูงสุด ในการค้นหานโยบายใหม่นี้ เราต้องฝึกอัลกอริธึมการเรียนรู้แบบเสริมแรงด้วยฟังก์ชันการให้รางวัลใหม่นี้ และฝึกจนกว่าค่า Q มาบรรจบกัน เพื่อให้ได้ค่าประมาณของนโยบายที่เหมาะสม
หลังจากที่เราได้เรียนรู้นโยบายใหม่แล้ว เราจะต้องทดสอบนโยบายนี้ทางออนไลน์ เพื่อให้ได้คุณลักษณะที่คาดหวังซึ่งสอดคล้องกับนโยบายใหม่นี้ จากนั้นเราจะเพิ่มความคาดหวังของฟีเจอร์ใหม่เหล่านี้ลงในรายการความคาดหวังของฟีเจอร์ของเรา และดำเนินการต่อไปโดยไม่มีการวนซ้ำครั้งต่อไปของอัลกอริทึม IRL จนกว่าจะมาบรรจบกัน
เรามาลองทำความเข้าใจกับโค้ดกัน กรุณาค้นหารหัสที่สมบูรณ์ใน repo git นี้ ส่วนใหญ่มี 3 ไฟล์ที่คุณต้องกังวล -
manualControl.py - เพื่อรับคุณสมบัติที่คาดหวังจากผู้เชี่ยวชาญโดยการย้ายตัวแทนด้วยตนเอง เรียกใช้ "python3 manualControl.py" รอให้ gui โหลดแล้วใช้ปุ่มลูกศรเพื่อเริ่มเคลื่อนที่ กำหนดพฤติกรรมที่คุณต้องการให้คัดลอก (โปรดทราบว่าพฤติกรรมที่คุณคาดหวังให้คัดลอกควรสมเหตุสมผลกับพื้นที่สถานะที่กำหนด) เคล็ดลับที่ดีคือการสมมติตัวเองแทนที่ตัวแทนและคิดว่าคุณจะสามารถแยกแยะพฤติกรรมที่กำหนดโดยพิจารณาจากพื้นที่สถานะปัจจุบันเท่านั้นได้หรือไม่ ดูไฟล์ต้นฉบับสำหรับรายละเอียดเพิ่มเติม
toy_car_IRL.py - ไฟล์หลัก นี่คือที่วางโค้ด IRL ให้เราดูโค้ดทีละขั้นตอน -
{% ส่วนสำคัญ 51542f27e97eac1559a00f06b757df1a %}
นำเข้าการอ้างอิงและกำหนดพารามิเตอร์ที่สำคัญ เปลี่ยน BEHAVIOR ตามต้องการ FRAMES คือจำนวนเฟรมที่คุณต้องการให้อัลกอริทึม RL ทำงาน 100K ก็โอเคและใช้เวลาประมาณ 2 ชั่วโมง
{% ส่วนสำคัญ 49b602b9a3090773d492310175bb2e3f %}
สร้างคลาส irlAgent ที่ใช้งานง่าย ซึ่งรับพฤติกรรมแบบสุ่มและพฤติกรรมของผู้เชี่ยวชาญ และพารามิเตอร์ที่สำคัญอื่นๆ ดังที่แสดง
{% ส่วนสำคัญ bc17c06a07ea3b915827e89f3c13a2ae %}
ฟังก์ชัน getRLAgentFE ใช้ IRL_helper จากผู้เรียนเสริมเพื่อฝึกโมเดลใหม่และรับความคาดหวังของคุณสมบัติโดยการเล่นโมเดลนั้นเพื่อวนซ้ำ 2,000 ครั้ง โดยพื้นฐานแล้วมันจะส่งคืนความคาดหวังของฟีเจอร์สำหรับชุดน้ำหนัก (W) ทุกชุดที่ได้รับ
{% ส่วนสำคัญ ce0ef99adc652c7469f1bc4303a3af41 %}
เพื่ออัปเดตพจนานุกรมที่เราเก็บนโยบายที่ได้รับและค่า t ที่เกี่ยวข้อง โดยที่ t = (weights.tanspose)x(expert-newPolicy)
{% ส่วนสำคัญ be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
การใช้งานอัลกอริธึม IRL หลักตามที่กล่าวไว้ข้างต้น {% ส่วนสำคัญ 9faee18596467ee33ac5d91fd0cb675f %}
การเพิ่มประสิทธิภาพแบบนูนเพื่ออัปเดตน้ำหนักเมื่อได้รับนโยบายใหม่ โดยพื้นฐานแล้วกำหนดป้ายกำกับ +1 ให้กับนโยบายผู้เชี่ยวชาญ และป้ายกำกับ -1 ให้กับนโยบายอื่นๆ ทั้งหมด และปรับให้เหมาะสมสำหรับน้ำหนักภายใต้ข้อจำกัดดังกล่าว หากต้องการทราบข้อมูลเพิ่มเติมเกี่ยวกับการเพิ่มประสิทธิภาพ โปรดไปที่ไซต์นี้
{% ส่วนสำคัญ 30cf6c59b9915054f3cf6d278f8f8a11 %}
สร้าง irlAgent และส่งพารามิเตอร์ที่ต้องการ เลือกระหว่างประเภทของพฤติกรรมของผู้เชี่ยวชาญที่คุณต้องการเรียนรู้น้ำหนัก จากนั้นเรียกใช้ฟังก์ชัน suitableWeightFinder() โปรดทราบว่าฉันได้รับความคาดหวังของฟีเจอร์สำหรับพฤติกรรมสีแดง เหลือง และน้ำตาลแล้ว หลังจากที่อัลกอริธึมยุติลง คุณจะได้รับรายการน้ำหนักใน 'weights-red/yellow/brown.txt' พร้อมด้วยพฤติกรรมที่เลือกตามลำดับ ตอนนี้ เพื่อเลือกพฤติกรรมที่ดีที่สุดที่เป็นไปได้จากน้ำหนักที่ได้รับทั้งหมด ให้เล่นโมเดลที่บันทึกไว้ในไดเร็กทอรี save-models_BEHAVIOR/evaluatedPolicies/ โมเดลต่างๆ จะถูกบันทึกในรูปแบบต่อไปนี้ 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+ หมายเลขวนซ้ำ+ '-164-150-100-50000-100000' + '.h5' โดยพื้นฐานแล้ว คุณจะได้รับน้ำหนักที่แตกต่างกันสำหรับการวนซ้ำที่แตกต่างกัน ขั้นแรกให้เล่นโมเดลต่างๆ เพื่อค้นหาโมเดลที่ทำงานได้ดีที่สุด จากนั้นสังเกตหมายเลขการวนซ้ำของโมเดลนั้น น้ำหนักที่ได้รับที่สอดคล้องกับหมายเลขการวนซ้ำนี้คือน้ำหนักที่ทำให้คุณใกล้ชิดกับผู้เชี่ยวชาญมากที่สุด พฤติกรรม.
แล้วมีไฟล์ที่คุณอาจไม่จำเป็นต้องอัปเดต/แก้ไข อย่างน้อยก็สำหรับเนื้อหาในโพสต์นี้ -
หลังจากการวนซ้ำประมาณ 10-15 ครั้ง อัลกอริธึมก็จะมาบรรจบกันในพฤติกรรมที่เลือกทั้ง 4 แบบ ฉันได้ผลลัพธ์ดังต่อไปนี้:
| ตุ้มน้ำหนัก | ฉันรักสีเหลือง | ฉันรักบราวน์ | ฉันรักสีแดง | ฉันรักการกระแทก |
|---|---|---|---|---|
| w1 (ระยะเซ็นเซอร์ด้านซ้าย) | -0.0880 | -0.2627 | 0.2816 | -0.5892 |
| w2 (ระยะเซ็นเซอร์กลาง) | -0.0624 | 0.0363 | -0.5547 | -0.3672 |
| w3 (ระยะเซ็นเซอร์ด้านขวา) | 0.0914 | 0.0931 | -0.2297 | -0.4660 |
| w4 (สีดำ) | -0.0114 | 0.0046 | 0.6824 | -0.0299 |
| w5 (สีเหลือง) | 0.6690 | -0.1829 | -0.3025 | -0.1528 |
| w6 (สีน้ำตาล) | -0.0771 | 0.6987 | 0.0004 | -0.0368 |
| w7 (สีแดง) | -0.6650 | -0.5922 | 0.0525 | -0.5239 |
| w8 (ขัดข้อง) | -0.2897 | -0.2201 | -0.0075 | 0.0256 |
ค่าลบที่สูงจะกำหนดให้กับน้ำหนักที่เป็นของลักษณะ การชน ในพฤติกรรม 3 ประการแรก เนื่องจากพฤติกรรมของผู้เชี่ยวชาญ 3 ประการนี้ไม่อยากให้เจ้าหน้าที่ชนกับสิ่งกีดขวาง ในขณะที่น้ำหนักของฟีเจอร์เดียวกันในพฤติกรรมล่าสุด กล่าวคือ บอทที่น่ารังเกียจนั้นเป็นค่าบวก เนื่องจากพฤติกรรมของผู้เชี่ยวชาญสนับสนุนการกระแทก
เห็นได้ชัดว่าน้ำหนักของคุณลักษณะสีนั้นสัมพันธ์กับพฤติกรรมของผู้เชี่ยวชาญ โดยจะสูงเมื่อต้องการสีนั้น หรือค่าค่อนข้างต่ำ/เป็นลบเพื่อให้ได้พฤติกรรมที่แตกต่าง
น้ำหนักคุณลักษณะระยะทางมีความคลุมเครือมาก (ขัดกับสัญชาตญาณ) และเป็นการยากมากที่จะค้นหารูปแบบที่มีความหมายบางอย่างในตุ้มน้ำหนัก สิ่งเดียวที่ฉันอยากจะชี้ให้เห็นก็คือ มันเป็นไปได้ที่จะแยกแยะพฤติกรรมตามเข็มนาฬิกาและทวนเข็มนาฬิกาในการตั้งค่าปัจจุบัน คุณลักษณะระยะทางจะนำข้อมูลนี้ไป
หมายเหตุ เป็นสิ่งสำคัญมากที่จะต้องคิดก่อนว่าในฐานะมนุษย์ จะสามารถแยกแยะระหว่างพฤติกรรมที่กำหนดกับความพร้อมของชุดสถานะปัจจุบัน (การสังเกต) ในขณะที่ออกแบบโครงสร้างของปัญหาได้หรือไม่ ไม่เช่นนั้นคุณอาจบังคับให้อัลกอริธึมค้นหาน้ำหนักที่แตกต่างกันโดยไม่ได้ให้ข้อมูลที่จำเป็นครบถ้วน
หากคุณต้องการเข้าสู่ IRL จริงๆ ฉันขอแนะนำให้คุณพยายามสอนตัวแทนถึงพฤติกรรมใหม่ (คุณอาจต้องแก้ไขสภาพแวดล้อมสำหรับสิ่งนั้น เนื่องจากพฤติกรรมที่แตกต่างกันที่เป็นไปได้สำหรับชุดสถานะปัจจุบันได้ถูกนำไปใช้ประโยชน์แล้วเช่นกัน อย่างน้อยตามฉัน)
ติดตั้งการพึ่งพาของ Pygame ด้วย:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
จากนั้นติดตั้ง Pygame เอง:
pip3 install hg+http://bitbucket.org/pygame/pygame
นี่คือกลไกทางฟิสิกส์ที่ใช้ในการจำลอง มันเพิ่งผ่านการเขียนใหม่ที่ค่อนข้างสำคัญ (v5) ดังนั้นคุณจึงต้องคว้าเวอร์ชัน v4 ที่เก่ากว่า v4 เขียนขึ้นสำหรับ Python 2 ดังนั้นจึงมีขั้นตอนเพิ่มเติมสองสามขั้นตอน
กลับไปที่บ้านของคุณหรือดาวน์โหลดและรับ Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
แกะมันออก:
tar zxvf pymunk-4.0.0.tar.gz
อัปเดตจาก Python 2 เป็น 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
ติดตั้ง:
cd .. python3 setup.py install
ตอนนี้กลับไปที่ตำแหน่งที่คุณโคลน reinforcement-learning-car และตรวจสอบให้แน่ใจว่าทุกอย่างทำงานได้กับ python3 learning.py อย่างรวดเร็ว หากคุณเห็นหน้าจอที่มีจุดเล็กๆ ลอยอยู่รอบๆ หน้าจอ คุณก็พร้อมแล้ว!
ขั้นแรก คุณต้องฝึกโมเดล การดำเนินการนี้จะบันทึกน้ำหนักลงในโฟลเดอร์ saved-models คุณอาจต้องสร้างโฟลเดอร์นี้ก่อนที่จะเรียกใช้ คุณสามารถฝึกโมเดลได้โดยการรัน:
python3 learning.py
อาจใช้เวลาตั้งแต่หนึ่งชั่วโมงถึง 36 ชั่วโมงในการฝึกโมเดล ขึ้นอยู่กับความซับซ้อนของเครือข่ายและขนาดของกลุ่มตัวอย่างของคุณ อย่างไรก็ตาม มันจะพ่นน้ำหนักออกมาทุกๆ 25,000 เฟรม ดังนั้นคุณจึงสามารถไปยังขั้นตอนต่อไปได้โดยใช้เวลาน้อยลงมาก
แก้ไขไฟล์ playing.py เพื่อเปลี่ยนชื่อพาธของโมเดลที่คุณต้องการโหลด ขออภัยเกี่ยวกับเรื่องนี้ ฉันรู้ว่ามันควรเป็นอาร์กิวเมนต์บรรทัดคำสั่ง
จากนั้น ดูรถขับตัวเองไปรอบๆ สิ่งกีดขวาง!
python3 playing.py
นั่นคือทั้งหมดที่มีให้มัน


