scratchplot story generation
1.0.0
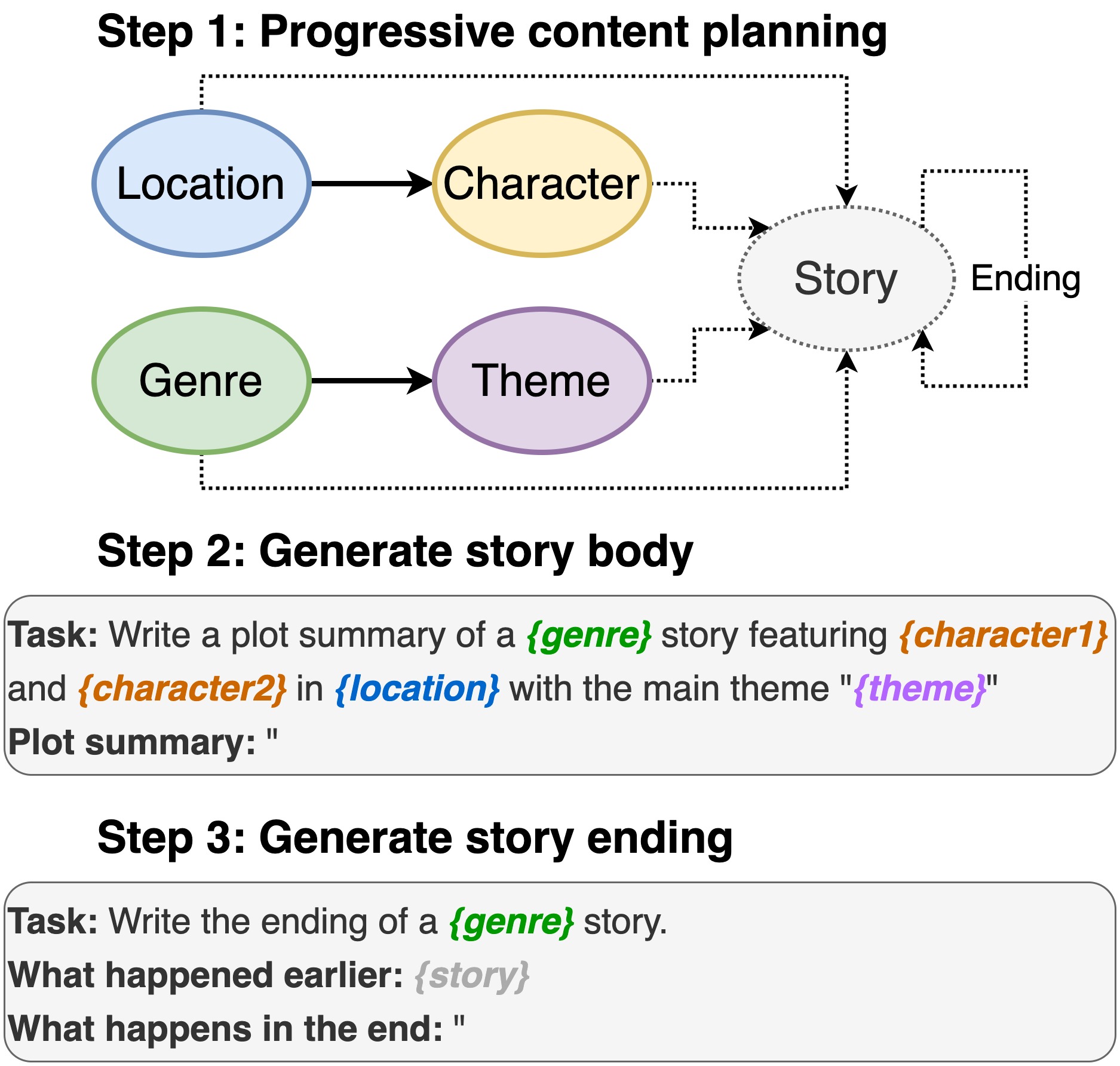
ที่เก็บนี้มีรหัสสำหรับ การเขียนพล็อตจากแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อน จะปรากฏใน INLG 2022 กระดาษแนะนำวิธีการที่จะแจ้ง PLM ก่อนเพื่อเขียนแผนเนื้อหา จากนั้นเราสร้างร่างกายของเรื่องราวและสิ้นสุดลงตามแผนเนื้อหา นอกจากนี้เราใช้วิธีการสร้างและจัดอันดับโดยใช้ PLM เพิ่มเติมเพื่อจัดอันดับคู่ที่สร้าง (จบลง)
repo นี้อาศัย Dino เป็นอย่างมาก เนื่องจากเราทำการเปลี่ยนแปลงเล็กน้อยเราจึงรวมรหัสที่สมบูรณ์เพื่อความสะดวกในการใช้งาน
รวมถึงสถานที่ตั้ง, cast, ประเภทและธีม
sh run_plot_static_gpu.shองค์ประกอบแผนเนื้อหาถูกสร้างขึ้นหนึ่งครั้งและจัดเก็บ เมื่อสร้างเรื่องราวตัวอย่างระบบจากองค์ประกอบพล็อตที่สร้างขึ้นแบบออฟไลน์
sh run_plot_dynamic_gpu_single.shsh run_plot_dynamic_gpu_batch.sh--no_cuda ไปยังคำสั่งทั้งหมดที่เรียกว่า dino.pyต้องใช้ Python3 ทดสอบใน Python 3.6 และ 3.8
pip3 install -r requirements.txt import nltk
nltk . download ( 'punkt' )
nltk . download ( 'stopwords' )หากคุณใช้รหัสในที่เก็บนี้โปรดอ้างอิงกระดาษต่อไปนี้:
@inproceedings{jin-le-2022-plot,
title = "Plot Writing From Pre-Trained Language Models",
author = "Jin, Yiping and Kadam, Vishakha and Wanvarie, Dittaya",
booktitle = "Proceedings of the 15th International Natural Language Generation conference",
year = "2022",
address = "Maine, USA",
publisher = "Association for Computational Linguistics"
}
หากคุณใช้ Dino สำหรับงานอื่น ๆ โปรดอ้างอิงกระดาษต่อไปนี้ด้วย:
@article{schick2020generating,
title={Generating Datasets with Pretrained Language Models},
author={Timo Schick and Hinrich Schütze},
journal={Computing Research Repository},
volume={arXiv:2104.07540},
url={https://arxiv.org/abs/2104.07540},
year={2021}
}


