guidewire
1.0.0
การตีความ Guidewire CDA เป็นตารางเดลต้า: ในฐานะ บริษัท เทคโนโลยี Guidewire เสนอแพลตฟอร์มอุตสาหกรรมสำหรับผู้ให้บริการประกันภัยอสังหาริมทรัพย์และผู้เสียชีวิตทั่วโลก ผ่านผลิตภัณฑ์และบริการที่แตกต่างกันภายใต้ชุดประกันภัยของพวกเขาพวกเขาให้ความสามารถในการดำเนินงานที่จำเป็นในการรับประมวลผลและชำระค่าเรียกร้องรักษานโยบายสนับสนุนการจัดจำหน่ายหลักทรัพย์และกระบวนการปรับ ในทางกลับกัน DataBricks ให้ความสามารถในการวิเคราะห์แก่ผู้ใช้ (จากการรายงานขั้นพื้นฐานไปจนถึงโซลูชั่น ML ที่ซับซ้อน) ผ่าน Lakehouse เพื่อการประกันภัย ด้วยการรวมทั้งสองแพลตฟอร์มเข้าด้วยกัน บริษัท ประกันภัย P&C ได้มีความสามารถในการเริ่มต้นการรวมความสามารถในการวิเคราะห์ขั้นสูง (AI/ML) เข้ากับกระบวนการทางธุรกิจหลักของพวกเขาเพิ่มข้อมูลลูกค้าด้วยข้อมูลทางเลือก (เช่นข้อมูลสภาพอากาศ) มาตราส่วน.
Guidewire รองรับการเข้าถึงข้อมูลสภาพแวดล้อมการวิเคราะห์ผ่านการเสนอการเข้าถึงข้อมูลคลาวด์ (CDA) การจัดเก็บไฟล์เป็นไฟล์ Parquet แต่ละไฟล์ภายใต้การประทับเวลาที่แตกต่างกันและวิวัฒนาการสคีมาน่าเสียดายที่การประมวลผลยากสำหรับผู้ใช้ปลายทาง แทนที่จะประมวลผลไฟล์เป็นรายบุคคลทำไมเราไม่สร้างไฟล์ delta log Manifest เพื่ออ่านข้อมูลที่เราต้องการเมื่อเราต้องการโดยไม่ต้องดาวน์โหลดประมวลผลและกระทบยอดข้อมูลที่ซับซ้อน นี่คือหลักการที่อยู่เบื้องหลังความคิดริเริ่มนี้ ตารางเดลต้าที่สร้างขึ้นจะไม่ปรากฏ (ข้อมูลจะไม่เคลื่อนไหวทางร่างกาย) แต่ทำหน้าที่เป็นโคลนตื้นต่อข้อมูล Guidewire
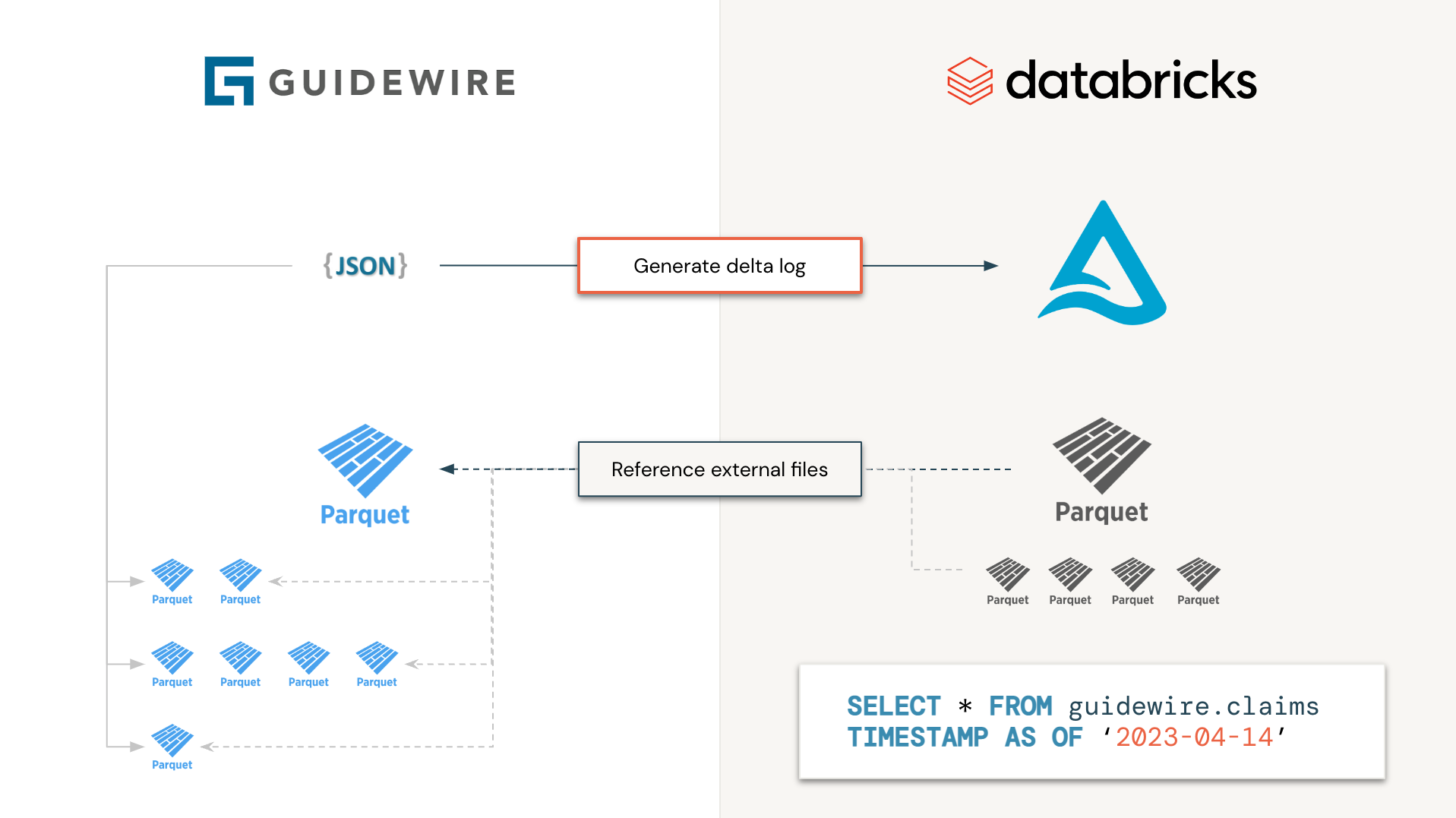
โดยเฉพาะอย่างยิ่งเราจะประมวลผลตาราง Guidewire ทั้งหมดอย่างอิสระในแบบขนาน (เช่นเป็นงาน Spark) ซึ่งแต่ละงานจะประกอบด้วยเฉพาะรายการไฟล์และโฟลเดอร์และสร้างบันทึกเดลต้าตามลำดับเท่านั้น จากมุมมองของผู้ใช้ปลายทาง Guidewire จะมองเป็นตารางเดลต้าและประมวลผลเช่นนี้ลดเวลาการประมวลผลจากวันเป็นวินาที (เนื่องจากเราไม่จำเป็นต้องดาวน์โหลดและประมวลผลแต่ละไฟล์ผ่านงาน Spark จำนวนมาก)

เนื่องจากข้อมูลอยู่ในทะเลสาบเดลต้า (เป็นรูปธรรมทางกายภาพหรือไม่) เราจะได้รับประโยชน์จากความสามารถดาวน์สตรีมทั้งหมดของทะเลสาบเดลต้า "สมัครรับ" การเปลี่ยนแปลงผ่านความสามารถในการโหลดอัตโนมัติ, เดลต้าสดตาราง (DLT) หรือแม้แต่การแบ่งปันเดลต้าเร่งความเร็ว ถึงเวลาข้อมูลเชิงลึกตั้งแต่วันหนึ่งถึงนาที
เนื่องจากโมเดลนี้เป็นไปตามวิธีการโคลนตื้นขอแนะนำให้อนุญาตให้อ่านการอ่านให้กับผู้ใช้เท่านั้นเนื่องจากการดำเนินการ VACCUM บนเดลต้าที่สร้างขึ้นอาจส่งผลให้เกิดการสูญเสียข้อมูลในถัง Guidewire S3 เราขอแนะนำให้องค์กรไม่เปิดเผยชุดข้อมูล RAW นี้ให้กับผู้ใช้ปลายทาง แต่ให้สร้างเวอร์ชันเงินที่มีข้อมูลที่เป็นรูปธรรมสำหรับการบริโภค โปรดทราบว่าคำสั่ง OPTIMIZE จะส่งผลให้เกิดการเป็นรูปธรรมของสแน็ปช็อตเดลต้าล่าสุดด้วยไฟล์ Parquet ที่ได้รับการปรับปรุง เฉพาะไฟล์ที่เกี่ยวข้องเท่านั้นที่จะดาวน์โหลดทางกายภาพจาก S3 ดั้งเดิมไปยังตารางปลายทาง
import com . databricks . labs . guidewire . Guidewire
val manifestUri = " s3://bucket/key/manifest.json "
val databasePath = " /path/to/delta/database "
Guidewire .index(manifestUri, databasePath) คำสั่งนี้จะทำงานบนการเพิ่มข้อมูลโดยค่าเริ่มต้นการโหลดจุดตรวจสอบก่อนหน้าของเราที่เก็บไว้เป็นตารางเดลต้าภายใต้ ${databasePath}/_checkpoints หากคุณจำเป็นต้องใช้ข้อมูล Guidewire ทั้งหมดอีกครั้งโปรดระบุพารามิเตอร์ savemode ที่เป็นตัวเลือกดังนี้
import org . apache . spark . sql . SaveMode
Guidewire .index(manifestUri, databasePath, saveMode = SaveMode . Overwrite )ตามรูปแบบ 'โคลนตื้น' ไฟล์ Guidewire จะไม่ถูกจัดเก็บ แต่อ้างอิงจากตำแหน่งเดลต้าที่สามารถกำหนดเป็นตารางภายนอก
CREATE DATABASE IF NOT EXISTS guidewire;
CREATE EXTERNAL TABLE IF NOT EXISTS guidewire . policy_holders LOCATION ' /path/to/delta/database/policy_holders ' ;ในที่สุดเราสามารถสืบค้นข้อมูล Guidewire และเข้าถึงเวอร์ชันที่แตกต่างกันทั้งหมดในการประทับเวลาที่แตกต่างกัน
SELECT * FROM guidewire . policy_holders
VERSION AS OF 2 mvn clean package -Pshaded ตามมาตรฐาน Maven ให้เพิ่มโปรไฟล์ shaded เพื่อสร้างไฟล์ jar แบบสแตนด์อโลนพร้อมการพึ่งพาทั้งหมดที่รวมอยู่ ขวดนี้สามารถติดตั้งได้ในสภาพแวดล้อม Databricks ตามลำดับ


