streaming
v0.9.1
เราสร้าง StreamingDataset เพื่อทำการฝึกอบรมชุดข้อมูลขนาดใหญ่จากที่เก็บข้อมูลบนคลาวด์เร็วราคาถูกและปรับขนาดได้มากที่สุด
มันได้รับการออกแบบมาเป็นพิเศษสำหรับหลายโหนดการฝึกอบรมแบบกระจายสำหรับรุ่นขนาดใหญ่-การรับประกันความถูกต้องสูงสุดประสิทธิภาพและความสะดวกในการใช้งาน ตอนนี้คุณสามารถฝึกอบรมได้อย่างมีประสิทธิภาพทุกที่เป็นอิสระจากตำแหน่งข้อมูลการฝึกอบรมของคุณ เพียงแค่สตรีมในข้อมูลที่คุณต้องการเมื่อคุณต้องการ หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับสาเหตุที่เราสร้าง StreamingDataset อ่านบล็อกประกาศของเรา
StreamingDataset เข้ากันได้กับประเภทข้อมูลใด ๆ รวมถึง รูปภาพข้อความวิดีโอและข้อมูลหลายรูปแบบ
ด้วยการสนับสนุนสำหรับผู้ให้บริการจัดเก็บข้อมูลคลาวด์ที่สำคัญ (AWS, OCI, GCS, Azure, Databricks และร้านค้าวัตถุที่เข้ากันได้กับ S3 เช่น CloudFlare R2, CoreWeave, Backblaze B2 ฯลฯ ) , StreamingDataset รวมเข้ากับเวิร์กโฟลว์การฝึกอบรมที่มีอยู่ของคุณได้อย่างราบรื่น

การสตรีมสามารถติดตั้งด้วย pip :
PIP ติดตั้ง mosaicml-streaming
แปลงชุดข้อมูลดิบของคุณเป็นหนึ่งในรูปแบบการสตรีมที่เราสนับสนุน:
รูปแบบ MDS (mosaic data shard) ซึ่งสามารถเข้ารหัสและถอดรหัสวัตถุ Python ใด ๆ
CSV / TSV
jsonl
นำเข้า numpy เป็น NPFROM PIL นำเข้าภาพจากการสตรีมนำเข้า mdswriter# ไดเรกทอรีท้องถิ่นหรือรีโมตซึ่งจะจัดเก็บเอาต์พุตที่บีบอัด filesdata_dir = 'เส้นทางไปสู่ข้อมูล'# ฟิลด์อินพุตการแมปพจนานุกรมไปยังข้อมูล typescolumns = {'ภาพ': 'jpeg' , 'class': 'int'}# การบีบอัดชาร์ดถ้า anyCompression = 'zstd'# บันทึกตัวอย่างเป็นเศษโดยใช้ mdswriterwith mdswriter (out = data_dir, คอลัมน์ = คอลัมน์, การบีบอัด = การบีบอัด) ): sample = {'image': image.fromarray (np.random.randint (0, 256, (32, 32, 3), np.uint8)), 'คลาส': np.random.randint (10),
} out.write (ตัวอย่าง)อัปโหลดชุดข้อมูลสตรีมมิ่งของคุณไปยังที่เก็บข้อมูลคลาวด์ที่คุณเลือก (AWS, OCI หรือ GCP) ด้านล่างเป็นตัวอย่างหนึ่งของการอัปโหลดไดเรกทอรีไปยังถัง S3 โดยใช้ AWS CLI
$ AWS S3 CP-เส้นทางสู่ DATASET S3: // MY-BUCKET/PATH-TO-DATASET
จาก Torch.utils.data นำเข้า dataloaderFrom streaming import import streamingDataset# พา ธ ระยะไกลที่ชุดข้อมูลเต็มรูปแบบถูกเก็บไว้อย่างต่อเนื่อง = 's3: // ของฉัน-บัคเก็ต /path-to-dataset '# สร้างสตรีมมิ่ง dataSetDataSet = streamingDataSet (local = local, remote = remote, shuffle = true)# มาดูกันว่ามีอะไรอยู่ในตัวอย่าง# 1337 ... ตัวอย่าง = ชุดข้อมูล [1337] img = ตัวอย่าง [' ภาพ '] cls = sample [' class ']# สร้าง pytorch dataloaderDataloader = dataloader (ชุดข้อมูล)
การเริ่มต้นคำแนะนำตัวอย่างการอ้างอิง API และข้อมูลที่เป็นประโยชน์อื่น ๆ สามารถพบได้ในเอกสารของเรา
เรามีบทช่วยสอนแบบครบวงจรสำหรับการฝึกอบรมแบบจำลอง:
CIFAR-10
Facesynthetics
syntheticnlp
นอกจากนี้เรายังมีรหัสเริ่มต้นสำหรับชุดข้อมูลยอดนิยมต่อไปนี้ซึ่งสามารถพบได้ในไดเรกทอรี streaming :
| ชุดข้อมูล | งาน | อ่าน | เขียน |
|---|---|---|---|
| LAION-400M | ข้อความและรูปภาพ | อ่าน | เขียน |
| เว็บวีด | ข้อความและวิดีโอ | อ่าน | เขียน |
| C4 | ข้อความ | อ่าน | เขียน |
| enwiki | ข้อความ | อ่าน | เขียน |
| กอง | ข้อความ | อ่าน | เขียน |
| ADE20K | การแบ่งส่วนภาพ | อ่าน | เขียน |
| CIFAR10 | การจำแนกรูปภาพ | อ่าน | เขียน |
| โกโก้ | การจำแนกรูปภาพ | อ่าน | เขียน |
| ImageNet | การจำแนกรูปภาพ | อ่าน | เขียน |
เพื่อเริ่มการฝึกอบรมในชุดข้อมูลเหล่านี้:
แปลงข้อมูลดิบเป็นรูปแบบ. MDS โดยใช้สคริปต์ที่เกี่ยวข้องจากไดเรกทอรี convert
ตัวอย่างเช่น:
$ python -m streaming.multimodal.convert.webvid -in <csv file> -out <mds output directory>
นำเข้าคลาสชุดข้อมูลเพื่อเริ่มการฝึกอบรมแบบจำลอง
จาก streaming.multimodal import streamingInsidewebvidDataset = streaminginsidewebvid (local = local, remote = remote, shuffle = true)
ทดลองกับชุดข้อมูลด้วย Stream ได้อย่างง่ายดาย การสุ่มตัวอย่างชุดข้อมูลสามารถควบคุมได้ในสัมพัทธ์ (สัดส่วน) หรือสัมบูรณ์ (ทำซ้ำหรือเงื่อนไขตัวอย่าง) ในระหว่างการสตรีมชุดข้อมูลที่แตกต่างกันจะถูกสตรีมสับและผสมอย่างราบรื่นในเวลา
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
คุณสมบัติที่เป็นเอกลักษณ์ของการแก้ปัญหาของเรา: ตัวอย่างอยู่ในลำดับเดียวกันโดยไม่คำนึงถึงจำนวน GPU, โหนดหรือพนักงาน CPU ทำให้ง่ายขึ้น:
การทำซ้ำและการดีบักการฝึกอบรมและการสูญเสียแหลม
โหลดจุดตรวจสอบที่ได้รับการฝึกฝนบน 64 GPU และการดีบักใน 8 GPU ด้วยการทำซ้ำ
ดูรูปด้านล่าง - การฝึกอบรมแบบจำลองใน 1, 8, 16, 32 หรือ 64 GPUs ให้ผล การสูญเสียที่แน่นอน (ขึ้นอยู่กับข้อ จำกัด ของคณิตศาสตร์จุดลอยตัว!))
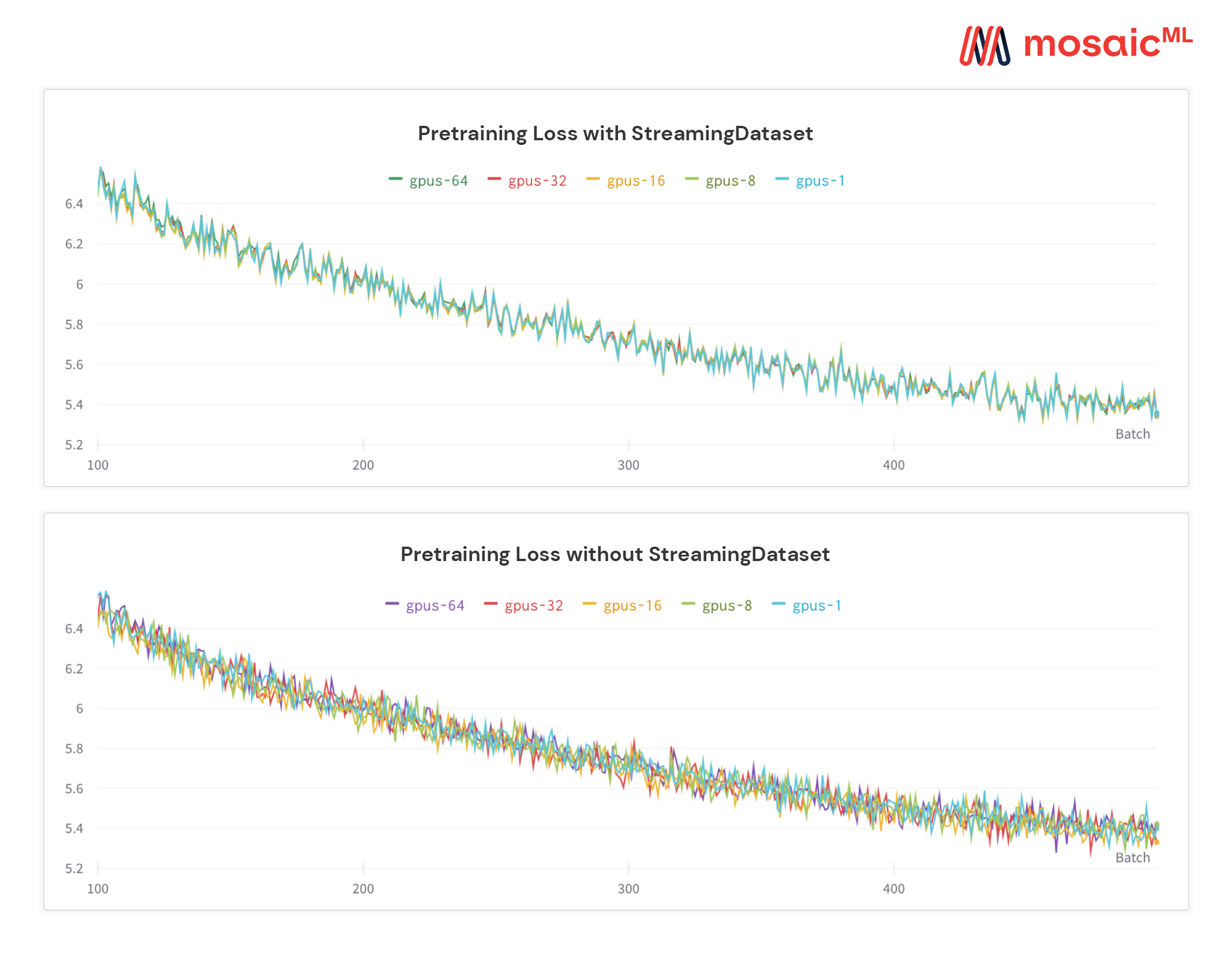
อาจมีราคาแพง - และน่ารำคาญ - รอให้งานของคุณกลับมาทำงานต่อในขณะที่ Dataloader ของคุณหมุนหลังจากความล้มเหลวของฮาร์ดแวร์หรือการสูญเสียสไปค์ ต้องขอบคุณการสั่งซื้อตัวอย่างที่กำหนดของเราสตรีมดาต้าช่วยให้คุณได้รับการฝึกอบรมต่อในไม่กี่วินาทีไม่ใช่ชั่วโมงในช่วงกลางของการฝึกอบรมระยะยาว
การลดเวลาแฝงการเริ่มต้นใหม่สามารถประหยัดได้หลายพันดอลลาร์ในค่าธรรมเนียม egress และเวลาคำนวณ GPU ที่ไม่ได้ใช้งานเมื่อเทียบกับโซลูชันที่มีอยู่
รูปแบบ MDS ของเราตัดงานที่ไม่เกี่ยวข้องกับกระดูกส่งผลให้เกิดเวลาแฝงตัวอย่างต่ำเป็นพิเศษและปริมาณงานที่สูงขึ้นเมื่อเทียบกับทางเลือกสำหรับเวิร์กโหลดคอขวดที่ถูกเก็บไว้โดย Dataloader
| เครื่องมือ | ปริมาณงาน |
|---|---|
| สตรีมมิ่ง | ~ 19000 IMG/SEC |
| ImageFolder | ~ 18000 IMG/SEC |
| WebDataset | ~ 16000 IMG/SEC |
ผลลัพธ์ที่แสดงมาจากการฝึกอบรม Imagenet + Resnet-50 รวบรวมมากกว่า 5 การทำซ้ำหลังจากข้อมูลถูกแคชหลังจากยุคแรก
การบรรจบกันของแบบจำลองจากการใช้ StreamingDataset นั้นดีพอ ๆ กับการใช้ดิสก์ในท้องถิ่นด้วยอัลกอริทึมการสับของเรา
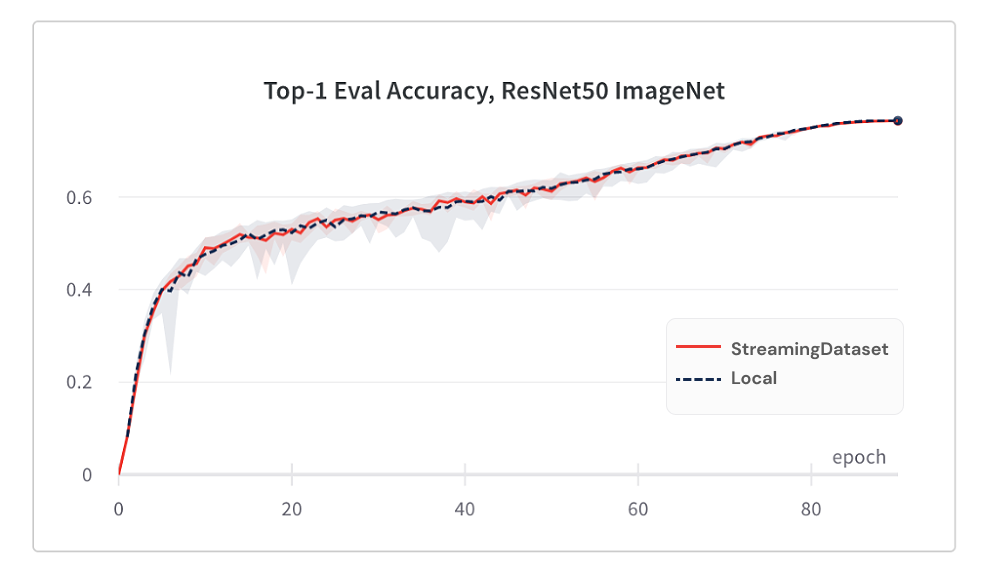
ด้านล่างนี้เป็นผลมาจากการฝึกอบรม Imagenet + Resnet-50 ซึ่งรวบรวมได้มากกว่า 5 ครั้ง
| เครื่องมือ | ความแม่นยำสูงสุด -1 |
|---|---|
| สตรีมมิ่ง | 76.51% +/- 0.09 |
| ImageFolder | 76.57% +/- 0.10 |
| WebDataset | 76.23% +/- 0.17 |
StreamingDataset สลับไปยังตัวอย่างทั้งหมดที่กำหนดให้กับโหนดในขณะที่โซลูชันทางเลือกจะสลับตัวอย่างเฉพาะในสระว่ายน้ำขนาดเล็ก (ภายในกระบวนการเดียว) การสับข้ามสระว่ายน้ำที่กว้างขึ้นกระจายตัวอย่างที่อยู่ติดกันมากขึ้น นอกจากนี้อัลกอริทึมการสับของเราลดตัวอย่างที่ลดลง เราพบว่าทั้งสองคุณสมบัติการสับเปลี่ยนนี้เป็นประโยชน์สำหรับการบรรจบกันของแบบจำลอง
เข้าถึงข้อมูลที่คุณต้องการเมื่อคุณต้องการ
แม้ว่าตัวอย่างยังไม่ดาวน์โหลดคุณสามารถเข้าถึง dataset[i] เพื่อรับตัวอย่าง i การดาวน์โหลดจะเริ่มขึ้นทันทีและผลลัพธ์จะถูกส่งคืนเมื่อเสร็จแล้ว - คล้ายกับชุดข้อมูล Pytorch สไตล์แผนที่พร้อมตัวอย่างที่มีหมายเลขตามลำดับและเข้าถึงได้ตามลำดับใด ๆ
DataSet = StreamingDataSet (... ) ตัวอย่าง = ชุดข้อมูล [19543]
StreamingDataset จะวนซ้ำตัวอย่างจำนวนมาก คุณไม่จำเป็นต้องลบตัวอย่างตลอดไปเพื่อให้ชุดข้อมูลสามารถหารได้มากกว่าจำนวนอุปกรณ์ที่อบ แต่แต่ละยุคมีการเลือกตัวอย่างที่แตกต่างกันซ้ำ (ไม่มีการลดลง) เพื่อให้แต่ละอุปกรณ์ประมวลผลจำนวนเดียวกัน
DataSet = StreamingDataSet (... ) DL = DataLoader (ชุดข้อมูล, num_workers = ... )
ลบเศษที่ใช้อย่างน้อยเมื่อเร็ว ๆ นี้เพื่อให้การใช้ดิสก์ภายใต้ขีด จำกัด ที่ระบุ สิ่งนี้คือการเปิดใช้งานโดยการตั้งค่าอาร์กิวเมนต์สตรีมมิ่งแคช cache_limit ดูคู่มือสับเปลี่ยนสำหรับรายละเอียดเพิ่มเติม
dataset = StreamingDataset( cache_limit='100gb', ... )
นี่คือบางโครงการและการทดลองที่ใช้ StreamingDataset มีอะไรเพิ่ม? ส่งอีเมล [email protected] หรือเข้าร่วมชุมชน Slack ของเรา
Biomedlm: แบบจำลองภาษาขนาดใหญ่เฉพาะโดเมนสำหรับ biomedicine โดย mosaicML และ Stanford CRFM
โมเดลการแพร่กระจายของโมเสค: การฝึกอบรมการแพร่กระจายที่มั่นคงจากค่าใช้จ่ายค่าเริ่มต้น <$ 160K
Mosaic LLMS: GPT-3 คุณภาพสำหรับ <$ 500K
Mosaic Resnet: การฝึกอบรมการมองเห็นคอมพิวเตอร์อย่างรวดเร็วอย่างรวดเร็วด้วย Mosaic Resnet และนักแต่งเพลง
โมเสค deeplabv3: 5x การฝึกการแบ่งส่วนภาพที่เร็วขึ้นด้วยสูตร mosaicml
…จะมาอีก! คอยติดตาม!
เรายินดีต้อนรับการมีส่วนร่วมใด ๆ ดึงคำขอหรือปัญหา
หากต้องการเริ่มต้นให้ดูหน้าการบริจาคของเรา
PS: เรากำลังจ้าง!
หากคุณชอบโครงการนี้ให้เราเป็นดาราและตรวจสอบโครงการอื่น ๆ ของเรา:
นักแต่งเพลง - ห้องสมุด Pytorch ที่ทันสมัยซึ่งทำให้การฝึกอบรมเครือข่ายประสาทที่ปรับขนาดและมีประสิทธิภาพได้ง่าย
ตัวอย่าง MOSAICML - ตัวอย่างอ้างอิงสำหรับการฝึกอบรม ML แบบจำลองอย่างรวดเร็วและมีความแม่นยำสูง - มีรหัสเริ่มต้นสำหรับรุ่น GPT / LAGHT LANGWID
MOSAICML Cloud- แพลตฟอร์มการฝึกอบรมของเราที่สร้างขึ้นเพื่อลดค่าใช้จ่ายในการฝึกอบรมสำหรับ LLMS, โมเดลการแพร่และรุ่นใหญ่อื่น ๆ-มีการประสานหลายคลาว
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

