awesome RLHF
1.0.0
นี่คือชุดของงานวิจัยสำหรับ การเรียนรู้การเสริมแรงด้วยความคิดเห็นของมนุษย์ (RLHF) และที่เก็บจะได้รับการปรับปรุงอย่างต่อเนื่องเพื่อติดตามชายแดนของ RLHF
ยินดีต้อนรับสู่การติดตามและดาว!
Awesome RLHF (RL พร้อมคำติชมของมนุษย์)
2024
2023
2022
2021
2020 และก่อน
คำอธิบายโดยละเอียด
สารบัญ
ภาพรวมของ RLHF
เอกสาร
รหัสฐาน
ชุดข้อมูล
บล็อก
การสนับสนุนภาษาอื่น ๆ
การบริจาค
ใบอนุญาต
แนวคิดของ RLHF คือการใช้วิธีการจากการเรียนรู้การเสริมแรงเพื่อเพิ่มประสิทธิภาพแบบจำลองภาษาโดยตรงกับข้อเสนอแนะของมนุษย์ RLHF ได้เปิดใช้งานแบบจำลองภาษาเพื่อเริ่มจัดทำโมเดลที่ผ่านการฝึกอบรมเกี่ยวกับคลังข้อมูลทั่วไปของข้อมูลข้อความให้เป็นค่านิยมของมนุษย์ที่ซับซ้อน
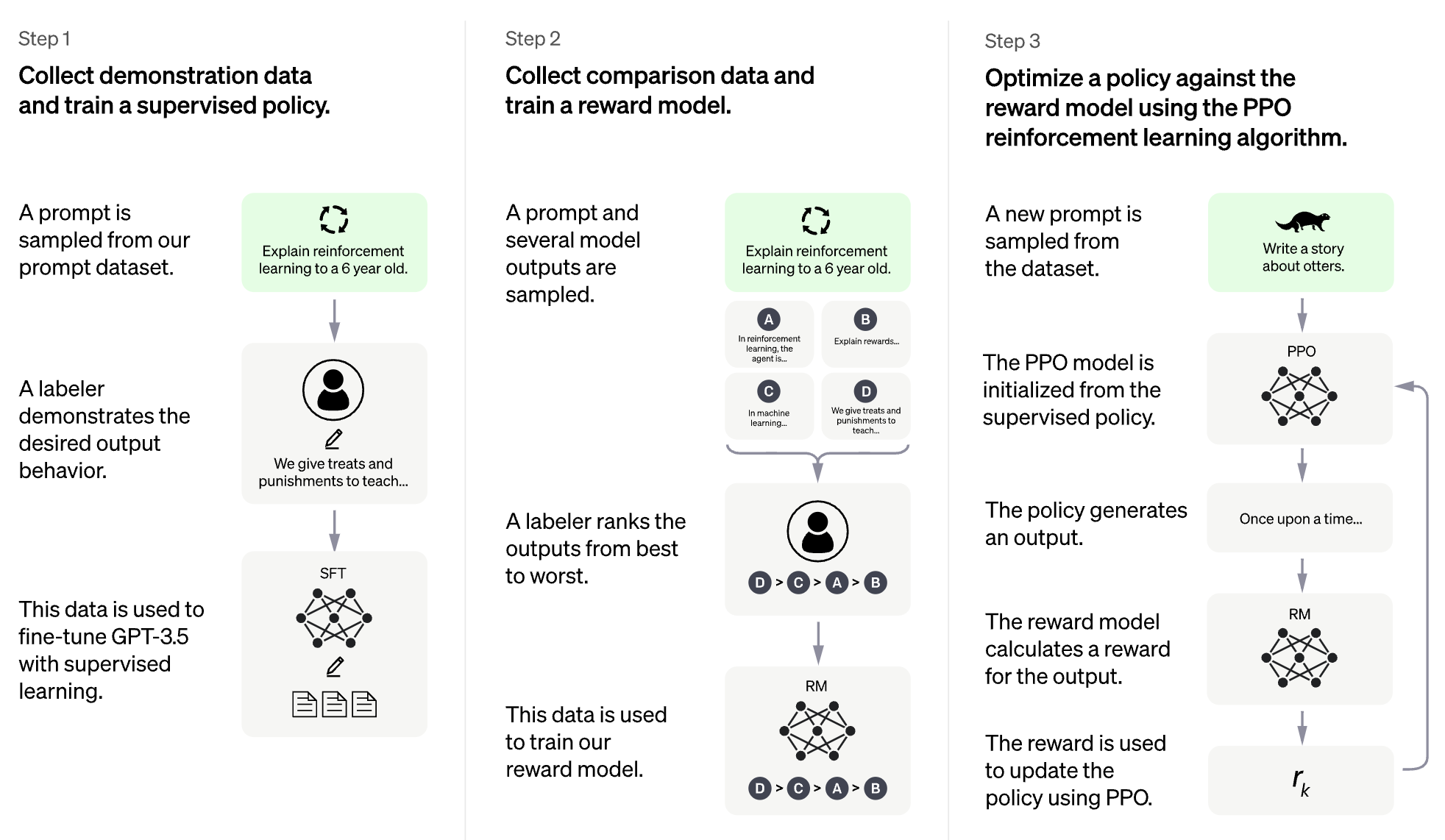
RLHF สำหรับรูปแบบภาษาขนาดใหญ่ (LLM)
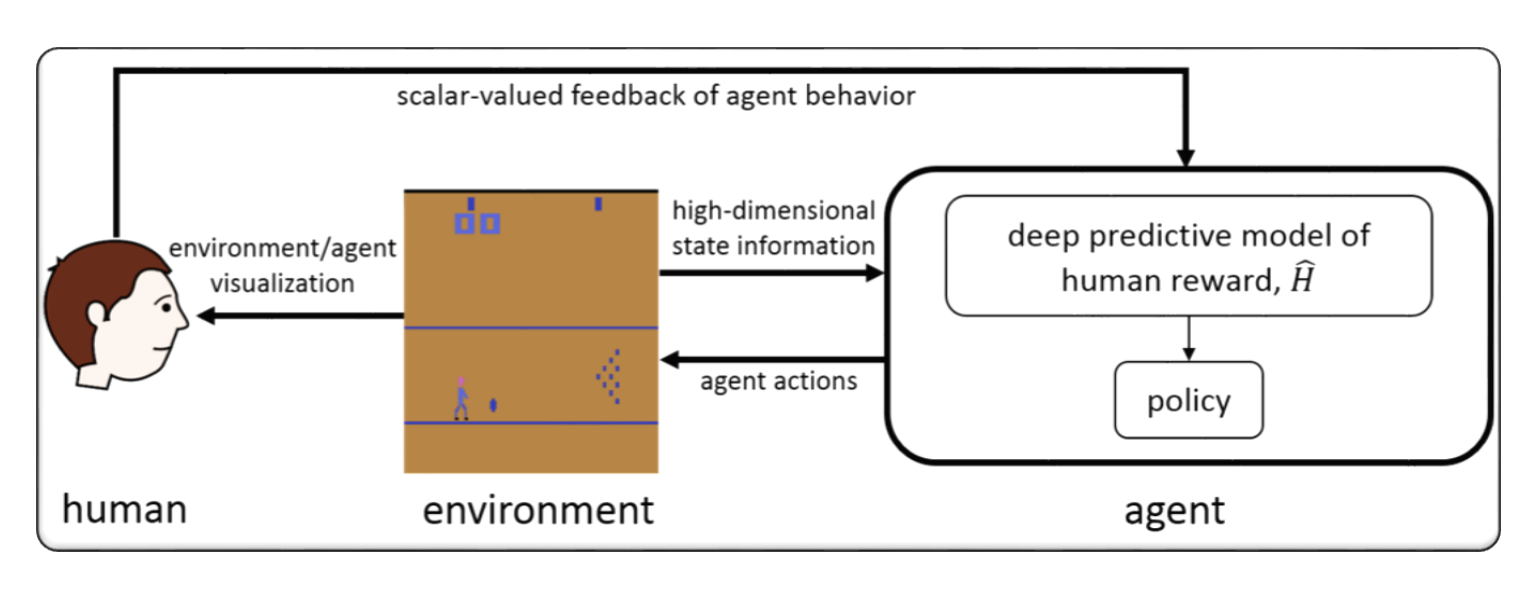
RLHF สำหรับวิดีโอเกม (เช่น Atari)
(ส่วนต่อไปนี้ถูกสร้างขึ้นโดยอัตโนมัติโดย CHATGPT)
โดยทั่วไปแล้ว RLHF หมายถึง "การเรียนรู้การเสริมแรงด้วยความคิดเห็นของมนุษย์" การเรียนรู้เสริมแรง (RL) เป็นประเภทของการเรียนรู้ของเครื่องที่เกี่ยวข้องกับการฝึกอบรมตัวแทนเพื่อทำการตัดสินใจตามข้อเสนอแนะจากสภาพแวดล้อม ใน RLHF ตัวแทนยังได้รับคำติชมจากมนุษย์ในรูปแบบของการให้คะแนนหรือการประเมินผลการกระทำของมันซึ่งสามารถช่วยให้มันเรียนรู้ได้อย่างรวดเร็วและแม่นยำยิ่งขึ้น
RLHF เป็นพื้นที่วิจัยที่ใช้งานอยู่ในปัญญาประดิษฐ์โดยมีแอปพลิเคชันในสาขาต่าง ๆ เช่นหุ่นยนต์เกมและระบบแนะนำส่วนบุคคล มันพยายามที่จะจัดการกับความท้าทายของ RL ในสถานการณ์ที่ตัวแทนมีการ จำกัด การเข้าถึงข้อเสนอแนะจากสภาพแวดล้อมและต้องการการป้อนข้อมูลของมนุษย์เพื่อปรับปรุงประสิทธิภาพ
การเรียนรู้การเสริมแรงด้วยข้อเสนอแนะของมนุษย์ (RLHF) เป็นพื้นที่ที่กำลังพัฒนาอย่างรวดเร็วของการวิจัยด้านปัญญาประดิษฐ์และมีเทคนิคขั้นสูงหลายอย่างที่ได้รับการพัฒนาเพื่อปรับปรุงประสิทธิภาพของระบบ RLHF นี่คือตัวอย่างบางส่วน:
Inverse Reinforcement Learning (IRL) : IRL เป็นเทคนิคที่ช่วยให้ตัวแทนเรียนรู้ฟังก์ชั่นรางวัลจากข้อเสนอแนะของมนุษย์แทนที่จะพึ่งพาฟังก์ชั่นการให้รางวัลที่กำหนดไว้ล่วงหน้า สิ่งนี้ทำให้ตัวแทนได้เรียนรู้จากสัญญาณตอบรับที่ซับซ้อนมากขึ้นเช่นการสาธิตพฤติกรรมที่ต้องการ
Apprenticeship Learning : การเรียนรู้การฝึกงานเป็นเทคนิคที่ผสมผสาน IRL กับการเรียนรู้ภายใต้การดูแลเพื่อให้ตัวแทนเรียนรู้จากทั้งข้อเสนอแนะของมนุษย์และการสาธิตผู้เชี่ยวชาญ สิ่งนี้สามารถช่วยให้ตัวแทนเรียนรู้ได้อย่างรวดเร็วและมีประสิทธิภาพมากขึ้นเนื่องจากสามารถเรียนรู้จากข้อเสนอแนะทั้งในเชิงบวกและเชิงลบ
Interactive Machine Learning (IML) : IML เป็นเทคนิคที่เกี่ยวข้องกับการมีปฏิสัมพันธ์ระหว่างตัวแทนและผู้เชี่ยวชาญของมนุษย์ทำให้ผู้เชี่ยวชาญสามารถให้ข้อเสนอแนะเกี่ยวกับการกระทำของตัวแทนในเวลาจริง สิ่งนี้สามารถช่วยให้ตัวแทนเรียนรู้ได้อย่างรวดเร็วและมีประสิทธิภาพมากขึ้นเนื่องจากสามารถรับข้อเสนอแนะเกี่ยวกับการกระทำในแต่ละขั้นตอนของกระบวนการเรียนรู้
Human-in-the-Loop Reinforcement Learning (HITLRL) : HITLRL เป็นเทคนิคที่เกี่ยวข้องกับการรวมความคิดเห็นของมนุษย์เข้ากับกระบวนการ RL ในหลายระดับเช่นการสร้างรางวัลการเลือกการกระทำและการเพิ่มประสิทธิภาพนโยบาย สิ่งนี้สามารถช่วยปรับปรุงประสิทธิภาพและประสิทธิผลของระบบ RLHF โดยใช้ประโยชน์จากจุดแข็งของมนุษย์และเครื่องจักร
นี่คือตัวอย่างของการเรียนรู้การเสริมแรงพร้อมข้อเสนอแนะของมนุษย์ (RLHF):
Game Playing : ในการเล่นเกมข้อเสนอแนะของมนุษย์สามารถช่วยให้ตัวแทนเรียนรู้กลยุทธ์และกลยุทธ์ที่มีประสิทธิภาพในสถานการณ์เกมที่แตกต่างกัน ตัวอย่างเช่นในเกมยอดนิยมของ GO ผู้เชี่ยวชาญสามารถให้ข้อเสนอแนะกับตัวแทนในการเคลื่อนไหวช่วยปรับปรุงการเล่นเกมและการตัดสินใจ
Personalized Recommendation Systems : ในระบบแนะนำข้อเสนอแนะของมนุษย์สามารถช่วยให้ตัวแทนเรียนรู้การตั้งค่าของผู้ใช้แต่ละคนทำให้สามารถให้คำแนะนำส่วนบุคคลได้ ตัวอย่างเช่นเอเจนต์สามารถใช้ข้อเสนอแนะจากผู้ใช้ในผลิตภัณฑ์ที่แนะนำเพื่อเรียนรู้ว่าคุณสมบัติใดที่สำคัญที่สุดสำหรับพวกเขา
Robotics : ในหุ่นยนต์ความคิดเห็นของมนุษย์สามารถช่วยให้ตัวแทนเรียนรู้วิธีการโต้ตอบกับสภาพแวดล้อมทางกายภาพในลักษณะที่ปลอดภัยและมีประสิทธิภาพ ตัวอย่างเช่นหุ่นยนต์สามารถเรียนรู้ที่จะนำทางสภาพแวดล้อมใหม่ได้เร็วขึ้นด้วยการตอบรับจากผู้ประกอบการมนุษย์บนเส้นทางที่ดีที่สุดในการรับหรือวัตถุที่ควรหลีกเลี่ยง
Education : ในการศึกษาความคิดเห็นของมนุษย์สามารถช่วยให้ตัวแทนเรียนรู้วิธีการสอนนักเรียนได้อย่างมีประสิทธิภาพมากขึ้น ตัวอย่างเช่นครูสอนพิเศษที่ใช้ AI สามารถใช้ข้อเสนอแนะจากครูที่กลยุทธ์การสอนทำงานได้ดีที่สุดกับนักเรียนที่แตกต่างกันช่วยปรับแต่งประสบการณ์การเรียนรู้ให้เป็นส่วนตัว
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
HybridFlow: กรอบ RLHF ที่ยืดหยุ่นและมีประสิทธิภาพ
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
คำหลัก: เฟรมเวิร์ก RLHF ที่ยืดหยุ่นมีประสิทธิภาพมีประสิทธิภาพ
รหัส: อย่างเป็นทางการ
สัญญาณเตือน: จัดแนวโมเดลภาษาผ่านการสร้างแบบจำลองผลตอบแทนแบบลำดับชั้น
Yuhang Lai, Siyuan Wang, Shujun Liu, Xuanjing Huang, Zhongyu Wei
คำสำคัญ: รางวัลลำดับชั้น, งานสร้างข้อความแบบเปิด
รหัส: อย่างเป็นทางการ
TLCR: รางวัลต่อเนื่องระดับโทเค็นสำหรับการเรียนรู้การเสริมแรงอย่างละเอียดจากข้อเสนอแนะของมนุษย์
Eunseop Yoon, Hee Suk Yoon, Soohwan Eom, Gunsoo Han, Daniel Wontae Nam, Daejin Jo, Kyoung-Woon On, Mark A. Hasegawa-Johnson, Sungwoong Kim, Chang D. Yoo
คำสำคัญ: รางวัลต่อเนื่องระดับโทเค็น RLHF
รหัส: อย่างเป็นทางการ
จัดแนวโมเดลหลายรูปแบบขนาดใหญ่กับ Augmented RLHF ตามความเป็นจริง
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
คำสำคัญ: Augmented RLHF, Vision & Language, ชุดข้อมูลการตั้งค่าของมนุษย์
รหัส: อย่างเป็นทางการ
ตรงไปตรงมาการจัดตำแหน่งแบบจำลองภาษาขนาดใหญ่ผ่านการกลั่นด้วยความคมชัดที่ได้จากตนเอง
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
คำสำคัญ: ไม่มีข้อมูลการตั้งค่าของมนุษย์รางวัลตนเอง DPO
รหัส: อย่างเป็นทางการ
การควบคุมเลขคณิตของ LLMs สำหรับการตั้งค่าผู้ใช้ที่หลากหลาย: การจัดตำแหน่งการตั้งค่าทิศทางกับรางวัลหลายวัตถุประสงค์
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, Tong Zhang
คำหลัก: การตั้งค่าของผู้ใช้, โมเดลรางวัลหลายวัตถุประสงค์, การสุ่มตัวอย่างการปฏิเสธ finetuning
รหัส: อย่างเป็นทางการ
กลับไปสู่พื้นฐาน: ทบทวนการเพิ่มประสิทธิภาพสไตล์เสริมสำหรับการเรียนรู้จากข้อเสนอแนะของมนุษย์ใน LLMS
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet üstün, Sara Hooker
คำหลัก: การเพิ่มประสิทธิภาพ RL ออนไลน์ค่าใช้จ่ายในการคำนวณต่ำ
รหัส: อย่างเป็นทางการ
การปรับปรุงแบบจำลองภาษาขนาดใหญ่ผ่านการเรียนรู้การเสริมแรงอย่างละเอียดพร้อมข้อ จำกัด การแก้ไขขั้นต่ำ
Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
คำสำคัญ: รางวัลระดับโทเค็น LLM
รหัส: อย่างเป็นทางการ
RLAIF vs. RLHF: การเรียนรู้การเสริมแรงจากการตอบกลับของมนุษย์พร้อมคำติชม AI
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakash
คำสำคัญ: RL จาก AI คำติชม
รหัส: อย่างเป็นทางการ
วิธีการตามหลักการลงโทษสำหรับการเรียนรู้การเสริมแรงของ Bilevel และ RLHF
Han Shen, Zhuoran Yang, Tianyi Chen
คำสำคัญ: การเพิ่มประสิทธิภาพ Bilevel
รหัส: อย่างเป็นทางการ
รางวัลหนาแน่นฟรีในการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์
Alex James Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
คำสำคัญ: รางวัลการสร้าง RLHF
รหัส: อย่างเป็นทางการ
วิธีการ minimaxiMalist เพื่อเสริมการเรียนรู้จากข้อเสนอแนะของมนุษย์
Gokul Swamy, Christoph Dann, Rahul Kidambi, Steven Wu, Alekh Agarwal
คำหลัก: ผู้ชนะขั้นต่ำแม็กซ์การเพิ่มประสิทธิภาพการตั้งค่าการเล่นด้วยตนเอง
รหัส: อย่างเป็นทางการ
RLHF-V: ไปสู่ MLLM ที่น่าเชื่อถือผ่านการจัดตำแหน่งพฤติกรรมจากข้อเสนอแนะของมนุษย์ที่มีความละเอียด
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen HE, Yifeng Han, Ganquan Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
คำสำคัญ: แบบจำลองภาษาขนาดใหญ่หลายรูปแบบปัญหาภาพหลอนการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์
รหัส: อย่างเป็นทางการ
เวิร์กโฟลว์ RLHF: จากการสร้างแบบจำลองรางวัลไปจนถึง RLHF ออนไลน์
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
คำสำคัญ: RLHF แบบวนซ้ำออนไลน์, การสร้างแบบจำลองการตั้งค่า, แบบจำลองภาษาขนาดใหญ่
รหัส: อย่างเป็นทางการ
Maxmin-RLHF: ไปสู่การจัดแนวแบบจำลองภาษาขนาดใหญ่ที่เป็นธรรมกับการตั้งค่าของมนุษย์ที่หลากหลาย
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
คำสำคัญ: ส่วนผสมของการแจกแจงการตั้งค่า, วัตถุประสงค์การจัดตำแหน่ง maxmin
รหัส: อย่างเป็นทางการ
การเพิ่มประสิทธิภาพนโยบายการรีเซ็ตชุดข้อมูลสำหรับ RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
คำหลัก: การเพิ่มประสิทธิภาพนโยบายการรีเซ็ตชุดข้อมูล
รหัส: อย่างเป็นทางการ
มุมมองรางวัลหนาแน่นเกี่ยวกับการจัดเรียงการแพร่กระจายข้อความกับภาพตามความชอบ
Shentao Yang, Tianqi Chen, Mingyuan Zhou
คำสำคัญ: RLHF สำหรับการสร้างข้อความเป็นภาพการปรับปรุง DPO การปรับปรุง DPO การจัดตำแหน่งที่มีประสิทธิภาพ
รหัส: อย่างเป็นทางการ
การปรับแต่งการปรับแต่งด้วยตนเองแปลงรูปแบบภาษาที่อ่อนแอเป็นรูปแบบภาษาที่แข็งแกร่ง
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu
คำหลัก: การปรับแต่งตนเองอย่างละเอียด
รหัส: อย่างเป็นทางการ
RLHF deciphered: การวิเคราะห์ที่สำคัญของการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์สำหรับ LLMS
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
คำสำคัญ: RLHF, รางวัล Oracular, การวิเคราะห์แบบจำลองรางวัล, การสำรวจ
การเผชิญหน้ากับรางวัล opoptimization สำหรับแบบจำลองการแพร่กระจาย: มุมมองของอคติอุปนัยและความเป็นอันดับหนึ่ง
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
คำสำคัญ: โมเดลการแพร่กระจายการจัดตำแหน่งการเรียนรู้การเสริมแรง RLHF รางวัลการ opoptimization รางวัลอคติอันดับหนึ่ง
รหัส: อย่างเป็นทางการ
เกี่ยวกับการตั้งค่าที่หลากหลายของการจัดตำแหน่งแบบจำลองภาษาขนาดใหญ่
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan Du, Zenglin Xu
คำสำคัญ: การจัดตำแหน่งการตั้งค่าที่ใช้ร่วมกัน, การสร้างแบบจำลองรางวัล, LLM
รหัส: อย่างเป็นทางการ
จัดแนวความคิดเห็นของฝูงชนผ่านการสร้างแบบจำลองรางวัลการตั้งค่าการกระจาย
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, Yong Liu
คำสำคัญ: RLHF, การกระจายการตั้งค่า, การจัดตำแหน่ง, LLM
นอกเหนือจากการจัดตำแหน่งแบบเดียวที่เหมาะสม: การเพิ่มประสิทธิภาพการตั้งค่าการตั้งค่าโดยตรงแบบหลายวัตถุประสงค์
Zhanhui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao
คำสำคัญ: RLHF หลายวัตถุประสงค์โดยไม่มีการสร้างแบบจำลองรางวัล DPO
รหัส: อย่างเป็นทางการ
Disalignment ที่เลียนแบบ: การจัดตำแหน่งความปลอดภัยสำหรับแบบจำลองภาษาขนาดใหญ่อาจย้อนกลับมาได้!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
คำสำคัญ: การโจมตีเวลา LLM, DPO, ผลิต LLM ที่เป็นอันตรายโดยไม่ต้องฝึกอบรม
รหัส: อย่างเป็นทางการ
การวิเคราะห์เชิงทฤษฎีของการเรียนรู้ของแนชจากข้อเสนอแนะของมนุษย์ภายใต้การตั้งค่า KL-regularized ทั่วไป
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
คำสำคัญ: RLHF ที่ใช้เกม, Nash Learning, การจัดตำแหน่งภายใต้ Oracle ที่ได้รับรางวัล
บรรเทาภาษีการจัดตำแหน่งของ RLHF
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, Yuan Yao, Yuan Yao,
คำสำคัญ: RLHF, ภาษีการจัดตำแหน่ง, การลืมหายนะ
รูปแบบการฝึกอบรมการแพร่กระจายด้วยการเรียนรู้การเสริมแรง
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, Sergey Levine
คำสำคัญ: การเรียนรู้การเสริมแรง, RLHF, แบบจำลองการแพร่กระจาย
รหัส: อย่างเป็นทางการ
Aligndiff: จัดแนวความชอบของมนุษย์ที่หลากหลายผ่านแบบจำลองการแพร่กระจายแบบกำหนดพฤติกรรม
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
คำสำคัญ: การเรียนรู้การเสริมแรง; แบบจำลองการแพร่กระจาย; Rlhf; การจัดตำแหน่งการตั้งค่า
รหัส: อย่างเป็นทางการ
รางวัลหนาแน่นฟรีในการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์
Alex J. Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
คำสำคัญ: RLHF
รหัส: อย่างเป็นทางการ
การเปลี่ยนแปลงและการรวมรางวัลสำหรับการจัดรูปแบบภาษาขนาดใหญ่
Zihao Wang, Chirag Nagpal, Jonathan Berant, Jacob Eisenstein, Alex d'Amour, Sanmi Koyejo, Victor Veitch
คำสำคัญ: RLHF, จัดตำแหน่ง, LLM
พารามิเตอร์การเรียนรู้การเสริมแรงอย่างมีประสิทธิภาพจากข้อเสนอแนะของมนุษย์
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Chaudhary Simral, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li , Abhinav Rastogi, Lucas Dixon
คำสำคัญ: RLHF, วิธีการที่มีประสิทธิภาพพารามิเตอร์, ต้นทุนการคำนวณต่ำ, LLM, VLM
การปรับปรุงการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์ด้วยชุดรูปแบบรางวัลที่มีประสิทธิภาพ
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
คำสำคัญ: RLHF, รางวัล Ensemble, วิธีการทั้งหมดที่มีประสิทธิภาพ
กระบวนทัศน์ทางทฤษฎีทั่วไปเพื่อทำความเข้าใจการเรียนรู้จากความชอบของมนุษย์
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos
คำสำคัญ: RLHF, การตั้งค่าแบบคู่
ข้อเสนอแนะของมนุษย์อย่างละเอียดจะให้รางวัลที่ดีกว่าสำหรับการฝึกอบรมรูปแบบภาษา
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
คำสำคัญ: RLHF, รางวัลระดับประโยค, LLM
รหัส: อย่างเป็นทางการ
คำแนะนำระดับโทเค็นที่มีเหตุผลสำหรับการปรับแต่งแบบจำลองภาษา
Shentao Yang, Shujian Zhang, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
คำสำคัญ: RLHF, แนวทางการฝึกอบรมระดับโทเค็น, กรอบการฝึกอบรมทางเลือก/ออนไลน์, วัตถุประสงค์การฝึกอบรมที่เรียบง่าย
รหัส: อย่างเป็นทางการ
รางวัลที่ยอดเยี่ยมและวิธีการทำให้เชื่อง: กรณีศึกษาเกี่ยวกับการเรียนรู้รางวัลสำหรับระบบบทสนทนาที่มุ่งเน้นงาน
Yihao Feng*, Shentao Yang*, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
คำสำคัญ: RLHF, การเรียนรู้ฟังก์ชั่นการให้รางวัล Genralized, การใช้ฟังก์ชั่นการให้รางวัล, ระบบบทสนทนาที่มุ่งเน้นงาน, การเรียนรู้เพื่อจัดอันดับ
รหัส: อย่างเป็นทางการ
การเรียนรู้การตั้งค่าผกผัน: RL ตามการตั้งค่าโดยไม่มีฟังก์ชั่นรางวัล
Joey Hejna, Dorsa Sadigh
คำสำคัญ: การเรียนรู้การตั้งค่าผกผันโดยไม่มีรูปแบบรางวัล
รหัส: อย่างเป็นทางการ
Alpacafarm: กรอบการจำลองสำหรับวิธีการเรียนรู้จากข้อเสนอแนะของมนุษย์
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy BA, Carlos Guestrin, Percy S. Liang, Tatsunori B. Hashimoto
คำสำคัญ: RLHF, กรอบการจำลอง
รหัส: อย่างเป็นทางการ
การเพิ่มประสิทธิภาพการจัดอันดับการตั้งค่าสำหรับการจัดตำแหน่งของมนุษย์
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, Houfeng Wang
คำหลัก: การเพิ่มประสิทธิภาพการจัดอันดับการตั้งค่า
รหัส: อย่างเป็นทางการ
การเพิ่มประสิทธิภาพการตั้งค่าของฝ่ายตรงข้าม
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Nan Du
คำสำคัญ: RLHF, GAN, เกมฝ่ายตรงข้าม
รหัส: อย่างเป็นทางการ
การเรียนรู้ซ้ำ ๆ จากการตอบรับจากความคิดเห็นของมนุษย์: การเชื่อมโยงทฤษฎีและการปฏิบัติสำหรับ RLHF ภายใต้ข้อ จำกัด ของ KL
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
คำสำคัญ: RLHF, ซ้ำ DPO, รากฐานทางคณิตศาสตร์
ตัวอย่างการเรียนรู้การเสริมแรงอย่างมีประสิทธิภาพจากข้อเสนอแนะของมนุษย์ผ่านการสำรวจที่ใช้งานอยู่
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, Willie Neiswanger
คำสำคัญ: RLHF, ประสิทธิภาพตัวอย่าง, การสำรวจ
การเรียนรู้การเสริมแรงจากข้อเสนอแนะทางสถิติ: การเดินทางจากการทดสอบ AB ไปยังการทดสอบมด
Feiyang Han, Yimin Wei, Zhaofeng Liu, Yanxing Qi
คำสำคัญ: RLHF, การทดสอบ AB, RLSF
การวิเคราะห์พื้นฐานของความสามารถของแบบจำลองรางวัลในการวิเคราะห์แบบจำลองพื้นฐานอย่างแม่นยำภายใต้การเปลี่ยนแปลงการกระจาย
Ben Pikus, Will Levine, Tony Chen, Sean Hendryx
คำสำคัญ: RLHF, OOD, Shift Distribution
การจัดตำแหน่งที่ประหยัดข้อมูลของแบบจำลองภาษาขนาดใหญ่ที่มีข้อเสนอแนะของมนุษย์ผ่านภาษาธรรมชาติ
Di Jin, Shikib Mehri, Devamanyu Hazarika, Aishwarya Padmakumar, Sungjin Lee, Yang Liu, Mahdi Namazifar
คำสำคัญ: RLHF, ประหยัดข้อมูล, การจัดตำแหน่ง
มาเสริมสร้างทีละขั้นตอน
Sarah Pan, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
คำสำคัญ: RLHF การให้เหตุผล
การเพิ่มประสิทธิภาพนโยบายตามการตั้งค่าโดยตรงโดยไม่มีการสร้างแบบจำลองรางวัล
Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, Hyun Oh Song
คำสำคัญ: RLHF โดยไม่มีการสร้างแบบจำลองรางวัล, การเรียนรู้แบบตัดกัน, การเรียนรู้การรับรู้แบบออฟไลน์
Aligndiff: จัดแนวความชอบของมนุษย์ที่หลากหลายผ่านแบบจำลองการแพร่กระจายแบบกำหนดพฤติกรรม
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
คำสำคัญ: RLHF, การจัดตำแหน่ง, แบบจำลองการแพร่กระจาย
ยูเรก้า: การออกแบบรางวัลระดับมนุษย์ผ่านการเข้ารหัสแบบจำลองภาษาขนาดใหญ่
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-an Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima Anandkumar
คำสำคัญ: LLM ใช้ฟังก์ชั่นการให้รางวัล
Safe RLHF: การเรียนรู้การเสริมแรงอย่างปลอดภัยจากข้อเสนอแนะของมนุษย์
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
คำหลัก: Sale RL, LLM Fine-Ture
ความหลากหลายที่มีคุณภาพผ่านข้อเสนอแนะของมนุษย์
Li Ding, Jenny Zhang, Jeff Clune, Lee Spector, Joel Lehman
คำสำคัญ: ความหลากหลายที่มีคุณภาพรูปแบบการแพร่กระจาย
Remax: วิธีการเรียนรู้การเสริมแรงที่เรียบง่ายมีประสิทธิภาพและมีประสิทธิภาพสำหรับการจัดรูปแบบภาษาขนาดใหญ่
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
คำสำคัญ: ประสิทธิภาพการคำนวณเทคนิคการลดความแปรปรวน
การปรับรุ่นคอมพิวเตอร์วิสัยทัศน์ด้วยรางวัลงาน
André Susano Pinto, Alexander Kolesnikov, Yuge Shi, Lucas Beyer, Xiaohua Zhai
คำสำคัญ: รางวัลการปรับแต่งในการมองเห็นคอมพิวเตอร์
ภูมิปัญญาของการเข้าใจถึงปัญหาหลังเหตุการณ์ทำให้โมเดลภาษาดีขึ้นผู้ติดตามการเรียนการสอน
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, Joseph E. Gonzalez
คำหลัก: คำสั่ง Hindsight Relabeling, ระบบ RLHF, ไม่จำเป็นต้องมีเครือข่ายมูลค่า
รหัส: อย่างเป็นทางการ
ภาษาที่ได้รับคำแนะนำการเรียนรู้การเสริมแรงสำหรับการประสานงานของมนุษย์-AI
Hengyuan Hu, Dorsa Sadigh
คำสำคัญ: การประสานงานของมนุษย์-AI, การจัดตำแหน่งการตั้งค่าของมนุษย์, การเรียนการสอนแบบมีเงื่อนไข RL
จัดรูปแบบภาษาที่มีการเรียนรู้การเสริมแรงแบบออฟไลน์จากข้อเสนอแนะของมนุษย์
Jian Hu, Li Tao, June Yang, Chandler Zhou
คำสำคัญ: การจัดตำแหน่งตามหม้อแปลงการตัดสินใจการเรียนรู้การเสริมแรงแบบออฟไลน์ระบบ RLHF
การเพิ่มประสิทธิภาพการจัดอันดับการตั้งค่าสำหรับการจัดตำแหน่งของมนุษย์
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li และ Houfeng Wang
คำสำคัญ: การจัดตำแหน่งการตั้งค่าความชอบของมนุษย์ภายใต้การดูแลการขยายการจัดอันดับการตั้งค่า
รหัส: อย่างเป็นทางการ
การเชื่อมช่องว่าง: การสำรวจเกี่ยวกับการบูรณาการข้อเสนอแนะ (มนุษย์) สำหรับการสร้างภาษาธรรมชาติ
Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José GC de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neubig, André ft Martins
คำสำคัญ: การสร้างภาษาธรรมชาติ, การรวมข้อเสนอแนะของมนุษย์, การตอบรับอย่างเป็นทางการและอนุกรมวิธาน, คำติชม AI และการตัดสินตามหลักการ
รายงานทางเทคนิค GPT-4
Openai
คำสำคัญ: โมเดลขนาดใหญ่หลายรูปแบบรุ่น transformerbased, RLHF ที่ใช้แล้วปรับแต่งอย่างละเอียด
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: Drop, Winogrande, Hellaswag, ARC, Humaneval, GSM8K, MMLU, Truthfulqa
Raft: รางวัลอันดับ Finetuning สำหรับการจัดแนวโมเดลพื้นฐานทั่วไป
Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang
คำสำคัญ: การปฏิเสธการสุ่มตัวอย่าง finetuning ทางเลือกสำหรับ PPO, โมเดลการแพร่กระจาย
รหัส: อย่างเป็นทางการ
RRHF: อันดับการตอบสนองต่อแบบจำลองภาษากับความคิดเห็นของมนุษย์โดยไม่ต้องน้ำตา
เจิ้งหยวน, ฮงยี่หยวน, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
คำสำคัญ: กระบวนทัศน์ใหม่สำหรับ RLHF
รหัส: อย่างเป็นทางการ
การเรียนรู้การตั้งค่าการยิงไม่กี่ครั้งสำหรับมนุษย์ในลูป RL
Joey Hejna, Dorsa Sadigh
คำสำคัญ: การเรียนรู้การตั้งค่าการเรียนรู้แบบโต้ตอบการเรียนรู้แบบหลายงานการขยายกลุ่มของข้อมูลที่มีอยู่โดยการดู RL ของมนุษย์ในวง
รหัส: อย่างเป็นทางการ
การจัดแนวแบบข้อความกับภาพให้ดีขึ้นตามความชอบของมนุษย์
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
คำสำคัญ: โมเดลการแพร่, ข้อความกับภาพ, ความงาม
รหัส: อย่างเป็นทางการ
ImageRardward: การเรียนรู้และประเมินความชอบของมนุษย์สำหรับการสร้างข้อความเป็นภาพ
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
คำสำคัญ: RM คำสำคัญ: การประเมินความชอบของมนุษย์กับภาพรวมการประเมินแบบจำลองการกำเนิดแบบข้อความกับภาพ
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: Coco, DiffusionDB
การจัดแนวโมเดลข้อความกับภาพโดยใช้ข้อเสนอแนะของมนุษย์
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
คำหลัก: แบบข้อความถึงภาพ, โมเดลการแพร่กระจายที่เสถียร, ฟังก์ชั่นรางวัลที่ทำนายข้อเสนอแนะของมนุษย์
Visual Chatgpt: การพูดคุยการวาดและการแก้ไขด้วยโมเดล Visual Foundation
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
คำหลัก: รุ่น Visual Foundation, Visual Chatgpt
รหัส: อย่างเป็นทางการ
แบบจำลองภาษาที่มีความต้องการของมนุษย์ (PHF)
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
คำสำคัญ: การเตรียมการ, RL ออฟไลน์, หม้อแปลงตัดสินใจ
รหัส: อย่างเป็นทางการ
จัดแนวโมเดลภาษาที่มีการตั้งค่าผ่านการย่อขนาด F-Divergence (F-DPG)
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
คำสำคัญ: F-Divergence, RL พร้อมบทลงโทษ KL
การเรียนรู้การเสริมแรงอย่างมีหลักการพร้อมข้อเสนอแนะของมนุษย์จากการเปรียบเทียบแบบคู่หรือ K-Wise
Banghua Zhu, Jiantao Jiao, Michael I. Jordan
คำสำคัญ: mle ในแง่ร้าย, max-entropy irl
ความสามารถในการแก้ไขตนเองทางศีลธรรมในรูปแบบภาษาขนาดใหญ่
มานุษยวิทยา
คำสำคัญ: ปรับปรุงความสามารถในการแก้ไขตนเองทางศีลธรรมโดยการเพิ่มการฝึกอบรม RLHF
ชุดข้อมูล; บาร์บีคิว
การเรียนรู้การเสริมแรง (ไม่ใช่) สำหรับการประมวลผลภาษาธรรมชาติหรือไม่: มาตรฐาน, baselines และการสร้างบล็อกสำหรับการเพิ่มประสิทธิภาพนโยบายภาษาธรรมชาติ (NLPO)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
คำสำคัญ: การเพิ่มประสิทธิภาพเครื่องกำเนิดภาษาด้วย RL, เกณฑ์มาตรฐาน, อัลกอริทึม RL Performant
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (en-de), NarrativeQa, DailyDialog
การปรับขนาดกฎหมายสำหรับแบบจำลองรางวัล opoptimization
Leo Gao, John Schulman, Jacob Hilton
คำหลัก: รุ่น Gold Model Model Model Proxy Reward, ขนาดชุดข้อมูล, ขนาดพารามิเตอร์นโยบาย, BON, PPO
การปรับปรุงการจัดตำแหน่งตัวแทนการสนทนาผ่านการตัดสินของมนุษย์เป้าหมาย (Sparrow)
Amelia Glaese, Nat McAleese, Maja Trębacz, และคณะ
คำหลัก: ตัวแทนการสนทนาการค้นหาข้อมูลแบ่งบทสนทนาที่ดีลงในกฎภาษาธรรมชาติ, DPC, โต้ตอบกับรูปแบบเพื่อล้วงเอาการละเมิดกฎเฉพาะ (การตรวจหาฝ่ายตรงข้าม)
ชุดข้อมูล: คำถามธรรมชาติ, Eli5, คุณภาพ, Triviaqa, Winobias, BBQ
แบบจำลองภาษาที่เป็นทีมสีแดงเพื่อลดอันตราย: วิธีการปรับขนาดพฤติกรรมและบทเรียนที่ได้เรียนรู้
Deep Ganguli, Liane Lovitt, Jackson Kernion และคณะ
คำสำคัญ: รูปแบบภาษาทีมสีแดงตรวจสอบพฤติกรรมการปรับขนาดอ่านชุดข้อมูลการทำงานเป็นทีม
รหัส: อย่างเป็นทางการ
การวางแผนแบบไดนามิกในการสนทนาแบบเปิดปลายโดยใช้การเรียนรู้การเสริมแรง
Deborah Cohen, Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor, Craig Boutilier, Gal Elidan
คำสำคัญ: ระบบบทสนทนาแบบเรียลไทม์คู่เปิดการฝังตัวของสถานะการสนทนาโดยแบบจำลองภาษา CAQL, CQL, Bert
Quark: การสร้างข้อความที่ควบคุมได้ด้วยการเสริมแรงแบบเสริมแรง
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
คำสำคัญ: การปรับรูปแบบภาษาบนสัญญาณของสิ่งที่ไม่ควรทำหม้อแปลงตัดสินใจการปรับแต่ง LLM ด้วย PPO
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: WritingPrompts, SST-2, Wikitext-103
การฝึกอบรมผู้ช่วยที่เป็นประโยชน์และไม่เป็นอันตรายด้วยการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์
Yuntao Bai, Andy Jones, Kamal Ndousse, et al.
คำหลัก: ผู้ช่วยที่ไม่เป็นอันตราย, โหมดออนไลน์, ความทนทานของการฝึกอบรม RLHF, การตรวจจับ OOD
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: Triviaqa, Hellaswag, Arc, OpenBookqa, Lambada, Humaneval, MMLU, Truthfulqa
แบบจำลองภาษาการสอนเพื่อสนับสนุนคำตอบด้วยคำพูดที่ผ่านการตรวจสอบแล้ว (Gophercite)
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, Nat McAleese
คำสำคัญ: สร้างคำตอบที่อ้างถึงหลักฐานเฉพาะงดการตอบเมื่อไม่แน่ใจ
ชุดข้อมูล: คำถามธรรมชาติ, Eli5, คุณภาพ, Trustfulqa
แบบจำลองภาษาการฝึกอบรมเพื่อทำตามคำแนะนำที่มีข้อเสนอแนะของมนุษย์ (InstructGPT)
Long Ouyang, Jeff Wu, Xu Jiang, et al.
คำสำคัญ: รูปแบบภาษาขนาดใหญ่จัดรูปแบบภาษาให้สอดคล้องกับความตั้งใจของมนุษย์
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: TrustfulQa, RealtoxicityPrompts
รัฐธรรมนูญ AI: ความไม่เป็นอันตรายจากข้อเสนอแนะ AI
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, et al.
คำหลัก: RL จาก AI Feedback (RLAIF), การฝึกอบรมผู้ช่วย AI ที่ไม่เป็นอันตรายผ่านการพัฒนาตนเอง, สไตล์โซ่แห่งความคิด, ควบคุมพฤติกรรม AI ได้อย่างแม่นยำยิ่งขึ้น
รหัส: อย่างเป็นทางการ
การค้นพบพฤติกรรมแบบจำลองภาษาด้วยการประเมินแบบจำลองที่เขียนขึ้น
Ethan Perez, Sam Ringer, KamilėLukošiūtė, Karina Nguyen, Edwin Chen, et al.
คำหลัก: สร้างการประเมินโดยอัตโนมัติด้วย LMS, RLHF มากขึ้นทำให้ LMS แย่ลงการประเมิน LM ที่เขียนเป็นคุณภาพสูง
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: BBQ, Winogender Schemas
การสร้างแบบจำลองรางวัล Non-Markovian จากฉลากวิถีผ่านการเรียนรู้หลายอินสแตนซ์ที่ตีความได้
Joseph Early, Tom Bewley, Christine Evers, Sarvapali Ramchurn
คำหลัก: การสร้างแบบจำลองรางวัล (RLHF), ไม่ใช่มาร์คโวเวียน, การเรียนรู้หลายอินสแตนซ์, การตีความได้
รหัส: อย่างเป็นทางการ
WebGPT: การตอบคำถามที่ได้รับการช่วยเหลือจากเบราว์เซอร์พร้อมคำติชมของมนุษย์ (WebGPT)
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, et al.
คำหลัก: การค้นหาแบบจำลองเว็บและให้การอ้างอิง, การเรียนรู้การเลียนแบบ, BC, คำถามแบบฟอร์มยาว
ชุดข้อมูล: Eli5, Triviaqa, Truthfulqa
สรุปหนังสือซ้ำอีกครั้งพร้อมคำติชมของมนุษย์
Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, Paul Christiano
คำหลัก: โมเดลที่ผ่านการฝึกอบรมเกี่ยวกับงานเล็ก ๆ เพื่อช่วยให้มนุษย์ประเมินงานที่กว้างขึ้น BC
ชุดข้อมูล: หนังสือ, NarrativeQa
ทบทวนจุดอ่อนของการเรียนรู้การเสริมแรงสำหรับการแปลเครื่องประสาท
Samuel Kiegeland, Julia Kreutzer
คำสำคัญ: ความสำเร็จของการไล่ระดับสีเป็นเพราะรางวัลมากกว่ารูปร่างของการแจกแจงเอาท์พุท, การแปลของเครื่อง, NMT, การปรับโดเมน
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: WMT15, IWSLT14
เรียนรู้ที่จะสรุปจากข้อเสนอแนะของมนุษย์
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
คำหลัก: ใส่ใจเกี่ยวกับคุณภาพสรุปการสูญเสียการฝึกอบรมส่งผลกระทบต่อพฤติกรรมของแบบจำลอง
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: TL; DR, CNN/DM
แบบจำลองภาษาที่ปรับแต่งจากการตั้งค่าของมนุษย์
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
คำสำคัญ: รางวัลการเรียนรู้ภาษาสำหรับการดำเนินการต่อไปด้วยความเชื่อมั่นในเชิงบวกงานสรุปคำอธิบายทางกายภาพ
รหัส: อย่างเป็นทางการ
ชุดข้อมูล: TL; DR, CNN/DM
การจัดตำแหน่งตัวแทนที่ปรับขนาดได้ผ่านการสร้างแบบจำลองรางวัล: ทิศทางการวิจัย
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg
คำสำคัญ: ปัญหาการจัดตำแหน่งตัวแทนเรียนรู้รางวัลจากการมีปฏิสัมพันธ์เพิ่มประสิทธิภาพการให้รางวัลด้วย RL การสร้างแบบจำลองรางวัลแบบเรียกซ้ำ
รหัส: อย่างเป็นทางการ
env: อาตาริ
ให้รางวัลการเรียนรู้จากการตั้งค่าของมนุษย์และการสาธิตในอาตาริ
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, Dario Amodei
คำสำคัญ: การตั้งค่าวิถีการสาธิตผู้เชี่ยวชาญให้รางวัลการแฮ็กปัญหาการแฮ็กเสียงในฉลากของมนุษย์
รหัส: อย่างเป็นทางการ
env: อาตาริ
Deep Tamer: การสร้างตัวแทนแบบโต้ตอบในพื้นที่รัฐมิติสูง
Garrett Warnell, Nicholas Waytowich, Vernon Lawhern, Peter Stone
คำสำคัญ: สถานะมิติสูงใช้ประโยชน์จากการป้อนข้อมูลของเทรนเนอร์มนุษย์
รหัส: บุคคลที่สาม
env: อาตาริ
การเรียนรู้การเสริมแรงอย่างลึกซึ้งจากการตั้งค่าของมนุษย์
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
คำสำคัญ: สำรวจเป้าหมายที่กำหนดไว้ในการตั้งค่าของมนุษย์ระหว่างคู่ของการแบ่งส่วนวิถี, เรียนรู้สิ่งที่ซับซ้อนมากกว่าข้อเสนอแนะของมนุษย์
รหัส: อย่างเป็นทางการ
env: Atari, Mujoco
การเรียนรู้แบบโต้ตอบจากข้อเสนอแนะของมนุษย์ตามนโยบาย
James MacGlashan, Mark K Ho, Robert Loftin, Bei Peng, Guan Wang, David Roberts, Matthew E. Taylor, Michael L. Littman
คำหลัก: การตัดสินใจได้รับอิทธิพลจากนโยบายปัจจุบันมากกว่าข้อเสนอแนะของมนุษย์เรียนรู้จากข้อเสนอแนะที่ขึ้นอยู่กับนโยบายที่มาบรรจบกัน
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl: การเรียนรู้การเสริมแรงของเครื่องยนต์ Volcano สำหรับ LLM
Seed Bytedance MLSYS ทีม & HKU: Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
คำหลัก: เฟรมเวิร์ก RLHF ที่ยืดหยุ่นมีประสิทธิภาพมีประสิทธิภาพ
งาน: RLHF, งานให้เหตุผลรวมถึงคณิตศาสตร์และรหัส
openrlhf
openrlhf
คำสำคัญ: 70b, RLHF, Deepspeed, Ray, Vllm
ภารกิจ: กรอบ RLHF ที่ใช้งานง่ายปรับขนาดได้
Palm + Rlhf - pytorch
Phil Wang, Yachine Zahidi, Ikko Eltociear Ashimine, Eric Alcaide
คำสำคัญ: หม้อแปลง, สถาปัตยกรรมปาล์ม
ชุดข้อมูล: Enwik8
LM-HUMAN-PREFERENCES
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
คำสำคัญ: รางวัลการเรียนรู้ภาษาสำหรับการดำเนินการต่อไปด้วยความเชื่อมั่นในเชิงบวกงานสรุปคำอธิบายทางกายภาพ
ชุดข้อมูล: TL; DR, CNN/DM
การแนะนำการแนะนำ-มนุษย์
Long Ouyang, Jeff Wu, Xu Jiang, et al.
คำสำคัญ: รูปแบบภาษาขนาดใหญ่จัดรูปแบบภาษาให้สอดคล้องกับความตั้งใจของมนุษย์
ชุดข้อมูล: TrustfulQa RealtoxicityPrompts
การเรียนรู้การเสริมแรงของหม้อแปลง (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall, et al.
คำสำคัญ: รถไฟ LLM ด้วย RL, PPO, Transformer
ภารกิจ: ความเชื่อมั่นของ IMDB
Transformer Sonforction Learning X (TRLX)
Jonathan Tow, Leandro von Werra และคณะ
คำสำคัญ: กรอบการฝึกอบรมแบบกระจาย, โมเดลภาษาที่ใช้ T5, รถไฟ LLM ด้วย RL, PPO, ILQL
ภารกิจ: การปรับแต่งอย่างละเอียด LLM กับ RL โดยใช้ฟังก์ชั่นรางวัลที่จัดเตรียมหรือชุดข้อมูลที่มีป้ายกำกับรางวัล
RL4LMS (ห้องสมุด RL แบบแยกส่วนเพื่อปรับแต่งแบบจำลองภาษาให้กับการตั้งค่าของมนุษย์)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
คำสำคัญ: การเพิ่มประสิทธิภาพเครื่องกำเนิดภาษาด้วย RL, เกณฑ์มาตรฐาน, อัลกอริทึม RL Performant
ชุดข้อมูล: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (en-de), NarrativeQa, DailyDialog
Lamda-Rlhf-Pytorch
ฟิลวัง
คำสำคัญ: Lamda, กลไกความสนใจ
ภารกิจ: การฝึกอบรมก่อนการฝึกอบรมโอเพ่นซอร์สของเอกสารการวิจัย Lamda ของ Google ใน Pytorch
textrl
Eric Lam
คำสำคัญ: หม้อแปลงของ HuggingFace
งาน: การสร้างข้อความ
env: pfrl, ยิม
minrlhf
Thomfoster
คำสำคัญ: PPO, ห้องสมุดขั้นต่ำ
งาน: วัตถุประสงค์ทางการศึกษา
deepspeed-chat
Microsoft
คำสำคัญ: การฝึกอบรม RLHF ราคาไม่แพง
Dromedary
IBM
คำสำคัญ: การกำกับดูแลของมนุษย์น้อยที่สุด
ภารกิจ: รูปแบบภาษาที่ได้รับการฝึกฝนด้วยตนเองที่ได้รับการฝึกฝนด้วยการกำกับดูแลของมนุษย์น้อยที่สุด
FG-RLHF
Zeqiu Wu, Yushi Hu, Weijia Shi, et al.
คำหลัก: RLHF ที่ละเอียดได้ดีซึ่งให้รางวัลหลังจากทุกส่วนโดยรวม RM หลายรายการที่เกี่ยวข้องกับประเภทข้อเสนอแนะที่แตกต่างกัน
ภารกิจ: เฟรมเวิร์กที่ช่วยให้การฝึกอบรมและการเรียนรู้จากฟังก์ชั่นรางวัลที่มีความหนาแน่นและ RMS-SAFE-RLHF หลายรายการ
Xuehai Pan, Ruiyang Sun, Jiaming Ji และคณะ
คำหลัก: รองรับโมเดลที่ได้รับการฝึกอบรมล่วงหน้ายอดนิยมชุดข้อมูลที่มีป้ายกำกับมนุษย์ขนาดใหญ่ตัวชี้วัดหลายระดับสำหรับการตรวจสอบข้อ จำกัด ด้านความปลอดภัยพารามิเตอร์ที่กำหนดเอง
ภารกิจ: LLM ที่สอดคล้องกับมูลค่าที่ จำกัด ผ่าน Safe RLHF
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
Ben Mann, Deep Ganguli
คำหลัก: ชุดข้อมูลการตั้งค่าของมนุษย์, ข้อมูลการเป็นทีมสีแดง, เขียนด้วยเครื่อง
ภารกิจ: ชุดข้อมูลโอเพนซอร์ซสำหรับข้อมูลการตั้งค่าของมนุษย์เกี่ยวกับความช่วยเหลือและความไม่เป็นอันตราย
ชุดข้อมูลการตั้งค่าของมนุษย์ Stanford (SHP)
Ethayarajh, Kawin และ Zhang, Heidi และ Wang, Yizhong และ Jurafsky, Dan
คำสำคัญ: ชุดข้อมูลที่เกิดขึ้นตามธรรมชาติและชุดข้อมูลที่เขียนโดยมนุษย์ 18 สาขาวิชาที่แตกต่างกัน
ภารกิจ: ตั้งใจที่จะใช้สำหรับการฝึกอบรมแบบจำลองรางวัล RLHF
Promptsource
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong และคณะ
คำหลัก: ชุดข้อมูลภาษาอังกฤษได้รับแจ้งการแมปตัวอย่างข้อมูลเป็นภาษาธรรมชาติ
งาน: Toolkit สำหรับการสร้างการแบ่งปันและการใช้พรอมต์ภาษาธรรมชาติ
คอลเล็กชั่นทรัพยากรความรู้พื้นฐานความรู้ (SKG)
Tianbao Xie, Chen Henry Wu, Peng Shi และคณะ
คำสำคัญ: การลงดินความรู้ที่มีโครงสร้าง
ภารกิจ: การรวบรวมชุดข้อมูลเกี่ยวข้องกับการต่อสายดินความรู้ที่มีโครงสร้าง
คอลเล็กชั่น Flan
Longpre Shayne, Hou le, Vu Tu และคณะ
ภารกิจ: คอลเลกชันรวบรวมชุดข้อมูลจาก FLAN 2021, P3, คำแนะนำสุดยอดธรรมชาติ
RLHF-DATASETS
yiting xie
คำหลัก: ชุดข้อมูลที่เขียนด้วยเครื่อง
webgpt_comparisons
Openai
คำสำคัญ: ชุดข้อมูลที่เขียนโดยมนุษย์, การตอบคำถามแบบฟอร์มยาว
ภารกิจ: ฝึกรูปแบบการตอบคำถามแบบฟอร์มยาวเพื่อให้สอดคล้องกับความชอบของมนุษย์
summarize_from_feedback
Openai
คำสำคัญ: ชุดข้อมูลที่เขียนโดยมนุษย์การสรุป
ภารกิจ: ฝึกอบรมแบบจำลองการสรุปเพื่อให้สอดคล้องกับความชอบของมนุษย์
Dahoas/Synthetic-Instruct-Gptj-Pairwise
Dahoas
คำสำคัญ: ชุดข้อมูลที่เขียนโดยมนุษย์ชุดข้อมูลสังเคราะห์
การจัดตำแหน่งที่มั่นคง - การจัดตำแหน่งการเรียนรู้ในเกมโซเชียล
Ruibo Liu, Ruixin (Ray) Yang, Qiang Peng
คำหลัก: ข้อมูลการโต้ตอบที่ใช้สำหรับการฝึกอบรมการจัดตำแหน่งทำงานใน Sandbox
งาน: ฝึกอบรมข้อมูลปฏิสัมพันธ์ที่บันทึกไว้ในเกมโซเชียลจำลอง
กรุงลิมา
Meta AI
คำสำคัญ: หากไม่มี RLHF ใด ๆ มีการแจ้งเตือนและการตอบกลับอย่างระมัดระวังเพียงเล็กน้อย
งาน: ชุดข้อมูลที่ใช้สำหรับการฝึกอบรมแบบจำลอง LIMA
[openai] chatgpt: การเพิ่มประสิทธิภาพแบบจำลองภาษาสำหรับบทสนทนา
[กอดใบหน้า] ภาพประกอบการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์ (RLHF)
[Zhihu] 通向 Agi 之路: 大型语言模型 (LLM) 技术精要
[Zhihu] 大语言模型的涌现能力: 现象与解释
[Zhihu] 中文 HH-RLHF 数据集上的 PPO 实践
[W&B เชื่อมต่ออย่างเต็มที่] การทำความเข้าใจการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์ (RLHF)
[DeepMind] การเรียนรู้ผ่านข้อเสนอแนะของมนุษย์
[ความคิด] 深入理解语言模型的突现能力
[ความคิด] 拆解追溯 GPT-3.5 各项能力的起源
[GIST] การเรียนรู้การเสริมแรงสำหรับแบบจำลองภาษา
[YouTube] John Schulman - การเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์: ความก้าวหน้าและความท้าทาย
[openai / arize] openai เกี่ยวกับการเรียนรู้การเสริมแรงด้วยความคิดเห็นของมนุษย์
[ENCORD] คู่มือการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์ (RLHF) สำหรับการมองเห็นคอมพิวเตอร์
[Weixun Wang] ภาพรวมของ RL (HF)+LLM
ตุรกี
จุดประสงค์ของเราคือทำให้ repo นี้ดียิ่งขึ้น หากคุณสนใจที่จะมีส่วนร่วมโปรดดูคำแนะนำในการบริจาคที่นี่
Awesome RLHF เปิดตัวภายใต้ใบอนุญาต Apache 2.0


