paper2slides
1.0.0
แปลงเอกสาร arxiv ใด ๆ เป็นสไลด์โดยใช้แบบจำลองภาษาขนาดใหญ่ (LLMS)! เครื่องมือนี้มีประโยชน์สำหรับการเข้าใจแนวคิดหลักของงานวิจัยอย่างรวดเร็ว
ตัวอย่างบางส่วนของสไลด์ที่สร้างขึ้นคือ: Word2vec, Gan, Transformer, Vit, Chain-of-Though, Star, DPO และนักวิทยาศาสตร์ AI ดูตัวอย่างอื่น ๆ ของสไลด์ที่สร้างขึ้นในการสาธิต
สคริปต์จะดาวน์โหลดไฟล์จากอินเทอร์เน็ต (ARXIV) ส่งข้อมูลไปยัง OpenAI API และรวบรวมในเครื่อง โปรดระมัดระวังเกี่ยวกับเนื้อหาที่แบ่งปันและความเสี่ยงที่อาจเกิดขึ้น หากคุณมี arxiv ID เฉพาะที่คุณสนใจและไม่ต้องการเรียกใช้รหัสด้วยตัวเองโปรดแจ้งให้เราทราบใน "การสนทนา" และฉันยินดีที่จะเพิ่มสไลด์ลงในรายการสาธิต
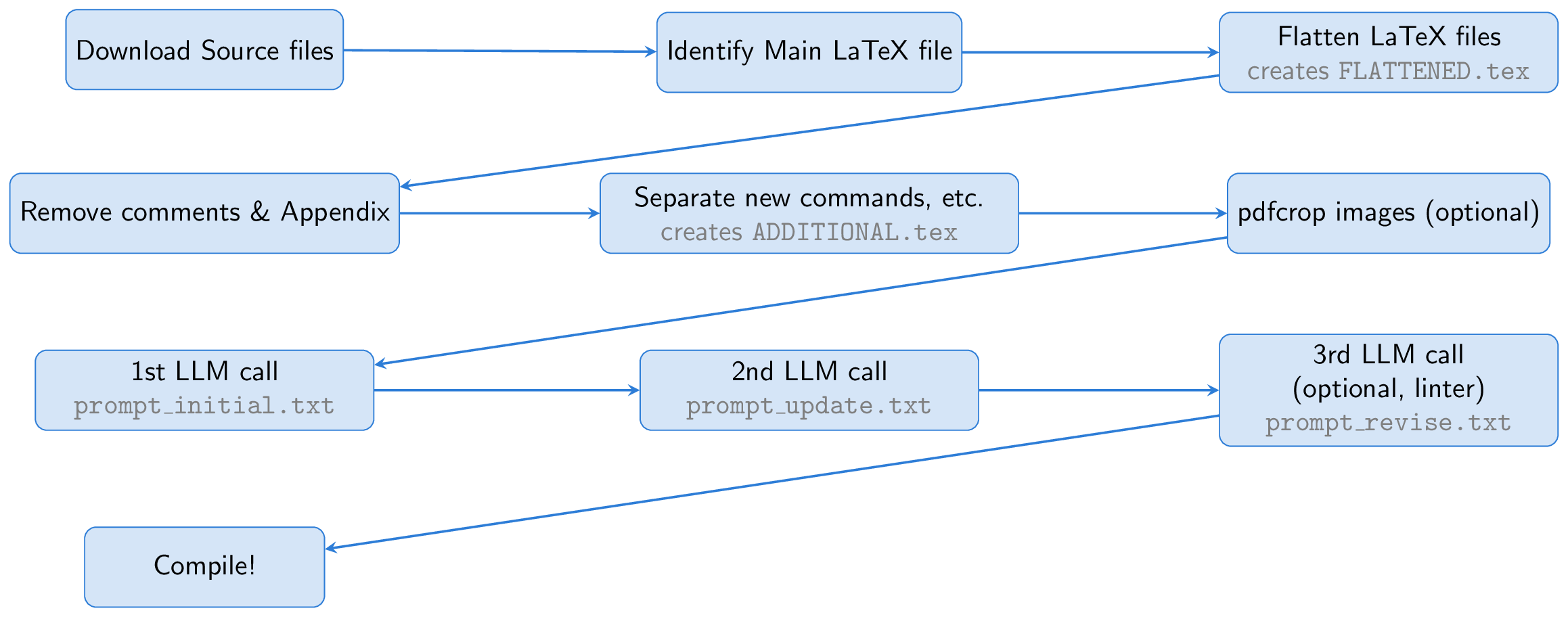
กระบวนการเริ่มต้นด้วยการดาวน์โหลดไฟล์ต้นฉบับของกระดาษ Arxiv ไฟล์ LaTex หลักจะถูกระบุและแบนโดยรวมไฟล์อินพุตทั้งหมดเข้ากับเอกสารเดียว ( FLATTENED.tex ) เราประมวลผลไฟล์ที่ผสานนี้ล่วงหน้าโดยการลบความคิดเห็นและภาคผนวก ไฟล์ที่ประมวลผลล่วงหน้านี้พร้อมกับคำแนะนำในการสร้างสไลด์ที่ดีเป็นพื้นฐานของพรอมต์ของเรา
แนวคิดสำคัญอย่างหนึ่งคือการใช้ Beamer สำหรับการสร้างสไลด์ทำให้เราสามารถอยู่ในระบบนิเวศน้ำยางได้ทั้งหมด วิธีการนี้จะเปลี่ยนงานเป็นแบบฝึกหัดสรุป: การแปลงกระดาษยางยาวเป็นน้ำยางที่รัดกุม LLM สามารถอนุมานเนื้อหาของตัวเลขจากคำบรรยายภาพและรวมไว้ในสไลด์ไม่จำเป็นต้องใช้ความสามารถในการมองเห็น
เพื่อช่วยเหลือ LLM เราสร้างไฟล์ที่เรียกว่า ADDITIONAL.tex ซึ่งมีแพ็คเกจที่จำเป็นทั้งหมดคำจำกัดความ NewCommand และการตั้งค่า LATEX อื่น ๆ ที่ใช้ในกระดาษ การรวมไฟล์นี้ด้วย input{ADDITIONAL.tex} ในพรอมต์จะสั้นลงและทำให้การสร้างสไลด์มีความน่าเชื่อถือมากขึ้นโดยเฉพาะอย่างยิ่งสำหรับเอกสารทางทฤษฎีที่มีคำสั่งที่กำหนดเองมากมาย
LLM สร้างรหัสบีมเมอร์จากแหล่งน้ำยาง แต่เนื่องจากการวิ่งครั้งแรกอาจมีปัญหาเราขอให้ LLM ตรวจสอบตนเองและปรับแต่งผลลัพธ์ ทางเลือกขั้นตอนที่สามเกี่ยวข้องกับการใช้ linter เพื่อตรวจสอบรหัสที่สร้างขึ้นพร้อมกับผลลัพธ์ที่ป้อนกลับไปยัง LLM สำหรับการแก้ไขเพิ่มเติม (ขั้นตอน linter นี้ได้รับแรงบันดาลใจจากนักวิทยาศาสตร์ AI) ในที่สุดรหัสบีมเมอร์จะถูกรวบรวมไว้ในงานนำเสนอ PDF โดยใช้ PDFLATEX
สคริปต์ all.zsh ทำให้กระบวนการทั้งหมดทำงานโดยอัตโนมัติโดยทั่วไปจะเสร็จสิ้นในเวลาน้อยกว่าสองสามนาทีด้วย GPT-4O สำหรับกระดาษแผ่นเดียว
ข้อกำหนดคือ:
requests ห้องสมุดarxivopenai Libraryarxiv-latex-cleaner librarypdflatex ที่ใช้งานได้ขั้นตอนสำหรับการติดตั้ง:
โคลนที่เก็บนี้:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slidesติดตั้งแพ็คเกจ Python ที่ต้องการ:
pip install requests arxiv openai arxiv-latex-cleaner pdflatex ให้แน่ใจว่ามีการติดตั้งและมีอยู่ในเส้นทางของระบบของคุณ เลือกตรวจสอบว่าคุณสามารถรวบรวมตัวอย่าง test.tex โดย pdflatex test.tex ตรวจสอบว่า test.pdf ถูกสร้างขึ้นอย่างถูกต้องหรือไม่ เลือกตรวจสอบ chktex และ pdfcrop ทำงานอยู่
ตั้งค่าคีย์ OpenAI API ของคุณ:
export OPENAI_API_KEY= ' your-api-key ' all.shสคริปต์นี้ทำให้กระบวนการดาวน์โหลดกระดาษอาร์กซิฟประมวลผลโดยอัตโนมัติและแปลงเป็นงานนำเสนอ Beamer
bash all.sh < arxiv_id > แทนที่ <arxiv_id> ด้วยรหัสกระดาษ ArxIV ที่ต้องการ ID สามารถระบุได้จาก URL: ID สำหรับ https://arxiv.org/abs/xxxx.xxxx คือ xxxx.xxxx
คุณยังสามารถเรียกใช้สคริปต์ Python เป็นรายบุคคลเพื่อควบคุมเพิ่มเติม
ดาวน์โหลดและประมวลผลไฟล์ต้นฉบับ arxiv
python arxiv2tex.py < arxiv_id > สคริปต์นี้ดาวน์โหลดไฟล์ต้นฉบับของกระดาษ Arxiv ที่ระบุแยกออกและประมวลผลไฟล์ LaTex หลัก ผลลัพธ์จะถูกบันทึกไว้ใน source/<arxiv_id>/FLATTENED.tex และ source/<arxiv_id>/ADDITIONAL.tex
แปลงน้ำยางเป็น Beamer
python tex2beamer.py --arxiv_id < arxiv_id > สคริปต์นี้อ่านไฟล์ LaTex ที่ประมวลผลและเตรียมสไลด์บีมเมอร์ นี่คือที่ที่เราใช้ OpenAI API เราโทรสองครั้งก่อนเพื่อสร้างรหัสบีมเมอร์จากนั้นตรวจสอบรหัสบีมเมอร์ด้วยตนเอง เลือกใช้ธงต่อไปนี้: --use_linter และ --use_pdfcrop พรอมต์ที่ส่งไปยัง LLM และการตอบสนองจาก LLM จะถูกบันทึกไว้ใน tex2beamer.log บันทึก linter จะถูกบันทึกใน source/<arxiv_id>/linter.log
แปลง Beamer เป็น PDF
python beamer2pdf.py < arxiv_id >สคริปต์นี้รวบรวมไฟล์ Beamer ลงในงานนำเสนอ PDF
พรอมต์จะถูกบันทึกไว้ใน prompt_initial.txt , prompt_update.txt และ prompt_revise.txt แต่อย่าลังเลที่จะปรับตามความต้องการของคุณ พวกเขามีตัวยึดตำแหน่งที่เรียกว่า PLACEHOLDER_FOR_FIGURE_PATHS สิ่งนี้จะถูกแทนที่ด้วยเส้นทางรูปที่ใช้ในกระดาษ เราต้องการให้แน่ใจว่าเส้นทางนั้นใช้อย่างถูกต้องในรหัสบีมเมอร์ LLM มักจะทำผิดพลาดดังนั้นเราจึงรวมสิ่งนี้ไว้ในพรอมต์อย่างชัดเจน
อัตราความสำเร็จอยู่ที่ประมาณ 90 เปอร์เซ็นต์ในประสบการณ์ของฉัน (การรวบรวมอาจล้มเหลวหรือเส้นทางภาพอาจผิดในบางกรณี) หากคุณพบปัญหาใด ๆ หรือมีข้อเสนอแนะสำหรับการปรับปรุงโปรดแจ้งให้เราทราบ!


