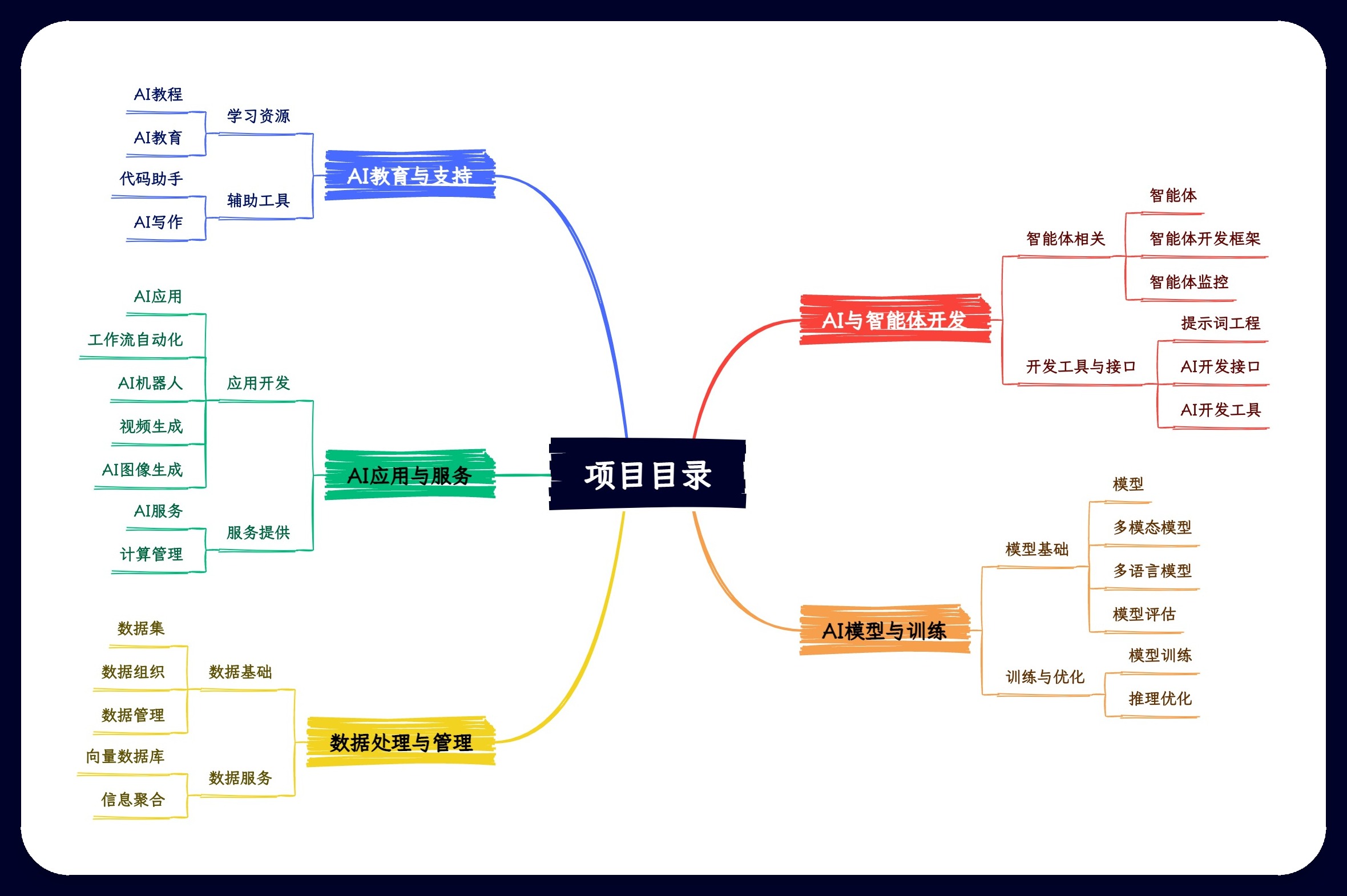
AI Resources Central
v1.0.0
การรวบรวมโครงการโอเพ่นซอร์สปัญญาประดิษฐ์ที่ยอดเยี่ยมทั่วโลก!
ภาษาอังกฤษ ภาษาจีนง่ายๆ
ยินดีต้อนรับสู่ AI Resource Central ! คลังสินค้าแห่งนี้มุ่งเน้นไปที่การรวมโครงการโอเพนซอร์สประดิษฐ์ที่ยอดเยี่ยม (AI) ที่ยอดเยี่ยมจากทั่วโลก ไม่ว่าคุณกำลังมองหาแรงบันดาลใจในการเริ่มโครงการของคุณเองหรือต้องการเรียนรู้วิธีการใช้เทคโนโลยี AI ล่าสุดนี่เป็นจุดเริ่มต้นที่ยอดเยี่ยม เรามุ่งมั่นที่จะจัดหานักพัฒนา AI นักวิจัยและผู้ที่ชื่นชอบด้วยแพลตฟอร์มในการสำรวจสื่อสารและแบ่งปันรหัสและการใช้งานโครงการ AI ต่างๆ
AI Resource Central
ร่างกายอัจฉริยะ
วิศวกรรมคำที่รวดเร็ว
อินเทอร์เฟซการพัฒนา AI
กรอบการพัฒนา Agile
แบบอย่าง
รายการ AI
การเพิ่มประสิทธิภาพการใช้เหตุผล
การรวมข้อมูล
ผู้ช่วยรหัส
การสอน AI
ระบบอัตโนมัติเวิร์กโฟลว์
หุ่นยนต์ AI
แบบหลายรูปแบบ
แบบหลายภาษา
การจัดระเบียบข้อมูล
บริการ AI
ฐานข้อมูลเวกเตอร์
การศึกษา AI
เครื่องมือพัฒนา AI
การฝึกอบรมแบบจำลอง
การสร้างภาพ AI
ชุดข้อมูล
การประเมินแบบจำลอง
การจัดการการคำนวณ
การเขียน AI
การตรวจสอบอัจฉริยะ
การสร้างวิดีโอ
การจัดการข้อมูล
แอปพลิเคชัน AI
วิศวกรรม AI
เป้า
แคตตาล็อกโครงการ
วิธีการมีส่วนร่วม
ใบอนุญาต
เป้าหมายหลักของเราคือ:
สร้างห้องสมุดโครงการ AI ที่ครอบคลุม : โครงการที่ครอบคลุมสาขาที่หลากหลายเช่นการเรียนรู้ของเครื่องการเรียนรู้อย่างลึกซึ้งและการประมวลผลภาษาธรรมชาติ
ส่งเสริมจิตวิญญาณของโอเพ่นซอร์ส : โดยแสดงให้เห็นถึงโครงการโอเพนซอร์สคุณภาพสูงผู้คนจำนวนมากได้รับการสนับสนุนให้เข้าร่วมในชุมชนโอเพนซอร์ส
ส่งเสริมนวัตกรรมทางเทคโนโลยี : จัดหากรณีและโซลูชั่นที่เป็นประโยชน์ให้นักพัฒนาและเร่งการใช้งานและการพัฒนาเทคโนโลยี AI
สนับสนุนการเรียนรู้และการพัฒนา : ให้โอกาสในทางปฏิบัติสำหรับผู้เรียนทุกระดับเพื่อช่วยให้พวกเขาเชี่ยวชาญเครื่องมือและเทคโนโลยี AI ล่าสุด
นี่คือรายการของโครงการ AI ที่เราเลือกบางส่วนตามฟิลด์ที่แตกต่างกัน:
Autogpt ที่สำคัญ - Gravitas/Autogpt - Autogpt ได้รับการออกแบบมาเพื่อให้ทุกคนสามารถใช้และพัฒนาปัญญาประดิษฐ์ ภารกิจของมันคือการจัดหาเครื่องมือให้ผู้คนมุ่งเน้นเรื่องสำคัญ
Geekan/MetAgpt - เฟรมเวิร์กหลายตัวแทนซอฟต์แวร์ AI แห่งแรกของ บริษัท มีวัตถุประสงค์เพื่อการเขียนโปรแกรมภาษาธรรมชาติ
Microsoft/Autogen - กรอบการเขียนโปรแกรมสำหรับปัญญาประดิษฐ์อัตโนมัติด้วยทรัพยากรที่เกี่ยวข้องเกี่ยวกับ PYPI, Discord และ Office Hour
Reworkd/AgentGpt - ประกอบกำหนดค่าและปรับใช้ตัวแทน AI อิสระในเบราว์เซอร์
JOAOMDMOURA/CREWAI - การสวมบทบาทและกรอบ AI AI AI AI ช่วยให้ตัวแทนสามารถทำงานร่วมกันและจัดการงานที่ซับซ้อน
Microsoft/Jarvis - Jarvis เป็นระบบที่ใช้ในการเชื่อมต่อแบบจำลองภาษาขนาดใหญ่ (LLMS) กับชุมชน Machine Learning (ML) (กระดาษ: https://arxiv.org/pdf/2303.17580.pdf)
MEM0AI/MEM0 - ชั้นจัดเก็บของแอพพลิเคชั่นปัญญาประดิษฐ์
Microsoft/Semantic-Kernel-รวมเทคโนโลยีรูปแบบภาษาขนาดใหญ่ที่ล้ำสมัยและง่ายดายและง่ายดายเข้ากับแอปพลิเคชันของคุณ
yoheinakajima/babyagi -
Openai/Swarm - การออกแบบตามหลักสรีรศาสตร์, กรอบการศึกษาการศึกษาแบบหลายตัวแทนที่มีน้ำหนักเบาจัดการโดยทีม OpenAI Solution
PHIDATAHQ/PHIDATA - สร้างตัวแทนหลายรูปแบบด้วยหน่วยความจำความรู้เครื่องมือและความสามารถในการใช้เหตุผลและการแชทผ่านส่วนต่อประสานผู้ใช้ตัวแทนที่สวยงาม
Transformeroptimus/superagi - Superagi เป็นนักพัฒนาโอเพ่นซอร์สเป็นครั้งแรกเฟรมเวิร์กการทำงานของระบบปัญญาประดิษฐ์อิสระที่ช่วยให้นักพัฒนาสามารถสร้างจัดการและเรียกใช้ตัวแทนอิสระที่มีประโยชน์ได้อย่างรวดเร็วและน่าเชื่อถือ
ComposioHQ/Composio - Composio มีการรวมกลุ่มที่มีคุณภาพสูงกว่า 100 รายการสำหรับตัวแทนปัญญาประดิษฐ์และโมเดลภาษาขนาดใหญ่ (LLMS) ผ่านการเรียกใช้ฟังก์ชั่น
CPACKER/MEMGPT - LETTA (เดิมชื่อ MEMGPT) กรอบการทำงานสำหรับการสร้างบริการรูปแบบภาษาขนาดใหญ่ (LLM) พร้อมความสามารถของหน่วยความจำ
Google-DeepMind/DeepMind-Research-ที่เก็บนี้มีรหัสการใช้งานและรหัสตัวอย่างสำหรับสิ่งพิมพ์ DeepMind
Botpress/Botpress - ศูนย์โอเพ่นซอร์สสำหรับการสร้างและปรับใช้ตัวแทน GPT/LLM
OpenMoss/Moss - รูปแบบภาษาการสนทนาโอเพนซอร์สที่พัฒนาโดย Fudan University และปรับปรุงด้วยเครื่องมือ
SMOL -AI/Developer - ห้องสมุดแรกที่ให้คุณฝังตัวแทนนักพัฒนาในแอปพลิเคชันของคุณเอง
OpenBMB/XAGENT - เอเจนต์รูปแบบภาษาอิสระสำหรับการแก้ปัญหาที่ซับซ้อน
Langchain -AI/Langgraph - สร้างตัวแทนภาษาที่ยืดหยุ่นในรูปแบบของกราฟ
E2B -DEV/E2B - Secure Open Source Cloud Runtime สำหรับแอปพลิเคชัน AI และพร็อกซี
ModelsCope/AgentsCope - สร้างแอพพลิเคชั่นหลายหน่วยงานได้ง่ายขึ้นด้วยโมเดลภาษาขนาดใหญ่ (LLMS)
homanp/superagent - เรียกใช้พร็อกซี AI ผ่าน API
aiwaves -cn/agent -
Frdel/Agent -Zero - Agent Zero Artificial Intelligence Framework
Microsoft/TinyTroupe - การจำลองบทบาทหลายหน้าที่ขับเคลื่อนด้วยโมเดลภาษาขนาดใหญ่ (LLM) เพื่อปรับปรุงจินตนาการและรับข้อมูลเชิงลึกทางธุรกิจ
QWENLM/QWEN -AGENT - เฟรมเวิร์กพร็อกซีและแอปพลิเคชันตามQWEN≥2.0พร้อมการเรียกใช้ฟังก์ชันล่ามโค้ดการสร้างการเพิ่มประสิทธิภาพการดึง (RAG) และฟังก์ชั่นส่วนขยายของโครเมี่ยม
OpenBMB/AgentVerse - AgentVerse ได้รับการออกแบบมาเพื่อปรับใช้ตัวแทนภาษาขนาดใหญ่หลายรูปแบบ (LLM) ในแอปพลิเคชันส่วนใหญ่ให้ความละเอียดงานและกรอบการจำลอง
Auto-Gravitas/Auto-GPT-Plugins-ปลั๊กอิน Auto-GPT
HuggingFace/Smolagents - Smolagents เป็นห้องสมุดพื้นฐานสำหรับตัวแทน ตัวแทนใช้มันเพื่อเขียนรหัส Python สำหรับการเรียกเครื่องมือและตัวแทน-orchestrating
Ironclad/Rivet - สภาพแวดล้อมการเขียนโปรแกรมปัญญาประดิษฐ์แบบโอเพนซอร์สและไลบรารี TypeScript
Gmpetrov/Databerry - แพลตฟอร์มไร้รหัสสำหรับการสร้างตัวแทนรูปแบบภาษาขนาดใหญ่ที่กำหนดเอง (LLM)
OpenBMB/BMTools - โซลูชันโอเพ่นซอร์สสำหรับเครื่องมือขนาดใหญ่การเรียนรู้ด้วยปลั๊กอิน ChatGPT
Langroid/Langroid - ใช้การเขียนโปรแกรมหลายตัวแทนเพื่อควบคุมโมเดลภาษาขนาดใหญ่
Muellerberndt/Mini -agi - Miniagi เป็นตัวแทนอิสระสากลที่ง่ายซึ่งอาศัย OpenAI API
Farama-Foundation/Pettingzoo-มาตรฐานแอพพลิเคชั่นการเรียนรู้ของโปรแกรมการเรียนรู้แบบหลายตัวแทน (API) รวมถึงสภาพแวดล้อมอ้างอิงและยูทิลิตี้ที่ใช้กันทั่วไป
Josh-XT/Agixt-Agixt เป็นแพลตฟอร์ม AI แบบไดนามิกที่ใช้หน่วยความจำแบบปรับตัวคุณสมบัติอัจฉริยะและระบบปลั๊กอินเพื่อจัดการคำแนะนำและดำเนินงานระหว่างผู้ขาย AI หลายรายเพื่อให้โซลูชั่น AI ที่มีประสิทธิภาพ
SOXOCPUTER/MOA - Agent Hybrid (MOA) ประสบความสำเร็จ 65.1% ในการประเมิน Alpaca (Alpacaeval) โดยใช้โมเดลซอฟต์แวร์โอเพนซอร์ซ
AgentOps -AI/Agentops - ชุดพัฒนาซอฟต์แวร์ Python (SDK) สำหรับการตรวจสอบ AI Agent, รูปแบบภาษาขนาดใหญ่ (LLM) การติดตามต้นทุนและการเปรียบเทียบ มันรวมเข้ากับโมเดลภาษาขนาดใหญ่และกรอบพร็อกซีที่หลากหลาย
Noahshinn/Reflexion - [Neurips 2023] "Reflexion: ตัวแทนภาษาขึ้นอยู่กับการเรียนรู้การเสริมแรงพูด"
SCISHARP/BOTSHARP - กรอบการทำงานหลายอย่างมีความหลากหลายใน. NET
dot -agent/nextpy -
การวนซ้ำ/ดาต้าเชน - การสกัด, การแปลง, การโหลด (ETL), การวิเคราะห์และการกำหนดเวอร์ชันของข้อมูลที่ไม่มีโครงสร้าง
Agiresearch/OpenAgi - OpenAgi: การเผชิญหน้ากับแบบจำลองภาษาขนาดใหญ่ (LLMS) กับผู้เชี่ยวชาญด้านโดเมน
Internlm/Lagent - กรอบที่มีน้ำหนักเบาสำหรับการสร้างพร็อกซีตามรุ่นภาษาขนาดใหญ่
Minedojo/Minedojo - ใช้ความรู้ระดับอินเทอร์เน็ตเพื่อสร้างร่างกายอัจฉริยะที่เป็นตัวเป็นตนแบบเปิด
Forethought -Technologies/Autochain - Autochain ใช้เพื่อสร้างตัวแทนรุ่นภาษาขนาดใหญ่ที่มีน้ำหนักเบาปรับขนาดได้และทดสอบได้ (LLM)
Landing-AI/VISION-AGENT-ตัวแทนภาพ
BCG-X-OFFICIAL/AgentKit-ชุดเริ่มต้นสำหรับการสร้างตัวแทนที่ถูก จำกัด โดยใช้ NextJS, Fastapi และ Langchain
Jina -AI/ThinkGPT - เทคโนโลยีพร็อกซีสำหรับการปรับปรุงรูปแบบภาษาขนาดใหญ่ (LLMS) และผ่านข้อ จำกัด
Farizrahman4u/loopgpt - เฟรมเวิร์กแบบแยกส่วนสำหรับอัตโนมัติ - Gpt
Farama -Foundation/Chatarena - Chatarena เป็นสภาพแวดล้อมการเล่นเกมหลายภาษาสำหรับรูปแบบภาษาขนาดใหญ่ (LLMs) ที่ออกแบบมาเพื่อพัฒนาความสามารถในการสื่อสารและการทำงานร่วมกันของปัญญาประดิษฐ์
Thudm/Agenttuning - การปรับแต่งตัวแทนให้ความสามารถของตัวแทนทั่วไปกับโมเดลภาษาขนาดใหญ่
Yifan-Song793/RESTGPT-พร็อกซีอัตโนมัติตามแบบจำลองภาษาขนาดใหญ่ควบคุมแอปพลิเคชันในโลกแห่งความเป็นจริงผ่าน RESTFUL API (อินเทอร์เฟซโปรแกรมการถ่ายโอนสถานะการถ่ายโอนสถานะ)
Link -Agi/Autoagents - ในการประชุมร่วมระหว่างประเทศปี 2024 เกี่ยวกับปัญญาประดิษฐ์ (IJCAI) บทบาท GPT ที่แตกต่างกันถูกสร้างขึ้นเพื่อจัดตั้งหน่วยงานร่วมกันเพื่อจัดการงานที่ซับซ้อน
AI-Engineer-Foundation/Agent-Protocol-นี่เป็นอินเทอร์เฟซทั่วไปที่มีปฏิสัมพันธ์กับตัวแทนปัญญาประดิษฐ์ซึ่งเป็นอิสระจากสแต็กเทคโนโลยีและสามารถใช้สำหรับกรอบการสร้างตัวแทนใด ๆ
KRENESKYP/IX - แพลตฟอร์มพร็อกซีสำหรับ GPT -4 อัตโนมัติ
F/Awesome-Chatgpt-Prompts-ห้องสมุดนี้จัดเรียงคำที่พรอมต์ CHATGPT เพื่อใช้เครื่องมือ CHATGPT และเครื่องมือ Language Language Language (LLM) อื่น ๆ
Plexpt/Awesome-Chatgpt-Prompts-ZH-คู่มือการฝึกอบรม Chatgpt Chinese คำแนะนำในการใช้สถานการณ์ต่าง ๆ เรียนรู้วิธีทำตามคำแนะนำของคุณ
Dair-AI/Prompt-Engineering-Guide-คู่มือเอกสารการบรรยายบันทึกย่อและทรัพยากรสำหรับการกระตุ้นวิศวกรรม
Stanfordnlp/dspy - DSPY: กรอบการทำงานสำหรับการเขียนโปรแกรมแบบจำลองการเขียนโปรแกรมภาษามากกว่าการแจ้งเตือน
Guidance -AI/Guidance - ภาษา bootstrapping สำหรับการควบคุมแบบจำลองภาษาขนาดใหญ่
เค้าโครง dev/โครงร่าง - การสร้างข้อความที่มีโครงสร้าง
MSHUMER/GPT-PROMPT-Engineer-
JXNL/ผู้สอน - เอาต์พุตที่มีโครงสร้างของแบบจำลองภาษาขนาดใหญ่ (LLMS)
BREXHQ/PROMPTINE -Engineering - เคล็ดลับและเทคนิคในการใช้ GPT - 4 ของ OpenAI และรุ่นภาษาขนาดใหญ่อื่น ๆ
Louisshark/chatgpt_system_prompt - ชุดของระบบ GPT พร้อมคำและความรู้เกี่ยวกับการฉีด/การรั่วไหล
Microsoft/Typechat - TypeChat เป็นห้องสมุดสำหรับการสร้างอินเทอร์เฟซภาษาธรรมชาติที่มีประเภท
SGL-Project/Sglang-Sglang เป็นกรอบการบริการที่รวดเร็วสำหรับรูปแบบภาษาขนาดใหญ่และโมเดลภาษาวิสัยทัศน์
MIT-HAN-LAB/Streaming-LLM-แบบจำลองภาษาสตรีมมิ่งที่มีประสิทธิภาพพร้อมการบรรจบกันของความสนใจ (ความสนใจที่จม) ที่เสนอในการประชุมนานาชาติปี 2024 เรื่องการเป็นตัวแทนการเรียนรู้ (ICLR)
SPDustin/chatgpt-autoexpert-คำสั่งที่กำหนดเองที่ได้รับการปรับปรุงสำหรับ chatgpt (ไม่เข้ารหัส) และการวิเคราะห์ข้อมูลขั้นสูงของ Chatgpt (การเข้ารหัส)
Civitai/Civitai - พื้นที่เก็บข้อมูลที่มีรูปแบบและข้อความผกผัน
Moonvy/OpenPromptStudio - AIGC Word Visual Editor |
Rockbenben/Chatgpt -Shortcut - เพิ่มประสิทธิภาพและผลผลิตสูงสุดด้วยทางลัด AI ปรับแต่งบันทึกและแบ่งปันเคล็ดลับและค้นหาเคล็ดลับสำหรับสถานการณ์ที่แตกต่างกันในชุมชนที่ใช้ร่วมกัน
Microsoft/Promptbase - ทุกอย่างที่เกี่ยวข้องกับโครงการพรอมต์
PrefecTHQ/Marvin - สร้างอินเทอร์เฟซ AI ที่น่าพอใจ
พรอมต์ FOO/PROMPTFOO - การทดสอบคำที่พรอมต์พร็อกซีและการสร้างการเพิ่มประสิทธิภาพการดึง (RAG) ในเวลาเดียวกันการทดสอบทีมสีแดงการทดสอบการเจาะและการสแกนช่องโหว่จะดำเนินการในรูปแบบภาษาขนาดใหญ่ (LLMS) เปรียบเทียบประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่และการกำหนดค่าอย่างง่ายผ่านบรรทัดคำสั่ง .
Princeton-NLP/Tree-of-Though-LLM-คิดเกี่ยวกับการใช้แบบจำลองภาษาขนาดใหญ่สำหรับการแก้ปัญหาโดยเจตนาในการประชุมระบบการประมวลผลข้อมูลระบบประสาท 2023 (Neurips 2023)
Pydantic/Pydantic -AI - พร็อกซีเฟรมเวิร์กหรือประชากรสำหรับการใช้ pydantic ในรูปแบบภาษาขนาดใหญ่ (LLMs)
1RGS/JSONFORMER - วิธีที่เชื่อถือได้ในการสร้าง JSON ที่มีโครงสร้างจากรูปแบบภาษา
Thunlp/OpenPrompt - เฟรมเวิร์กโอเพ่นซอร์สสำหรับการเรียนรู้ที่รวดเร็ว
Guardrails -AI/Guardrails - เพิ่มข้อ จำกัด ด้านความปลอดภัยหรือข้อ จำกัด ในรูปแบบภาษาขนาดใหญ่
ETH -SRI/LMQL - ภาษาที่โปรแกรมแบบจำลองภาษาขนาดใหญ่ (LLM) ได้อย่างมีประสิทธิภาพภายใต้คำแนะนำข้อ จำกัด
Prompttslab/Promptify - การควบคุมวิศวกรรมและเวอร์ชันพร้อมใช้งานโดยใช้ GPT หรือโมเดลที่ใช้พรอมต์อื่น ๆ เพื่อรับเอาต์พุตที่มีโครงสร้าง เข้าร่วม Discord สำหรับการวิจัยที่เกี่ยวข้อง
Shreyashankar/GPT3-Sandbox-โครงการนี้ได้รับการออกแบบมาเพื่อให้ผู้ใช้สามารถสร้างการสาธิตเว็บที่ยอดเยี่ยมด้วยรหัส Python ไม่กี่บรรทัดโดยใช้ OpenAI GPT-3 API ใหม่
Hegelai/Prompttools - เครื่องมือโอเพ่นซอร์สสำหรับการทดสอบการทดสอบ/การทดลองสนับสนุนโมเดลภาษาขนาดใหญ่ (เช่น OpenAI, Llama) และฐานข้อมูลเวกเตอร์ (เช่น Chroma, Weaviate, LancingB)
BigScience -Workshop/ProftsSource - ชุดเครื่องมือสำหรับการแจ้งเตือนภาษาธรรมชาติรวมถึงการสร้างการแบ่งปันและการใช้งาน
Yival/Yival - แอพพลิเคชั่นปัญญาประดิษฐ์ทั่วไปของคุณจะแจ้งผู้ช่วยวิศวกรรมโดยอัตโนมัติ
Microsoft/Prompt -Engine - ห้องสมุดที่ช่วยให้นักพัฒนาสร้างพรอมต์สำหรับรุ่นภาษาขนาดใหญ่
Ianarawjo/Chainforge - สภาพแวดล้อมโอเพ่นซอร์สสำหรับการเขียนโปรแกรมด้วยภาพสำหรับการทดสอบเคล็ดลับสำหรับแบบจำลองภาษาขนาดใหญ่ (LLMs)
SPCL/Graph-of-thoughts-การใช้งานอย่างเป็นทางการของ "MAP การคิด: การแก้ปัญหาที่ซับซ้อนด้วยโมเดลภาษาขนาดใหญ่"
ysymyth/react - [ICLR 2023] "React: การรวมเหตุผลและการกระทำในแบบจำลองภาษา"
Microsoft/Genaiscript - สคริปต์ปัญญาประดิษฐ์อัตโนมัติ (ปัญญาประดิษฐ์ทั่วไป)
JackMpCollins/Magentic - การรวมตัวของแบบจำลองภาษาขนาดใหญ่อย่างต่อเนื่องเข้ากับฟังก์ชั่น Python
Adieyal/SD -Dynamic -Prompts - สคริปต์ที่กำหนดเองที่เขียนขึ้นสำหรับ Automatic1111/เสถียร - การแพร่กระจาย - WebUI เพื่อสร้างภาษาเทมเพลตขนาดเล็กเพื่อสร้างคำที่รวดเร็วแบบสุ่ม
ZJUNLP/EasyEdit-กรอบการแก้ไขความรู้ที่ใช้งานง่ายสำหรับแบบจำลองภาษาขนาดใหญ่ (LLMS) ในการประชุมสมาคมภาษาศาสตร์การคำนวณ (ACL) ของอเมริกาปี 2024
Microsoft/AICI - AICI: พร้อมเป็นโปรแกรม WebAssembly
Zou -Group/TextGrad - TextGrad: ใช้โมเดลภาษาขนาดใหญ่เพื่อ backpropagate การไล่ระดับสีข้อความผ่าน "อนุพันธ์" ของข้อความอัตโนมัติ
Microsoft/Promptcraft -Robotics - ชุมชนของการใช้แบบจำลองภาษาขนาดใหญ่ (LLMS) ในสาขาหุ่นยนต์และเครื่องจำลองหุ่นยนต์ที่รวมเข้ากับ ChatGPT
GRESHAKE/LLM -Security - วิธีใหม่ในการทำลายโมเดลภาษาขนาดใหญ่สำหรับแอปพลิเคชันแบบบูรณาการ
NoAmgat/LM-Format-enforcer-เสริมความแข็งแกร่งของรูปแบบผลลัพธ์ของรูปแบบภาษา (เช่นรูปแบบ JSON, การแสดงออกปกติ ฯลฯ )
BER666/LLM -REASONERS - ห้องสมุดสำหรับการให้เหตุผลที่ซับซ้อนในรูปแบบภาษาขนาดใหญ่
JUJUMILK3/รั่วไหลของระบบ -Sompts-คอลเลกชันของระบบที่รั่วไหลออกมา
Laiyer-AI/LLM-Guard-ชุดเครื่องมือรักษาความปลอดภัยสำหรับการโต้ตอบแบบจำลองภาษาขนาดใหญ่
Hiyouga/FastEdit - แก้ไขรุ่นภาษาขนาดใหญ่ได้อย่างรวดเร็วใน 10 วินาที
TIMQIAN/OPENPROMPT.CO - สร้างใช้และแบ่งปันเคล็ดลับ CHATGPT
การสำรวจ/Spacy -LLM - รวมโมเดลภาษาขนาดใหญ่ (LLMS) เข้ากับกระบวนการประมวลผลภาษาธรรมชาติที่มีโครงสร้าง (NLP)
Protecttai/rebuff - รูปแบบภาษาขนาดใหญ่ (LLM) แจ้งให้เครื่องตรวจจับการฉีด
GetMetal/Motorhead - Motorhead เป็นเซิร์ฟเวอร์สำหรับรุ่นภาษาขนาดใหญ่ (LLMS) สำหรับหน่วยความจำและการดึงข้อมูล
Mirascope/Mirascope - แนวคิดบทคัดย่อภาษาขนาดใหญ่ (LLM) ที่ไม่ขัดขวาง
Cocacola -lab/chatie -
Jmorganca/Ollama - เริ่มต้นอย่างรวดเร็วด้วย Llama 3.3, Mistral, Gemma 2 และรูปแบบภาษาขนาดใหญ่อื่น ๆ
chatgptnextweb/chatgpt-next-web-chatgpt, gemini และส่วนต่อประสานผู้ใช้ข้ามแพลตฟอร์มอื่น ๆ (UI) ช่วยให้คุณมีแอปพลิเคชันภาษาขนาดใหญ่ (LLM) ของคุณเองในครั้งเดียวคลิก
XTEKKY/GPT4FREE - ที่เก็บ GPT4Free อย่างเป็นทางการมีแบบจำลองภาษาที่มีประสิทธิภาพที่หลากหลาย
Oobabooga/Text-Generation-Webui-ส่วนต่อประสานผู้ใช้เว็บ Gradio Web สำหรับรุ่นภาษาขนาดใหญ่ที่รองรับแบ็กเอนด์การอนุมานหลายครั้ง
RVC-BOSS/GPT-Sovits-หนึ่งนาทีของข้อมูลการพูดสามารถใช้ในการฝึกอบรมแบบจำลองการสังเคราะห์คำพูดที่ดี (TTS) (โคลนตัวอย่างขนาดเล็ก)
Gradio -App/Gradio - สร้างและแบ่งปันแอพพลิเคชั่นการเรียนรู้ของเครื่อง Python ที่ยอดเยี่ยม ต้องการสนับสนุน
McKaywrigley/chatbot -ui - ทุกรุ่นมีความสามารถในการแชท AI
Openai/Openai -Python - ห้องสมุด Python อย่างเป็นทางการสำหรับ Openai API
Danny-Avila/Librechat-รุ่นที่ได้รับการปรับปรุงของ ChatGPT พร้อมคุณสมบัติต่าง ๆ เช่น APIs ที่แตกต่างกันรุ่น AI และคุณสมบัติและเป็นโครงการโอเพ่นซอร์สโฮสต์ที่ใช้งานอยู่
Sunner/Chatall - แชทกับ chatbots หลายรายการ (เช่น chatgpt, bing chat ฯลฯ ) พร้อมกันเพื่อค้นหาคำตอบที่ดีที่สุด
Gaizhenbiao/Chuanhuchatgpt - อินเทอร์เฟซผู้ใช้กราฟิก (GUI) สำหรับ chatgpt API และรุ่นภาษาขนาดใหญ่จำนวนมาก (LLMs) มันมีฟังก์ชั่นต่าง ๆ เช่นตัวแทนและ QA ที่ใช้ไฟล์และมีส่วนต่อประสานผู้ใช้ที่สวยงาม
Copilotkit/Copilotkit - ตอบสนอง UI และโครงสร้างพื้นฐานที่สง่างามสำหรับแอพพลิเคชั่นปัญญาประดิษฐ์ที่หลากหลายเช่น Copilot, ตัวแทนในแอป, แชทบ็อตและพื้นที่ข้อความ
MLC-AI/WEB-LLM-เอ็นจิ้นการอนุมานแบบจำลองภาษาขนาดใหญ่ (LLM) ของเบราว์เซอร์สูง (LLM)
jina-ai/clip-as-service-ใช้คลิปเพื่อทำการฝังที่ปรับขนาดได้การให้เหตุผลและการเรียงลำดับภาพและประโยค
Chathub-dev/Chathub-ไคลเอนต์ chatbot แบบครบวงจร
Theramu/Fay - Fay เป็นเฟรมเวิร์ก Digital Human โอเพนซอร์ส มันมีเวอร์ชันที่แตกต่างกันสำหรับแอปพลิเคชันต่างๆ
Sashabaranov/Go -Openai - Go Wrapper สำหรับ Openai Chatgpt, GPT - 3, GPT - 4, Dall · E และ Whisper APIs
sillytaver/sillytaver - front -end สำหรับผู้ใช้ขั้นสูงในรูปแบบภาษาขนาดใหญ่ (LLM)
OpenAI/Openai -Node - ไลบรารี JavaScript/TypeScript อย่างเป็นทางการสำหรับ OpenAI API
Sebastianstarke/Ai4Animation - ใช้ Intelligence Computer เพื่อนำตัวละครมาสู่ความเป็นเอกภาพ
XIANGSX/GPT4FREE-TS-ให้บริการ OpenAI GPT-4 API ฟรีในโครงการจำลองของรุ่น TypeScript ของ XTEKKY/GPT4FREE
WZPAN/WUKONG -ROBOT - หุ่นยนต์ Wukong เป็นโครงการหุ่นยนต์บทสนทนาเสียง/สมาร์ทของจีนที่เรียบง่ายยืดหยุ่นและหรูหรา รองรับบทสนทนาหลายรอบ CHATGPT และอาจเป็นโครงการลำโพงอัจฉริยะโอเพนซอร์สแห่งแรกที่สนับสนุนการโต้ตอบระหว่างคอมพิวเตอร์สมอง
Yihong0618/Xiaogpt - เล่น CHATGPT และรุ่นภาษาขนาดใหญ่อื่น ๆ (LLM) พร้อมลำโพง Xiaomi Smart
NAT/OpenPlayground - สนามเด็กเล่นภาษาขนาดใหญ่ (LLM) ที่สามารถทำงานบนแล็ปท็อปได้
PostgresML/PostgresML - Postgres (ระบบการจัดการฐานข้อมูล) พร้อม GPU สำหรับการเรียนรู้ของเครื่องและแอพพลิเคชั่นปัญญาประดิษฐ์
Shaunwei/Realchar - สร้างปรับแต่งและมีการสนทนาแบบเรียลไทม์กับอักขระ/พันธมิตร AI ใช้เทคโนโลยีต่าง ๆ เพื่อให้ได้บทสนทนา AI ที่ราบรื่นทุกที่ทุกเวลา
Parisneo/Lollms -Webui - ส่วนต่อประสานผู้ใช้เว็บของรุ่นหลักของรุ่นภาษาขนาดใหญ่
Zhayujie/bot-on-anshing-ผู้สร้าง Chatbot ที่ใช้โมเดลขนาดใหญ่สามารถรวมโมเดลปัญญาประดิษฐ์ได้อย่างรวดเร็วเช่น Chatgpt, Claude และ Gemini เข้ากับแอพพลิเคชั่นซอฟต์แวร์และเว็บไซต์เช่น Telegram, Gmail, Slack
Deanxv/coze-discord-proxy-ผ่านบทสนทนา coze-bot proxy discord, ขอโมเดล GPT4 ผ่าน API, ให้ฟังก์ชั่นเช่นบทสนทนา, กราฟิกที่สร้างข้อความ, ข้อความกราฟิกที่สร้างขึ้นและการค้นหาฐานความรู้
VocodeDev/Vocode -Python - สร้างเอเจนต์รูปแบบภาษาขนาดใหญ่ (LLM) ขึ้นอยู่กับเสียงที่เป็นโมดูลและโอเพ่นซอร์ส
Alexrudall/Ruby -Openai - Openai API และ Ruby
AHMADBILALDEV/LUNAGI - ส่วนต่อประสานผู้ใช้ปัญญาประดิษฐ์ ส่วนประกอบ Tailwind โอเพ่นซอร์สสำหรับ GPT, ปัญญาประดิษฐ์กำเนิดและโครงการรูปแบบภาษาขนาดใหญ่ (LLM)
Ollama/Ollama -JS - Ollama JavaScript Library
Xusenlinzy/Api-for-Open-LLM-API สไตล์ OpenAI สำหรับรุ่นภาษาขนาดใหญ่แบบเปิด รองรับรุ่นต่าง ๆ เช่น Llama, Chatglm ฯลฯ
anse -app/anse - chatgpt, Dall - e และโมเดลการแพร่กระจายที่เสถียรเป็นประสบการณ์ที่ยอดเยี่ยม
MyLXSW/AIDEA-SERVER-AIDEA เป็นแอพอเนกประสงค์ที่รองรับ GPT แบบจำลองภาษาขนาดใหญ่ในประเทศ (เช่น Tongyi Qianwen และ Wenxin Yiyan) เช่นเดียวกับที่ใช้ในวรรณกรรมและชีวประวัติภาพชีวประวัติ SDXL1.0 การแพร่กระจายที่เสถียรเป็นพิเศษสำหรับความละเอียดและการระบายสีภาพ
Aallam/Openai-Kotlin-ไคลเอนต์ Kotlin Openai API ที่รองรับหลายแพลตฟอร์มและ coroutines
Guinmoon/LLMFARM - ใช้ห้องสมุด GGML สำหรับ Llama และรุ่นภาษาขนาดใหญ่อื่น ๆ ออฟไลน์บน iOS และ MacOS
Uezo/Chatdollkit - Chatdollkit ช่วยให้คุณสามารถแปลงรุ่น 3D ของคุณเองเป็น chatbots
Langchain -AI/Langchain - สร้างแอปพลิเคชันที่มีความสามารถในการให้เหตุผลการรับรู้สถานการณ์
NOMIC -AI/GPT4ALL - GPT4ALL สามารถเรียกใช้โมเดลภาษาขนาดใหญ่ในท้องถิ่น (LLMS) บนอุปกรณ์ใด ๆ เป็นโอเพ่นซอร์สและสามารถใช้เพื่อวัตถุประสงค์ในเชิงพาณิชย์
comfyanonymous/comfyui - โมเดลการแพร่กระจายที่ทรงพลังและโมดูลมากที่สุดมีอินเตอร์เฟสกราฟ/โหนดสำหรับอินเทอร์เฟซผู้ใช้กราฟิก (GUI), อินเทอร์เฟซโปรแกรมแอปพลิเคชัน (APIs) และแบ็กเอนด์
Langgenius/DIFY - DIFY เป็นแพลตฟอร์มการพัฒนาแอปพลิเคชัน Open Source Language Language Model (LLM) ที่มีอินเตอร์เฟสที่ใช้งานง่ายและฟังก์ชั่นที่หลากหลายเพื่อให้ตระหนักถึงกระบวนการจากการผลิตต้นแบบอย่างรวดเร็วไปจนถึงการผลิต
Lobehub/Lobe -Chat - Lobe Chat เป็นกรอบการแชทปัญญาประดิษฐ์โอเพ่นซอร์สพร้อมการออกแบบที่ทันสมัย รองรับผู้ขาย AI หลายฐานความรู้และหลายรูปแบบและสามารถปรับใช้แอปพลิเคชันแชทส่วนตัวได้ฟรีด้วยคลิกเดียว
LogSpace-AI/Langflow-Langflow เป็นตัวสร้างแอปพลิเคชันต่ำแบบจำลองที่ไม่ขึ้นกับแบบจำลองสำหรับ RAG (การสร้างการเพิ่มประสิทธิภาพการดึง) และแอปพลิเคชัน AI หลายตัวแทน มันสามารถทำงานร่วมกับ API หรือฐานข้อมูลใด ๆ
run -llama/llama_index - llamaidex เป็นกรอบข้อมูลสำหรับแอปพลิเคชันรูปแบบภาษาขนาดใหญ่ (LLM)
Flowiseai/Flowise-สร้างกระบวนการ Language Language Language (LLM) ส่วนบุคคลของคุณโดยใช้อินเทอร์เฟซผู้ใช้แบบลากและวาง
Chatchat-space/langchain-chatchat-Langchain-Chatchat (เดิมชื่อ Langchain-Chatglm) เป็นแอปพลิเคชั่นการค้นหาที่เพิ่มขึ้น (RAG) และ Agent (Agent) ตาม Langchain, Chatglm, Qwen, Llama, ฯลฯ สำหรับความรู้ในท้องถิ่น รูปแบบภาษาขนาดใหญ่ (LLM)
Go -Skynet/Localai - โครงการโอเพ่นซอร์สที่สามารถแทนที่บริการเช่น Openai และ Claude มันสามารถทำงานบนฮาร์ดแวร์ของผู้บริโภคและทำงานต่าง ๆ เช่นการสร้างประเภทสื่อที่แตกต่างกัน
Infiniflow/Ragflow - Ragflow เป็นเครื่องยนต์ Open Source Rag (การสร้างการปรับปรุงการดึงข้อมูล) เพื่อทำความเข้าใจกับเอกสารอย่างลึกซึ้ง
MindSDB/MINDSDB - เครื่องมือค้นหาของ AGI เป็นแพลตฟอร์มสำหรับการสร้างปัญญาประดิษฐ์ที่สามารถเรียนรู้และตอบคำถามเกี่ยวกับข้อมูลสหพันธรัฐ
EMBEDCHAIN/EMBEDCHAIN - ชั้นจัดเก็บของแอปพลิเคชันปัญญาประดิษฐ์ของคุณ
SongQuanpeng/One -API - นี่คือการจัดการคีย์ OpenAI และระบบแจกจ่ายซ้ำ รองรับโมเดลภาษาขนาดใหญ่หลายรุ่น (LLMS) มีอินเทอร์เฟซผู้ใช้ภาษาอังกฤษ (UI) สามารถดำเนินการในไฟล์เดียวและมีอิมเมจนักเทียบท่าเพื่อการปรับใช้ที่ง่าย
Cinnamon/Kotaemon - เครื่องมือโอเพ่นซอร์สตามเทคโนโลยีการสร้างการเพิ่มการดึง (RAG) ที่สามารถใช้ในการแชทกับเอกสาร
Labring/FastGPT - FastGPT เป็นแพลตฟอร์มความรู้ที่ใช้โมเดลภาษาขนาดใหญ่ (LLMS) ที่ให้ฟังก์ชั่นหลายอย่างเพื่อพัฒนาและปรับใช้ระบบถามตอบได้อย่างง่ายดาย
Deepset -AI/Haystack - กรอบการเตรียมการปัญญาประดิษฐ์สำหรับการสร้างแอปพลิเคชันรูปแบบภาษาขนาดใหญ่ (LLM) สำหรับงานเช่นการค้นหา Augmented Generation (RAG) และ chatbots ด้วยวิธีการค้นหาขั้นสูง
Berriai/Litellm - Python SDK และ Proxy Server (LLM Gateway) สามารถเรียก API แบบจำลองภาษาขนาดใหญ่ (LLM) มากกว่า 100 รูปแบบในรูปแบบ OpenAI รวมถึง APIs เช่น Bedrock, Azure ฯลฯ
Flairnlp/Flair - กรอบพื้นฐานมากสำหรับการประมวลผลภาษาธรรมชาติระดับสูง
Langchain -AI/LANGCHAINJS - สร้างแอปพลิเคชันการใช้เหตุผลด้วยการรับรู้บริบท
Xenova/Transformers.js-เทคโนโลยีการเรียนรู้ของเครื่องจักรที่ทันสมัยสำหรับเครือข่ายช่วยให้ทำงานในเบราว์เซอร์ที่ไม่มีเซิร์ฟเวอร์ได้หรือไม่
Netease -Youdao/Qanything - คำถามและคำตอบตามอะไรก็ได้
H2OAI/H2OGPT - แชทส่วนตัวกับ GPT ในท้องถิ่นเอกสารสนับสนุนรูปภาพวิดีโอและเนื้อหาอื่น ๆ มันเป็นส่วนตัว 100% ตามโปรโตคอล Apache 2.0 รองรับ Ollama, Mixtral, Llama.cpp ฯลฯ และมีตัวอย่างในลิงค์ที่กำหนด
PathwayCom/LLM-APP-เทมเพลตคลาวด์พร้อมใช้งานสำหรับการสร้างการปรับปรุงการสร้าง (RAG), ท่อปัญญาประดิษฐ์และการค้นหาองค์กรสามารถประมวลผลข้อมูลเรียลไทม์, เป็นมิตรกับนักเทียบท่าและซิงโครไนซ์กับแหล่งข้อมูลต่างๆ
LUDWIG-AI/LUDWIG-เฟรมเวิร์กรหัสต่ำสำหรับการสร้างโมเดลปัญญาประดิษฐ์ที่กำหนดเองเช่นโมเดลภาษาขนาดใหญ่ (LLMS) และเครือข่ายประสาท
vercel/ai - สร้างแอพพลิเคชั่น AI ที่ใช้งานโดยใช้ React, Svelte, Vue และ Solid
Microsoft/PromptFlow - สร้างแอพพลิเคชั่นรูปแบบภาษาขนาดใหญ่ที่มีคุณภาพสูง (LLM) ผ่านการสร้างต้นแบบการทดสอบการปรับใช้และการตรวจสอบ
ไม่มีโครงสร้าง -IO/ไม่มีโครงสร้าง - ไลบรารีโอเพ่นซอร์สและ API สำหรับการสร้างท่อก่อนการประมวลผลแบบกำหนดเองเช่นการติดแท็กการฝึกอบรมหรืองานการผลิตในการเรียนรู้ของเครื่อง
DataElement/Bisheng - Bisheng เป็นแพลตฟอร์มการดำเนินงานและการบำรุงรักษา Language Language Model (LLM) สำหรับแอพพลิเคชั่นปัญญาประดิษฐ์ระดับองค์กร มันมีฟังก์ชั่นเช่นเวิร์กโฟลว์ปัญญาประดิษฐ์ (GENAI) การสร้างการปรับปรุงการดึง (RAG) และฟังก์ชั่นอื่น ๆ
Computer/OpenChatkit -
LLMware-AI/LLMware-เฟรมเวิร์กแบบครบวงจรสำหรับการสร้างท่อส่งการค้นหาระดับองค์กร (RAG) ระดับองค์กรโดยใช้โมเดลขนาดเล็กโดยเฉพาะ
leptonai/search_with_lepton - สร้างการสาธิตการค้นหาตามการสนทนาอย่างรวดเร็วโดยใช้ Lepton AI
DeepTrain-Community/Chatnio-โซลูชันปัญญาประดิษฐ์รุ่นต่อไปแบบครบวงจรโซลูชัน B/C-End แบบครบวงจรรองรับโมเดลที่หลากหลายและฟังก์ชั่นต่าง ๆ
chainlit/chainlit - สร้าง AI การสนทนาอย่างรวดเร็วในไม่กี่นาที
ModelsCope/ModelsCope - ModelsCope เปลี่ยนแนวคิดของโมเดลเป็นบริการสู่ความเป็นจริง
Deeppavlov/Deeppavlov-ห้องสมุดโอเพ่นซอร์สสำหรับการเรียนรู้อย่างลึกซึ้งและระบบการสนทนาแบบ end-to-end และ chatbots
langchain -ai/opengpts -
Taskingai/Taskingai - แพลตฟอร์มโอเพ่นซอร์สสำหรับการพัฒนาแอพพลิเคชั่นปัญญาประดิษฐ์พื้นเมือง
Wenda-LLM/Wenda-Wenda เป็นแพลตฟอร์มการโทรแบบจำลองภาษาขนาดใหญ่ (LLM) ที่ออกแบบมาเพื่อสร้างเนื้อหาอย่างมีประสิทธิภาพในสภาพแวดล้อมที่เฉพาะเจาะจงโดยคำนึงถึงข้อ จำกัด ของทรัพยากรการประมวลผลองค์กรส่วนบุคคลและขนาดกลางและขนาดกลาง ปัญหา.
Rustformers/LLM - ระบบนิเวศห้องสมุดสนิมที่ไม่ได้รับการดูแลรักษาสำหรับการจัดการแบบจำลองภาษาขนาดใหญ่ ดูรายละเอียดไฟล์ readme
Josstorer/RWKV -Runner - 8MB การจัดการ RWKV อัตโนมัติและเครื่องมือเริ่มต้นพร้อมอินเทอร์เฟซที่เข้ากันได้กับ OpenAI API RWKV เป็นรูปแบบภาษาขนาดใหญ่ที่เปิดกว้างและมีวางจำหน่ายทั่วไป
langchain4j/langchain4j - เวอร์ชัน Java ของ Langchain
OpenBMB/Toolbench - แพลตฟอร์มเปิดสำหรับการฝึกอบรมการบริการและการประเมินผลของแบบจำลองภาษาขนาดใหญ่สำหรับการเรียนรู้เครื่องมือ (ICLR'24 FOCE PAPER)
Microsoft/Flaml - ไลบรารีที่รวดเร็วสำหรับการเรียนรู้ของเครื่องอัตโนมัติ (AutomL) และการปรับพารามิเตอร์ นอกจากนี้ยังมีลิงค์สำหรับเข้าร่วม Discord (ซอฟต์แวร์แชท)
Microsoft/LMOPS - เทคโนโลยีทั่วไปสำหรับการตระหนักถึงความสามารถด้านปัญญาประดิษฐ์ผ่านโมเดลภาษาขนาดใหญ่ (LLMS) และแบบจำลองภาษาขนาดใหญ่หลายรูปแบบ (MLLMS)
LLM-Workflow-Engine/LLM-Workflow-Engine-Power CLI และ Workflow Manager สำหรับรุ่นภาษาขนาดใหญ่ (แพ็คเกจหลัก)
Timescale/Pgai - ชุดเครื่องมือเพื่อการพัฒนาที่ง่ายขึ้นของการค้นหาการค้นหา (RAG) การค้นหาความหมายและแอปพลิเคชัน AI อื่น ๆ โดยใช้ PostgreSQL
FreedomIntelligence/Llmzoo - LLM Zoo เป็นโครงการที่ให้ข้อมูลแบบจำลองและมาตรฐานการประเมินผลสำหรับแบบจำลองภาษาขนาดใหญ่
Casibase/Casibase - AI Cloud เป็นฐานความรู้ที่เพิ่มขึ้นจากการดึงข้อมูลโอเพนซอร์ส (RAG) คล้ายกับ Langchain รองรับหลายรุ่นและมีการสาธิต chatbots และผู้ใช้งานผู้ใช้ (UI)
getzep/zep - zep: พื้นฐานหน่วยความจำของสแต็ค AI ของคุณ
leptonai/leptonai - เฟรมเวิร์ก Python สำหรับการสร้างความซับซ้อนของการสร้างบริการปัญญาประดิษฐ์
Pezzolabs/Pezzo - แพลตฟอร์ม LLMOPS แบบโอเพ่นซอร์สนักพัฒนาซอฟต์แวร์แรกสำหรับการทำให้งานง่ายขึ้นในทุกด้านเช่นการออกแบบที่รวดเร็วและการจัดการเวอร์ชัน
Cheshire-Cat-AI/CORE-Microservices พร็อกซีปัญญาประดิษฐ์
Aurelio-Labs/Semantic-Router-ปัญญาประดิษฐ์ความเร็วสูงพิเศษสำหรับการตัดสินใจข้อมูลหลายรูปแบบและการประมวลผลอัจฉริยะ
Install-AI/VDP-Instill Core เป็นเครื่องมือโครงสร้างพื้นฐาน AI แบบเต็มสแต็คสำหรับข้อมูลโมเดลและการจัดวางท่อที่ทำให้กระบวนการสร้างแอพพลิเคชั่น AI-First หลายครั้งง่ายขึ้น
Intelligence/Intel-Extension-for-transformers-ใช้เทคโนโลยีการบีบอัดที่ทันสมัยเพื่อสร้าง chatbots ของคุณบนอุปกรณ์ของคุณอย่างรวดเร็วและเรียกใช้แบบจำลองภาษาขนาดใหญ่อย่างมีประสิทธิภาพบนแพลตฟอร์ม Intel
Griptape -AI/GRIPTAPE - กรอบ Python แบบแยกส่วนสำหรับตัวแทนปัญญาประดิษฐ์และเวิร์กโฟลว์ด้วยการใช้เหตุผลห่วงโซ่เครื่องมือและความสามารถของหน่วยความจำ
Run-Llama/LlamaIndexts-Data Framework สำหรับแอพพลิเคชั่น Language Model (LLM) ขนาดใหญ่โดยมุ่งเน้นไปที่โซลูชันฝั่งเซิร์ฟเวอร์
Agenta -AI/Agenta - แพลตฟอร์ม LLMOPS โอเพ่นซอร์สที่รวมสนามเด็กเล่น Word Playground, การจัดการคำที่รวดเร็ว, การประเมินแบบจำลองภาษาขนาดใหญ่ (LLM) และการสังเกตแบบจำลองภาษาขนาดใหญ่
Marella/Ctransformers - การผูก Python ที่จัดไว้สำหรับรุ่นหม้อแปลงใน C/C ++ ผ่านไลบรารี GGML
DevFlowinc/Trieve - โครงสร้างพื้นฐานที่ใช้ API ที่รวมการค้นหาคำแนะนำการค้นหา Augmented Generation (RAG) และการวิเคราะห์
Yangling0818/RPG-DiffusionMaster-[ICML 2024] เกมการแพร่กระจายบทบาทการแพร่กระจายของข้อความ (RPGS) ผ่านการวางแผนการวางแผนและการสร้างแบบจำลองภาษาขนาดใหญ่หลายรูปแบบ (LLMS)
Trypromptly/LLMStack - กรอบการทำงานแบบหลายสายพันธุ์ไร้รหัสสำหรับการสร้างตัวแทนรูปแบบภาษาขนาดใหญ่ (LLM) เวิร์กโฟลว์และแอปพลิเคชันโดยใช้ข้อมูลของคุณ
getzep/graphiti - สร้างกราฟความรู้แบบไดนามิกและการสืบค้นด้วยการรับรู้เวลา
Kimmeen/Time-LLM-การใช้งานอย่างเป็นทางการของ "Time-LLM: การทำนายอนุกรมเวลาโดยการเขียนโปรแกรมแบบจำลองภาษาขนาดใหญ่" ใน ICLR 2024
Floneum/Floneum - แบบจำลองสติปัญญาแบบทันทีควบคุมและประดิษฐ์ในภาษาสนิมที่ผ่านการฝึกอบรมมาก่อน
Jina-AI/Langchain-Serve-แอปพลิเคชัน Langchain ผลิตโดยใช้ Jina และ Fastapi
Squeezeailab/LLMCompiler - LLM Compiler (LLMCompiler) ที่เสนอในการประชุมนานาชาติ 2024 เกี่ยวกับการเรียนรู้ของเครื่อง (ICML) เป็นคอมไพเลอร์แบบจำลองภาษาขนาดใหญ่ (LLM) สำหรับการเรียกฟังก์ชั่นแบบขนาน
Andreibondarev/Langchainrb - สร้างแอปพลิเคชันที่ขับเคลื่อนด้วยโมเดลภาษาขนาดใหญ่ (LLM) โดยใช้ทับทิม
Psychic-API/RAG-Stack-ปรับใช้ทางเลือกส่วนตัวของ ChatGPT ทางเลือกใน Cloud Virtual Private Cloud (VPC) เชื่อมต่อกับฐานความรู้ขององค์กรของคุณและสนับสนุนโมเดลภาษาโอเพนซอร์สขนาดใหญ่ (LLMs)
DAGWORKS-INC/BURR-สร้างแอปพลิเคชันสำหรับการตัดสินใจเช่น chatbots และจัดการพวกเขาในโครงสร้างพื้นฐานของคุณเอง
Intellabs/Fastrag - การเพิ่มประสิทธิภาพการค้นหาที่มีประสิทธิภาพและกรอบการสร้าง
Sobelio/LLM-chain-"LLM-Chain" เป็นลังสนิมที่ทรงพลัง (ลังซึ่งสามารถเข้าใจได้ว่าเป็นฐานรหัส) ที่ใช้ในการสร้างโซ่ในรูปแบบภาษาขนาดใหญ่ใช้ข้อความสรุปและความสมบูรณ์ของงานที่ซับซ้อน
Microsoft/Windows-ai-Studio-
Vercel/Modelfusion - ไลบรารี TypeScript สำหรับการสร้างแอพพลิเคชั่นปัญญาประดิษฐ์
Axflow/Axflow - กรอบ TypeScript สำหรับการพัฒนาปัญญาประดิษฐ์
Gabrielchua/Ragxplorer - เครื่องมือโอเพ่นซอร์สสำหรับการสร้างภาพการสร้างการค้นหาการค้นหาของคุณ (RAG)
Parthsarthi03/Raptor - การดำเนินการอย่างเป็นทางการของ Raptor (Raptor) สำหรับการดึงข้อมูลองค์กรเหมือนต้นไม้ผ่านการประมวลผลนามธรรมแบบเรียกซ้ำ
Google/Generative-AI-Swift-ห้องสมุด Swift อย่างเป็นทางการสำหรับ Google Gemini API
PINECONE -IO/CANOPY - เฟรมเวิร์กการสร้างที่ปรับปรุงใหม่ (RAG) การดึงข้อมูลและ Engine Engine ที่ขับเคลื่อนโดย Pinecone
SafeVideo/Autollm - เปิดตัวแอพพลิเคชั่นเครือข่าย Language Model (LLM) ตามการค้นหา Augmented Generation (RAG) ในไม่กี่วินาที
Openai/Whisper - เปิดใช้งานการจดจำเสียงที่แข็งแกร่งผ่านการกำกับดูแลที่อ่อนแอขนาดใหญ่
CompVIS/STABLE-DIFFUSION-โมเดลการแพร่กระจายข้อความถึงภาพที่มีศักยภาพ
FacebookResearch/Llama - รหัสการอนุมานสำหรับรุ่น Llama
XAI-ORG/GROK-1-Grok เวอร์ชันสาธารณะได้รับการปล่อยตัว
ความเสถียร - AI/StabledIffusion - การสังเคราะห์ภาพความละเอียดสูงโดยใช้แบบจำลองการแพร่กระจายที่มีศักยภาพ
Karpathy/Nanogpt-ห้องสมุดที่ง่ายที่สุดและเร็วที่สุดสำหรับการฝึกอบรม/การปรับแต่งขนาดกลาง GPT
TencentArc/Gfpgan - Gfpgan มุ่งเน้นไปที่การสร้างอัลกอริทึมที่เป็นประโยชน์สำหรับการซ่อมแซมใบหน้าในสถานการณ์จริง
lllyasviel/controlnet -
Tatsu -LAB/Stanford_Alpaca - รหัสและเอกสารประกอบสำหรับการฝึกอบรมโมเดล Stanford Alpaca และสร้างข้อมูล
Meta -llama/llama3 - Meta Llama อย่างเป็นทางการ 3 เว็บไซต์ GitHub
ความเสถียร-AI/รุ่น Generative-แบบจำลองความเสถียร AI
Lucidrains/Vit -Pytorch - การใช้ Vision Transformer ใน Pytorch โดยใช้ตัวเข้ารหัสหม้อแปลงเพียงหนึ่งตัวเท่านั้นที่จะไปถึงระดับที่ทันสมัยที่สุด (SOTA) ในงานการจำแนกประเภทภาพ
Apple/ML-Stable-Diffusion-การแพร่กระจายที่เสถียรโดยใช้ Core ML บน Apple Silicon
FacebookResearch/Codellama - รหัสการอนุมานสำหรับโมเดล Codellama
Qwenlm/Qwen - ฐานรหัสอย่างเป็นทางการของ Qwen, Tongyi Qianwen เป็นรูปแบบภาษาขนาดใหญ่ที่เสนอโดย Alibaba Cloud
AI4Finance -Foundation/Fingpt - Fingpt - รูปแบบภาษาโอเพนซอร์สการเงินขนาดใหญ่ รูปแบบการฝึกอบรมที่วางจำหน่ายใน HuggingFace
สถานะของรัฐ/Mamba - สถาปัตยกรรม Mamba SSM
BlinkDL/RWKV -LM - RWKV เป็นเครือข่ายประสาทกำเริบ (RNN) ที่ทำงานได้ดีในรูปแบบภาษาขนาดใหญ่ (LLM) และสามารถฝึกฝนได้เหมือนหม้อแปลง GPT มันมีลักษณะของประสิทธิภาพที่ยอดเยี่ยมและเวลาเชิงเส้น
compvis/latent -diffusion - การสังเคราะห์ภาพความละเอียดสูงโดยใช้แบบจำลองการแพร่กระจายที่มีศักยภาพ
QWENLM/QWEN1.5 - Tongyi Qianwen 2.5 เป็นชุดภาษาขนาดใหญ่ที่พัฒนาโดยทีมงาน Alibaba Cloud Tongyi Qianwen
Lucidrains/Dalle2 -Pytorch - Dall เครือข่ายประสาทสำหรับการสังเคราะห์ข้อความและกราฟิกที่ใช้ OpenAI Update ใน Pytorch - E 2
NVIDIA/MEGATRON-LM-ยังคงทำการวิจัยเกี่ยวกับการฝึกอบรมขนาดใหญ่ของโมเดลหม้อแปลงขนาดใหญ่
Guoyww/Animatediff - การใช้งานอย่างเป็นทางการของ Animatediff
DataBrickslabs/Dolly - Databricks 'Dolly เป็นรูปแบบภาษาขนาดใหญ่ที่ได้รับการฝึกฝนบนแพลตฟอร์มการเรียนรู้ของเครื่อง Databricks
MLFoundations/Open_Clip-การใช้งานแบบโอเพ่นซอร์สของคลิป (การฝึกอบรมภาษาคอนทราสต์-ภาพล่วงหน้า)
Thudm/Cogvideo - ข้อความและรูปภาพไปยังการสร้างวิดีโอ: Cogvideox (2024) และ Cogvideo (การประชุมนานาชาติ 2023 เกี่ยวกับการเรียนรู้ลักษณะการเรียนรู้)
AIGC -Audio/Audiogpt - AudioGpt เกี่ยวข้องกับความเข้าใจและการสร้างเสียงดนตรีเสียงและอวตารที่พูด
NLPXUCAN/WIZARDLM - โมเดลภาษาขนาดใหญ่ (LLMS) ถูกสร้างขึ้นบน EVOL Insturct (คำแนะนำ EVOL): Wizardlm (รูปแบบภาษาพ่อมด), WizardCoder (ตัวเข้ารหัสตัวช่วยสร้าง), WizardMath (พ่อมดคณิตศาสตร์)
Lucidrains/denoising-diffusion-pytorch-การใช้แบบจำลองความน่าจะเป็นในการแพร่กระจาย denoising ใน pytorch
Thudm/Codegeex - CodeGeex เป็นรุ่นการสร้างรหัสหลายภาษาโอเพนซอร์ส (KDD 2023)
vaibhavs10/whisper-เร็วอย่างบ้าคลั่ง-
01-AI/YI-ชุดของแบบจำลองภาษาขนาดใหญ่ที่พัฒนาขึ้นจากพื้นดินโดยนักพัฒนา 01-AI
Lucidrains/Palm-RLHF-Pytorch-การใช้การเรียนรู้การเสริมความคิดเห็นของมนุษย์ (RLHF) คล้ายกับ CHATGPT บน PALM
Humanaigc/emo - ใช้โมเดลการแพร่กระจายของ Audio2Video เพื่อสร้างวิดีโอภาพบุคคลที่แสดงออก: ภาพบุคคลอิโมติคอนที่สดใส
alembics/disco -diffusion - ไม่มีคำอธิบายที่แปลได้
OpenLM -Research/Open_llama - Openllama เป็นแบบจำลองโอเพ่นซอร์สของ LLAMA 7B ของ Meta AI ที่มีข้อตกลงใบอนุญาตหลวมและได้รับการฝึกฝนในชุดข้อมูล Redpajama
OpenBMB/MINICPM - MINICPM3 - 4B รุ่นภาษาขนาดใหญ่ (LLM) ที่ขอบพร้อมประสิทธิภาพที่ดีกว่า GPT - 3.5 - เทอร์โบ
LargeWorldModel/LWM - โมเดลโลกขนาดใหญ่สำหรับการสร้างแบบจำลองข้อความและวิดีโอด้วยบริบทขนาดใหญ่นับล้าน
liheyoung/depth-anshing-"Deep Everything: ปลดปล่อยพลังของข้อมูลที่ไม่มีเครื่องหมายขนาดใหญ่" ซึ่งเป็นแบบจำลองพื้นฐานสำหรับการประมาณค่าความลึกบนพื้นฐานของภาพตาข้างเดียวในการประชุม 2024 เกี่ยวกับการมองเห็นคอมพิวเตอร์และการจดจำรูปแบบ (CVPR)
OpenAI/POINT -E - การแพร่กระจายของคลาวด์จุดใช้สำหรับการสังเคราะห์แบบจำลอง 3 มิติ
Google-Research/text-text-transfer-transformer-รหัสสำหรับกระดาษ "สำรวจขีด จำกัด ของการเรียนรู้การถ่ายโอนด้วยตัวแปลงข้อความเป็นข้อความรวม"
Lightning-AI/LIT-LLAMA-การใช้รูปแบบภาษา Llama ที่ใช้ Nanogpt รองรับคุณสมบัติที่หลากหลายเช่นกลไกความสนใจอย่างรวดเร็วการหาปริมาณการปรับแต่งและการฝึกอบรมล่วงหน้าและได้รับใบอนุญาตภายใต้ใบอนุญาต Apache 2.0
OpenGVLAB/LLAMA-ADAPTER-ในการประชุมนานาชาติ 2024 เรื่องการเรียนรู้ลักษณะการเรียนรู้ (ICLR), Llama ได้รับการปรับแต่งใน 1 ชั่วโมงเพื่อทำตามคำแนะนำโดยใช้พารามิเตอร์ 1.2 ล้าน
NVIDIA/DALI - ห้องสมุดการเร่งความเร็ว GPU (กราฟิก) มีการสร้างบล็อกและเอ็นจิ้นการดำเนินการที่ดีที่สุดสำหรับการประมวลผลข้อมูลเพื่อเร่งการฝึกอบรมการเรียนรู้อย่างลึกซึ้งและแอปพลิเคชันการอนุมาน
Allenai/Olmo - รหัส Olmo สำหรับการสร้างแบบจำลองการฝึกอบรมการประเมินผลและการใช้เหตุผล
Salesforce/Codegen - Codegen เป็นซีรี่ส์โอเพนซอร์สสำหรับการสังเคราะห์โปรแกรมที่ผ่านการฝึกอบรมเกี่ยวกับ TPU -V4 เทียบได้กับ OpenAI Codex
Lucidrains/X -Transformers - หม้อแปลงที่มุ่งเน้นอย่างกระชับและสมบูรณ์พร้อมลักษณะการทดลองจากหลายเอกสาร
SCIR-HI/HUATUO-LLAMA-MED-Chinese-Ben Cao (เดิมชื่อ Hua Tuo) ซึ่งเป็นห้องสมุดแบบจำลองที่ใช้ความรู้ทางการแพทย์จีนเพื่อปรับคำแนะนำเกี่ยวกับรูปแบบภาษาขนาดใหญ่
Luosiallen/Hatent-Consistency-Model-แบบจำลองความสอดคล้องแฝง: การสังเคราะห์ภาพความละเอียดสูงโดยการอนุมานขั้นตอนเล็ก ๆ
Microsoft/Biogpt -
Google-Research/SimClr-SimClrv2: โมเดลที่ดูแลตนเองขนาดใหญ่เป็นผู้เรียนกึ่งผู้ดูแลที่มีประสิทธิภาพ
LLSourcell/Doctor-Dignity-Doctor Dignity เป็นรูปแบบภาษาขนาดใหญ่ (LLM) ที่สามารถผ่านการตรวจสอบใบอนุญาตทางการแพทย์ของสหรัฐอเมริกา (USMLE), เป็นออฟไลน์, ข้ามแพลตฟอร์มและปกป้องความเป็นส่วนตัวของข้อมูลที่ดีต่อสุขภาพ
Google -Research/Multinerf - การเปิดตัวรหัสสำหรับ MIP - Nerf 360, Ref - Nerf และ Rawnerf
JAYMODY/PICOGPT - GPT ขนาดเล็กมากที่ใช้กับ NUMPY - 2 เวอร์ชัน
Google-Research/Albert-Albert เป็นรุ่นที่มีความคล่องตัวของ Bert (การเป็นตัวแทนของการเข้ารหัสแบบสองทิศทางจาก Transformers) สำหรับการเรียนรู้ด้วยตนเองของการเป็นตัวแทนภาษา
Project-Baize/Baize-Chatbot-ใช้ CHATGPT เป็นเวลาหลายชั่วโมงด้วย GPU เพียงหนึ่งเดียว
Salesforce/Codet5 - Codet5 ได้รับการออกแบบมาเพื่อให้การสนับสนุนสำหรับการทำความเข้าใจรหัสและการสร้างสำหรับโมเดลภาษาขนาดใหญ่ (LLMS) ของรหัสเปิด
FacebookResearch/JEPA - รหัส pytorch และรูปแบบสำหรับการเรียนรู้ที่ดูแลตนเองจากวิดีโอผ่านวิสัยทัศน์ - ขึ้นอยู่กับสถาปัตยกรรมการทำนายการฝังร่วม (V -JEPA)
PapersWithCode/Galai - ส่วนต่อประสานโปรแกรมแอปพลิเคชันของ Galactica
DVLAB -Research/Longlora - รหัสและเอกสารประกอบสำหรับ Longlora และ Longalpaca (ICLR 2024 รายงานทางวาจา)
Baaivision/Painter - Series และ Seggpt Series: Visual Basic Model จากสถาบันวิจัยปัญญาประดิษฐ์ (BAAI) (BAAI)
DataBricks/DBRX - ตัวอย่างโค้ดและทรัพยากรสำหรับรูปแบบภาษาขนาดใหญ่ DBRX สำหรับ DatAbricks
state -spaces/S4 - โมเดลลำดับพื้นที่สถานะที่มีโครงสร้าง
Google-Research/Electra-Electra Pre-Train Text Encoder เป็นตัวเลือกจำเพาะมากกว่าเครื่องกำเนิดไฟฟ้า
Eleutherai/Pythia - ศูนย์วิจัยการตีความและการเรียนรู้พลวัต
ISE -UIUC/MAGICODER - MAGICODER (ICML'24) ใช้การสร้างรหัสผ่านคำสั่งโอเพ่นซอร์ส (OSS - CRUSSTIC)
EPFLLM/Meditron - Meditron เป็นแบบจำลองภาษาโอเพ่นซอร์สทางการแพทย์ขนาดใหญ่
Metaglm/Finglm - Finglm มีจุดมุ่งหมายเพื่อสร้างโครงการสวัสดิการสาธารณะที่เปิดกว้างและโครงการทางการเงินที่ยั่งยืนเพื่อส่งเสริมการพัฒนา "AI+Finance" ผ่านโอเพนซอร์ส
Deepseek-AI/DEEPSEEK-LLM-DEEPSEEK MODEL LANGGUTION (LLM): จะมีคำตอบ
Allenai/Scispacy - ท่อและแบบจำลองที่สมบูรณ์สำหรับเอกสารทางวิทยาศาสตร์/ชีวการแพทย์
Apple/ML-4M-4M: การสร้างแบบจำลองหน้ากากหลายรูปแบบขนาดใหญ่
Google -Research/Language - ห้องสมุดที่ใช้ร่วมกันสำหรับโครงการโอเพ่นซอร์สของทีมปัญญาประดิษฐ์ของ Google
Google/MaxText - โมเดลภาษาขนาดใหญ่ JAX ขนาดใหญ่ที่เรียบง่ายและปรับขนาดได้ (LLM)
Netease -Youdao/Bcembedding - โมเดลโอเพ่นซอร์สสำหรับการดึงผลิตภัณฑ์ที่ปรับปรุงแล้ว (RAG) (การฝังและรีสอร์ท)
Shi -Labs/OneFormer - OneFormer ใน CVPR 2023 เป็นหม้อแปลงสำหรับการแบ่งส่วนภาพสากล
Google Research/Flan -
LXTGH/OMG-SEG-ฐานรหัส OMG-LLALAVA และ OMG-SEG เกี่ยวข้องกับ CVPR-24 (การประชุมการรับรู้และการรับรู้รูปแบบคอมพิวเตอร์-2024) และ Neurips-24 (การประชุมระบบการประมวลผลข้อมูลประสาท-2024)
Shi-labs/การกระจายอเนกประสงค์-การแพร่กระจายที่หลากหลาย: รูปแบบการแพร่กระจายที่รวมข้อความรูปภาพและตัวแปรเผยแพร่บนแพลตฟอร์ม preprint arxiv ในปี 2022 และนำเสนอในการประชุมนานาชาติเกี่ยวกับวิสัยทัศน์คอมพิวเตอร์ (ICCV) ในปี 2023
Time-series-foundation-models/lag-llama-lag-llama: วิธีการทำนายแบบจำลองพื้นฐานของอนุกรมเวลาที่น่าจะเป็น
OpenAI/LM-HUMAN-PREFERENCES-รหัสสำหรับเอกสารเกี่ยวกับรูปแบบภาษาที่ปรับแต่ง
IBM/DROMEDARY - DROMEDARY ได้รับการออกแบบให้เป็นแบบจำลองภาษาขนาดใหญ่ที่มีประโยชน์จริยธรรมและเชื่อถือได้
dauparas/proteinmpnn - รหัสกระดาษที่เรียกว่า ProteinMpnn
Shi-Labs/Neighborhood-Attention-Transformer-Transformer ความสนใจในละแวกใกล้เคียงที่ตีพิมพ์ใน Arxiv ในปี 2022 และ CVPR ในปี 2023 นอกจากนี้หม้อแปลงความสนใจในละแวกใกล้เคียงที่ตีพิมพ์ในอาร์กซ์ในปี 2565
Thudm/Swissarmytransformer - Swissarmytransformer เป็นห้องสมุดที่ยืดหยุ่นและทรงพลังสำหรับการพัฒนาตัวแปรหม้อแปลง
ctllllll/llm -toolmaker -
XWIN-LM/XWIN-LM-XWIN-LM: การจัดตำแหน่งแบบจำลองภาษาขนาดใหญ่ที่ทรงพลังมีความเสถียรและทำซ้ำได้
Microsoft/Tora - Tora (สำหรับ ICLR'24) เป็นตัวแทนแบบจำลองภาษาขนาดใหญ่ที่มีเครื่องมือแบบบูรณาการเพื่อแก้ปัญหาการใช้เหตุผลทางคณิตศาสตร์ที่ยากลำบาก
Salesforceaiesearch/Uni2TS - หม้อแปลงการทำนายอนุกรมเวลาสากลได้รับการฝึกฝนอย่างสม่ำเสมอ
REPORT/REPORTLM - แก้ไขรหัสการอนุมานซีรี่ส์และการกำหนดค่าแบบจำลอง
Hazyresearch/Safari - Convolution ในบริบทของการสร้างแบบจำลองลำดับ
Fighting41love/funnlp -
LINEXJLIN/GPTS - เคล็ดลับการรั่วไหลที่เกี่ยวข้องกับ GPT
E2B-DEV/Awesome-AI-Agents-ชุดตัวแทนอิสระสำหรับปัญญาประดิษฐ์
Eugeneyan/Open -LLM - รายการของแบบจำลองภาษาขนาดใหญ่แบบเปิด (LLMS) พร้อมใช้งานสำหรับการใช้งานเชิงพาณิชย์
Shubhamsaboo/Awesome-LLM-APPS-แอปพลิเคชันชุดภาษาขนาดใหญ่ (LLM) ที่ยอดเยี่ยมพร้อมความสามารถในการค้นหาที่ปรับปรุงการค้นหา (RAG) ที่ใช้ OpenAI, มานุษยวิทยา, ราศีเมถุนและโมเดลโอเพ่นซอร์ส
RUCAIBOX/LLMSURVEY - การสำรวจรูปแบบภาษาขนาดใหญ่หน้า GitHub อย่างเป็นทางการสำหรับรายงานการสำรวจนี้
Woooodyy/LLM-Agent-Paper-List-รายการเอกสารเกี่ยวกับการเพิ่มขึ้นและศักยภาพของตัวแทนตามแบบจำลองภาษาขนาดใหญ่: บทวิจารณ์เขียนโดย Xi Zhiheng (การแปล) และอื่น ๆ
Steven2358/Awesome-Generative-AI-รายชื่อโครงการและบริการปัญญาประดิษฐ์ร่วมสมัยร่วมสมัย
WGWANG/LLMS-in-China-รุ่นจีนขนาดใหญ่
Lonepatient/Awesome-Pretrained-Chinese-NLP-Models-ชุดของแบบจำลองที่มีคุณภาพสูงของจีนรุ่นที่มีคุณภาพสูงรุ่นขนาดใหญ่แบบจำลองหลายรูปแบบและแบบจำลองภาษาขนาดใหญ่
Tensorchord/Awesome -llmops - รายการเครื่องมือ LLMOPS ที่ยอดเยี่ยมมากมายที่เลือกสำหรับนักพัฒนา
OpenDilab/Awesome -RLHF - รายการทรัพยากรการเรียนรู้การเสริมแรงอย่างต่อเนื่องตามข้อเสนอแนะของมนุษย์
DSXIANGLI/DECRYPTPROMPT - บทสรุปของการประยุกต์ใช้โมเดลภาษาพรอมต์และภาษาขนาดใหญ่ (LLM), ข้อมูลและโมเดลโอเพ่นซอร์สและเนื้อหาที่สร้างจากปัญญาประดิษฐ์ (AIGC)
FreedomIntelligence/Medical_NLP - การแข่งขันการประมวลผลภาษาธรรมชาติ, ชุดข้อมูล, โมเดลขนาดใหญ่และเอกสาร
Archinetai/Audio-AI-Timeline-ไทม์ไลน์สำหรับรุ่น AI ที่สร้างขึ้นด้วยเสียงล่าสุดเริ่มต้นในปี 2023
Chiphuyen/Aie -Book - ทรัพยากรของวิศวกร AI และวัสดุเสริมสำหรับวิศวกรรมปัญญาประดิษฐ์ (Chip Hughn, 2025)
Egoalpha/Prompt-in-context-learning-ทรัพยากรคุณภาพสูงสำหรับการเรียนรู้บริบทและวิศวกรรมที่รวดเร็ว มาสเตอร์โมเดลภาษาขนาดใหญ่ที่มีการอัปเดตล่าสุดเช่น CHATGPT, GPT-3 และ FLANT5
Taranjeet/Awesome -Gpts - คอลเลกชันของ GPT ทั้งหมด (ตัวแปลงที่สร้างไว้ล่วงหน้า) ที่ผลิตโดยชุมชน
CFAHLGREN1/NATURAL-SQL-ชุดของรูปแบบภาษาขนาดใหญ่ที่มีประสิทธิภาพสูงถึง SQL
yokoffing/chatgpt -prompts - การจัดการคำที่รวดเร็วสำหรับ chatgpt และ bing ai
ggerganov/llama.cpp - การอนุมานภาษาขนาดใหญ่ (LLM) ใน C/C ++
ggerganov/whisper.cpp - รุ่นพอร์ตของรุ่น Whisper ของ OpenAI ที่เขียนใน C/C ++
Karpathy/LLM.C - ฝึกอบรมรูปแบบภาษาขนาดใหญ่ (LLM) โดยใช้ C/CUDA แบบเรียบง่าย
Mozilla -Ocho/LlamaFile - ใช้เพียงไฟล์เดียวเพื่อแจกจ่ายและเรียกใช้โมเดลภาษาขนาดใหญ่ (LLMS)
unslothai/unsloth-เพิ่มความเร็วในการปรับแต่งของ Llama 3.3, Mistral, PHI, Qwen 2.5 และ Gemma Models Language Language (LLMS) 2-5 ครั้งในขณะที่ใช้หน่วยความจำน้อยลง 70%
MLC-AI/MLC-LLM-เอ็นจิ้นการปรับใช้ภาษาขนาดใหญ่แบบสากล (LLM) พร้อมความสามารถในการรวบรวมการเรียนรู้ของเครื่อง (ML)
karpathy/llama2.c - อนุมาน llama 2 ในไฟล์ C บริสุทธิ์เดียว
Dao-Ailab/Flash-Attention-กลไกความสนใจที่รวดเร็วและมีประสิทธิภาพทั้งที่รวดเร็วและประหยัดหน่วยความจำ
Openai/Triton - ห้องสมุดการพัฒนาสำหรับภาษา Triton และคอมไพเลอร์
Microsoft/Bitnet - กรอบการอนุมานอย่างเป็นทางการสำหรับรุ่นภาษาขนาดใหญ่ 1 บิต (LLMS)
Ggerganov/GGML - ห้องสมุดเทนเซอร์สำหรับการเรียนรู้ของเครื่อง
NVIDIA/TENSORRT - NVIDIA TENSORRT เป็นชุดเครื่องมือพัฒนาซอฟต์แวร์ (SDK) สำหรับการใช้เหตุผลการเรียนรู้เชิงลึกที่มีประสิทธิภาพสูงใน NVIDIA GPU ที่เก็บนี้มีส่วนประกอบโอเพ่นซอร์ส
BigScience-Workshop/Petals-ใช้ภาษาขนาดใหญ่ (LLMS) ที่บ้านในลักษณะที่เหมือน bittorrent การปรับจูนและการอนุมานความเร็วเร็วกว่า 10 เท่า
NVIDIA/TENSORRT-LLM-TENSORRT-LLM ให้ Python API ที่ใช้งานง่ายสำหรับการกำหนดรุ่นภาษาขนาดใหญ่ (LLMS) และสร้างเครื่องยนต์ tensorrt ที่เหมาะสมสำหรับการอนุมาน GPU ที่มีประสิทธิภาพและมีรันไทม์ Python และ C ++ สำหรับการสร้าง Python เพื่อดำเนินการส่วนประกอบของเครื่องยนต์เหล่านี้
Intelligence-ANALYTICS/BIGDL-เร่งการอนุมานภาษาขนาดใหญ่ในท้องถิ่น (LLM) และการปรับแต่งอย่างละเอียดเกี่ยวกับ Intel XPUs และรวมเข้ากับกรอบที่เกี่ยวข้องต่างๆ
Intelligence-Analytics/Ipex-LLM-เร่งการอนุมานภาษาขนาดใหญ่ในท้องถิ่น (LLM) และการปรับแต่งอย่างละเอียดเกี่ยวกับ Intel XPU (โปรเซสเซอร์เร่งความเร็วสำหรับสถาปัตยกรรม Intel) และรวมเข้ากับเครื่องมือที่หลากหลาย
Timdettmers/Bitsandbytes - รูปแบบภาษาขนาดใหญ่ที่สามารถเข้าถึงได้ผ่านการหาปริมาณ K -bit ของ pytorch
Google/gemma.cpp - เอ็นจิ้นการอนุมานแบบสแตนด์อโลนที่มีน้ำหนักเบาสำหรับรุ่น Google Gemma
NVIDIA/CUTLASS - เทมเพลต CUDA สำหรับรูทีนย่อยพีชคณิตเชิงเส้น
Pytorch-LABS/GPT-FAST-ใช้รหัส Python น้อยกว่า 1,000 บรรทัดเพื่อใช้หม้อแปลง Pytorch ดั้งเดิมที่เรียบง่ายและมีประสิทธิภาพสำหรับการสร้างข้อความ
PANQIWEI/AUTOGPTQ - แพ็คเกจการหาปริมาณแบบจำลองภาษาขนาดใหญ่ที่ใช้อัลกอริทึม GPTQ ใช้งานง่ายและใช้งานง่าย
turboderp/exllamav2 - ไลบรารีการอนุมานที่รวดเร็วสำหรับการใช้งานรุ่นภาษาขนาดใหญ่ (LLMs) ในพื้นที่ของ GPU เกรดผู้บริโภคทั่วไป
OpenNMT/CTRANSLATE2 - เอ็นจิ้นการอนุมานรุ่น Fast Transformer
ZTXZ16/FASTLLM - ไลบรารีการเร่งความเร็ว C ++ Pure -Platform Language Model (LLM) ที่รองรับการโทร Python มันสามารถทำให้โมเดลระดับ Chatglm-6b ระดับเดียวเข้าถึงโทเค็นมากกว่า 10,000 ต่อวินาทีรองรับ GLM, Llama, Moss Basic Models และทำงานได้อย่างราบรื่นบนอุปกรณ์มือถือ
QWOPQWOP200/GPTQ-FOR-LLAMA-QUANTIZE LLAMA เป็น 4 บิตโดยใช้ GPTQ
VAINF/TORCH -PRUNING - [CVPR 2023] DepGraph: การตัดแต่งกิ่งสำหรับโครงสร้างโดยพลการ
Turboderp/exllama - เวอร์ชันการเขียนใหม่ของ Llama รุ่น HF Transformers สำหรับการวัดน้ำหนักด้วยประสิทธิภาพของหน่วยความจำมากขึ้น
Lucidrains/Vector-Quantize-Pytorch-quantization เวกเตอร์ (และสเกลาร์) ใน pytorch
MIT-HAN-LAB/LLM-AWQ-AWQ: ปริมาณการเปิดใช้งาน-รับรู้ปริมาณ (วิธีการ) สำหรับการบีบอัดและการเร่งความเร็วของแบบจำลองภาษาขนาดใหญ่ที่ได้รับรางวัลกระดาษที่ดีที่สุดในปี 2024 MLSYS
Jittor/Jittorllms - ไลบรารีการอนุมานแบบจำลอง Jittor มีลักษณะของประสิทธิภาพสูงข้อกำหนดการกำหนดค่าต่ำการสนับสนุนภาษาจีนที่ดีและการพกพา
FasterDecoding/Medusa - Medusa: เฟรมเวิร์กง่าย ๆ ที่เร่งการสร้างแบบจำลองภาษาขนาดใหญ่ (LLMs) ผ่านเทอร์มินัลการถอดรหัสหลายรายการ
Intel/Neural-Compressor-SOTA Low-Bit LLM Quantization (รวมถึง INT8/FP8/Int4/FP4/NF4) และ Sparseness เป็นเทคนิคการบีบอัดแบบจำลองชั้นนำสำหรับ tensorflow, pytorch และ onnx runtimes
Neuralmagic/SparsEML - ห้องสมุดที่อำนวยความสะดวกในการใช้งานง่าย ๆ ของเครือข่ายประสาทส่งผลให้รุ่นที่เร็วขึ้นและเล็กลง
IST-DASLAB/GPTQ-รหัสกระดาษในปริมาณการฝึกอบรมหลังการฝึกอบรมที่แม่นยำของหม้อแปลงไฟฟ้าก่อนการฝึกอบรม (GPT) ในการประชุมนานาชาติปี 2023 เกี่ยวกับการเรียนรู้ลักษณะการเรียนรู้ (ICLR) เรียกว่า "GPTQ"
Hazyresearch/Thunderkittens - กระเบื้องดั้งเดิมสำหรับเมล็ดที่รวดเร็ว
UTENSOR/UTENSOR - MICRO Machine Learning Library การอนุมานปัญญาประดิษฐ์
Pytorch -Labs/AO - Pytorch Native Quantization และ Sparseness สำหรับการฝึกอบรมและการใช้เหตุผล
Saharnooby/rwkv.cpp - INT4/Int5/Int8 และ FP16 การอนุมานบน CPU สำหรับรูปแบบภาษา RWKV
MIT-HAN-LAB/SmoothQuant-Smoothquant: การหาปริมาณหลังการฝึกอบรมที่แม่นยำและมีประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่
Lightning-AI/Lightning-Thunder-Thunder เป็นคอมไพเลอร์ Pytorch Source-to-Source ที่สามารถเพิ่มความเร็วของรุ่นได้มากถึง 40% และใช้แอคทูเอเตอร์ฮาร์ดแวร์ที่แตกต่างกันใน GPU หลายตัว
Pytorch-labs/segment-anhingthing-fast-เซ็กเมนต์สำหรับการให้เหตุผลแบบออฟไลน์แบทช์-เวอร์ชันอะไรก็ได้
VAHE1994/AQLM - ห้องสมุด Pytorch อย่างเป็นทางการซึ่งมีเอกสารสองฉบับเกี่ยวกับการบีบอัดแบบจำลองภาษาขนาดใหญ่อย่างมาก : //arxiv.org/abs/2405.14852)
Hao-ai-lab/lookaheaddecoding-ใช้การถอดรหัส lookahead เพื่อทำลายการพึ่งพาตามลำดับในการอนุมานแบบจำลองภาษาขนาดใหญ่ (LLM) (ICML 2024)
Horseee/LLM -Pruner - [Neurips 2023] โมเดลภาษาขนาดใหญ่ (เช่น Llama - 3/3.1, Llama - 2, Llama, ฯลฯ ) โครงสร้าง LLM - Pruner
KULESHOV/MINILLM - MINILLM เป็นระบบที่ใช้โมเดลภาษาขนาดใหญ่ที่ทันสมัย (LLM) บน GPU เกรดผู้บริโภคในวิธีที่น้อยที่สุด
Binary -Husky/GPT_ACADEMIC - ให้อินเทอร์เฟซแบบโต้ตอบเชิงปฏิบัติสำหรับแบบจำลองภาษาขนาดใหญ่ (LLMS) เช่น GPT/GLM โดยเฉพาะอย่างยิ่งการเพิ่มประสิทธิภาพการอ่านกระดาษการขัดและประสบการณ์การเขียน รองรับหลายฟังก์ชั่นและรวมหลายรุ่น
Imartinez/Privategpt - ใช้ GPT เพื่อโต้ตอบกับเอกสารเป็นการส่วนตัวไม่มีการละเมิดข้อมูล
Mintplex-Labs/Anything-LLM-แอปพลิเคชันเดสก์ท็อปและ Docker AI ได้รับการรวมเข้ากับการสร้างการเพิ่มการดึงข้อมูลในตัว (RAG) และ AI Proxy
Khoj-ai/khoj-มันเป็นสมองที่สองของปัญญาประดิษฐ์ที่สามารถรับคำตอบจากแหล่งต่าง ๆ สร้างตัวแทนที่กำหนดเองจัดงานอัตโนมัติและดำเนินการวิจัยและสามารถเปลี่ยนรูปแบบภาษาขนาดใหญ่ให้กลายเป็นสิ่งประดิษฐ์ส่วนตัวสำหรับอัจฉริยะฟรี
PROMTENTENTENER/LOCALGPT - แชทแบบส่วนตัวกับเอกสารท้องถิ่นผ่านรุ่น GPT ข้อมูลไม่ได้ออกจากอุปกรณ์
KaixIndelele/Chatpaper - ใช้ ChatGPT เพื่อเร่งการวิจัยทางวิทยาศาสตร์รวมถึงบทสรุปของเอกสารอาร์กซิฟการแปลระดับมืออาชีพการขัดเงาการทบทวนโดยเพื่อนและการตอบสนองต่อการทบทวนเพียร์
Assafelovic/GPT -Researcher - Autonomous Agent ตามรูปแบบภาษาขนาดใหญ่ (LLM) ดำเนินการวิจัยในท้องถิ่นและเว็บในหัวข้อใด ๆ และสร้างรายงานที่ครอบคลุมพร้อมการอ้างอิง
ARC53/DOCSGPT - Document Chatbots สามารถแชทกับข้อมูลปรับใช้ส่วนตัวและรวมความรู้เข้ากับเวิร์กโฟลว์ AI สำหรับการแบ่งปัน
Mayooear/GPT4-PDF-Chatbot-Langchain-GPT4 และ Langchain Chatbot สำหรับเอกสาร PDF ขนาดใหญ่
Danswer -AI/DANSWER - GEN - AI Chat สำหรับทีมเป็นเหมือน ChatGPT แต่สามารถได้รับความรู้พิเศษเกี่ยวกับทีม
Josstorer/ChatgptBox - รวม CHATGPT เข้ากับเบราว์เซอร์ของคุณอย่างลึกซึ้ง ทุกสิ่งที่คุณต้องการอยู่ที่นี่
FacebookResearch/Nougat - การประยุกต์ใช้ Nougat ในความเข้าใจด้านประสาทของเอกสารทางวิชาการ
Bhaskatripathi/PDFGPT - PDF GPT สามารถโต้ตอบกับเนื้อหา PDF ผ่านความสามารถของ GPT และเป็นโซลูชันโอเพ่นซอร์สที่มีประสิทธิภาพสำหรับการเปลี่ยน PDF ให้กลายเป็น chatbot
Whitead/Paper-Qa-เทคโนโลยีการค้นหาที่เพิ่มความแม่นยำสูง (RAG) สำหรับการตอบคำถามที่อ้างถึงตามวรรณกรรมทางวิทยาศาสตร์
Weaviate/verba - แชทบ็อตรุ่นค้นหา (RAG) ที่ใช้งานได้โดย Weaviate
Run -llama/Rags - ใช้ข้อมูลของคุณเพื่อสร้าง chatgpt ทั้งหมดเป็นภาษาธรรมชาติ
Muisedestiny/Zotero -GPT - GPT ตรงกับ Zotero
Madawei2699/Mygptreader - วิธีการที่ขับเคลื่อนด้วยชุมชนในการโต้ตอบกับหุ่นยนต์ปัญญาประดิษฐ์โดยใช้ CHATGPT
Swirlai/Swirl -Search - AI Search & Rag สามารถรับคำตอบได้ทันทีจากความรู้ของ บริษัท ในแอปพลิเคชันจำนวนมากในขณะที่มั่นใจว่าข้อมูลมีความปลอดภัยและการปรับใช้อย่างรวดเร็ว
Dvorka/Mindforger - บันทึกความคิดและตัวแก้ไข markdown
Kha-White/Manga-COR-ส่วนใหญ่ใช้สำหรับการจดจำตัวละครแบบออพติคอลตัวละครญี่ปุ่นในการ์ตูนญี่ปุ่น
NLMATICS/LLMSHERPA - อินเทอร์เฟซโปรแกรมแอปพลิเคชันนักพัฒนา (API) สำหรับการเร่งโครงการรูปแบบภาษาขนาดใหญ่ (LLM)
UCBEPIC/DOCETL - การประมวลผลข้อมูลและ ETL (การตัดสินใจการแปลงการโหลด) ระบบขับเคลื่อนด้วยโมเดลภาษาอัตโนมัติ (LLM)
KnowledGecanvas/ความรู้ - ความรู้เป็นเครื่องมือที่ใช้สำหรับการดำเนินการต่าง ๆ (เช่นการบันทึกการค้นหา ฯลฯ ) ของเว็บไซต์เอกสารและไฟล์
RotatemWeISS57/GPT-NEWSPAPER-ตัวแทนที่ใช้ GPT แบบอิสระที่สามารถสร้างหนังสือพิมพ์ส่วนบุคคลตามการตั้งค่าของผู้ใช้
NLMATICS/NLM-ingestor-ที่เก็บนี้ให้รหัสฝั่งเซิร์ฟเวอร์สำหรับการเชื่อมต่อ LLMSHERPA API และตัวแยกวิเคราะห์สำหรับรูปแบบไฟล์ที่แตกต่างกัน
Kha -White/Mokuro - อ่านการ์ตูนญี่ปุ่นพร้อมข้อความที่เลือกได้ในเบราว์เซอร์ของคุณ
Brucemacd/chatd - แชทกับเอกสารของคุณผ่าน AI ท้องถิ่น
Akshata29/entaoai - ใช้ข้อมูลของคุณเองเพื่อแชทและถามคำถาม อัปโหลดข้อมูลองค์กรอย่างรวดเร็วเพื่อใช้บริการ OpenAI เพื่อแชทและถามคำถามเกี่ยวกับข้อมูลที่อัปโหลด
ABI/screenshot-to-code-ใส่ภาพหน้าจอและแปลงเป็นรหัสที่กระชับ (HTML/tailwind/react/vue)
GPT-Engineer-ORG/GPT-Engineer-แพลตฟอร์มที่ใช้เทอร์มินัลสำหรับการประสบกับวิศวกรซอฟต์แวร์ปัญญาประดิษฐ์ซึ่งแตกต่างจาก https://gptengineer.app
Opendevin/Opendevin - OpenHands: ใช้ฟังก์ชั่นเพิ่มเติมด้วยรหัสน้อย
Pythongora-IO/GPT-Pilot-คนแรกที่กลายเป็นนักพัฒนาอย่างแท้จริงในด้านปัญญาประดิษฐ์
GetCursor/Cursor - โปรแกรมแก้ไขรหัสปัญญาประดิษฐ์
OpenBMB/ChatDev - สร้างซอฟต์แวร์ที่กำหนดเองตามแนวคิดภาษาธรรมชาติผ่านการทำงานร่วมกันแบบหลายตัวแทนกับโมเดลภาษาขนาดใหญ่ (LLM)
Paul -Gauthier/Aider - Aider เป็นโปรแกรมจับคู่ปัญญาประดิษฐ์ในเทอร์มินัล
TABBYML/TABBY - ผู้ช่วยการเข้ารหัส AI ที่โฮสต์ด้วยตนเอง
ต่อเนื่อง/ดำเนินการต่อ - ดำเนินการต่อเป็นผู้ช่วยรหัสปัญญาประดิษฐ์โอเพ่นซอร์ส มันสามารถเชื่อมต่อกับรุ่นและบริบทสำหรับการเติมข้อความอัตโนมัติที่กำหนดเองและแชทในรหัส VS และเจ็ตบราส
Stageai/Devika - Devika เป็นวิศวกรซอฟต์แวร์ปัญญาประดิษฐ์ตัวแทนที่สามารถเข้าใจคำแนะนำของมนุษย์แบ่งคำแนะนำดำเนินการวิจัยและเขียนรหัส เป้าหมายของมันคือการเป็นทางเลือกโอเพ่นซอร์สสำหรับ Devin ที่พัฒนาโดย Cognition AI และไม่มีเว็บไซต์อย่างเป็นทางการ
Emilwallner/Screenshot-to-Code-เครือข่ายประสาทสำหรับการแปลงรูปแบบการออกแบบเป็นเว็บไซต์คงที่
fauxpilot/fauxpilot - fauxpilot เป็นทางเลือกโอเพ่นซอร์สสำหรับเซิร์ฟเวอร์ GitHub Copilot
Eosphoros-AI/DB-GPT-กรอบการพัฒนาข้อมูลปัญญาประดิษฐ์พื้นเมืองกับ AWEL (Agistrator Workflow Expression Language) และตัวแทน
Princeton-NLP/SWE-Agent-SWE-Agent จะแก้ไขปัญหา GitHub โดยอัตโนมัติโดยใช้ GPT-4 หรือแบบจำลองภาษาอื่น ๆ และยังสามารถใช้เพื่อความปลอดภัยทางไซเบอร์ที่น่ารังเกียจหรือความท้าทายในการเขียนโปรแกรมที่แข่งขันได้ [Neurips 2024]
SINAPTIK-AI/PANDAS-AI-โต้ตอบกับฐานข้อมูลต่าง ๆ (SQL, CSV ฯลฯ ) และใช้ Pandasai เพื่อทำการวิเคราะห์ข้อมูลการสนทนาผ่านแบบจำลองภาษาขนาดใหญ่ (LLMS) และการค้นหา Augmented Generation (RAG)
Vanna -ai/Vanna - โต้ตอบกับฐานข้อมูล SQL ของคุณ สร้างคำสั่ง text-to-SQL ที่แม่นยำผ่านแบบจำลองภาษาขนาดใหญ่ (LLM) โดยใช้เทคโนโลยีการสร้างแบบใช้การค้นหา (RAG)
Shishirpatil/Gorilla - กอริลลา: การฝึกอบรมและการประเมินผลของแบบจำลองภาษาขนาดใหญ่สำหรับการเรียกใช้ฟังก์ชัน (การเรียกใช้เครื่องมือ)
CODOTA/TABNINE - AI Code Complete หมายถึงฟังก์ชั่นของระบบ AI เพื่อให้คำแนะนำหรือกลุ่มรหัสสมบูรณ์
Ther1d/shell_gpt - เครื่องมือการผลิตบรรทัดคำสั่งที่ขับเคลื่อนโดยโมเดลภาษาขนาดใหญ่ของ AI เช่น GPT -4 ช่วยให้งานเสร็จเร็วขึ้นและมีประสิทธิภาพมากขึ้น
Nutlope/AICOMMITS - อินเตอร์เฟสบรรทัดคำสั่ง (CLI) ที่ใช้ปัญญาประดิษฐ์เพื่อเขียนข้อมูลการส่ง GIT สำหรับคุณ
Greydgl/Pentestgpt - เครื่องมือทดสอบการเจาะที่ได้รับการเสริมพลังจาก GPT
Joshpxyne/GPT -MIGRATE - โยกย้ายโค้ดของคุณระหว่างเฟรมเวิร์กหรือภาษาได้อย่างง่ายดาย
Kuafuai/DevOpsGPT-ระบบการพัฒนาซอฟต์แวร์ที่ใช้พลังงานจากระบบสืบพันธุ์แบบหลายตัวแทนรวมโมเดลภาษาขนาดใหญ่ (LLMs) เข้ากับเครื่องมือ DevOps เพื่อเปลี่ยนข้อกำหนดภาษาธรรมชาติให้เป็นซอฟต์แวร์ที่รันได้สนับสนุนภาษาการพัฒนาใด ๆ และขยายรหัสที่มีอยู่
Di -Sukharev/OpenCommit - GPT wrapper สำหรับ Git สามารถสร้างข้อความที่กระทำใน 1 วินาทีโดยใช้โมเดลภาษาขนาดใหญ่ (LLM) ทำงานได้ดีกับ Claude 3.5 และรองรับโมเดลท้องถิ่น
SQLCHAT/SQLCHAT - ไคลเอนต์ SQL และตัวแก้ไขตามฟังก์ชั่นการแชทสำหรับทศวรรษหน้า
exafunction/codeium.vim - ทางเลือก Copilot ฟรีและเร็วสุดสำหรับ Vim และ Neovim
Varunshenoy/graphgpt - การอนุมานกราฟความรู้จากข้อความที่ไม่มีโครงสร้างโดยใช้ GPT - 3
Nutlope/Llamacoder - ผลิตภัณฑ์โอเพ่นซอร์สที่ผลิตโดย Claude สร้างขึ้นโดยใช้ LLAMA 3.1 405B
McKaywrigley/AI-Code-Translator-ใช้ประโยชน์จากปัญญาประดิษฐ์เพื่อแปลรหัสระหว่างภาษาต่าง ๆ
Shobrook/Adrenaline - โต้ตอบกับและแสดงภาพฐานรหัส
QWENLM/QWEN2.5 -CODER - Tongyi Qianwen 2.5 - Coder เป็นรุ่นรหัสของ Tongyi Qianwen 2.5
Ricklamers/GPT-Code-UI-การใช้งาน Open Source ของ OpenAI Code Code Interpreter
Gofireflyio/AIAC - เครื่องกำเนิดรหัสโครงสร้างพื้นฐานปัญญาประดิษฐ์
defog -ai/sqlcoder - รูปแบบภาษาที่ทันสมัยที่สุดสำหรับการแปลงปัญหาภาษาธรรมชาติเป็นแบบสอบถาม SQL
GPTScript -AI/GPTScript - สร้างผู้ช่วยปัญญาประดิษฐ์สำหรับการโต้ตอบกับระบบของคุณ
RootbeerComputer/Backend -Gpt -
MPOON/GPT-Repository-Loader-แปลง codebase เป็นรูปแบบภาษาขนาดใหญ่ (LLM) รูปแบบที่เป็นมิตรกับพรอมต์ที่สร้างขึ้นโดย GPT-4 เป็นหลัก
Canner/Wrenai - ตัวแทนข่าวกรองเทียมโอเพนซอร์ซช่วยให้ข้อมูลและทีมผลิตภัณฑ์สามารถโต้ตอบและแชทกับข้อมูลผ่านข้อความถึง SQL (ข้อความ - ถึง - SQL) เพื่อสร้างแผนภูมิสเปรดชีตรายงานและระบบธุรกิจอัจฉริยะ (BI)
NUS-APR/Auto-Code-Rover-วิศวกรซอฟต์แวร์อิสระที่เข้าใจโครงสร้างของโครงการนั้นทุ่มเทให้กับการปรับปรุงโปรแกรมอิสระ มันเสร็จสิ้นเปอร์เซ็นต์ของงานทั้งในการเปรียบเทียบและค่าใช้จ่ายน้อยกว่า $ 0.7 ต่องาน
FERN -API/FERN - ป้อน OpenAPI และส่งออก SDK (ชุดพัฒนาซอฟต์แวร์) และเอกสารประกอบ
Georgia-Tech-DB/EVADB-ระบบฐานข้อมูลแอปพลิเคชันขับเคลื่อนโดยปัญญาประดิษฐ์
Abanteai/Mentat - Mentat - ผู้ช่วยการเข้ารหัสปัญญาประดิษฐ์
EMCF/ENGSHELL - เชลล์ภาษาอังกฤษ (เชลล์) ขับเคลื่อนด้วยโมเดลภาษาขนาดใหญ่ (LLMS) ที่สามารถใช้กับระบบปฏิบัติการใด ๆ (OS)
AI -CITIZEN/SOLIDGPT - ปัญญาประดิษฐ์นักพัฒนาเพื่อค้นหาบทบาท
Context -LABS/Autodoc - ชุดเครื่องมือทดลองที่สร้างเอกสาร Codebase โดยอัตโนมัติโดยใช้โมเดลภาษาขนาดใหญ่ (LLMs) โดยอัตโนมัติ
Knuckleswtf/Scribe - สร้างเอกสาร API สำหรับมนุษย์จากฐานรหัส Laravel
Jina-AI/DEV-GPT-ทีมพัฒนาเสมือนจริงของคุณสามารถเป็นกลุ่มนักพัฒนาระยะไกลที่ทำงานเพื่อพัฒนาซอฟต์แวร์หรือโครงการอื่น ๆ ผ่านการทำงานร่วมกันเสมือนจริง
Pythongora -IO/Pythagora - สร้างการทดสอบอัตโนมัติสำหรับแอปพลิเคชัน Node.js โดยใช้แบบจำลองภาษาขนาดใหญ่ (LLMs) โดยไม่จำเป็นต้องให้นักพัฒนาเขียนโค้ดใด ๆ
ELI64S/ReadMe -AI - เครื่องกำเนิดไฟฟ้า ReadMe ขับเคลื่อนโดยปัญญาประดิษฐ์
Mattzcarey/Code-Review-GPT-การตรวจสอบรหัสโดยใช้โมเดลภาษาขนาดใหญ่ (GPT4, Sonnet 3.5) และ Embeddings ปรับปรุงคุณภาพของรหัสและตรวจจับข้อผิดพลาดในขั้นตอนก่อนการผลิตและการรวมอย่างต่อเนื่องกับ GitHub/Gitlab/Azure DevOps (CI)
SmallCloudai/Refact-WebUI สำหรับการปรับแต่งและการโฮสต์โอเพ่นซอร์สแบบจำลองการเข้ารหัสขนาดใหญ่
Eyelonmiz/React -agent - โอเพนซอร์ส React.js โมเดลภาษาขนาดใหญ่ (LLM) พร็อกซีแบบอิสระ (LLM)
Gorilla-LLM/Gorilla-CLI-รุ่นภาษาขนาดใหญ่ (LLMS) สำหรับอินเทอร์เฟซบรรทัดคำสั่ง (CLIS)
HuggingFace/LLM -VSCODE - การพัฒนาขับเคลื่อนด้วยรูปแบบภาษาขนาดใหญ่ (LLM) ใน VSCODE
Peterw/chat-with-github-repo-ที่เก็บนี้มีสคริปต์ Python สองตัวสำหรับการสร้าง chatbots ผ่าน Streamlit, Openai GPT-3.5-turbo และทะเลสาบ Deep ของ Activeloop
PARELLDDRIVE/SUDOLANG-LLM-SUPPORT-SUDOLANG MODEL LANGGUTION LANGGUTION (LLM) สนับสนุนในรหัส Visual Studio
Ricklamers/Shell -AI - อินเตอร์เฟสบรรทัดคำสั่ง (CLI) ขับเคลื่อนโดย Langchain สำหรับการสร้างและเรียกใช้คำสั่งเชลล์
Google/oss -fuzz -gen - ผ่าน OSS - Fuzz ขับเคลื่อนด้วยรูปแบบภาษาขนาดใหญ่ (LLM)
KANTORD/SEAGOAT - เครื่องมือค้นหารหัสความหมายที่ใช้วิธีการที่ต้องการในท้องถิ่น
OpenAutocoder/Agentless - วิธีการที่ไม่เป็นตัวแทนสำหรับการแก้ปัญหาการพัฒนาซอฟต์แวร์โดยอัตโนมัติ
Ferrislucas/PROMPTR-PROMPTR เป็นเครื่องมืออินเตอร์เฟสบรรทัดคำสั่ง (CLI) ที่สามารถแก้ไขฐานรหัสในภาษาอังกฤษที่เข้าใจง่าย
Microsoft/Generative-AI-for-beginners-21 หลักสูตรเพื่อเริ่มการสร้างโดยใช้ปัญญาประดิษฐ์กำเนิด ลิงค์: https://microsoft.github.io/generative-ai-for-beginners/
Openai/Openai -Cookbook - ตัวอย่างการใช้งานและคำแนะนำของ OpenAI API
MLABONNE/LLM-Course-หลักสูตรเชิงลึกพร้อมรูปแบบภาษาขนาดใหญ่ (LLMS) ที่มีแผนงานและสมุดบันทึก colab
RASBT/LLMS-from-Scratch-ค่อยๆใช้โมเดลภาษาขนาดใหญ่ที่มีลักษณะคล้ายแชท GPT (LLM) ใน Pytorch ตั้งแต่เริ่มต้น
Lutzroeder/Netron - เครื่องมือสร้างภาพสำหรับเครือข่ายประสาทการเรียนรู้ลึกและรูปแบบการเรียนรู้ของเครื่อง
Datawhalechina/Prompt-Engineering-for-Developers-บทนำเกี่ยวกับรูปแบบภาษาขนาดใหญ่ (LLM) สำหรับนักพัฒนารุ่นจีนเวอร์ชันภาษาจีนของหลักสูตร NG Model Series
Liguodongiot/LLM-ACTION-โครงการนี้มีวัตถุประสงค์เพื่อแบ่งปันหลักการทางเทคนิคและประสบการณ์การปฏิบัติที่เกี่ยวข้องกับโมเดลขนาดใหญ่ (วิศวกรรมโมเดลขนาดใหญ่และการใช้งานแอปพลิเคชันแบบจำลองขนาดใหญ่)
STAS00/ML -Engineering - Open Book on Machine Learning Engineering
Mikeroyal/Self-Hosting-Guide-คู่มือการโฮสต์ตนเอง: โฮสต์และจัดการแอพพลิเคชั่นซอฟต์แวร์ในพื้นที่โดยบุคคลหรือองค์กรครอบคลุมคลาวด์โมเดลภาษาขนาดใหญ่ (LLMS) และอื่น ๆ
HUA1995116/Awesome-AI-Painting-คอลเลกชันของวัสดุจิตรกรรมปัญญาประดิษฐ์รวมถึงแพลตฟอร์มในประเทศและต่างประเทศแบบฝึกหัดและข่าวเช่นการแพร่กระจายที่มั่นคง, ภาพเคลื่อนไหว, คาสเคดที่มั่นคง, เทอร์โบเทอร์โบ SDXL SDXL ที่มั่นคง)
Mooler0410/LLMSPracticalGuide - รายการแหล่งข้อมูลคู่มือที่เป็นประโยชน์สำหรับแบบจำลองภาษาขนาดใหญ่ (LLMs) รวมถึงต้นไม้ LLMS ตัวอย่างและเอกสาร
GoogleCloudPlatform/generative-ai - 谷歌云(Google Cloud)上使用Vertex AI中的Gemini进行生成式人工智能(Generative AI)的示例代码和笔记本。
kyrolabs/awesome-langchain - 使用LangChain框架的工具和项目的优秀列表。
microsoft/DeepSpeedExamples - DeepSpeed示例模型。
huggingface/alignment-handbook - 使语言模型符合人类和人工智能偏好的稳健方法。
trigaten/Learn_Prompting - 提示工程、生成式人工智能和大型语言模型(LLM)指南,由Learn Prompting提供。加入其Discord(一款聊天软件),获取最大的提示工程学习社区。
bbycroft/llm-viz - GPT风格大型语言模型的3D可视化。
ray-project/llm-numbers - 每个大型语言模型(LLM)开发者都应该知晓的数字。
luban-agi/Awesome-AIGC-Tutorials - 大型语言模型、人工智能绘画等方面的精选教程和资源。
georgezouq/awesome-ai-in-finance - 金融市场中一系列精心挑选的优秀大型语言模型(LLMs)、深度学习策略和工具。
howl-anderson/unlocking-the-power-of-llms - 使用提示(Prompts)和链(Chains)使ChatGPT成为强大的生产力工具。释放大型语言模型(LLMs)的潜力。
ashishpatel26/LLM-Finetuning - 使用PEFT(参数高效微调)对大型语言模型(LLM)进行微调。
ray-project/llm-applications - 一份面向生产开发基于检索增强生成(RAG)的大型语言模型(LLM)应用的综合指南。
premAI-io/state-of-open-source-ai - 在开源创新这个混乱又快节奏的世界里,需要有清晰的思路。
pionxzh/chatgpt-exporter - 导出并分享你的ChatGPT聊天记录。
ianand/spreadsheets-are-all-you-need -
majacinka/crewai-experiments - 使用本地模型和可通过应用程序接口(API)访问的模型进行实验。
thu-vu92/local-llms-analyse-finance -
KillianLucas/open-interpreter - 计算机的自然语言界面。
StanGirard/quivr - 用于将生成式人工智能(GenAI)集成到应用中的有主见的检索增强生成(RAG)技术,重点关注产品。可在现有产品中轻松集成并定制,并且在大型语言模型(LLM)、向量存储和文件方面具有多功能性。
danielmiessler/fabric - Fabric是一个开源的人工智能增强人类框架,它具有模块化结构,可通过众包人工智能提示来解决问题。
openai-translator/openai-translator - 使用ChatGPT API进行翻译的浏览器和桌面应用程序。
Skyvern-AI/skyvern - 使用大型语言模型(LLMs)和计算机视觉技术实现基于浏览器的任务自动化。
activepieces/activepieces - 您最友好的开源人工智能自动化工具。它是一个具有200多种集成的工作流自动化工具,是企业自动化方面Zapier的替代品。
OthersideAI/self-operating-computer - 一种供多模态模型操作计算机的框架。
microsoft/UFO - 一个专注于用户界面的Windows操作系统交互代理。
yihong0618/bilingual_book_maker - 利用人工智能翻译手段创作双语的epub书籍。
lavague-ai/LaVague - 用于开发人工智能网络代理的大型动作模型框架。
aisingapore/TagUI - 由新加坡人工智能开发的一款免费的机器人流程自动化(RPA)工具。
openchatai/OpenCopilot - 语言到行为引擎
KillianLucas/01 - 适用于桌面端、移动端和ESP32芯片的顶级开源语音接口。
katanaml/sparrow - 使用机器学习、大型语言模型(LLM)和基于视觉的大型语言模型进行数据处理。
xlang-ai/OpenAgents - 2024年的OpenAgents:一个面向野生语言智能体(agents)的开放平台。
BAAI-Agents/Cradle -
Cormanz/smartgpt - 一个使大型语言模型(LLMs)能够借助插件完成复杂任务的程序。
fiatrete/OpenDAN-Personal-AI-OS - OpenDAN是一个开源的个人人工智能操作系统,它整合了各种人工智能模块供个人使用。
n4ze3m/page-assist - 使用本地运行的人工智能模型来协助网络浏览。
OS-Copilot/FRIDAY -
andrewnguonly/Lumos - 一个由本地大型语言模型(LLM)提供支持、用于网络浏览的检索增强生成(RAG)大型语言模型(LLM)副驾驶。
Dicklesworthstone/swiss_army_llama - 一个通过预先计算的嵌入、相似性度量以及通过textract支持文件类型来进行语义文本搜索的FastAPI服务。
lencx/ChatGPT - 适用于Mac、Windows和Linux系统的ChatGPT桌面应用程序。
LAION-AI/Open-Assistant - OpenAssistant是一个基于聊天的助手,能够理解任务、与第三方系统交互并动态检索信息。
zhayujie/chatgpt-on-wechat - A chatbot based on large models, supporting multiple platforms (WeChat official account, enterprise WeChat application, Feishu, DingTalk, etc.), multiple models (GPT3.5/GPT - 4o/GPT - o1/ Claude/Wenxin Yiyan/iFlytek/Tongyi Qianwen/GLM-4/Claude/Qimi/Link Love), able to process text, voice and pictures, access the operating system and The Internet and supports customized enterprise intelligent customer service based on its own knowledge ฐาน.
Chanzhaoyu/chatgpt-web - 一个使用Express和Vue3构建的ChatGPT演示网页。
janhq/jan - Jan是一个开源的ChatGPT替代品,可在计算机上完全离线运行。
Bin-Huang/chatbox - 对人工智能模型/大型语言模型(如GPT、Claude、Gemini、Ollama等)友好的桌面客户端应用程序。
joonspk-research/generative_agents - 生成式智能体:人类行为的交互模拟。
Unity-Technologies/ml-agents - Unity ML - Agents工具包是一个开源项目,用于通过深度强化学习和模仿学习在游戏和模拟中训练智能体。
transitive-bullshit/chatgpt-api - 一个兼容任何大型语言模型(LLM)和TypeScript人工智能软件开发工具包(SDK)的人工智能代理标准库。
leon-ai/leon - 利昂是你的开源个人助手。
xcanwin/KeepChatGPT - 这是一个增强ChatGPT数据安全性和效率的插件。它提供许多免费的创新功能以提供更好的人工智能体验。
lss233/chatgpt-mirai-qq-bot - 一键部署!真正的人工智能聊天机器人,支持多平台和多种功能。
getumbrel/llama-gpt - 一个像ChatGPT一样的自托管离线聊天机器人,由Llama 2提供支持,是私有的,没有数据离开设备,现在还支持Code Llama。
sfyc23/EverydayWechat - 微信助手:1. 每天定期向朋友(女友)发送定制消息。2. 机器人自动回复朋友。3. 群助手功能(如垃圾分类查询、天气、日历、实时电影票房、快递物流、PM2.5等)。
BlinkDL/ChatRWKV - ChatRWKV是一个像ChatGPT一样的开源语言模型,但由RWKV(一种100%的循环神经网络)提供动力。
ztjhz/BetterChatGPT - ChatGPT的一个很棒的用户界面,可在网站以及包括Windows、MacOS和Linux在内的多种操作系统上使用。
a16z-infra/ai-town - 一个用于构建人工智能小镇(人工智能角色在其中生活、聊天和社交)的、遵循麻省理工学院(MIT)许可的入门工具包可部署且可定制。
memochou1993/gpt-ai-assistant - OpenAI、LINE和Vercel结合起来形成了GPT AI助手。
miurla/morphic - 一个由人工智能驱动并具有生成式用户界面的搜索引擎。
interstellard/chatgpt-advanced - WebChatGPT是一款浏览器扩展程序,可通过网络结果增强ChatGPT提示。
linyiLYi/street-fighter-ai - 这是一个针对《街头霸王II冠军版》的人工智能代理。
vincelwt/chatgpt-mac - 适用于Mac的ChatGPT驻留在你的菜单栏中。
camel-ai/camel - CAMEL:首个也是最佳的多智能体框架,用于发现智能体的扩展定律。(https://www.camel - ai.org)
MineDojo/Voyager - 与大型语言模型相关的开放式具身智能体。
a16z-infra/companion-app - 具有记忆功能的人工智能伙伴:一个用于创建和托管自己的人工智能伙伴的轻量级堆栈。
ConnectAI-E/Feishu-OpenAI - 飞书(结合GPT - 4、GPT - 4V、DALL·E - 3和Whisper)提供了很棒的工作体验,包括语音对话、角色扮演、多话题讨论、图像创作、表格分析和文档导出。
simonw/llm - 通过命令行访问大型语言模型。
sigoden/aichat - 一款集Shell助手、聊天交互(Chat - REPL)、检索增强生成(RAG)、人工智能工具与代理于一体的大型语言模型(LLM)命令行界面(CLI)工具,可访问OpenAI、Claude等多个平台。
lencx/nofwl - 无防火墙(No FireWall,简称NoFWL)桌面应用程序。
Kent0n-Li/ChatDoctor -
xtekky/chatgpt-clone - 具有改进用户界面的ChatGPT界面。
deep-diver/LLM-As-Chatbot - 大型语言模型(LLM)作为一种聊天机器人服务。
gragland/chatgpt-chrome-extension - 一个将ChatGPT集成到互联网上每个文本框的ChatGPT Chrome扩展程序。
ohmplatform/FreedomGPT - 这个代码库是用于一个带有基于聊天界面的React - Electron(一种将React框架用于构建桌面应用的技术)应用程序,可在Mac和Windows系统本地运行FreedomGPT大型语言模型(LLM)。
SoraWebui/SoraWebui - SoraWebui是一个开源的Sora网络客户端,可轻松使用OpenAI的Sora模型从文本创建视频。
karthink/gptel - 一个使用大型语言模型的简单Emacs客户端。
a16z-infra/llama2-chatbot - LLaMA v2聊天机器人。
ItsPi3141/alpaca-electron - 在自己的个人电脑上运行羊驼(Alpaca)和其他基于LLaMA的本地大型语言模型(LLM)的最简单方法。
opendilab/DI-star - 一个用于《星际争霸II》的人工智能平台,具备大规模分布式训练和宗师级智能体。
jncraton/languagemodels - 使用512MB内存探索大型语言模型。
SamurAIGPT/Camel-AutoGPT - 介绍CAMEL,一种针对大型语言模型(LLMs)和自动代理(auto - agents)的角色扮演方法。它使代理能够协作,并在多个领域具有潜力。
Syan-Lin/CyberWaifu - 一个由大型语言模型(LLM)+语音合成(TTS)构成的具有真实感的聊天机器人,一个支持表情符号、QQ表情和互联网搜索的QQ机器人。
PaddlePaddle/PaddleOCR - 基于飞桨(PaddlePaddle)的超棒多语言光学字符识别(OCR)工具包。它们实用、超轻量,支持80多种语言,可在多种设备上使用。
suno-ai/bark - 一种由文本提示的生成式音频模型。
openai/CLIP - CLIP(对比语言- 图像预训练):为图像预测最相关的文本片段。
hpcaitech/Open-Sora - Open - Sora:使每个人都能以民主的方式进行高效的视频制作。
haotian-liu/LLaVA - NeurIPS'23 Oral(神经信息处理系统大会2023年口头报告)中的视觉指令调整(LLaVA)旨在获得GPT - 4V级别的能力甚至更强的能力。
fishaudio/fish-speech - 最先进的开源语音合成(TTS)技术。
borisdayma/dalle-mini - DALL·E Mini根据文本提示生成图像。
google-deepmind/alphafold - AlphaFold 2的开源代码。
OpenBMB/OmniLMM - MiniCPM - V 2.6是一款在手机上用于单张图像、多张图像和视频的、达到GPT - 4V水平的多模态大语言模型(MLLM)。
PKU-YuanGroup/Open-Sora-Plan - 该项目旨在复现Sora(OpenAI的文本到视频模型),并希望开源社区做出贡献。
openai/shap-e - 基于文本或图像生成3D对象。
facebookresearch/seamless_communication - 用于最先进的语音和文本翻译的基础模型。
openai/DALL-E - PyTorch软件包用于DALL·E中的离散变分自编码器(VAE)。
google-research/vision_transformer -
magic-research/magic-animate - CVPR 2024中的MagicAnimate使用扩散模型实现时序一致的人体图像动画。
ashawkey/stable-dreamfusion - 使用神经辐射场(NeRF)+扩散技术进行文本到3D、图像到3D以及网格导出。
lucidrains/imagen-pytorch - 在Pytorch中实现谷歌的文本到图像神经网络Imagen。
openai/jukebox - 论文《Jukebox:一种音乐生成模型》的代码。
deep-floyd/IF -
netease-youdao/EmotiVoice - EmotiVoice?:一款拥有多种音色并且受提示控制的语音合成(TTS)引擎。
IDEA-Research/GroundingDINO - 论文《Grounding DINO:将DINO与基础预训练相结合用于开集目标检测》在ECCV 2024中的官方实现。
FoundationVision/VAR - NeurIPS 2024口头报告《视觉自回归建模:通过下一尺度预测进行可扩展图像生成》的官方实现。这是一个用于自回归图像生成的极其简单、用户友好的最先进代码库。
threestudio-project/threestudio - 一种统一生成3D内容的框架。
openai/guided-diffusion -
THUDM/CogVLM - 一种最先进的开放式视觉语言模型,一种多模态预训练模型。
openai/consistency_models - 一致性模型官方库。
levihsu/OOTDiffusion - OOTDiffusion:基于潜扩散的服装融合用于可控虚拟试穿——官方实现。
clovaai/donut - ECCV 2022的Donut(无光学字符识别的文档理解变换器)和SynthDoG(合成文档生成器)的官方实现。
google/gemma_pytorch - 谷歌Gemma模型的官方PyTorch实现。
QwenLM/Qwen-VL - 通义千问- VL(阿里云的一个聊天和预训练大视觉语言模型)的官方仓库。
yl4579/StyleTTS2 - StyleTTS 2旨在通过风格扩散和利用大型语音语言模型进行对抗训练来实现人类水平的文本到语音转换。
snakers4/silero-models - Silero模型是用于语音转文本、文本转语音和文本增强的预训练模型,这些模型制作得非常简单。
salesforce/BLIP - 用于BLIP(Bootstrapping Language - Image Pre - training,自举语言- 图像预训练)的PyTorch代码,BLIP用于通过自举语言- 图像预训练来实现统一的视觉- 语言理解和生成。
google-deepmind/alphageometry -
metavoiceio/metavoice-src - 一个类人、富有表现力的文本到语音(TTS)基础模型。
Luodian/Otter - 水獭(Otter)是一个基于OpenFlamingo的多模态模型,在MIMIC - IT数据集上进行训练,具有更好的指令遵循和上下文学习能力。
NExT-GPT/NExT-GPT - NExT - GPT(一种任意到任意多模态大型语言模型)的代码和模型。
openai/improved-diffusion - 发布用于改进的去噪扩散概率模型。
X-PLUG/MobileAgent - 移动设备- 代理:强大的移动设备操作助手家族。
dvlab-research/MiniGemini - 《Mini - Gemini:挖掘多模态视觉语言模型的潜力》官方知识库。
lucidrains/musiclm-pytorch - 使用注意力网络在PyTorch中实现谷歌最先进的音乐生成模型MusicLM。
hustvl/Vim - Vision Mamba(于2024年国际机器学习会议中提出)通过双向状态空间模型实现高效的视觉表征学习。
OpenGVLab/Ask-Anything - CVPR2024亮点:VideoChatGPT使ChatGPT能够理解视频。它还支持其他语言模型,如miniGPT4、StableLM和MOSS。
microsoft/lida - 通过大型语言模型自动生成可视化内容和信息图表。
google-research/frame-interpolation - ECCV 2022中的大运动帧插值(FILM)
InternLM/InternLM-XComposer - InternLM - XComposer2.5 - OmniLive:一个用于长期视频和音频交互的多模态系统。
yerfor/GeneFace - GeneFace:广义且高保真的3D说话人脸合成,ICLR 2023,含官方代码。
OpenGVLab/InternImage - CVPR 2023中的InternImage:利用可变形卷积探索大规模视觉基础模型。
google-deepmind/gemma - 谷歌DeepMind的开放权重大型语言模型。
baaivision/EVA - EVA系列:来自北京智源人工智能研究院(BAAI)的视觉表象的幻想。
MzeroMiko/VMamba - VMamba:视觉状态空间模型。其代码基于Mamba。
deepseek-ai/DeepSeek-VL - DeepSeek - VL旨在对现实世界中的视觉- 语言进行理解。
openai/consistencydecoder - 一致性蒸馏差分变分自编码器。
gligen/GLIGEN - 开放- 基于基础(grounding)的文本到图像生成。
dvlab-research/LISA - “LISA:基于大型语言模型的推理分割”项目页面。
3DTopia/LGM - ECCV 2024口头报告中的LGM用于高分辨率3D内容创作。
lyuchenyang/Macaw-LLM - 金刚鹦鹉(Macaw)——大型语言模型(LLM)集成了图像、视频、音频和文本,用于多模态语言建模。
OpenMotionLab/MotionGPT - MotionGPT在2023年神经信息处理系统大会(NeurIPS 2023)上是一个使用大型语言模型(LLMs)的统一运动- 语言生成模型。
OpenGVLab/InternVideo - ECCV2024(欧洲计算机视觉国际会议2024)中用于多模态理解的视频基础模型和数据。
openai/Video-Pre-Training - 视频预训练(VPT)包括通过观察未标记的在线视频来学习行动。
THUDM/ImageReward - NeurIPS 2023中的ImageReward:学习和评估人类对文生图的偏好。
evo-design/evo - 从分子到基因组规模的生物学基础建模。
google-research/tapas - 用于理解表格和文本的端到端神经模型。
apple/ml-aim - 该存储库提供用于AIMv1和AIMv2研究项目的代码和模型检查点。
showlab/Show-o - Show - o的代码库,一个用于统一多模态理解和生成的单一Transformer。
ELLA-Diffusion/ELLA - 为扩散模型配备大型语言模型(LLM)以加强语义对齐。
declare-lab/tango - 一种用于文生音的扩散模型家族。
OpenBMB/VisCPM - 基于CPM基础模型的汉英双模态大模型系列(聊天与绘画)
OpenGVLab/VisionLLM - 视觉大型语言模型(VisionLLM)系列。
BAAI-DCAI/Bunny - 轻量级多模态模型家族。
Ligo-Biosciences/AlphaFold3 - AlphaFold3的开源实现。
Vchitect/SEINE - SEINE:一种用于2024年国际学习表征会议(ICLR)中生成性转换和预测的短视频到长视频扩散模型。
google-deepmind/materials_discovery -
OpenGVLab/SAM-Med2D - SAM - Med2D的官方实现。
OpenMOSS/AnyGPT - 用于“AnyGPT:具有离散序列建模的统一多模态大型语言模型(LLM)”的代码。
THUDM/ChatGLM-6B - ChatGLM - 6B是一个开放的双语对话语言模型。
ymcui/Chinese-LLaMA-Alpaca - 中国的LLaMA(小羊驼)和Alpaca(羊驼)大型语言模型+ 本地CPU(中央处理器)/GPU(图形处理器)训练与部署
UKPLab/sentence-transformers - 最先进的文本嵌入技术。
FlagAlpha/Llama2-Chinese - 羊驼(Llama)中文社区已开放Llama3以供在线体验和微调。它更新了Llama3的所有代码,完全开源且可用于商业用途,并且还编写了最新的Llama3学习资料。
THUDM/ChatGLM3 - ChatGLM3系列:开源双语聊天大型语言模型。
ymcui/Chinese-LLaMA-Alpaca-2 - 中国版LLaMA - 2和Alpaca - 2大型模型二期项目以及64K长文本模型。
InternLM/InternLM - InternLM2.5基础模型和聊天模型正式发布,支持100万(1M)的上下文。
Facico/Chinese-Vicuna - 中国- Vicuna:一个遵循指令的基于LLaMA的中文模型- 一种参考羊驼结构的低资源中文llama + lora解决方案。
LC1332/Luotuo-Chinese-LLM - 骆驼(Luotuo)是由华中师范大学的陈启源、商汤科技的李路路和冷子昂开发的开源中文语言模型。
wenge-research/YAYI2 - YAYI 2是中科闻歌开发的新一代开源大语言模型,使用超过2万亿个高质量、多语言语料库的标记进行预训练。
wenge-research/YaYi - 亚一大型模型由中科文歌算法团队开发,是为客户打造的安全可靠的专属大型模型,它基于LlaMA2和BLOOM系列的大规模中英文多领域指令数据进行训练。
TigerResearch/TigerBot - TigerBot是一个支持多种语言和任务的大型语言模型。
LinkSoul-AI/Chinese-Llama-2-7b - 开源社区中首个可下载且可运行的中文LLaMA2模型!
MiuLab/Taiwan-LLM - 面向台湾的传统普通话语言模型。
zjunlp/KnowLM - 一个带有知识的开源大语言模型框架。
google-research/multilingual-t5 -
SkyworkAI/Skywork - Skywork系列模型在3.2TB的多语言和代码数据上进行了预训练,相关项目已开源。
photoprism/photoprism - 去中心化网络上由人工智能驱动的照片应用。
freedmand/semantra - 一种用于语义搜索的多功能工具。
neo4j/NaLLM - NaLLM项目的存储库。
vllm-project/vllm - 一种用于大型语言模型(LLMs)推理和服务的高通量且内存高效的引擎。
guillaumekln/faster-whisper - 使用CTranslate2进行更快速的Whisper转录。
bentoml/OpenLLM - 在云端将像Llama和Mistral这样的开源大型语言模型(LLM)作为与OpenAI兼容的API端点来运行。
huggingface/text-generation-inference - 大规模语言模型文本生成推理。
FMInference/FlexGen - 在以吞吐量为重点的场景下,在单个GPU上运行大型语言模型。
triton-inference-server/server - Triton推理服务器为云端和边缘端提供了优化的推理解决方案。
dusty-nv/jetson-inference - 《Hello AI World》中使用TensorRT和NVIDIA Jetson部署深度学习推理网络和深度视觉原语指南。
openvinotoolkit/openvino - OpenVINO™是一个开源的人工智能推理优化和部署工具包。
zilliztech/GPTCache - 用于大型语言模型(LLMs)的语义缓存,与LangChain和llama_index完全集成。
Portkey-AI/gateway - 一个速度非常快、集成了防护栏并且可以通过一个API路由到许多大型语言模型(LLMs)和人工智能防护栏的人工智能网关。
tensorflow/serving - 一个灵活且高性能的机器学习模型服务系统。
xorbitsai/inference - 通过使用Xinference修改一行代码,在你的应用中用另一个大型语言模型(LLM)替换OpenAI GPT,Xinference支持在任何地方运行各种模型的推理。
allegroai/clearml - ClearML是一种用于人工智能工作负载(包括实验和数据管理等)的MLOps/LLMOps解决方案。
InternLM/lmdeploy - LMDeploy是一个用于压缩、部署和服务大型语言模型的工具包。
argmaxinc/WhisperKit - 苹果硅芯片设备端语音识别。
kserve/kserve - 一个基于Kubernetes的标准化无服务器机器学习推理平台。
neuralmagic/deepsparse - 基于CPU的稀疏感知深度学习推理运行时。
huggingface/text-embeddings-inference - 一种用于文本嵌入模型的非常快速的推理解决方案。
open-mmlab/mmdeploy - OpenMMLab的模型部署框架。
ModelTC/lightllm - LightLLM是一个基于Python的大型语言模型(LLM)推理和服务框架,它轻巧、易于扩展且速度快。
predibase/lorax - 一个可扩展至数千个微调大型语言模型(LLM)的多LoRA推理服务器。
langchain-ai/langserve - 朗格服务(LangServe) ?️?
S-LoRA/S-LoRA - S - LoRA:服务大量并发的LoRA适配器。
michaelfeil/infinity - Infinity是一种用于文本嵌入、重排序模型、clip、clap和colpali的服务引擎,具有高吞吐量和低延迟的特点。
roboflow/inference - 将任何计算机或边缘设备转变为计算机视觉项目的指挥枢纽。
ray-project/ray-llm - RayLLM - 基于Ray的大型语言模型。
PygmalionAI/aphrodite-engine - 大规模语言模型(LLM)推理引擎。
punica-ai/punica - 将多个LoRA微调的大型语言模型作为一个来服务。
msoedov/langcorn - 使用FastApi为LLMops自动为LangChain大型语言模型(LLM)应用程序和代理提供服务。
mosecorg/mosec - 一种高性能机器学习模型服务框架,具有动态批处理和CPU/GPU管道,可最大限度地提高计算机利用率。
facebookresearch/faiss - 一个用于高效稠密向量相似性搜索和聚类的库。
milvus-io/milvus - Milvus是一个高性能、云原生的向量数据库,用于可扩展的向量近似最近邻搜索。
qdrant/qdrant - Qdrant是一款面向下一代人工智能的高性能、大规模矢量数据库和搜索引擎,也提供云服务。
chroma-core/chroma - 人工智能原生的开源嵌入数据库。
spotify/annoy - 针对内存使用和磁盘I/O进行优化的C++/Python近似最近邻算法。
weaviate/weaviate - Weaviate是一个开源向量数据库。它存储对象和向量,并能够在结构化过滤下进行向量搜索,具备容错性和可扩展性。
neuml/txtai - 一个用于语义搜索、大型语言模型(LLM)编排和语言模型工作流的一体化开源嵌入数据库。
activeloopai/deeplake - 一个供人工智能使用的数据库,它能够存储诸如向量、图像、文本和视频等各种类型的数据。它可与大型语言模型/语言链(LLMs/LangChain)一起用于存储、查询、版本管理和可视化人工智能数据等操作,并且能够向PyTorch/ TensorFlow实时传输数据。
vespa-engine/vespa - 人工智能+数据,可在https://vespa.ai在线获取。
lancedb/lancedb - 一种用于人工智能应用的无服务器矢量数据库,对开发者友好,能轻松为大型语言模型(LLM)应用添加长期记忆。
marqo-ai/marqo - 统一的嵌入生成和搜索引擎,也可在云端使用- cloud.marqo.ai。
nmslib/hnswlib - 一个仅含头文件的C++/python库,用于快速近似最近邻搜索。
unum-cloud/usearch - 适用于多种编程语言的快速开源搜索与聚类引擎。
tensorchord/pgvecto.rs - 借助混合功能在Postgres(一种数据库管理系统)中进行可扩展、低延迟的向量搜索。它革新的是向量搜索而非数据库。
spotify/voyager - 一个用于近似最近邻搜索的Python和Java库,侧重于易用性、简洁性和可部署性。
rapidsai/raft - RAFT拥有用于机器学习和信息检索(IR)的基本算法和原语,这些算法和原语通过CUDA加速以用于高性能应用。
JushBJJ/Mr.-Ranedeer-AI-Tutor - 一种用于个性化学习体验且可定制的GPT - 4人工智能导师提示词。
Nutlope/llamatutor - 一个AI私人导师是基于Llama 3.1构建的。
codeacme17/examor - 对于学生、学者、受访者和终身学习者来说,大型语言模型(LLMs)有助于学习。
jina-ai/jina - 使用云原生技术栈构建多模态人工智能应用。
iterative/dvc - 数据版本控制与机器学习实验。
unifyai/ivy - 在不同框架之间转换机器学习代码。
HigherOrderCO/HVM - 用Rust编写的大规模并行最优函数运行时。
marimo-team/marimo - Python反应式笔记本可用于可重现性实验、脚本执行、应用程序部署以及使用Git进行版本控制。
arogozhnikov/einops - 用于创建可读性和可靠性兼具的代码的灵活且强大的张量操作,适用于PyTorch、Jax、TensorFlow等。
replicate/cog - 机器学习中使用的容器。
jessevig/bertviz - BertViz:可视化如BERT、GPT2、BART等自然语言处理模型中的注意力。
AbdBarho/stable-diffusion-webui-docker - 通过用户友好界面轻松设置用于Stable Diffusion的Docker。
huggingface/safetensors - 一种存储和分配张量的简单且安全的方法。
wangzhaode/mnn-llm - 基于MNN部署一个大型语言模型(LLM)项目。
ajndkr/lanarky - 用于构建大型语言模型(LLM)微服务的网络框架。
tensorflow/tensorflow - 一个所有人都能使用的开源机器学习框架。
huggingface/transformers - Transformer:适用于Pytorch、TensorFlow和JAX的最先进机器学习技术。
pytorch/pytorch - 使用强大的GPU加速功能、基于Python的张量和动态神经网络。
hpcaitech/ColossalAI - 降低大型人工智能模型的成本、提高其速度并增强其可及性。
hiyouga/LLaMA-Factory - 对100多个大型语言模型(LLMs)进行统一高效的微调(ACL 2024)
lm-sys/FastChat - 一个用于大型语言模型训练、服务和评估的开放平台,也是Vicuna和Chatbot Arena的发布库。
coqui-ai/TTS - ?是一个用于文本转语音的深度学习工具包,在研究和生产中得到验证。
microsoft/DeepSpeed - DeepSpeed是一个深度学习库,用于轻松、高效且有效的分布式训练和推理。
ray-project/ray - Ray是一个人工智能计算引擎,它具有核心分布式运行时和人工智能库,用于加速机器学习工作负载。
google-research/google-research - 谷歌研究
google/jax - Python+NumPy程序可以通过多种方式进行组合转换,例如求导、向量化以及即时编译(JIT)到GPU/TPU等。
open-mmlab/mmdetection - OpenMMLab检测工具包与基准测试。
tinygrad/tinygrad - 如果你喜欢PyTorch和Micrograd,那么你也会喜欢Tinygrad。
huggingface/diffusers - Diffusers:用于生成图像、视频和音频的PyTorch和FLAX最先进的扩散模型。
mozilla/DeepSpeech - DeepSpeech是一个开源的语音转文本引擎,可在各种设备上实时使用。
modularml/mojo - 莫霍编程语言(给定描述中未提供更多细节)
microsoft/unilm - 大规模涵盖任务、语言和模态的自监督预训练。
ml-explore/mlx - MLX是一个适用于苹果芯片的数组框架。
HigherOrderCO/Bend - 一种具有大规模并行性的高级编程语言。
huggingface/peft - PEFT:最佳的参数高效微调。
huggingface/candle - 一个用于Rust语言的极简机器学习框架。
NVIDIA/NeMo - 一个适用于大型语言模型(LLMs)、多模态和语音人工智能等人工智能领域研究人员和开发人员的框架,该框架具有可扩展性和生成性。
PaddlePaddle/PaddleNLP - 一个易于使用且功能强大的自然语言处理(NLP)和大型语言模型(LLM)库,拥有大量优秀的模型,支持从研究到工业应用的各种自然语言处理任务。
PaddlePaddle/PaddleSpeech - 一个易用的语音工具包包含多种功能,并获得了NAACL2022最佳演示奖。
Lightning-AI/litgpt - 20多个高性能大型语言模型(LLM)以及大规模预训练、微调与部署的相关方案。
huggingface/trl - 利用强化学习来训练Transformer语言模型。
artidoro/qlora - QLoRA能够实现量化大型语言模型的高效微调。
salesforce/LAVIS - LAVIS是一个一站式的语言- 视觉智能库。
nerfstudio-project/nerfstudio - 一个对神经辐射场(NeRFs)协作友好的工作室。
mozilla/TTS - 用于语音合成的深度学习(讨论论坛:https://discourse.mozilla.org/c/tts)
tracel-ai/burn - Burn是一个全新的动态深度学习框架,由Rust构建,旨在实现灵活性、高效性和可移植性。
facebookresearch/pytorch3d - PyTorch3D是FAIR(Facebook人工智能研究)用于3D数据深度学习的库。
facebookresearch/xformers - Transformer构建模块可灵活调整且经过优化,支持组合式构建。
OptimalScale/LMFlow - 一个用于大型基础模型微调及推理的可扩展工具包,让所有人都能使用大型模型。
OpenAccess-AI-Collective/axolotl - 只管去问蝾螈问题就好。
FlagOpen/FlagEmbedding - 检索与检索增强型大型语言模型(LLMs)
huggingface/accelerate - 一种在各种设备和配置上处理PyTorch模型的简单方法,具有自动混合精度等功能,并支持完全分片数据并行(FSDP)和DeepSpeed。
LianjiaTech/BELLE - BELLE是一个开源的面向所有人的中文对话大型语言模型引擎。
cloneofsimo/lora - 通过低秩适应快速微调扩散模型。
EleutherAI/gpt-neox - 使用Megatron和DeepSpeed库在GPU上实现具有模型并行性的自回归变换器。
open-mmlab/mmagic - OpenMMLab是一个多模态工具箱,可用于像人工智能生成内容(AIGC)等各种任务,拥有易用的应用程序接口(API)和模型库。
facebookresearch/metaseq - 外部大型工作资料库。
Maartengr/BERTopic - 使用BERT和c - TF - IDF生成易于理解的主题。
Project-MONAI/MONAI - 一个用于人工智能领域医疗影像(处理)的工具包。
yangjianxin1/Firefly - Firefly是一个大型模型训练工具,支持训练多个大型模型,如Qwen2.5、Qwen2等。
google-deepmind/graphcast -
mosaicml/composer - 增强你的模型训练。
cg123/mergekit - 用于组合预训练大型语言模型的工具。
CarperAI/trlx - 一个用于使用人类反馈强化学习(RLHF)进行语言模型分布式训练的代码库。
pytorch/torchtune - 一个PyTorch原生的训练后库。
google-deepmind/open_spiel - OpenSpiel是一组用于通用强化学习以及游戏搜索/规划研究的环境和算法。
huggingface/autotrain-advanced - 自动训练进阶版。
InternLM/xtuner - 一个高效、灵活且功能齐全的用于对各种大型语言模型(LLMs)进行微调的工具包。
mosaicml/llm-foundry - 用于Databricks基础模型的大型语言模型(LLM)训练代码。
baidu-research/warp-ctc - 快速并行的连接主义时间分类(CTC)。
JohnSnowLabs/spark-nlp - 自然语言处理的最先进技术。
FlagAI-Open/FlagAI - FlagAI是一个用于大规模模型的工具包,它快速、易用且可扩展。
mlfoundations/open_flamingo - 一个用于训练大型多模态模型的开源框架。
OpenLLMAI/OpenRLHF - 一个易用、可扩展且高性能的人类反馈强化学习(RLHF)框架,具有700亿以上参数的近端策略优化(PPO)完全微调、迭代直接偏好优化(DPO)、低秩自适应(LoRA)、环形注意力(RingAttention)和递归微调(RFT)等功能。
google-deepmind/acme - 一个用于强化学习的组件和代理库。
open-mmlab/mmpretrain - OpenMMLab的预训练工具箱和基准测试。
shibing624/MedicalGPT - MedicalGPT uses ChatGPT training pipeline to train medical GPT models to achieve incremental pre-training, supervised fine-tuning, human feedback reinforcement learning (RLHF), direct preference optimization (DPO), and sort-based preference optimization (ORPO) .
iryna-kondr/scikit-llm - 毫无问题地将大型语言模型(LLMs)集成到scikit - learn中。
google-research/scenic - Scenic:一个用于计算机视觉研究及其他更多用途的Jax库。
facebookresearch/fairscale - 用于高性能和大规模训练的PyTorch扩展。
alpa-projects/alpa - 通过自动并行化训练和服务大规模神经网络。
microsoft/torchscale - 大中型语言模型的基础架构。
google-deepmind/dm-haiku - 基于JAX的神经网络库。
eureka-research/Eureka - ICLR 2024会议上发表的论文《Eureka:通过对大型语言模型进行编码实现人类水平的奖励设计》的官方存储库。
Alpha-VLLM/LLaMA2-Accessory - 一个用于开发大型语言模型的开源工具包。
google-research/t5x -
google-deepmind/alphatensor -
PhoebusSi/Alpaca-CoT -
huggingface/optimum - 使用易用的硬件优化工具来加速Transformer、Diffuser、TIMM和Sentence Transformer的推理和训练。
stochasticai/xTuring - 通过xTuring可以轻松地从数据预处理到微调构建、定制和控制您自己的大型语言模型(LLMs),并加入其Discord社区。
adapter-hub/adapters - 一个用于参数高效和模块化迁移学习的统一库。
openai/weak-to-strong -
OpenPipe/OpenPipe - 将昂贵的提示转换为价格实惠的微调模型。
lamini-ai/lamini - Lamini API的官方Python客户端。
google-research/big_vision - 用于开发视觉变换器(Vision Transformer)、SigLIP、多层感知机混合器(MLP - Mixer)、LiT等的官方代码库。
young-geng/EasyLM - EasyLM(基于JAX/Flax)为预训练、微调、评估和服务等各种大型语言模型(LLM)操作提供一站式解决方案。
pyro-ppl/numpyro - 使用NumPy进行概率编程,并利用JAX进行自动求导以及将即时编译(JIT编译)到GPU/TPU/CPU。
eric-mitchell/direct-preference-optimization - 直接偏好优化(DPO)的参考实现。
huggingface/setfit - 使用句向量转换器(Sentence Transformers)进行高效的小样本学习。
allenai/open-instruct -
allenai/RL4LMs - 一个用于根据人类偏好微调语言模型的模块化强化学习(RL)库。
lxe/simple-llm-finetuner - 用于微调大型语言模型(LLM)的简单用户界面。
THUDM/P-tuning-v2 - 一种优化的深度提示微调策略在不同规模和任务中的效果与微调一样好。
tensorflow/privacy - 一个用于训练机器学习模型且对训练数据有隐私保护的库。
xlang-ai/instructor-embedding - 适用于任何任务的单一嵌入器:指令- 微调文本嵌入(ACL 2023)
unslothai/hyperlearn - 机器学习算法的速度提高了2 - 2000倍,内存使用量减少50%,并且可在所有硬件上运行。
salesforce/ctrl - 一种用于可控生成的条件转换语言模型。
google-deepmind/optax - Optax是一个用于梯度处理和优化的JAX库。
google-deepmind/penzai - 一个用于构建、修改和可视化神经网络的JAX工具包。
microsoft/i-Code -
kubeflow/training-operator - 在Kubernetes上进行分布式机器学习训练和微调。
AetherCortex/Llama-X - 开展使LLaMA达到最先进大型语言模型的开放学术研究。
salesforce/ALBEF - 一种新的视觉- 语言预训练方法ALBEF的代码。
kubeflow/katib - Kubernetes环境下的自动化机器学习。
facebookresearch/multimodal - TorchMultimodal是一个PyTorch库,用于对最先进的多模态多任务模型进行大规模训练。
jina-ai/finetuner - 用于BERT、CLIP等的面向任务的嵌入调整。
salesforce/CodeTF - CodeTF:用于最新代码大型语言模型(LLM)的一站式Transformer库。
AnswerDotAI/fsdp_qlora - 使用QLoRA和全分片数据并行(FSDP)训练大型语言模型(LLM)。
nerfstudio-project/nerfacc - 一个基于PyTorch的通用神经辐射场(NeRF)加速工具箱。
jquesnelle/yarn - YaRN:大型语言模型的高效上下文窗口扩展。
PKU-Alignment/safe-rlhf - 安全的人类反馈强化学习(Safe RLHF)利用基于人类反馈的安全强化学习来实现受限的值对齐。
lucidrains/self-rewarding-lm-pytorch - 实现MetaAI在《自奖励语言模型》中提出的训练框架。
OpenLMLab/MOSS-RLHF - 这是关于大型语言模型中人类反馈强化学习(RLHF)的秘密,特别是关于近端策略优化算法(PPO)的第一部分。
JonasGeiping/cramming - 在有限的计算资源内压缩BERT类型语言模型的训练。
AlibabaResearch/DAMO-ConvAI - 达摩- 对话式人工智能(ConvAI)是拥有阿里巴巴达摩院对话式人工智能(DAMO Conversational AI)代码库的官方资源库。
databricks/megablocks -
AGI-Edgerunners/LLM-Adapters - EMNLP 2023论文《LLM - 适配器:用于大型语言模型参数高效微调的适配器家族》的代码。
KhoomeiK/LlamaGym - 通过在线强化学习对大型语言模型(LLM)智能体进行微调。
thunlp/OpenDelta - 一个即插即用的参数高效调整(Delta Tuning)库。
Liuhong99/Sophia - 论文《Sophia:一种用于语言模型预训练的可扩展随机二阶优化器》的官方实现。
yuchenlin/LLM-Blender - LLM - Blender是[ACL2023]中的一个集成框架,它通过排序来消除弱点,并通过生成融合优势以提升大型语言模型(LLMs)的能力。
google-deepmind/xmanager - 一个用于处理机器学习实验的平台。
google-deepmind/chex -
AUTOMATIC1111/stable-diffusion-webui - 稳定扩散Web用户界面。
lllyasviel/Fooocus - 描述内容是关于专注于提示和生成。
upscayl/upscayl - Upscayl是适用于Linux、MacOS和Windows系统的排名第一的免费开源人工智能图像放大器。
s0md3v/roop - 一键换脸意味着只需点击一下就可以完成换脸。
invoke-ai/InvokeAI - Invoke是一个用于Stable Diffusion模型的创意引擎,它提供了一个WebUI(用户界面)并作为商业产品的基础。
facefusion/facefusion - 一个行业领先的面部处理平台。
Sanster/lama-cleaner - 由最先进的人工智能模型驱动的图像修复工具可以去除图片中不需要的元素或替换其中的事物。
Mikubill/sd-webui-controlnet - 用于ControlNet的WebUI扩展。
camenduru/stable-diffusion-webui-colab - 在Colab(谷歌协作平台)上的Stable diffusion(稳定扩散)网页用户界面。
divamgupta/diffusionbee-stable-diffusion-ui - Diffusion Bee是在M1 Mac本地运行Stable Diffusion的最简单方法。它有一个一键安装程序,不需要依赖项或技术知识。
Baiyuetribe/paper2gui - 将人工智能论文转换为图形用户界面(GUI),以便每个人都能轻松使用人工智能技术。
easydiffusion/easydiffusion - 在PC端利用人工智能创作精美艺术作品最简单的方法是一键操作。只需输入文本提示词,就能通过浏览器用户界面生成图像,无需技术知识。
Stability-AI/StableStudio - 生成式人工智能的社区界面。
carson-katri/dream-textures - Stable Diffusion集成到Blender中。
TheLastBen/fast-stable-diffusion - 快速- 稳定- 扩散和DreamBooth。
godly-devotion/MochiDiffusion - 在Mac上本地运行Stable Diffusion。
HumanAIGC/OutfitAnyone - 超高质量的适用于所有人和衣物的虚拟试穿。
sensity-ai/dot - 深度伪造攻击工具包。
leap-ai/headshots-starter -
Nutlope/restorePhotos - 使用人工智能修复模糊的旧人脸照片。
jina-ai/discoart - 一行创建迪斯科扩散艺术作品。
mlc-ai/web-stable-diffusion - 将稳定扩散模型引入网络浏览器;无需服务器支持,一切都在浏览器中运行。
all-in-aigc/aicover - 一个用于生成人工智能封面的工具。
huggingface/datasets - 最大的机器学习模型数据集中心拥有快速、易用且高效的数据操作工具。
BuilderIO/gpt-crawler - 从一个网址抓取网站内容以生成创建自定义GPT所需的知识文件。
joke2k/faker - Faker是一个用于生成虚假数据的Python包。
DS4SD/docling - 为生成式人工智能准备好你的文档。
openai/tiktoken - Tiktoken是适用于OpenAI模型的一种快速的BPE分词器。
cleanlab/cleanlab - 标准的人工智能包专注于用于质量和机器学习的数据,处理杂乱的现实世界数据和标签。
karpathy/minbpe - 用于大型语言模型(LLM)标记化中常用的字节对编码(BPE)算法的简洁代码。
huggingface/tokenizers - 快速、先进的分词器,为研究和生产进行了优化。
arsenetar/dupeguru - 查找重复文件。
QuivrHQ/MegaParse - 优化的文件解析器,用于无损的大型语言模型(LLM)摄入,能够将PDF、Docx、PPTx文件解析成适合大型语言模型(LLM)的理想格式。
togethercomputer/RedPajama-Data - RedPajama - 数据存储库中有用于为大型语言模型训练准备大型数据集的代码。
lk-geimfari/mimesis - Mimesis是一个Python数据生成器,能够创建多种语言的各类虚假数据。
Instruction-Tuning-with-GPT-4/GPT-4-LLM - 使用GPT - 4进行指令微调。
yizhongw/self-instruct - 将预训练语言模型与其自身生成的指令数据进行对齐。
dedupeio/dedupe - 一个用于精确和可扩展的模糊匹配、记录去重和实体解析的Python库。
argilla-io/argilla - Argilla是一种可供人工智能工程师和领域专家共同创建高质量数据集的工具。
mshumer/gpt-llm-trainer -
life4/textdistance - 使用30多种纯Python算法、通用接口以及可选择使用外部库来计算序列之间的距离。
Docta-ai/docta - 一位医生来照管你的数据。
alibaba/data-juicer - 为基础模型提供高质量、丰富且易于处理的数据。
towhee-io/towhee - Towhee是一个使神经数据处理管道变得简单快速的框架。
QData/TextAttack - TextAttack是一个用于自然语言处理(NLP)任务(如对抗性攻击、数据增强和模型训练)的Python框架。
seatgeek/thefuzz - Python中的模糊字符串匹配。
ekzhu/datasketch - 最小哈希、局部敏感哈希、局部敏感哈希森林、加权最小哈希、超对数、超对数++、局部敏感哈希集成和分层可导航小世界图。
thunlp/UltraChat - 大规模、信息丰富且多样的多轮聊天数据和模型。
modAL-python/modAL - 一个用Python编写的模块化主动学习框架。
chiphuyen/lazynlp - 一个用于爬取和清理网页以生成大型数据集的库。
huggingface/datatrove - 提供一组与平台无关的可定制管道处理模块,使数据处理不再依赖脚本编写。
refuel-ai/autolabel - 使用大型语言模型对文本数据集进行标记、清理和扩充。
google-deepmind/code_contests -
Tencent/MedicalNet - 许多研究表明,训练数据量会显著影响深度学习的性能。MedicalNet项目提供3D - ResNet预训练模型和代码。
argilla-io/distilabel - Distilabel是一个合成数据和人工智能反馈框架,适用于需要基于经过验证的研究论文构建快速、可靠且可扩展管道的工程师。
google-deepmind/mathematics_dataset - 该数据集代码从各种题型中创建学校难度级别的数学问答对。
openai/prm800k - 80万条针对大型语言模型(LLM)解决数学问题的答案的步骤级正确性标签。
salesforce/WikiSQL - 一个用于带有语义分析注释的自然语言界面开发的大型语料库。
anthropics/hh-rlhf - 用于训练通过人类反馈强化学习的助手(使其有用且无害)的人类偏好数据。
moj-analytical-services/splink - 快速、可扩展且精确的概率性数据链接,支持多种SQL后端。
dleemiller/WordLlama - 大型语言模型(LLM)的标记嵌入可完成的事情。
AI4Finance-Foundation/FinRL-Meta - FinRL - Meta为FinRL提供动态数据集和市场环境。
tensorflow/text - 将文本作为TensorFlow中的首要元素。
google-research/deduplicate-text-datasets -
allenai/dolma - 用于创建和检查OLMo预训练数据的数据和工具。
lilacai/lilac - 改进大型语言模型的数据管理。
1e0ng/simhash - 一种Simhash算法的Python实现。
J535D165/recordlinkage - 一个用于记录链接和重复数据检测的Python工具包,功能强大且模块化。
google-deepmind/tree - Tree是一个用于处理嵌套数据结构的库。
xtreme1-io/xtreme1 - Xtreme1是一个多模态数据训练一体化平台,支持3D激光雷达点云、图像和大型语言模型(LLM)进行数据标记和注释。
datadreamer-dev/DataDreamer - DataDreamer:提示、生成合成数据、训练和校准模型。
HazyResearch/meerkat - 所有数据集的创意性和交互性视图。
openai/evals - Evals是一个用于评估大型语言模型(LLMs)及其系统的框架,也是一个开源的基准测试注册中心。
explodinggradients/ragas - 为你对大型语言模型(LLM)应用的评估注入强大动力。
EleutherAI/lm-evaluation-harness - 一种使用少量样本评估语言模型的框架。
erikbern/ann-benchmarks - Python中近似最近邻库的基准测试。
Trusted-AI/adversarial-robustness-toolbox - 对抗性鲁棒性工具包(ART)是一个用于机器学习安全的Python库,涵盖了红蓝两队(攻防双方)的规避、投毒、提取和推理(攻击)。
open-compass/opencompass - OpenCompass是一个大型语言模型(LLM)评估平台,支持100多个数据集以及诸如Llama3、Mistral等各种各样的模型。
Arize-ai/phoenix - 人工智能可观察性与评估。
NVIDIA/NeMo-Guardrails - NeMo Guardrails是一个开源工具包,可轻松为基于大型语言模型(LLM)的对话系统添加可编程的防护栏。
confident-ai/deepeval - 大语言模型(LLM)评估框架。
Giskard-AI/giskard - 人工智能与大型语言模型(LLM)系统的开源评估与测试。
fchollet/ARC - 抽象推理语料库是一种资源,但没有更多细节的情况下,很难给出更具体的描述。它可能可用于各个领域中与抽象和推理相关的任务。
llm-attacks/llm-attacks - 对齐语言模型的通用可迁移攻击。
leondz/garak - 大型语言模型(LLM)漏洞扫描器。
jeinlee1991/chinese-llm-benchmark - 中国大模型能力评估清单包含134个模型,包括商业和开源模型,并提供能力评分和原始输出。
google/BIG-bench - 超越模仿游戏:一个用于衡量和推断语言模型能力的协作性基准。
meta-llama/PurpleLlama - 一组用于评估和增强大型语言模型(LLM)安全性的工具。
openai/human-eval - 论文《评估基于代码训练的大型语言模型》的代码
salesforce/decaNLP - 自然语言十项全能(竞赛)是自然语言处理领域的一项多任务挑战。
THUDM/AgentBench - 一个用于评估作为智能体的大型语言模型(LLMs)的综合基准(国际学习表征会议ICLR'24)。
truera/trulens - 大型语言模型(LLM)实验中的评估与跟踪。
princeton-nlp/SWE-bench - [国际学习表征会议(ICLR)2024] SWE - bench:语言模型能否解决现实世界中的GitHub(代码托管平台)问题。
Lightning-AI/torchmetrics - 适用于分布式且可扩展的PyTorch应用程序的机器学习指标。
openai/simple-evals -
huggingface/evaluate - 一个名为Evaluate的库,用于轻松评估机器学习模型和数据集。
embeddings-benchmark/mteb - MTEB是大规模文本嵌入基准测试。
Azure/PyRIT - PyRIT是一个开源框架,可帮助安全专业人员和工程师主动识别生成式人工智能系统中的风险。
stanford-crfm/helm - HELM是一个用于提高语言模型透明度的框架,它还用于评估其他模型,如HEIM中的文本到图像模型和VHELM中的视觉- 语言模型。
TransformerLensOrg/TransformerLens - 一个用于类GPT语言模型的机械可解释性的库。
beir-cellar/beir - 一个异构信息检索(IR)基准,用于轻松评估15个以上不同数据集的模型。
tatsu-lab/alpaca_eval - 一种指令遵循型语言模型的自动评估器。它经过人工验证,质量高、成本低且速度快。
microsoft/CodeXGLUE - CodeXGLUE是一个项目或者实体,但没有更多的上下文信息的话,很难说得更具体。
google-deepmind/bsuite - Bsuite是一组精心设计的实验,用于探索强化学习智能体的核心能力。
CalculatedContent/WeightWatcher - WeightWatcher工具用于预测深度神经网络的准确性。
facebookresearch/LAMA - 语言模型分析。
evalplus/evalplus - 在NeurIPS 2023和COLM 2024对大型语言模型(LLM)合成的代码进行严格评估。
vectara/hallucination-leaderboard - 用于比较大型语言模型(LLM)在总结短文时产生幻觉表现的排行榜。
hendrycks/test - 在2021年国际学习表征会议(ICLR)上衡量大规模多任务语言理解能力。
mlcommons/inference - MLPerf™推理基准的参考实现。
openai/grade-school-math -
rlancemartin/auto-evaluator - 大型语言模型问答链的评估工具。
openai/automated-interpretability -
allenai/natural-instructions - 该描述是关于扩展自然指令的。
WeOpenML/PandaLM -
thu-coai/Safety-Prompts - 用于评估和提升大型语言模型安全性的中国安全提示。
salesforce/OmniXAI - OmniXAI是一个可解释人工智能(XAI)库。
bigcode-project/bigcode-evaluation-harness - 用于评估自回归代码生成语言模型的框架。
hsiehjackson/RULER - 这个存储库包含RULER(关于长上下文语言模型的真实上下文大小)的源代码。
kubeflow/kubeflow - 一个专为Kubernetes设计的机器学习工具包。
Netflix/metaflow - 一个人工智能与机器学习的开源平台。
skypilot-org/skypilot - SkyPilot能够在任何基础设施(Kubernetes或12种以上的云)上运行AI和批处理作业,通过一个简单的接口提供统一的执行、成本节约和高GPU可用性。
gpuweb/gpuweb - 这是网络中GPU(图形处理器)工作的地方。
zenml-io/zenml - ZenML:机器学习与操作之间的联系。
higgsfield-ai/higgsfield - 容错且高度可扩展的GPU编排,以及用于训练大规模模型的机器学习框架。
Haidra-Org/AI-Horde - 一个用于生成人工智能艺术和文本的众包分布式集群。
steven-tey/novel - 一个所见即所得且具有人工智能驱动的自动补全功能的类似Notion的编辑器。
reorproject/reor - 一款面向高熵人群的、私密且本地化的人工智能个人知识管理应用。
shibing624/pycorrector - Pycorrector是一个文本纠错工具包,有多种用于纠错的模型应用且易于使用。
BlinkDL/AI-Writer - 人工智能创作诸如奇幻和浪漫网络小说之类的小说。它是一个类似于GPT - 2、使用RWKV模型的中文预训练生成模型。
mshumer/gpt-author -
Nutlope/twitterbio - 使用人工智能创建你的推特简介。
nhaouari/obsidian-textgenerator-plugin - Text Generator是一个Obsidian插件,可用于与OpenAI、Anthropic、Google等各种人工智能供应商以及本地模型一起生成文本。
google-deepmind/dramatron - Dramatron利用大型语言模型来生成连贯的脚本和剧本。
nebuly-ai/nebuly - 一组用于优化人工智能模型性能的库。
langfuse/langfuse - 具有多种集成(用于大型语言模型可观测性、指标等)的开源大型语言模型工程平台。它来自于YC W23。
evidentlyai/evidently - Evidently is an open source framework for machine learning (ML) and large language model (LLM) observability, which can be used to evaluate, test and monitor artificial intelligence-related systems or data pipelines, with more than 100 items index .
traceloop/openllmetry - 依靠OpenTelemetry(开放遥测)为您的大型语言模型(LLM)应用提供开源可观测性。
Helicone/helicone - 一个开源的大型语言模型(LLM)可观测性平台。一行代码即可用于监控、评估和实验。
whylabs/whylogs - 一个用于记录机器学习模型和管道中数据的开源库。它提供数据质量和模型性能的可见性,以及受隐私保护的数据收集。
uptrain-ai/uptrain - UpTrain是一个用于评估和改进生成式人工智能应用的开源平台。它为预配置的检查提供评分,分析故障并给出解决方案。
labmlai/labml - 通过手机监控深度学习模型训练和硬件使用情况。
lmnr-ai/lmnr - Laminar是一个用于构建人工智能产品的开源一体化平台。它通过跟踪、评估、数据集和标签为人工智能应用创建数据飞轮(YC S24)。
llmonitor/llmonitor - 大语言模型(LLMs)的生产工具包涉及可观测性、提示管理和评估。
lunary-ai/lunary - 大型语言模型(LLMs)的生产工具包包括可观测性、提示管理和评估。
dillionverma/llm.report - llm.report是一个针对OpenAI的开源平台,用于记录API请求、成本分析和提示优化。
whylabs/langkit - LangKit是一个用于大型语言模型(LLM)监控的开源工具包。它具有用于LLM可观测性的文本质量和情感分析等功能。
RayVentura/ShortGPT - ShortGPT——一个用于自动化运营YouTube Shorts(短视频)/TikTok(抖音国际版)频道的实验性AI框架。
all-in-aigc/sorafm - 由Sora.FM提供的Sora人工智能视频生成器。
ibis-project/ibis - 可移植的Python数据框库。
SuperDuperDB/superduperdb - Superduper能够在现有数据基础设施和首选工具上构建端到端的人工智能应用程序和代理工作流,无需进行数据迁移。
run-llama/llama-hub - 由社区制作的数据加载器库,用于LlamaIndex和/或LangChain的大型语言模型(LLM)。
webdataset/webdataset - 一个适用于各种规模深度学习问题的基于Python的输入输出(I/O)系统,强力支持PyTorch。
NVIDIA/aistore - AIStore:可扩展的AI应用程序存储。
mosaicml/streaming - 一种用于高效神经网络训练的数据流库。
code-kern-ai/refinery - 数据科学家用于扩展、评估和维护自然语言数据的开源选项。将训练数据视为软件工件。
lastmile-ai/aiconfig - AIConfig是一个基于配置构建生成式AI应用程序的框架。
我们非常欢迎您对本仓库做出贡献。您可以:
提交新的AI项目或资源链接。
改进现有项目的描述或分类。
报告问题或提出改进建议。
参与讨论并帮助其他成员解决问题。
请阅读我们的贡献指南了解更多细节。
本项目采用MIT许可证进行授权- 详情参见LICENSE文件。


