Marketing Attribution Models
1.0.10
ชั้น Python สร้างขึ้นเพื่อแก้ไขปัญหาเกี่ยวกับแหล่งที่มาของการตลาดดิจิทัล
ในขณะที่เรียกดูออนไลน์ผู้ใช้มีจุดสัมผัสหลายจุดก่อนที่จะแปลงซึ่งอาจนำไปสู่การเดินทางที่ยาวนานขึ้นและซับซ้อนมากขึ้น
วิธีการแปลงเครดิตและการลงทุนในสื่ออย่างถูกต้อง?
ในการจัดทำสิ่งนี้เราใช้ รูปแบบการระบุแหล่งที่มา
แบบจำลองฮิวริสติก :
การโต้ตอบครั้งสุดท้าย :
การระบุแหล่งที่มาเริ่มต้นใน GOGLE Analytics และแพลตฟอร์มสื่ออื่น ๆ เช่น Google Ads และ Facebook Business Manager
เฉพาะจุดสัมผัสสุดท้ายเท่านั้นที่ให้เครดิตสำหรับการแปลง
คลิกสุดท้ายที่ไม่ได้กำกับ :
การรับส่งข้อมูลโดยตรงทั้งหมดจะถูกละเว้นและ 100% ของผลลัพธ์จะไปที่ช่องสุดท้ายที่ลูกค้าไปถึงเว็บไซต์ก่อนที่จะแปลง
การโต้ตอบครั้งแรก :
ผลที่ได้นั้นมาจากจุดสัมผัสแรก
เชิงเส้น :
ทุกจุดสัมผัสได้รับการยกย่องอย่างเท่าเทียมกัน
เวลาสลายตัว :
ยิ่งจุดสัมผัสล่าสุดคือเครดิตมากขึ้นเท่านั้น
ตำแหน่งตาม :
ในรุ่นนี้ 40% ของผลลัพธ์มีสาเหตุมาจากจุดสัมผัสสุดท้ายอีก 40% เป็นครั้งแรกและส่วนที่เหลือ 20% นั้นมีการกระจายอย่างเท่าเทียมกันระหว่างช่องทางกลาง
โมเดล Algotithmic
ค่าสเปปลีย์
ใช้ในทฤษฎีเกมค่านี้เป็นการประเมินการมีส่วนร่วมของผู้เล่นแต่ละคนในเกมสหกรณ์
การแปลงจะได้รับเครดิตไปยังช่องทางโดยกระบวนการเปลี่ยนรูปแบบการเดินทาง ในการเปลี่ยนแปลงแต่ละช่องจะมีการให้ช่องทางเพื่อประเมินว่ามันมีสาระสำคัญโดยรวมอย่างไร
ตัวอย่างเช่น ลองดูที่การเดินทางที่มีความเป็นอยู่ต่อไปนี้:
การค้นหาออร์แกนิก> Facebook> โดยตรง> $ 19 (เป็นรายได้)
เพื่อให้ได้ค่า Shapley ของแต่ละช่องเราต้องพิจารณาค่าการแปลงทั้งหมดสำหรับการเรียงสับเปลี่ยนส่วนประกอบของการเดินทางที่กำหนดนี้
การค้นหาออร์แกนิก> $ 7
Facebook> $ 6
โดยตรง> $ 4
การค้นหาออร์แกนิก> Facebook> $ 15
การค้นหาออร์แกนิก> โดยตรง> $ 7
Facebook> โดยตรง> $ 9
การค้นหาแบบออร์แกนิก> Facebook> โดยตรง> $ 19
จำนวน joneys ส่วนประกอบเพิ่มขึ้นอย่างทวีคูณช่องทางที่แตกต่างกันมากขึ้น: อัตราคือ 2^n (2 ถึงพลังของ N) สำหรับ ช่อง N
กล่าวอีกนัยหนึ่งมี 3 จุดสัมผัสที่แตกต่างกันมีการเรียงสับเปลี่ยน 8 ครั้ง ตัวอย่างเช่นมากกว่า 15 กระบวนการนี้ไม่สามารถทำได้
โดยค่าเริ่มต้นลำดับของจุดสัมผัสจะไม่ถูกนำมาพิจารณาเมื่อคำนวณค่า Shapley เฉพาะการมีอยู่หรือขาด เพื่อที่จะทำเช่นนั้นจำนวนการเรียงสับเปลี่ยน เพิ่มขึ้น
เมื่อคำนึงถึงสิ่งนั้นโปรดทราบว่ามันค่อนข้างยากที่จะใช้โมเดลนี้เมื่อพิจารณาลำดับของการโต้ตอบ สำหรับช่อง N ไม่เพียง แต่มีการเรียงสับเปลี่ยน 2^n ของช่องที่กำหนด I แต่ยัง รวมถึงการเปลี่ยนแปลงทุกครั้งที่มีฉันอยู่ในตำแหน่งที่แตกต่างกัน
ปัญหาและข้อ จำกัด บางประการของค่า Shapley
มาร์คอฟเชนเชน มาร์คอฟเป็นกระบวนการสุ่มโดยเฉพาะซึ่งการกระจายความน่าจะเป็นของสถานะถัดไปใด ๆ ขึ้นอยู่กับสถานะปัจจุบันโดยไม่คำนึงถึงสถานะก่อนหน้าและลำดับของพวกเขา
ในการใช้งานหลายช่องทางเราสามารถใช้โซ่มาร์คอฟเพื่อคำนวณความน่าจะเป็นของการมีปฏิสัมพันธ์ระหว่างคู่ของช่องทางสื่อกับ เมทริกซ์การเปลี่ยนแปลง
ในเรื่องเกี่ยวกับการมีส่วนร่วมของแต่ละช่องในการแปลง เอฟเฟกต์การกำจัด จะเกิดขึ้น: สำหรับแต่ละช่องทางของ Jorney จะถูกลบออกและคำนวณความน่าจะเป็นของการแปลง
ค่าที่เกิดจากช่องทางจากนั้นจะได้รับจากอัตราส่วนของความแตกต่างระหว่างความน่าจะเป็นของการแปลงโดยทั่วไปและความน่าจะเป็นเมื่อช่องดังกล่าวจะถูกลบออกไปในความน่าจะเป็นทั่วไปอีกครั้ง
กล่าวอีกนัยหนึ่งเอฟเฟกต์การกำจัดของช่องที่ใหญ่ขึ้นยิ่งมีส่วนร่วมมากขึ้นเท่านั้น
** เมื่อทำงานกับกระบวนการ Markovian ไม่มีข้อ จำกัด เนื่องจากปริมาณหรือลำดับของช่อง ลำดับของพวกเขาเองเป็นส่วนพื้นฐานของอัลกอริทึม
>> pip install marketing_attribution_models from marketing_attribution_models import MAM เมื่อ สร้าง แม่แบบ เฟรมข้อมูลสองวัตถุ MAM สามารถใช้เป็นอินพุตขึ้นอยู่กับค่าของพารามิเตอร์ group_channels คืออะไร
สำหรับการลดทอนนี้เราจะใช้กรอบข้อมูลที่ ยังไม่ได้จัดกลุ่ม การเดินทางโดยแต่ละแถวเป็นเซสชั่นที่แตกต่างกันและไม่มีรหัสการเดินทางที่ไม่ซ้ำกัน
หมายเหตุ: คลาส MAM มีพารามิเตอร์ในตัวสำหรับการสร้าง ID การเดินทาง, create_journey_id_based_on_conversion ว่าถ้าเป็น จริง ID จะถูกสร้างขึ้นตาม ID ผู้ใช้ป้อนเข้าพารามิเตอร์ group_channels_id_list และคอลัมน์ที่ระบุว่ามีการแปลงหรือไม่ ชื่อถูกกำหนดโดยพารามิเตอร์ JOURAGT_WITH_CONV_COLNAME
ในสถานการณ์นี้เซสชันทั้งหมดจากผู้ใช้ที่แตกต่างกันจะได้รับการสั่งซื้อและสำหรับการแปลงทุกครั้งจะมีการสร้าง ID การเดินทางใหม่ อย่างไรก็ตามเรา ขอแนะนำอย่างมาก ว่าการสร้าง ID การเดินทางครั้งนี้ได้รับการปรับแต่งตาม ความรู้เฉพาะสำหรับธุรกิจในมือ และข้อสรุปเชิงสำรวจ ตัวอย่างเช่นหากในธุรกิจที่กำหนดมีการระบุว่าระยะเวลาการเดินทางเฉลี่ยประมาณหนึ่งสัปดาห์อาจมีการกำหนดนักวิจารณ์ใหม่เพื่อให้เมื่อผู้ใช้ไม่มีปฏิสัมพันธ์ใด ๆ เป็นเวลาเจ็ดวันการเดินทางจะหยุดพักภายใต้สมมติฐาน ที่น่าสนใจ
สำหรับพารามิเตอร์ตอนนี้นี่คือวิธีการกำหนดค่าสำหรับ กลุ่ม _ channels ของเรา = สถานการณ์จริง:
attributions = MAM ( df ,
group_channels = True ,
channels_colname = 'channels' ,
journey_with_conv_colname = 'has_transaction' ,
group_channels_by_id_list = [ 'user_id' ],
group_timestamp_colname = 'visitStartTime' ,
create_journey_id_based_on_conversion = True )เพื่อที่จะสำรวจและทำความเข้าใจความสามารถของ MAM ได้มีการใช้ "ตัวสร้างข้อมูลแบบสุ่ม" ถูกนำมาใช้ผ่านการใช้พารามิเตอร์ แบบสุ่ม apparameter เมื่อตั้งค่าเป็น TRUE
attributions = MAM ( random_df = True )หลังจากสร้างวัตถุ MAM แล้วเราสามารถตรวจสอบฐานข้อมูลของเราได้ตอนนี้ด้วยการเพิ่ม JOURJIT_ID ของเราและด้วยเซสชั่นที่จัดกลุ่มใน การเดินทาง โดยใช้ ATTREUTE ".DATAFRAME"
attributions . DataFrame| Journey_id | channels_agg | time_till_conv_agg | converted_agg | Conversion_value | |
|---|---|---|---|---|---|
| 0 | id: 0_j: 0 | 0.0 | จริง | 1 | |
| 1 | ID: 0_J: 1 | Google Search | 0.0 | จริง | 1 |
| 2 | ID: 0_J: 10 | การค้นหาของ Google> ออร์แกนิก> การตลาดผ่านอีเมล | 72.0> 24.0> 0.0 | จริง | 1 |
| 3 | ID: 0_J: 11 | ออร์แกนิก | 0.0 | จริง | 1 |
| 4 | ID: 0_J: 12 | การตลาดผ่านอีเมล> Facebook | 432.0> 0.0 | จริง | 1 |
| - | - | - | - | - | - |
| 20341 | ID: 9_J: 5 | โดยตรง> Facebook | 120.0> 0.0 | จริง | 1 |
| 20342 | ID: 9_J: 6 | การค้นหาของ Google> การค้นหาของ Google> การค้นหาของ Google | 48.0> 24.0> 0.0 | จริง | 1 |
| 20343 | ID: 9_J: 7 | ออร์แกนิก> ออร์แกนิก> การค้นหาของ Google> การค้นหาของ Google | 480.0> 480.0> 288.0> 0.0 | จริง | 1 |
| 20344 | ID: 9_J: 8 | โดยตรง> อินทรีย์ | 168.0> 0.0 | จริง | 1 |
| 20345 | ID: 9_J: 9 | Google Search> Organic> Google Search> Emai ... | 528.0> 528.0> 408.0> 240.0> 0.0 | จริง | 1 |
แอตทริบิวต์นี้ได้ รับการอัปเดต สำหรับ ทุกรูปแบบที่มา ที่สร้างขึ้น เฉพาะในกรณีของแบบจำลองฮิวริสติกคอลัมน์ใหม่จะถูกผนวกเข้ากับค่าที่มาจากโมเดลดังกล่าว
หมายเหตุ: แอตทริบิวต์ . dataframe ไม่รบกวนการคำนวณแบบจำลองใด ๆ หากมีการเปลี่ยนแปลงโดยการใช้งานผลลัพธ์ต่อไปนี้จะไม่ได้รับผลกระทบ
attributions . attribution_last_click ()
attributions . DataFrame| Journey_id | channels_agg | time_till_conv_agg | converted_agg | Conversion_value | |
|---|---|---|---|---|---|
| 0 | id: 0_j: 0 | 0.0 | จริง | 1 | |
| 1 | ID: 0_J: 1 | Google Search | 0.0 | จริง | 1 |
| 2 | ID: 0_J: 10 | การค้นหาของ Google> ออร์แกนิก> การตลาดผ่านอีเมล | 72.0> 24.0> 0.0 | จริง | 1 |
| 3 | ID: 0_J: 11 | ออร์แกนิก | 0.0 | จริง | 1 |
| 4 | ID: 0_J: 12 | การตลาดผ่านอีเมล> Facebook | 432.0> 0.0 | จริง | 1 |
| - | - | - | - | - | - |
| 20341 | ID: 9_J: 5 | โดยตรง> Facebook | 120.0> 0.0 | จริง | 1 |
| 20342 | ID: 9_J: 6 | การค้นหาของ Google> การค้นหาของ Google> การค้นหาของ Google | 48.0> 24.0> 0.0 | จริง | 1 |
| 20343 | ID: 9_J: 7 | ออร์แกนิก> ออร์แกนิก> การค้นหาของ Google> การค้นหาของ Google | 480.0> 480.0> 288.0> 0.0 | จริง | 1 |
| 20344 | ID: 9_J: 8 | โดยตรง> อินทรีย์ | 168.0> 0.0 | จริง | 1 |
| 20345 | ID: 9_J: 9 | Google Search> Organic> Google Search> Emai ... | 528.0> 528.0> 408.0> 240.0> 0.0 | จริง | 1 |
โดยปกติปริมาณของข้อมูลที่ใช้งานได้นั้นกว้างขวางดังนั้นจึงเป็นไปไม่ได้หรือเป็นไปไม่ได้ที่จะวิเคราะห์ผลลัพธ์ที่เกิดจากการเดินทาง แต่ละครั้ง ด้วยการทำธุรกรรม อย่างไรก็ตามด้วยแอตทริบิวต์ group_by_channels_models อย่างไรก็ตามผลลัพธ์ทั้งหมดสามารถดูได้โดยจัดกลุ่มตามช่อง
หมายเหตุ : ผลลัพธ์ที่จัดกลุ่ม ไม่ได้เขียนทับ กันในกรณีที่ใช้โมเดลเดียวกันในสองกรณีที่แตกต่างกัน ทั้งสอง (หรือมากกว่า) ของพวกเขาจะแสดงใน " group_by_channels_models "
attributions . group_by_channels_models| ช่อง | attribution_last_click_heuristic |
|---|---|
| โดยตรง | 2133 |
| การตลาดผ่านอีเมล | 1033 |
| 3168 | |
| Google Display | 1073 |
| Google Search | 4255 |
| 1028 | |
| ออร์แกนิก | 6322 |
| YouTube | 1093 |
เช่นเดียวกับแอตทริบิวต์ . dataframe กลุ่ม _by_channels_models ยังได้รับการปรับปรุงสำหรับทุกรุ่นที่ใช้ โดยไม่มีข้อ จำกัด ในการไม่แสดงผลลัพธ์อัลกอริทึม
attributions . attribution_shapley ()
attributions . group_by_channels_models| ช่อง | attribution_last_click_heuristic | attribution_shapley_size4_conv_rate_algorithmic | |
|---|---|---|---|
| 0 | โดยตรง | 109 | 74.926849 |
| 1 | การตลาดผ่านอีเมล | 54 | 70.558428 |
| 2 | 160 | 160.628945 | |
| 3 | Google Display | 65 | 110.649352 |
| 4 | Google Search | 193 | 202.179519 |
| 5 | 64 | 72.982433 | |
| 6 | ออร์แกนิก | 315 | 265.768549 |
| 7 | YouTube | 58 | 60.305925 |
โมเดลฮิวริสติกทั้งหมดทำตัวเหมือนกันเมื่อใช้แอตทริบิวต์ . dataframe และ . group_by_channels_models ตามที่อธิบายไว้ก่อนหน้านี้และ ผลลัพธ์ ของ วิธีการของแบบจำลอง ฮิวริสติกทั้งหมดกลับ tuple ที่มีสอง ชุดแพนด้า
attribution_first_click = attributions . attribution_first_click ()ชุด แรก ของ tuple คือผลลัพธ์ใน การเดินทางที่ละเอียด คล้ายกับที่สังเกตในแอตทริบิวต์ . dataframe
attribution_first_click [ 0 ] 0 [1, 0, 0, 0, 0]
1 [1]
2 [1, 0, 0, 0, 0, 0, 0, 0, 0]
3 [1, 0]
4 [1]
...
20512 [1, 0]
20513 [1, 0, 0]
20514 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
20515 [1, 0, 0]
20516 [1, 0, 0, 0]
Length: 20517, dtype: object
อัน ที่สอง มีผลลัพธ์ที่ มีความละเอียดของช่อง ตามที่เห็นในแอตทริบิวต์. group_by_channels_models
attribution_first_click [ 1 ]| ช่อง | attribution_first_click_heuristic | |
|---|---|---|
| 0 | โดยตรง | 2078 |
| 1 | การตลาดผ่านอีเมล | 1095 |
| 2 | 3177 | |
| 3 | Google Display | 1066 |
| 4 | Google Search | 4259 |
| 5 | 1007 | |
| 6 | ออร์แกนิก | 6361 |
| 7 | YouTube | 1062 |
ของทุกรุ่นที่มีอยู่ในวัตถุ MAM เพียงคลิกล่าสุดคลิกแรกและเชิงเส้น ไม่มีพารามิเตอร์ที่ปรับแต่งได้ แต่ group_by_channels_models ซึ่งมี ค่าบูลีน ที่เมื่อตั้งค่าเป็น เท็จ
สร้างขึ้นเพื่อทำซ้ำคุณลักษณะเริ่มต้นของ Google Analytics ( คลิกสุดท้ายไม่ได้โดยตรง ) ซึ่ง การรับส่งข้อมูลโดยตรง ถูก เขียนทับ ในกรณีที่การแทรกแซงก่อนหน้านี้มีแหล่งข้อมูลเฉพาะนอกเหนือจากตัวเองโดยตรงในช่วงเวลาที่กำหนด (6 เดือนโดยค่าเริ่มต้น)
หากไม่ได้ระบุพารามิเตอร์ but_not_this_channel ถูกตั้งค่าเป็น 'โดยตรง' แต่สามารถตั้งค่าเป็นช่องทางอื่น ๆ ที่น่าสนใจสำหรับธุรกิจ
attributions . attribution_last_click_non ( but_not_this_channel = 'Direct' )[ 1 ]| ช่อง | attribution_last_click_non_direct_heuristic | |
|---|---|---|
| 0 | โดยตรง | 11 |
| 1 | การตลาดผ่านอีเมล | 60 |
| 2 | 172 | |
| 3 | Google Display | 69 |
| 4 | Google Search | 224 |
| 5 | 67 | |
| 6 | ออร์แกนิก | 350 |
| 7 | YouTube | 65 |
โมเดลนี้มีพารามิเตอร์ list_positions_first_middle_last ซึ่งน้ำหนักที่เกี่ยวข้องกับตำแหน่งของช่องในการเดินทางแต่ละครั้งสามารถระบุได้ตามการตัดสินใจ ที่เกี่ยวข้องกับธุรกิจ การแจกแจงเริ่มต้นของพารามิเตอร์คือ 40% สำหรับช่อง แนะนำ 40% สำหรับ การแปลง / ช่องสุดท้าย และ 20% สำหรับ อินเตอร์ เมดิส
attributions . attribution_position_based ( list_positions_first_middle_last = [ 0.3 , 0.3 , 0.4 ])[ 1 ]| ช่อง | attribution_position_based_0.3_0.3_0.4_heuristic | |
|---|---|---|
| 0 | โดยตรง | 95.685085 |
| 1 | การตลาดผ่านอีเมล | 57.617191 |
| 2 | 145.817501 | |
| 3 | Google Display | 56.340693 |
| 4 | Google Search | 193.282305 |
| 5 | 54.678557 | |
| 6 | ออร์แกนิก | 288.148896 |
| 7 | YouTube | 55.629772 |
มีการตั้งค่าที่ปรับแต่งได้สองครั้ง: อัตราการสลายตัว , throght พารามิเตอร์ Decay_over_time * และเวลา (ในชั่วโมง) ระหว่างแต่ละ decaiment ผ่านพารามิเตอร์ ความถี่
อย่างไรก็ตามเป็นที่น่าสังเกตว่าในกรณีที่มีจุดสัมผัสมากกว่าหนึ่งจุดระหว่างช่วงความถี่ค่าการแปลงจะถูกกระจายอย่างเท่าเทียมกันระหว่างช่องทางเหล่านี้
เป็นตัวอย่าง:
attributions . attribution_time_decay (
decay_over_time = 0.6 ,
frequency = 7 )[ 1 ]| ช่อง | attribution_time_decay0.6_freq7_heuristic | |
|---|---|---|
| 0 | โดยตรง | 108.679538 |
| 1 | การตลาดผ่านอีเมล | 54.425914 |
| 2 | 159.592216 | |
| 3 | Google Display | 64.350107 |
| 4 | Google Search | 192.838884 |
| 5 | 64.611414 | |
| 6 | ออร์แกนิก | 314.920082 |
| 7 | YouTube | 58.581845 |
Uppon ถูกเรียกว่าโมเดลนี้จะส่งคืน tuple ด้วย สี่ องค์ประกอบ สองคนแรก (จัดทำดัชนี 0 และ 1) เป็นเหมือนโมเดลฮิวริสติกโดยมีการเป็นตัวแทนของ . dataframe และ . group_by_channels_models ตามลำดับ สำหรับส่วนประกอบที่สามและสี่ (ดัชนี 2 และ 3) ผลลัพธ์คือ เมทริกซ์การเปลี่ยน และ ตารางเอฟเฟกต์การกำจัด
ในการเริ่มต้นมีความเป็นไปได้ที่จะระบุว่า การเปลี่ยนสถานะ เดียวกันได้รับการพิจารณาหรือไม่ ( เช่น โดยตรงไปยังโดยตรง)
attribution_markov = attributions . attribution_markov ( transition_to_same_state = False )| ช่อง | attribution_markov_algorithmic | |
|---|---|---|
| 0 | โดยตรง | 2305.324362 |
| 1 | การตลาดผ่านอีเมล | 1237.400774 |
| 2 | 3273.918832 | |
| 3 | YouTube | 1231.183938 |
| 4 | Google Search | 4035.260685 |
| 5 | 1205.949095 | |
| 6 | ออร์แกนิก | 5358.270644 |
| 7 | Google Display | 1213.691671 |
การกำหนดค่านี้ ไม่ส่งผลกระทบต่อ ผลลัพธ์โดยรวมสำหรับแต่ละช่อง แต่ค่าที่สังเกตได้ใน เมทริกซ์การเปลี่ยนแปลง เนื่องจากเราตั้งค่า transition_to_same_state เป็น เท็จ เส้นทแยงมุมซึ่งบ่งบอกถึงสถานะที่เปลี่ยนไปเป็นตัวเองจึงเป็นโมฆะ
ax , fig = plt . subplots ( figsize = ( 15 , 10 ))
sns . heatmap ( attribution_markov [ 2 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )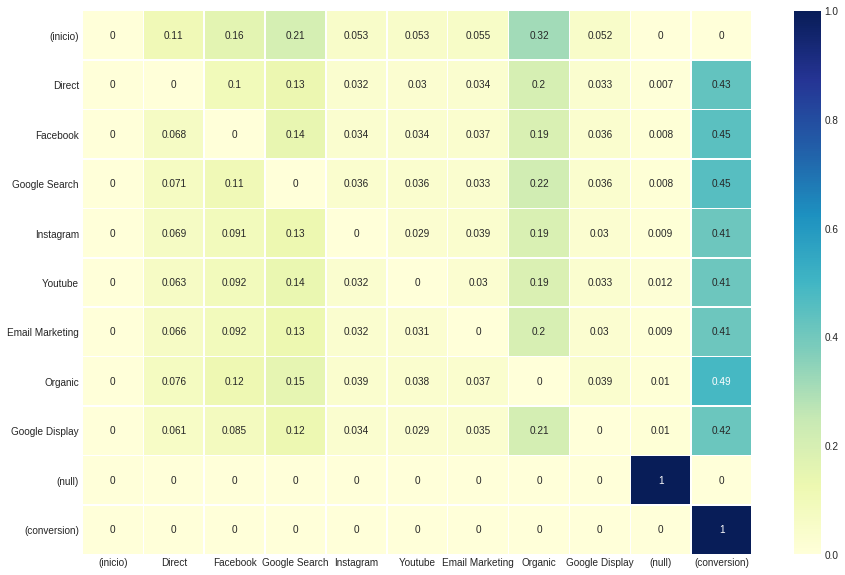
เอฟเฟกต์การกำจัด ซึ่งเป็นเอาท์พุท attribution_markov ที่สี่ได้มาจากอัตราส่วนของความแตกต่างระหว่างความน่าจะเป็นของการแปลงโดยทั่วไปและความน่าจะเป็นเมื่อช่องดังกล่าวถูกลบออกไปในความน่าจะเป็นทั่วไปอีกครั้ง
ax , fig = plt . subplots ( figsize = ( 2 , 5 ))
sns . heatmap ( attribution_markov [ 3 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )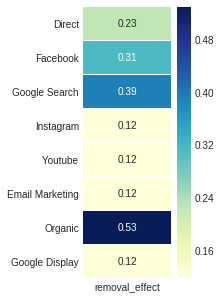
ในที่สุดโมเดลอัลกอริ ธ ที่สองของ MAM ซึ่งมีแนวคิดมาจาก ทฤษฎีเกม วัตถุประสงค์ที่นี่คือการแจกจ่ายการมีส่วนร่วมของผู้เล่นแต่ละคน (ในกรณีของเราช่องทาง) ในเกมความร่วมมือที่คำนวณโดยใช้การรวมกันของการเดินทางที่มีและไม่มีช่องทางที่กำหนด
ขนาด พารามิเตอร์กำหนดขีด จำกัด ของระยะ เวลา ที่ ห่วงโซ่ของช่อง ในทุกการเดินทาง โดยค่าเริ่มต้นค่าของมันถูกตั้งค่าเป็น 4 หมายถึงเฉพาะ สี่ช่องสุดท้ายก่อนหน้าการแปลง เท่านั้น
วิธีการคำนวณของการมีส่วนร่วมเล็กน้อยของแต่ละช่องทางอาจแตกต่างกันไปตามพารามิเตอร์ คำสั่งซื้อ โดยค่าเริ่มต้นจะถูกตั้งค่าเป็น เท็จ ซึ่งหมายความว่าการบริจาคจะถูกคำนวณโดยไม่คำนึงถึงลำดับของแต่ละช่องในการเดินทาง
attributions . attribution_shapley ( size = 4 , order = True , values_col = 'conv_rate' )[ 0 ]| การรวมกัน | การแปลง | Total_equences | Conversion_value | เชื่อมั่น | attribution_shapley_size4_conv_rate_order_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | โดยตรง | 909 | 926 | 909 | 0.981641 | [909.0] |
| 1 | โดยตรง> การตลาดผ่านอีเมล | 27 | 28 | 27 | 0.964286 | [13.948270234099155, 13.051729765900845] |
| 2 | โดยตรง> การตลาดผ่านอีเมล> Facebook | 5 | 5 | 5 | 1.000000 | [1.6636366232390172, 1.583583671498818, 1.752 ... |
| 3 | โดยตรง> การตลาดผ่านอีเมล> Facebook> Google D ... | 1 | 1 | 1 | 1.000000 | [0.2563402919193473, 0.2345560799963515, 0.259 ... |
| 4 | โดยตรง> การตลาดผ่านอีเมล> Facebook> Google S ... | 1 | 1 | 1 | 1.000000 | [0.2522517802130265, 0.2401286956930936, 0.255 ... |
| - | - | - | - | - | - | - |
| 1278 | YouTube> Organic> Google Search> Google Dis ... | 1 | 2 | 1 | 0.500000 | [0.2514214624662836, 0.24872101523605275, 0.24 ... |
| 1279 | YouTube> Organic> Google Search> Instagram | 1 | 1 | 1 | 1.000000 | [0.2544401477637237, 0.2541071889956603, 0.253 ... |
| 1280 | YouTube> Organic> Instagram | 4 | 4 | 4 | 1.000000 | [1.2757196742326997, 1.4712839059493295, 1.252 ... |
| 1281 | YouTube> Organic> Instagram> Facebook | 1 | 1 | 1 | 1.000000 | [0.2357631944623868, 0.2610913781266248, 0.247 ... |
| 1282 | YouTube> Organic> Instagram> Google Search | 3 | 3 | 3 | 1.000000 | [0.7223482210689489, 0.7769049003203142, 0.726 ... |
ในที่สุดพารามิเตอร์ที่ระบุว่าตัวชี้วัดใดที่ใช้ในการคำนวณค่า Shapley คือ values_col ซึ่งโดยค่าเริ่มต้นจะถูกตั้งค่าเป็น อัตราการแปลง ในการทำเช่นนั้นการเดินทาง โดยไม่มีการแปลง จะถูกนำมาใช้
อย่างไรก็ตามเป็นไปได้ที่จะพิจารณาเฉพาะ การแปลงตามตัวอักษร เมื่อใช้แบบจำลองดังที่เห็นด้านล่าง
attributions . attribution_shapley ( size = 3 , order = False , values_col = 'conversions' )[ 0 ]| การรวมกัน | การแปลง | Total_equences | Conversion_value | เชื่อมั่น | attribution_shapley_size3_conversions_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | โดยตรง | 11 | 18 | 18 | 0.611111 | [11.0] |
| 1 | โดยตรง> การตลาดผ่านอีเมล | 4 | 5 | 5 | 0.800000 | [2.0, 2.0] |
| 2 | โดยตรง> การตลาดผ่านอีเมล> การค้นหาของ Google | 1 | 2 | 2 | 0.500000 | [-3.1666666666666665, -7.6666666666666666, 11.8 ... |
| 3 | โดยตรง> การตลาดผ่านอีเมล> ออร์แกนิก | 4 | 6 | 6 | 0.666667 | [-7.83333333333333333, -10.8333333333333332, 22.6 ... |
| 4 | โดยตรง> Facebook | 3 | 4 | 4 | 0.750000 | [-8.5, 11.5] |
| - | - | - | - | - | - | - |
| 75 | Instagram> Organic> YouTube | 46 | 123 | 123 | 0.373984 | [5.833333333333332, 34.33333333333333, 5.83333 ... |
| 76 | Instagram> YouTube | 2 | 4 | 4 | 0.500000 | [2.0, 0.0] |
| 77 | ออร์แกนิก | 64 | 92 | 92 | 0.695652 | [64.0] |
| 78 | ออร์แกนิก> YouTube | 8 | 11 | 11 | 0.727273 | [30.5, -22.5] |
| 79 | YouTube | 11 | 15 | 15 | 0.733333 | [11.0] |
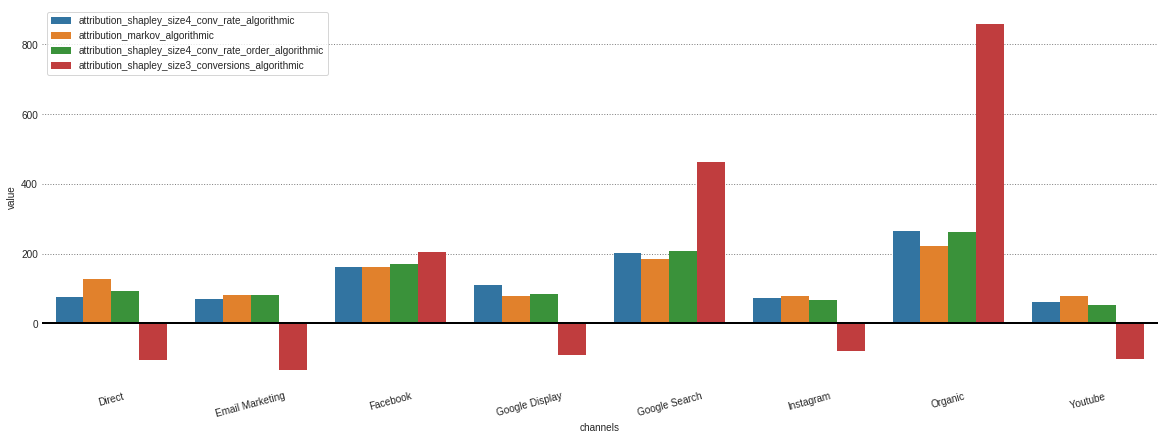
หลังจากได้รับการระบุแหล่งที่มาจากโมเดลที่แตกต่างกันที่เก็บไว้ในวัตถุ . group_by_channels_models ของเราแล้วมันเป็นไปได้ที่จะพล็อตและเปรียบเทียบผลลัพธ์สำหรับข้อมูลเชิงลึก
attributions . plot ()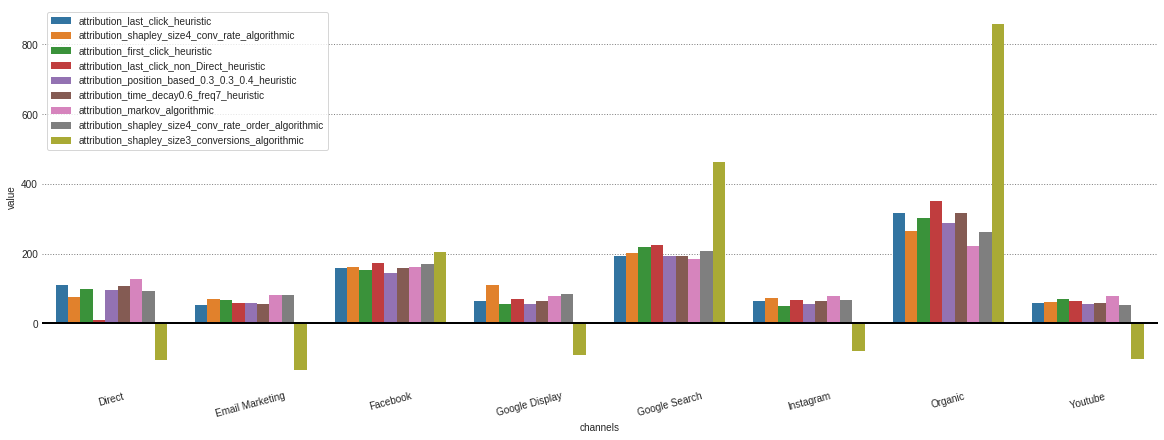
ในกรณีที่คุณสนใจเฉพาะรุ่นอัลกอริทึมฉันสามารถระบุสิ่งนี้ในพารามิเตอร์ model_type
attributions . plot ( model_type = 'algorithmic' )