text embeddings inference
v1.5.1
โซลูชันการอนุมานที่รวดเร็วสำหรับรุ่น Embeddings ข้อความ
เกณฑ์มาตรฐานสำหรับ BAAI/BGE-BASE-V1.5 บน NVIDIA A10 ที่มีความยาวลำดับ 512 โทเค็น:
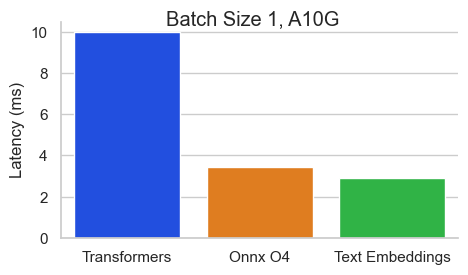
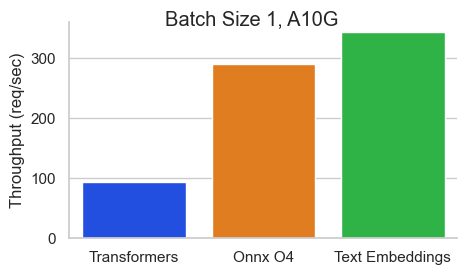
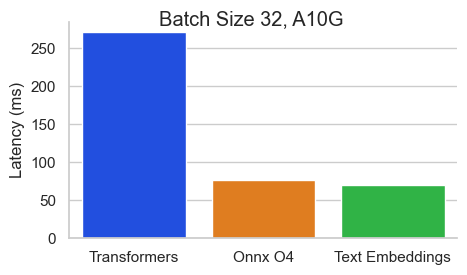
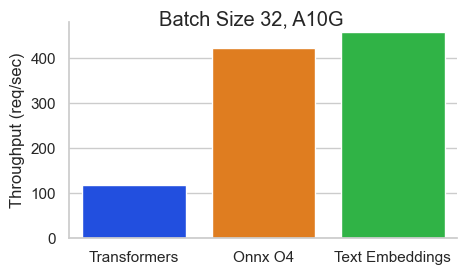
Text Embeddings Inference (TEI) เป็นชุดเครื่องมือสำหรับการปรับใช้และให้บริการแบบฝังตัวข้อความโอเพ่นซอร์สและแบบจำลองการจำแนกลำดับ TEI ช่วยให้การสกัดประสิทธิภาพสูงสำหรับรุ่นที่ได้รับความนิยมมากที่สุดรวมถึง Flagembedding, Ember, GTE และ E5 TEI ใช้คุณสมบัติมากมายเช่น:
การอนุมานการฝังตัวในปัจจุบันรองรับ Nomic, Bert, Camembert, รุ่น XLM-Roberta ที่มีตำแหน่งสัมบูรณ์, โมเดล Jinabert ที่มีตำแหน่ง Alibi และ Mistral, Alibaba GTE และ QWEN2 รุ่นที่มีตำแหน่งเชือก
ด้านล่างนี้เป็นตัวอย่างของโมเดลที่รองรับในปัจจุบัน:
| อันดับ MTEB | ขนาดรุ่น | ประเภทรุ่น | ID รุ่น |
|---|---|---|---|
| 1 | 7b (แพงมาก) | ผิดพลาด | Salesforce/SFR-embedding-2_R |
| 2 | 7b (แพงมาก) | Qwen2 | Alibaba-NLP/GTE-QWEN2-7B-Instruct |
| 9 | 1.5B (แพง) | Qwen2 | Alibaba-NLP/GTE-QWEN2-1.5B-Instruct |
| 15 | 0.4B | อาลีบาบา GTE | Alibaba-NLP/GTE-LARGE-EN-V1.5 |
| 20 | 0.3b | เบิร์ต | Whereisai/UAE-Large-V1 |
| 24 | 0.5b | XLM-Roberta | Intfloat/MultilingUad-E5-Large-Instruct |
| N/A | 0.1b | ผู้มีชื่อเสียง | Nomic-AI/NOMIC-EMBED-TEXT-V1 |
| N/A | 0.1b | ผู้มีชื่อเสียง | Nomic-AI/NOMIC-EMBED-TEXT-V1.5 |
| N/A | 0.1b | นักบวช | jinaai/jina-embeddings-v2-base-en |
| N/A | 0.1b | นักบวช | jinaai/jina-embeddings-v2-base-code |
หากต้องการสำรวจรายการของรุ่น Embeddings ที่มีประสิทธิภาพดีที่สุดให้ไปที่บอร์ดลีดเดอร์บอร์ด Embedding Benchmark (MTEB) ขนาดใหญ่
การอนุมานการฝังข้อความในปัจจุบันรองรับโมเดลการจำแนกลำดับ Camembert และ XLM-Roberta Sequence ที่มีตำแหน่งสัมบูรณ์
ด้านล่างนี้เป็นตัวอย่างของโมเดลที่รองรับในปัจจุบัน:
| งาน | ประเภทรุ่น | ID รุ่น |
|---|---|---|
| จัดอันดับใหม่ | XLM-Roberta | BAAI/BGE-RERANKER-LARGE |
| จัดอันดับใหม่ | XLM-Roberta | BAAI/BGE-RERANKER-BASE |
| จัดอันดับใหม่ | GTE | Alibaba-NLP/GTE-MULTILINGUAD-RERANKER-BASE |
| การวิเคราะห์ความเชื่อมั่น | โรเบอร์ต้า | Samlowe/Roberta-Base-Go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelจากนั้นคุณสามารถร้องขอได้เช่น
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json 'หมายเหตุ: ในการใช้ GPU คุณต้องติดตั้งชุดเครื่องมือคอนเทนเนอร์ NVIDIA ไดรเวอร์ Nvidia บนเครื่องของคุณจะต้องเข้ากันได้กับ CUDA เวอร์ชัน 12.2 หรือสูงกว่า
หากต้องการดูตัวเลือกทั้งหมดเพื่อให้บริการแบบจำลองของคุณ:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
การอนุมานการฝังตัวของข้อความจัดส่งด้วยรูปภาพ Docker หลายภาพที่คุณสามารถใช้เพื่อกำหนดเป้าหมายแบ็กเอนด์ที่เฉพาะเจาะจง:
| สถาปัตยกรรม | ภาพ |
|---|---|
| ซีพียู | ghcr.io/huggingface/text-embeddings-inference:cpu-1.5 |
| Volta | ไม่รองรับ |
| Turing (T4, RTX 2000 Series, ... ) | ghcr.io/huggingface/text-embeddings-inference:turing-1.5 (ทดลอง) |
| Ampere 80 (A100, A30) | ghcr.io/huggingface/text-embeddings-inference:1.5 |
| Ampere 86 (A10, A40, ... ) | ghcr.io/huggingface/text-embeddings-inference:86-1.5 |
| Ada Lovelace (RTX 4000 Series, ... ) | ghcr.io/huggingface/text-embeddings-inference:89-1.5 |
| Hopper (H100) | ghcr.io/huggingface/text-embeddings-inference:hopper-1.5 (ทดลอง) |
คำเตือน : ความสนใจของแฟลชถูกปิดโดยค่าเริ่มต้นสำหรับภาพทัวริงเนื่องจากมันทนทุกข์ทรมานจากปัญหาความแม่นยำ คุณสามารถเปิด Flash Attention V1 ได้โดยใช้ USE_FLASH_ATTENTION=True
คุณสามารถปรึกษาเอกสาร OpenAPI ของ text-embeddings-inference REST API โดยใช้เส้นทาง /docs UI Swagger ยังมีอยู่ที่: https://huggingface.github.io/text-embeddings-inference
คุณมีตัวเลือกในการใช้ประโยชน์จากตัวแปรสภาพแวดล้อม HF_API_TOKEN สำหรับการกำหนดค่าโทเค็นที่ใช้โดยการใช้ text-embeddings-inference สิ่งนี้ช่วยให้คุณสามารถเข้าถึงทรัพยากรที่ได้รับการป้องกัน
ตัวอย่างเช่น:
HF_API_TOKEN=<your cli READ token>หรือกับนักเทียบท่า:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelในการปรับใช้การอนุมานการฝังข้อความในสภาพแวดล้อมที่มีอากาศที่มีอากาศให้ดาวน์โหลดน้ำหนักก่อนแล้วติดตั้งไว้ในภาชนะโดยใช้ระดับเสียง
ตัวอย่างเช่น:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5 text-embeddings-inference v0.4.0 เพิ่มการสนับสนุนสำหรับ Camembert, Roberta, XLM-Roberta และ GTE Sequence Models โมเดล Rankers อีกครั้งคือโมเดลการจำแนกประเภทการจำแนกแบบ Cross-Encoders ที่มีคลาสเดียวที่ให้คะแนนความคล้ายคลึงกันระหว่างการสืบค้นและข้อความ
ดู BlogPost นี้โดยทีม Llamaidex เพื่อทำความเข้าใจว่าคุณสามารถใช้โมเดล Rankers อีกครั้งในท่อส่ง RAG ของคุณเพื่อปรับปรุงประสิทธิภาพการทำงานของปลายน้ำ
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelจากนั้นคุณสามารถจัดอันดับความคล้ายคลึงกันระหว่างการสืบค้นและรายการข้อความด้วย:
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json ' นอกจากนี้คุณยังสามารถใช้แบบจำลองการจำแนกลำดับคลาสสิกเช่น SamLowe/roberta-base-go_emotions :
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model เมื่อคุณปรับใช้โมเดลแล้วคุณสามารถใช้จุดสิ้นสุดที่ predict เพื่อให้ได้อารมณ์ที่เกี่ยวข้องกับอินพุตมากที่สุด:
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'คุณสามารถเลือกที่จะเปิดใช้งาน Splade Pooling สำหรับสถาปัตยกรรม Bert และ Distilbert Maskedlm:
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade เมื่อคุณปรับใช้โมเดลแล้วคุณสามารถใช้จุดสิ้นสุด /embed_sparse เพื่อรับการฝังแบบเบาบาง:
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json ' text-embeddings-inference เป็นเครื่องมือที่มีการติดตามแบบกระจายโดยใช้ opentelemetry คุณสามารถใช้คุณสมบัตินี้ได้โดยการตั้งค่าที่อยู่เป็นตัวรวบรวม OTLP ด้วยอาร์กิวเมนต์ --otlp-endpoint
text-embeddings-inference เสนอ GRPC API เป็นทางเลือกสำหรับ HTTP API เริ่มต้นสำหรับการปรับใช้ประสิทธิภาพสูง คำจำกัดความของ API Protobuf สามารถพบได้ที่นี่
คุณสามารถใช้ GRPC API ได้โดยเพิ่มแท็ก -grpc ลงในภาพ TEI Docker ใด ๆ ตัวอย่างเช่น:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed นอกจากนี้คุณยังสามารถเลือกที่จะติดตั้ง text-embeddings-inference กันในเครื่อง
การติดตั้งครั้งแรก Rust:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | shจากนั้นเรียกใช้:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metalตอนนี้คุณสามารถเปิดการอนุมานการฝังข้อความบน CPU ด้วย:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080หมายเหตุ: ในบางเครื่องคุณอาจต้องใช้ไลบรารี OpenSSL และ GCC บนเครื่อง Linux Run:
sudo apt-get install libssl-dev gcc -yGPUs พร้อมความสามารถในการคำนวณ CUDA <7.5 ไม่รองรับ (V100, Titan V, GTX 1000 Series, ... )
ตรวจสอบให้แน่ใจว่าคุณติดตั้งไดรเวอร์ Cuda และ Nvidia แล้ว ไดรเวอร์ NVIDIA บนอุปกรณ์ของคุณจะต้องเข้ากันได้กับ CUDA เวอร์ชัน 12.2 หรือสูงกว่า คุณต้องเพิ่ม Nvidia Binaries ลงในเส้นทางของคุณ:
export PATH= $PATH :/usr/local/cuda/binจากนั้นเรียกใช้:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-featuresตอนนี้คุณสามารถเปิดการอนุมานการฝังข้อความบน GPU ด้วย:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080คุณสามารถสร้างคอนเทนเนอร์ CPU ด้วย:
docker build .ในการสร้างคอนเทนเนอร์ CUDA คุณต้องทราบฝาปิดคำนวณของ GPU ที่คุณจะใช้เมื่อรันไทม์
จากนั้นคุณสามารถสร้างคอนเทนเนอร์ด้วย:
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_capตามที่อธิบายไว้ที่นี่พร้อม MPS-arm64 Docker Image, Metal / MPS ไม่ได้รับการสนับสนุนผ่าน Docker การอนุมานเช่นนี้จะถูกผูกมัด CPU และน่าจะค่อนข้างช้าเมื่อใช้ภาพนักเทียบท่านี้บน CPU แขน M1/M2
docker build . -f Dockerfile --platform=linux/arm64


