flash attention
v2.7.0
ที่เก็บนี้ให้การดำเนินการอย่างเป็นทางการของ Flashattention และ Flashattention-2 จากเอกสารต่อไปนี้
Flashattention: ความสนใจที่รวดเร็วและมีประสิทธิภาพอย่างรวดเร็วด้วยการรับรู้ของ IO
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
กระดาษ: https://arxiv.org/abs/2205.14135
บทความ IEEE Spectrum เกี่ยวกับการส่งไปยังเกณฑ์มาตรฐาน MLPERF 2.0 โดยใช้ FlashAttention 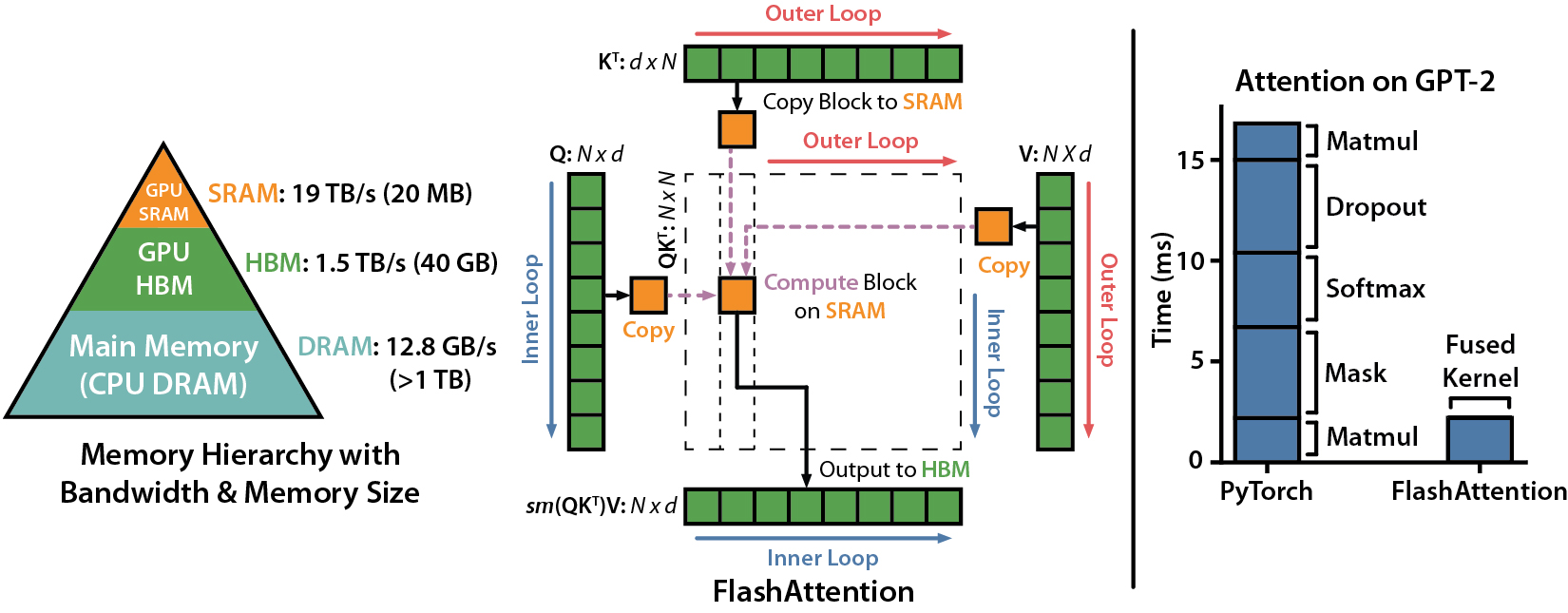
Flashattention-2: ความสนใจที่เร็วขึ้นด้วยการขนานที่ดีขึ้นและการแบ่งพาร์ติชันการทำงาน
Tri Dao
กระดาษ: https://tridao.me/publications/flash2/flash2.pdf

เรามีความสุขมากที่ได้เห็น Flashattention ถูกนำมาใช้อย่างกว้างขวางในช่วงเวลาสั้น ๆ หลังจากการเปิดตัว หน้านี้มีรายการบางส่วนของสถานที่ที่มีการใช้งาน Flashattent
Flashattention และ Flashattention-2 มีอิสระที่จะใช้และแก้ไข (ดูใบอนุญาต) โปรดอ้างอิงและให้เครดิต Flashattention หากคุณใช้
Flashattention-3 ได้รับการปรับให้เหมาะสมสำหรับ Hopper GPU (เช่น H100)
BlogPost: https://tridao.me/blog/2024/flash3/
กระดาษ: https://tridao.me/publications/flash3/flash3.pdf
นี่คือการเปิดตัวเบต้าสำหรับการทดสอบ / การเปรียบเทียบก่อนที่เราจะรวมเข้ากับส่วนที่เหลือของ repo
วางจำหน่ายในปัจจุบัน:
ข้อกำหนด: H100 / H800 GPU, CUDA> = 12.3
สำหรับตอนนี้เราขอแนะนำ Cuda 12.3 สำหรับประสิทธิภาพที่ดีที่สุด
ในการติดตั้ง:
cd hopper
python setup.py installเพื่อเรียกใช้การทดสอบ:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.pyความต้องการ:
packaging แพ็คเกจ Python ( pip install packaging )ninja Python ( pip install ninja ) * * ตรวจสอบให้แน่ใจว่ามีการติดตั้ง ninja และใช้งานได้อย่างถูกต้อง (เช่น ninja --version จากนั้น echo $? ควรส่งคืนรหัสออก 0) ถ้าไม่ใช่ (บางครั้ง ninja --version จากนั้น echo $? ส่งคืนรหัสออกที่ไม่ใช่ศูนย์), ถอนการติดตั้งจากนั้นติดตั้ง ninja ใหม่ ( pip uninstall -y ninja && pip install ninja ) หากไม่มี ninja การรวบรวมอาจใช้เวลานานมาก (2H) เนื่องจากไม่ได้ใช้คอร์ CPU หลายตัว ด้วยการรวบรวม ninja ใช้เวลา 3-5 นาทีในเครื่อง 64-core โดยใช้ CUDA Toolkit
ในการติดตั้ง:
pip install flash-attn --no-build-isolationหรือคุณสามารถรวบรวมจากแหล่งที่มา:
python setup.py install หากเครื่องของคุณมี RAM น้อยกว่า 96GB และคอร์ CPU จำนวนมาก ninja อาจทำงานได้มากเกินไปงานรวบรวมแบบขนานที่อาจทำให้ปริมาณ RAM หมดลง ในการ จำกัด จำนวนงานรวบรวมแบบขนานคุณสามารถตั้งค่าตัวแปรสภาพแวดล้อม MAX_JOBS :
MAX_JOBS=4 pip install flash-attn --no-build-isolation อินเตอร์เฟส: src/flash_attention_interface.py
ความต้องการ:
เราขอแนะนำคอนเทนเนอร์ Pytorch จาก Nvidia ซึ่งมีเครื่องมือที่จำเป็นทั้งหมดในการติดตั้ง Flashattention
Flashattention-2 กับ CUDA ปัจจุบันรองรับ:
เวอร์ชัน ROCM ใช้ composable_kernel เป็นแบ็กเอนด์ มันให้การใช้งาน Flashattention-2
ความต้องการ:
เราขอแนะนำคอนเทนเนอร์ Pytorch จาก ROCM ซึ่งมีเครื่องมือที่จำเป็นทั้งหมดในการติดตั้ง Flashattention
Flashattention-2 พร้อม ROCM รองรับ: ปัจจุบัน:
ฟังก์ชั่นหลักใช้ความสนใจของผลิตภัณฑ์ DOT ที่ปรับขนาด (softmax (q @ k^t * softmax_scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""หากต้องการดูว่าฟังก์ชั่นเหล่านี้ใช้ในเลเยอร์ความสนใจหลายหัว (ซึ่งรวมถึงการฉาย QKV, การฉายภาพออก) ดูการใช้งาน MHA
การอัพเกรดจาก Flashattention (1.x) เป็น Flashattention-2
ฟังก์ชั่นเหล่านี้ถูกเปลี่ยนชื่อแล้ว:
flash_attn_unpadded_func -> flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func -> flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func -> flash_attn_varlen_kvpacked_funcหากอินพุตมีความยาวลำดับเท่ากันในชุดเดียวกันมันจะง่ายและเร็วกว่าในการใช้ฟังก์ชั่นเหล่านี้:
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )ถ้า seqlen_q! = seqlen_k และ causal = true หน้ากากสาเหตุจะถูกจัดแนวที่มุมล่างขวาของเมทริกซ์ความสนใจแทนที่จะเป็นมุมบนซ้าย
ตัวอย่างเช่นถ้า seqlen_q = 2 และ seqlen_k = 5, หน้ากากสาเหตุ (1 = เก็บ, 0 = สวมหน้ากากออก) คือ:
v2.0:
1 0 0 0 0 0
1 1 0 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
ถ้า seqlen_q = 5 และ seqlen_k = 2 หน้ากากสาเหตุคือ:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
หากแถวของหน้ากากเป็นศูนย์ทั้งหมดเอาต์พุตจะเป็นศูนย์
ปรับให้เหมาะสมสำหรับการอนุมาน (การถอดรหัสซ้ำ) เมื่อแบบสอบถามมีความยาวลำดับเล็กมาก (เช่นความยาวลำดับการสืบค้น = 1) คอขวดที่นี่คือการโหลดแคช KV ให้เร็วที่สุดเท่าที่จะเป็นไปได้และเราแยกการโหลดข้ามบล็อกเธรดที่แตกต่างกันโดยมีเคอร์เนลแยกต่างหากเพื่อรวมผลลัพธ์
ดูฟังก์ชั่น flash_attn_with_kvcache พร้อมคุณสมบัติเพิ่มเติมสำหรับการอนุมาน (ดำเนินการฝังแบบโรตารี่อัพเดตแคช KV ในสถานที่)
ขอบคุณทีม Xformers และโดยเฉพาะอย่างยิ่ง Daniel Haziza สำหรับการทำงานร่วมกันนี้
ใช้ความสนใจในหน้าต่างเลื่อน (เช่นความสนใจในท้องถิ่น) ขอบคุณ Mistral AI และโดยเฉพาะอย่างยิ่งTimothée Lacroix สำหรับการบริจาคนี้ หน้าต่างเลื่อนถูกใช้ในรุ่น Mistral 7B
ใช้ Alibi (Press et al., 2021) ขอบคุณ Sanghun Cho จาก Kakao Brain สำหรับการบริจาคนี้
ใช้งานผ่านการกำหนดย้อนหลัง ขอบคุณวิศวกรจาก Meituan สำหรับการบริจาคนี้
รองรับแคช KV เพจ (เช่น Pagedattention) ขอบคุณ @beginlner สำหรับการบริจาคนี้
รองรับความสนใจด้วย softcapping ตามที่ใช้ในรุ่น Gemma-2 และ Grok ขอบคุณ @narsil และ @lucidrains สำหรับการบริจาคนี้
ขอบคุณ @ani300 สำหรับการบริจาคนี้
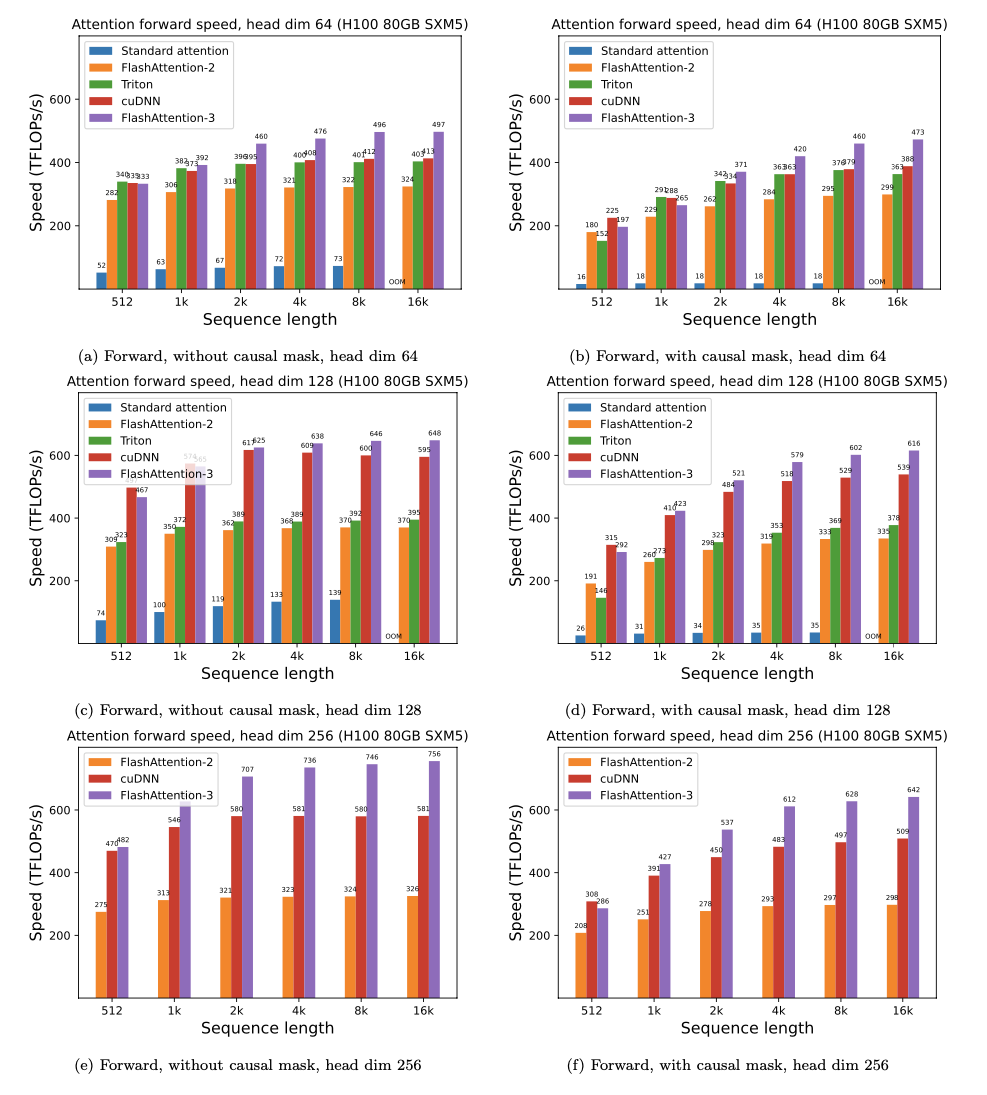
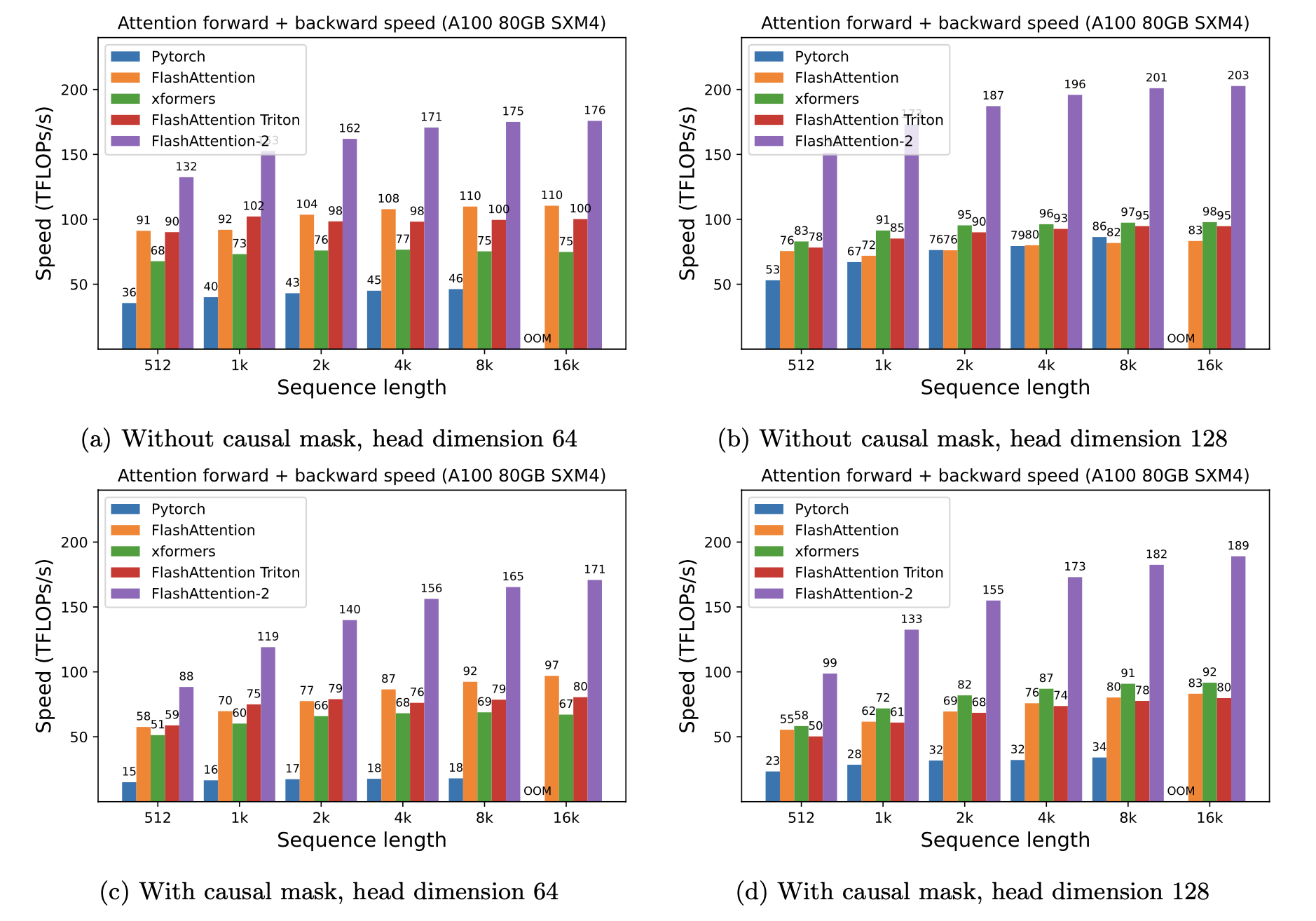
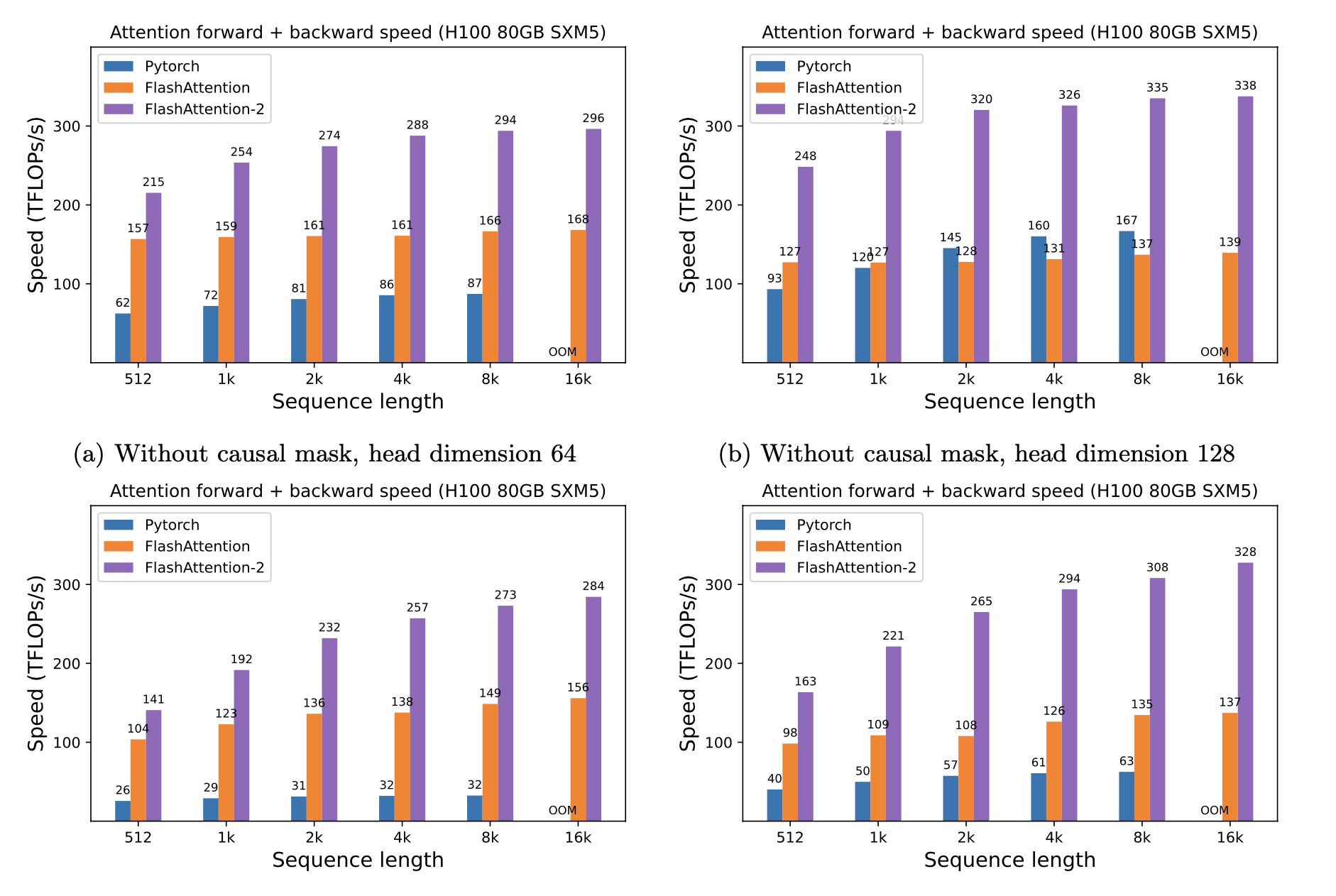
เรานำเสนอการเร่งความเร็วที่คาดหวัง (รวมไปข้างหน้า + ผ่านไปข้างหลัง) และการประหยัดหน่วยความจำจากการใช้ Flashattention กับความสนใจมาตรฐาน Pytorch ขึ้นอยู่กับความยาวลำดับบน GPU ที่แตกต่างกัน (การเร่งความเร็วขึ้นอยู่กับแบนด์วิดท์หน่วยความจำ - เราเห็นการเร่งความเร็วมากขึ้นในหน่วยความจำ GPU ที่ช้าลง)
ขณะนี้เรามีเกณฑ์มาตรฐานสำหรับ GPU เหล่านี้:
เราแสดงการเร่งความเร็ว Flashattention โดยใช้พารามิเตอร์เหล่านี้:
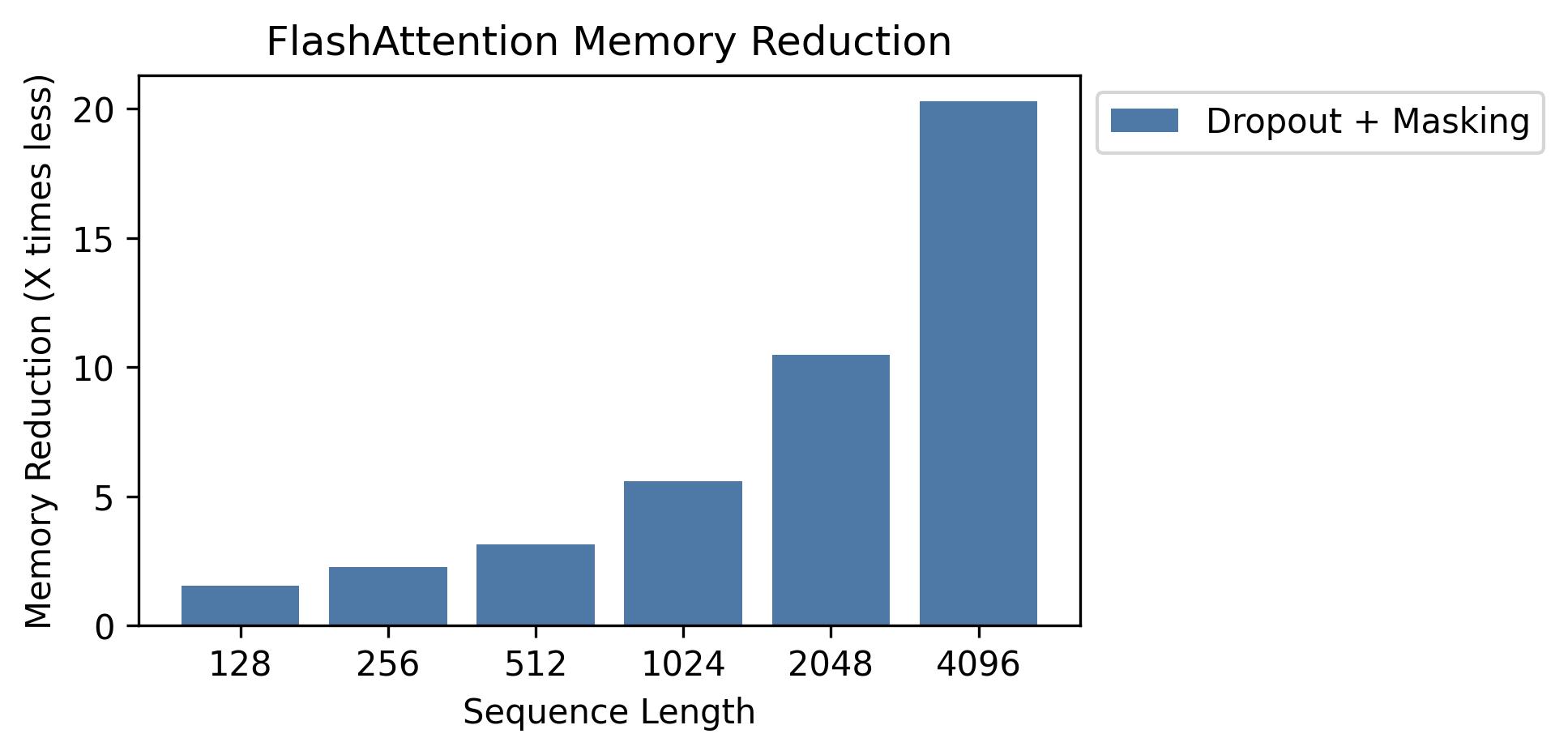
เราแสดงการประหยัดหน่วยความจำในกราฟนี้ (โปรดทราบว่ารอยเท้าหน่วยความจำนั้นเหมือนกันไม่ว่าคุณจะใช้การออกกลางคันหรือการปิดบัง) การออมหน่วยความจำเป็นสัดส่วนกับความยาวลำดับ - เนื่องจากความสนใจมาตรฐานมีหน่วยความจำกำลังสองในความยาวลำดับในขณะที่ flashattention มีหน่วยความจำเชิงเส้นตามลำดับความยาว เราเห็นการออมหน่วยความจำ 10x ที่ความยาวลำดับ 2K และ 20x ที่ 4K เป็นผลให้ Flashattention สามารถปรับขนาดความยาวตามลำดับได้นานขึ้น
เราได้เปิดตัวการใช้งานแบบจำลอง GPT เต็มรูปแบบ นอกจากนี้เรายังให้การใช้งานที่ดีที่สุดของเลเยอร์อื่น ๆ (เช่น MLP, Layernorm, การสูญเสียข้ามการเกิด, การฝังแบบโรตารี่) โดยรวมแล้วจะเพิ่มความเร็วในการฝึกอบรม 3-5x เมื่อเทียบกับการใช้งานพื้นฐานจาก HuggingFace สูงถึง 225 TFLOPS/วินาทีต่อ A100 เทียบเท่ากับการใช้ประโยชน์จากการใช้งานของโมเดล 72% (เราไม่ต้องการจุดตรวจการเปิดใช้งานใด ๆ )
นอกจากนี้เรายังรวมถึงสคริปต์การฝึกอบรมเพื่อฝึก GPT2 บน OpenWebText และ GPT3 บนกอง
Phil Tillet (OpenAI) มีการทดลองใช้ FlashAttention ใน Triton: https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
เนื่องจากไทรทันเป็นภาษาระดับสูงกว่า CUDA จึงอาจเข้าใจและทดลองได้ง่ายขึ้น สัญลักษณ์ในการใช้งาน Triton นั้นใกล้เคียงกับสิ่งที่ใช้ในบทความของเรา
นอกจากนี้เรายังมีการใช้งานทดลองใน Triton ที่สนับสนุนอคติความสนใจ (เช่น Alibi): https://github.com/dao-ailab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
เราทดสอบว่า Flashattention สร้างผลลัพธ์และการไล่ระดับสีเดียวกันกับการใช้งานอ้างอิงถึงความอดทนเชิงตัวเลขบางอย่าง โดยเฉพาะอย่างยิ่งเราตรวจสอบว่าข้อผิดพลาดเชิงตัวเลขสูงสุดของ flashattention นั้นมากที่สุดสองเท่าของข้อผิดพลาดเชิงตัวเลขของการใช้งานพื้นฐานใน pytorch (สำหรับขนาดหัวที่แตกต่างกัน, อินพุต dtype, ความยาวลำดับ, สาเหตุ / ไม่ใช่ causal)
เพื่อเรียกใช้การทดสอบ:
pytest -q -s tests/test_flash_attn.pyการเปิดตัว Flashattention-2 รุ่นใหม่นี้ได้รับการทดสอบในหลายรุ่น GPT ซึ่งส่วนใหญ่อยู่ใน A100 GPU
หากคุณพบข้อบกพร่องโปรดเปิดปัญหา GitHub!
เพื่อเรียกใช้การทดสอบ:
pytest tests/test_flash_attn_ck.pyหากคุณใช้ codebase นี้หรือพบว่างานของเรามีค่าโปรดอ้างอิง:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


