pytorch openai transformer lm
1.0.0
นี่คือการใช้งาน Pytorch ของรหัส Tensorflow ที่มาพร้อมกับกระดาษของ Openai "ปรับปรุงความเข้าใจภาษาโดยการฝึกอบรมก่อนการกำเนิด" โดย Alec Radford, Karthik Narasimhan, Tim Salimans และ Ilya Sutskever
การใช้งานนี้ประกอบด้วย สคริปต์เพื่อโหลดในโมเดล Pytorch น้ำหนักที่ได้รับการฝึกฝนไว้ล่วงหน้าโดยผู้เขียน ด้วยการใช้งาน TensorFlow
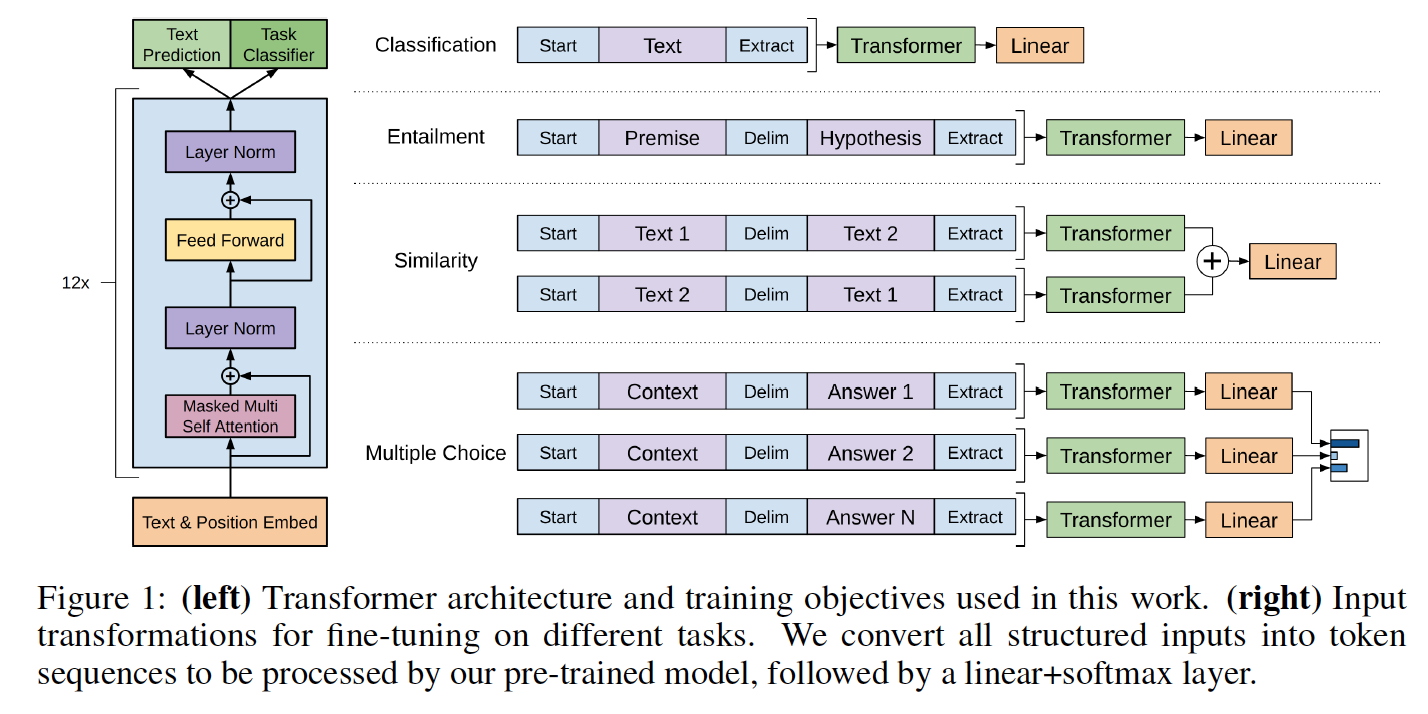
คลาสโมเดลและสคริปต์การโหลดอยู่ใน model_pytorch.py
ชื่อของโมดูลในโมเดล pytorch จะติดตามชื่อของตัวแปรในการใช้งาน tensorflow การใช้งานนี้พยายามที่จะติดตามรหัสดั้งเดิมอย่างใกล้ชิดที่สุดเพื่อลดความคลาดเคลื่อน
การใช้งานนี้ยังประกอบด้วยอัลกอริทึมการปรับให้เหมาะสมของ ADAM ที่แก้ไขแล้วตามที่ใช้ในกระดาษของ OpenAI ด้วย:
ในการใช้แบบจำลองด้วยตนเองโดยการนำเข้า model_pytorch.py คุณเพียงแค่ต้องการ:
ในการเรียกใช้สคริปต์การฝึกอบรมตัวจําแนกใน Train.py คุณจะต้องมีนอกจากนี้:
คุณสามารถดาวน์โหลดน้ำหนักของเวอร์ชันที่ได้รับการฝึกอบรมล่วงหน้าของ OpenAI ได้โดยการโคลนนิ่ง repo ของ Alec Radford และวางโฟลเดอร์ model ที่มีน้ำหนักที่ได้รับการฝึกอบรมไว้ล่วงหน้าใน repo ปัจจุบัน
โมเดลสามารถใช้เป็นแบบจำลองภาษาหม้อแปลงที่มีน้ำหนักได้รับการฝึกอบรมล่วงหน้าของ OpenAI ดังนี้:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) รุ่นนี้สร้างสถานะที่ซ่อนอยู่ของหม้อแปลง คุณสามารถใช้คลาส LMHead ใน model_pytorch.py เพื่อเพิ่มตัวถอดรหัสที่ผูกกับน้ำหนักของตัวเข้ารหัสและรับแบบจำลองภาษาเต็ม นอกจากนี้คุณยังสามารถใช้คลาส ClfHead ใน model_pytorch.py เพื่อเพิ่มตัวจําแนกที่ด้านบนของหม้อแปลงและรับตัวจําแนกตามที่อธิบายไว้ในสิ่งพิมพ์ของ OpenAi (ดูตัวอย่างของทั้งคู่ในฟังก์ชัน __main__ ของ Train.py)
ในการใช้ตัวเข้ารหัสตำแหน่งของหม้อแปลงคุณควรเข้ารหัสชุดข้อมูลของคุณโดยใช้ฟังก์ชัน encode_dataset() ของ utils.py โปรดดูที่จุดเริ่มต้นของฟังก์ชั่น __main__ ใน Train.py เพื่อดูวิธีการกำหนดคำศัพท์และเข้ารหัสชุดข้อมูลของคุณอย่างถูกต้อง
รุ่นนี้ยังสามารถรวมเข้ากับตัวจําแนกตามรายละเอียดในกระดาษของ Openai ตัวอย่างของการปรับแต่งอย่างละเอียดเกี่ยวกับงาน rocstories cloze นั้นรวมอยู่ในรหัสการฝึกอบรมใน Train.py
ชุดข้อมูล Rocstories สามารถดาวน์โหลดได้จากเว็บไซต์ที่เกี่ยวข้อง
เช่นเดียวกับรหัส tensorflow รหัสนี้ใช้ผลการทดสอบ rocstories cloze ที่รายงานในกระดาษซึ่งสามารถทำซ้ำได้โดยการวิ่ง:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]Finetuning รุ่น Pytorch สำหรับ 3 Epochs บน rocstories ใช้เวลา 10 นาทีในการทำงานบน Nvidia K-80
ความแม่นยำในการทดสอบการเรียกใช้ครั้งเดียวของรุ่น pytorch นี้คือ 85.84%ในขณะที่ผู้เขียนรายงานความแม่นยำเฉลี่ยด้วยรหัส Tensorflow 85.8%และกระดาษรายงานความแม่นยำในการวิ่งเดี่ยวที่ดีที่สุด 86.5%
การใช้งานผู้เขียนใช้ 8 GPU และสามารถรองรับชุดตัวอย่าง 64 ชุดได้ในขณะที่การใช้งานปัจจุบันเป็น GPU เดี่ยวและมีผล จำกัด อยู่ที่ 20 อินสแตนซ์ของ K80 ด้วยเหตุผลหน่วยความจำ ในการทดสอบของเราการเพิ่มขนาดแบทช์จาก 8 ถึง 20 ตัวอย่างเพิ่มความแม่นยำในการทดสอบ 2.5 คะแนน อาจได้รับความแม่นยำที่ดีขึ้นโดยใช้การตั้งค่า multi-GPU (ยังไม่ได้ลอง)
SOTA ก่อนหน้านี้ในชุดข้อมูล Rocstories คือ 77.6% ("Hidden Coherence Model" ของ Chaturvedi และคณะที่เผยแพร่ใน "ความเข้าใจในเรื่องราวสำหรับการทำนายว่าเกิดอะไรขึ้นต่อไป" EMNLP 2017 ซึ่งเป็นกระดาษที่ดีมากเช่นกัน!)


