rag experiment accelerator
1.0.0
ตัวเร่งการทดลอง RAG เป็นเครื่องมือที่หลากหลายที่ช่วยให้คุณทำการทดลองและการประเมินผลโดยใช้รูปแบบการค้นหา Azure AI และ RAG เอกสารนี้ให้คำแนะนำที่ครอบคลุมซึ่งครอบคลุมทุกสิ่งที่คุณจำเป็นต้องรู้เกี่ยวกับเครื่องมือนี้เช่นวัตถุประสงค์คุณสมบัติการติดตั้งการใช้งานและอื่น ๆ
เป้าหมายหลักของ ตัวเร่งการทดลอง RAG คือการทำให้ง่ายขึ้นและเร็วขึ้นในการทดลองและการประเมินผลการค้นหาและคุณภาพของการตอบสนองจาก OpenAI เครื่องมือนี้มีประโยชน์สำหรับนักวิจัยนักวิทยาศาสตร์ด้านข้อมูลและนักพัฒนาที่ต้องการ:
18 มีนาคม 2567: เพิ่มการสุ่มตัวอย่างเนื้อหา ฟังก์ชั่นนี้จะช่วยให้ชุดข้อมูลได้รับการสุ่มตัวอย่างโดยเปอร์เซ็นต์ที่ระบุ ข้อมูลจะถูกจัดกลุ่มตามเนื้อหาจากนั้นเปอร์เซ็นต์ตัวอย่างจะถูกนำไปใช้ในแต่ละคลัสเตอร์เพื่อพยายามกระจายข้อมูลตัวอย่าง
สิ่งนี้ทำเพื่อให้แน่ใจว่าตัวแทนผลลัพธ์ในตัวอย่างที่จะได้รับผ่านชุดข้อมูลทั้งหมด
หมายเหตุ : ขอแนะนำให้สร้างสภาพแวดล้อมของคุณใหม่หากคุณเคยใช้เครื่องมือนี้มาก่อนเนื่องจากการพึ่งพาใหม่
ตัวเร่งความเร็วการทดลอง RAG เป็นตัวขับเคลื่อนการกำหนดค่าและนำเสนอชุดคุณสมบัติที่หลากหลายเพื่อรองรับวัตถุประสงค์:
การตั้งค่าการทดลอง : คุณสามารถกำหนดและกำหนดค่าการทดลองโดยการระบุช่วงของพารามิเตอร์ของเครื่องมือค้นหาประเภทการค้นหาชุดคิวรีและตัวชี้วัดการประเมินผล
การบูรณาการ : มันรวมเข้ากับ Azure AI Search, Azure Machine Learning, MLFlow และ Azure Openai
Rich Search Index : สร้างดัชนีการค้นหาหลายอย่างตามการกำหนดค่าไฮเปอร์พารามิเตอร์ที่มีอยู่ในไฟล์กำหนดค่า
ตัวโหลดเอกสารหลายรายการ : เครื่องมือรองรับตัวโหลดเอกสารหลายรายการรวมถึงการโหลดผ่าน Azure Document Intelligence และ Langchain Loaders พื้นฐาน สิ่งนี้จะช่วยให้คุณมีความยืดหยุ่นในการทดสอบด้วยวิธีการสกัดที่แตกต่างกันและประเมินประสิทธิภาพของพวกเขา
Document Intelligence Loader : เมื่อเลือกโมเดล API 'prebuilt-Layout' สำหรับ Document Intelligence เครื่องมือจะใช้ตัวโหลดความฉลาดของเอกสารที่กำหนดเองเพื่อโหลดข้อมูล ตัวโหลดที่กำหนดเองนี้รองรับการจัดรูปแบบของตารางที่มีส่วนหัวคอลัมน์เป็นคู่คีย์-ค่า (เพื่อเพิ่มความสามารถในการอ่านสำหรับ LLM) ไม่รวมส่วนที่ไม่เกี่ยวข้องของไฟล์สำหรับ LLM (เช่นหมายเลขหน้าและส่วนท้าย) ลบรูปแบบที่เกิดขึ้นซ้ำในไฟล์โดยใช้ Regex และอื่น ๆ เนื่องจากแต่ละแถวตารางจะถูกแปลงเป็นบรรทัดข้อความเพื่อหลีกเลี่ยงการทำลายแถวตรงกลาง chunking จะทำซ้ำตามวรรคและบรรทัด ตัวโหลดที่กำหนดเองรีสอร์ทไปยังโมเดล API 'prebuilt-layout' ที่ง่ายขึ้นเป็นทางเลือกเมื่อ 'prebuilt-layout' ล้มเหลว รูปแบบ API อื่น ๆ จะใช้ประโยชน์จากการใช้งานของ Langchain ซึ่งส่งคืนการตอบสนองแบบดิบจาก API ของ Document Intelligence
การสร้างแบบสอบถาม : เครื่องมือสามารถสร้างชุดคิวรีที่หลากหลายและปรับแต่งได้หลากหลายซึ่งสามารถปรับให้เหมาะกับความต้องการการทดลองที่เฉพาะเจาะจง
การค้นหาหลายประเภท : รองรับการค้นหาหลายประเภทรวมถึงข้อความบริสุทธิ์, เวกเตอร์บริสุทธิ์, cross-vector, multi-vector, ลูกผสมและอื่น ๆ สิ่งนี้จะช่วยให้คุณสามารถทำการวิเคราะห์ที่ครอบคลุมเกี่ยวกับความสามารถในการค้นหาและผลลัพธ์
การตั้งคำถามย่อย : รูปแบบจะประเมินแบบสอบถามของผู้ใช้และหากพบว่ามันซับซ้อนพอมันจะแบ่งมันออกเป็นส่วนย่อยที่เล็กลงเพื่อสร้างบริบทที่เกี่ยวข้อง
การจัดอันดับใหม่ : การตอบคำถามจากการค้นหา Azure AI ได้รับการประเมินอีกครั้งโดยใช้ LLM และจัดอันดับตามความเกี่ยวข้องระหว่างการสืบค้นและบริบท
ตัวชี้วัดและการประเมินผล : รองรับการวัดแบบ end-to-end เปรียบเทียบคำตอบที่สร้างขึ้น (จริง) กับคำตอบความจริงพื้นดิน (คาดว่า) รวมถึงการวัดระยะทางตามระยะทางโคไซน์และความหมายที่คล้ายคลึงกัน นอกจากนี้ยังรวมถึงตัวชี้วัดที่ใช้องค์ประกอบเพื่อประเมินประสิทธิภาพการดึงและการสร้างโดยใช้ LLMS เป็นผู้พิพากษาเช่นการเรียกคืนบริบทหรือความเกี่ยวข้องกับคำตอบรวมถึงตัวชี้วัดการดึงข้อมูลเพื่อประเมินผลการค้นหา (เช่น MAP@K)
การสร้างรายงาน : ตัวเร่งความเร็วการทดลอง RAG ทำให้กระบวนการสร้างรายงานพร้อมด้วยการสร้างภาพข้อมูลที่ทำให้ง่ายต่อการวิเคราะห์และแบ่งปันผลการทดลอง
หลายภาษา : เครื่องมือสนับสนุนเครื่องวิเคราะห์ภาษาสำหรับการสนับสนุนทางภาษาในแต่ละภาษาและเครื่องวิเคราะห์พิเศษ (ภาษา-ไม่เชื่อเรื่องพระเจ้า) สำหรับรูปแบบที่ผู้ใช้กำหนดไว้ในดัชนีการค้นหา สำหรับข้อมูลเพิ่มเติมดูประเภทของเครื่องวิเคราะห์
การสุ่มตัวอย่าง : หากคุณมีชุดข้อมูลขนาดใหญ่และ/หรือต้องการเพิ่มความเร็วในการทดลองกระบวนการสุ่มตัวอย่างจะสามารถสร้างตัวอย่างขนาดเล็ก แต่เป็นตัวแทนของข้อมูลสำหรับเปอร์เซ็นต์ที่ระบุ ข้อมูลจะถูกจัดกลุ่มตามเนื้อหาและเปอร์เซ็นต์ของแต่ละคลัสเตอร์จะถูกเลือกเป็นส่วนหนึ่งของตัวอย่าง ผลลัพธ์ที่ได้รับควรบ่งบอกถึงชุดข้อมูลเต็มรูปแบบภายในระยะขอบ ~ 10% เมื่อมีการระบุวิธีการแล้วให้เรียกใช้ชุดข้อมูลเต็มรูปแบบเพื่อให้ได้ผลลัพธ์ที่แม่นยำ
ในขณะนี้ตัวเร่งความเร็วการทดลอง RAG สามารถใช้งานได้ในท้องถิ่นซึ่งใช้ประโยชน์จากหนึ่งในสิ่งต่อไปนี้:
การใช้คอนเทนเนอร์การพัฒนาจะหมายความว่าซอฟต์แวร์ที่จำเป็นทั้งหมดจะถูกติดตั้งสำหรับคุณ สิ่งนี้จะต้องใช้ WSL สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการพัฒนาคอนเทนเนอร์เยี่ยมชม containers.dev
ติดตั้งซอฟต์แวร์ต่อไปนี้บนเครื่องโฮสต์คุณจะทำการปรับใช้จาก:
- สำหรับ Windows - Windows Store Ubuntu 22.04.3 LTS
- Docker Desktop
- รหัสสตูดิโอภาพ
- VS Code Extension: Remote-Containers
คำแนะนำเพิ่มเติมเกี่ยวกับการตั้งค่า WSL สามารถดูได้ที่นี่ ตอนนี้คุณมีข้อกำหนดเบื้องต้นคุณสามารถ:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .เมื่อโครงการเปิดใน VSCODE ควรถามคุณว่าคุณต้องการ "เปิดใหม่ในคอนเทนเนอร์การพัฒนา" อีกครั้งหรือไม่ พูดว่าใช่.
แน่นอนว่าคุณสามารถเรียกใช้ เครื่องเร่งความเร็วการทดลอง RAG บนเครื่อง Windows/Mac ได้หากคุณต้องการ คุณมีหน้าที่รับผิดชอบในการติดตั้งเครื่องมือที่ถูกต้อง ทำตามขั้นตอนการติดตั้งเหล่านี้:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bashปิดเทอร์มินัลของคุณเปิดใหม่แล้วเรียกใช้:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account showมี 3 ตัวเลือกในการติดตั้งบริการ Azure ที่จำเป็นทั้งหมด:
โครงการนี้สนับสนุน Azure Developer CLI
azd provisionazd up หากคุณต้องการเป็น azd provision นี้ต่อไป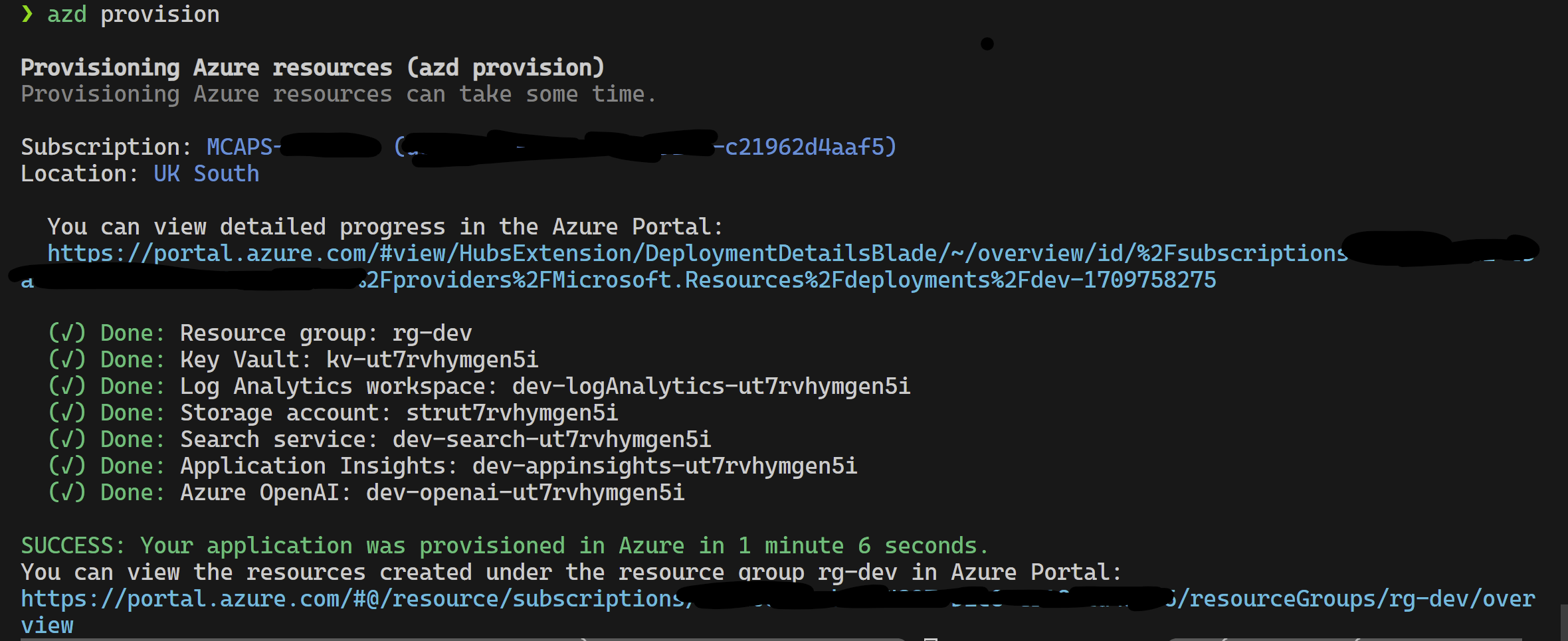
เมื่อสิ่งนี้เสร็จสิ้นแล้วคุณสามารถใช้การกำหนดค่าการเปิดใช้งานเพื่อเรียกใช้หรือดีบัก 4 ขั้นตอนและสภาพแวดล้อมปัจจุบันที่จัดเตรียมโดย azd จะถูกโหลดด้วยค่าที่ถูกต้อง
หากคุณต้องการปรับใช้โครงสร้างพื้นฐานด้วยตัวคุณเองจากเทมเพลตคุณสามารถคลิกที่นี่:
หากคุณไม่ต้องการใช้ azd คุณสามารถใช้ az CLI ปกติได้เช่นกัน
ใช้คำสั่งต่อไปนี้เพื่อปรับใช้
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepหรือ
ในการปรับใช้กับการใช้เครือข่ายแบบแยกออกคำสั่งต่อไปนี้ แทนที่ค่าพารามิเตอร์ด้วยข้อมูลเฉพาะของเครือข่ายที่แยกได้ของคุณ คุณ ต้อง จัดหาพารามิเตอร์ทั้งสาม (เช่น vnetAddressSpace , proxySubnetAddressSpace และ subnetAddressSpace ) หากคุณต้องการปรับใช้กับเครือข่ายที่แยกได้
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >นี่คือตัวอย่างที่มีค่าพารามิเตอร์:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' หากต้องการใช้ ตัวเร่งการทดลอง RAG ในเครื่องให้ทำตามขั้นตอนเหล่านี้:
คัดลอกไฟล์ .env.template ที่ให้ไปยังไฟล์ชื่อ .env และอัปเดตค่าที่ต้องการทั้งหมด ค่าที่ต้องการจำนวนมากสำหรับไฟล์ .env จะมาจากทรัพยากรที่ได้รับการกำหนดค่าก่อนหน้านี้และ/หรือสามารถรวบรวมได้จากทรัพยากรที่จัดสรรไว้ในส่วนโครงสร้างพื้นฐานบทบัญญัติ หมายเหตุโดยค่าเริ่มต้น LOGGING_LEVEL ถูกตั้งค่าเป็น INFO แต่สามารถเปลี่ยนเป็นระดับใด ๆ ต่อไปนี้: NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL
cp .env.template .env
# change parameters manually คัดลอกไฟล์ config.sample.json ที่ให้ไปยังไฟล์ชื่อ config.json และเปลี่ยน hyperparameters ใด ๆ เพื่อปรับให้เข้ากับการทดสอบของคุณ
cp config.sample.json config.json
# change parameters manually คัดลอกไฟล์ใด ๆ สำหรับการบริโภค (PDF, HTML, Markdown, Text, JSON หรือ DOCX รูปแบบ) ลงในโฟลเดอร์ data
เรียกใช้ 01_index.py (Python 01_index.py) เพื่อสร้างดัชนีการค้นหา Azure AI และโหลดข้อมูลลงในพวกเขา
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " เรียกใช้ 02_qa_generation.py (Python 02_qa_generation.py) เพื่อสร้างคู่ตอบคำถามโดยใช้ Azure Openai
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " เรียกใช้ 03_querying.py (Python 03_Querying.py) เพื่อค้นหา Azure AI Search เพื่อสร้างบริบทจัดอันดับรายการใหม่ในบริบทและรับการตอบกลับจาก Azure OpenAI โดยใช้บริบทใหม่
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " เรียกใช้ 04_evaluation.py (Python 04_evaluation.py) เพื่อคำนวณตัวชี้วัดโดยใช้วิธีการต่าง ๆ และสร้างแผนภูมิและรายงานในการเรียนรู้ของเครื่อง Azure โดยใช้การรวม MLFlow
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " หรือคุณสามารถเรียกใช้ขั้นตอนข้างต้น (นอกเหนือจาก 02_qa_generation.py ) โดยใช้ท่อ Azure ML ในการทำเช่นนั้นให้ทำตามคำแนะนำที่นี่
การสุ่มตัวอย่างจะถูกเรียกใช้ในพื้นที่เพื่อสร้างชิ้นส่วนเล็ก ๆ แต่เป็นตัวแทนของข้อมูล สิ่งนี้ช่วยในการทดลองอย่างรวดเร็วและลดต้นทุนลง ผลลัพธ์ที่ได้รับควรบ่งบอกถึงชุดข้อมูลเต็มรูปแบบภายในระยะขอบ ~ 10% เมื่อมีการระบุวิธีการแล้วให้เรียกใช้ชุดข้อมูลเต็มรูปแบบเพื่อให้ได้ผลลัพธ์ที่แม่นยำ
หมายเหตุ : การสุ่มตัวอย่างสามารถเรียกใช้งานได้เฉพาะในขั้นตอนนี้มันไม่ได้รับการสนับสนุนในคลัสเตอร์การคำนวณ AML แบบกระจาย ดังนั้นกระบวนการจะเรียกใช้การสุ่มตัวอย่างในเครื่องแล้วใช้ชุดข้อมูลตัวอย่างที่สร้างขึ้นเพื่อทำงานบน AML
หากคุณมีชุดข้อมูลที่มีขนาดใหญ่มากและต้องการเรียกใช้วิธีการที่คล้ายกันในการสุ่มตัวอย่างข้อมูลคุณสามารถใช้การใช้งานแบบกระจายในหน่วยความจำ PYSPARK ในชุดเครื่องมือค้นหาข้อมูลสำหรับ Microsoft Fabric หรือ Azure synapse Analytics
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},กระบวนการสุ่มตัวอย่างจะสร้างสิ่งประดิษฐ์ต่อไปนี้ในไดเรกทอรีการสุ่มตัวอย่าง:
job_name ที่มีชุดย่อยของตัวอย่างไฟล์ตัวอย่างเหล่านี้สามารถระบุเป็นอาร์กิวเมนต์ --data_dir เมื่อเรียกใช้กระบวนการทั้งหมดบน AML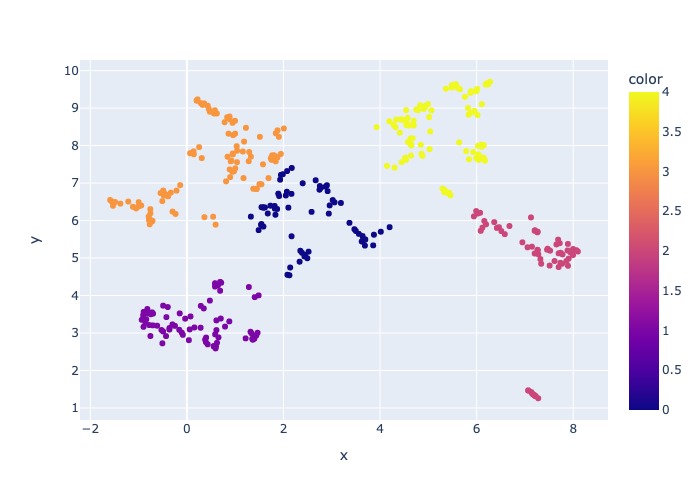
"optimum_k": auto ถูกตั้งค่าเป็นอัตโนมัติกระบวนการสุ่มตัวอย่างจะพยายามตั้งค่าจำนวนกลุ่มที่เหมาะสมโดยอัตโนมัติ สิ่งนี้สามารถแทนที่ได้หากคุณรู้ว่ามีเนื้อหาในวงกว้างมากเท่าใดในข้อมูลของคุณ กราฟข้อศอกจะถูกสร้างขึ้นในโฟลเดอร์การสุ่มตัวอย่าง 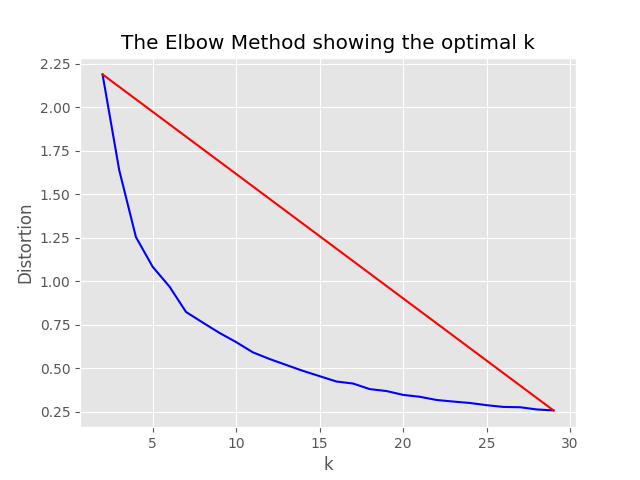
มีตัวเลือกสองตัวเลือกสำหรับการสุ่มตัวอย่างคือ:
ตั้งค่าต่อไปนี้เพื่อเรียกใช้กระบวนการจัดทำดัชนีในเครื่อง:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, หากการกำหนดค่าการกำหนดค่า only_run_sampling ถูกตั้งค่าเป็น TRUE จะเรียกใช้ขั้นตอนการสุ่มตัวอย่างเท่านั้นจะไม่มีการสร้างดัชนีและขั้นตอนอื่น ๆ ที่ตามมาจะไม่ดำเนินการ ตั้งค่าอาร์กิวเมนต์ --data_dir เป็นไดเรกทอรีที่สร้างโดยกระบวนการสุ่มตัวอย่างซึ่งจะเป็น:
artifacts/sampling/config.[job_name] และดำเนินการขั้นตอน Pipeline AML
ค่าทั้งหมดสามารถเป็นรายการขององค์ประกอบ รวมถึงการกำหนดค่าที่ซ้อนกัน ทุกอาร์เรย์จะสร้างการรวมกันของการกำหนดค่าแบบแบนเมื่อวิธีการ flatten() ถูกเรียกใช้ในโหนดเฉพาะเพื่อเลือกการรวมกันแบบสุ่ม 1 ชุด - เรียก sample()
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}หมายเหตุ: เมื่อเปลี่ยนการกำหนดค่าอย่าลืมเปลี่ยน:
config.sample.json (ตัวอย่างการกำหนดค่าที่จะคัดลอกโดยผู้อื่น) embedding_model เป็นอาร์เรย์ที่มีการกำหนดค่าสำหรับโมเดลฝังตัวที่จะใช้ type การฝังตัวของโมเดลจะต้องเป็น azure สำหรับ Azure Openai Models และ sentence-transformer สำหรับโมเดล Transformer ประโยค HuggingFace
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} หากคุณใช้โมเดลอื่นนอกเหนือจาก text-embedding-ada-002 คุณต้องระบุมิติที่สอดคล้องกันสำหรับโมเดลในฟิลด์ dimension ตัวอย่างเช่น:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}ขนาดของโมเดล Azure OpenAI Embeddings ที่แตกต่างกันสามารถพบได้ในเอกสารประกอบโมเดล Azure OpenAI Service
เมื่อใช้รุ่น Embeddings ใหม่ (V3) คุณสามารถใช้ประโยชน์จากการสนับสนุนสำหรับการลดการฝังตัวของพวกเขา ในกรณีนี้ให้ระบุจำนวนมิติที่คุณต้องการและเพิ่มธง shorten_dimensions เพื่อระบุว่าคุณต้องการลดการฝังตัว ตัวอย่างเช่น:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}การให้ตัวอย่างของคำตอบสมมุติฐานสำหรับคำถามในการสืบค้นข้อความสมมุติที่เก็บคำตอบสำหรับการสืบค้นหรือสร้างคำถามที่เกี่ยวข้องทางเลือกเล็กน้อยอาจปรับปรุงการดึงข้อมูลและทำให้เอกสารที่แม่นยำยิ่งขึ้นเพื่อส่งผ่านไปยังบริบท LLM ขึ้นอยู่กับบทความอ้างอิง - การดึงข้อมูลที่มีความหนาแน่นเป็นศูนย์อย่างแม่นยำโดยไม่มีฉลากที่เกี่ยวข้อง (ไฮด์ - เอกสารสมมุติฐานฝังตัว)
ตัวเลือกการกำหนดค่าต่อไปนี้เปิดใช้วิธีการทดลองนี้:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} คุณลักษณะนี้จะสร้างคำถามที่เกี่ยวข้องที่ดีกรองสิ่งที่น้อยกว่า min_query_expansion_related_question_similarity_score เปอร์เซ็นต์จากการสืบค้นดั้งเดิม (ใช้คะแนนความคล้ายคลึงกันของโคไซน์) และค้นหาเอกสารสำหรับแต่ละรายการพร้อมกับการสืบค้นดั้งเดิม
ค่าเริ่มต้นสำหรับ min_query_expansion_related_question_similarity_score ตั้งค่าเป็น 90%คุณอาจเปลี่ยนสิ่งนี้ใน config.json
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}โซลูชันรวมกับการเรียนรู้ของเครื่อง Azure และใช้ MLFlow เพื่อจัดการการทดลองงานและสิ่งประดิษฐ์ คุณสามารถดูรายงานต่อไปนี้เป็นส่วนหนึ่งของกระบวนการประเมินผล:
all_metrics_current_run.html แสดงคะแนนเฉลี่ยในคำถามและประเภทการค้นหาสำหรับแต่ละเมตริกที่เลือก:
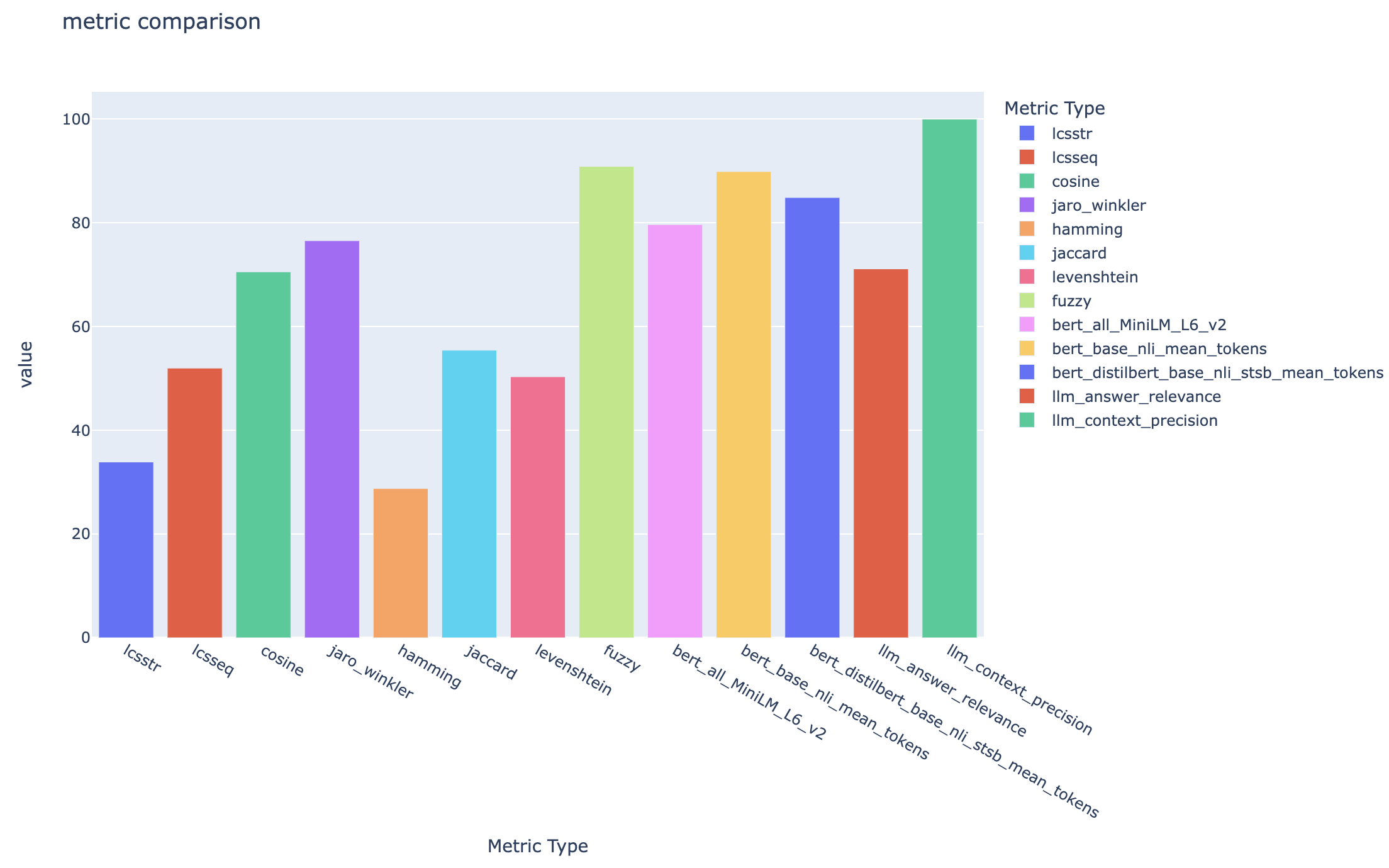
การคำนวณของแต่ละเมตริกและฟิลด์ที่ใช้สำหรับการประเมินผลจะถูกติดตามสำหรับแต่ละคำถามและประเภทการค้นหาในไฟล์ CSV เอาต์พุต:
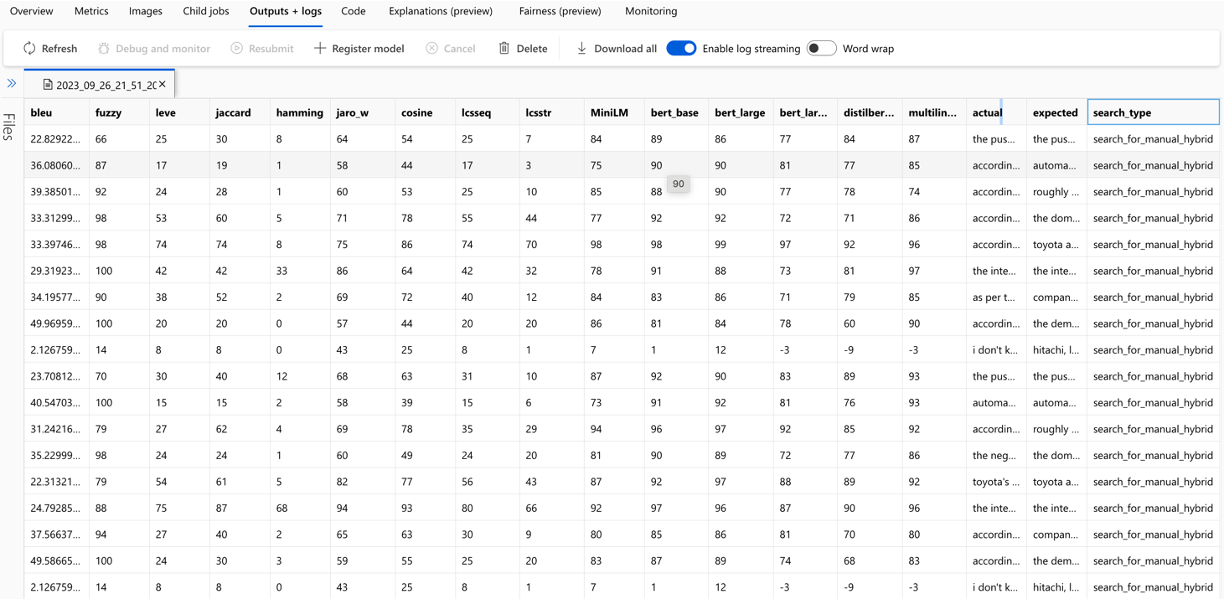
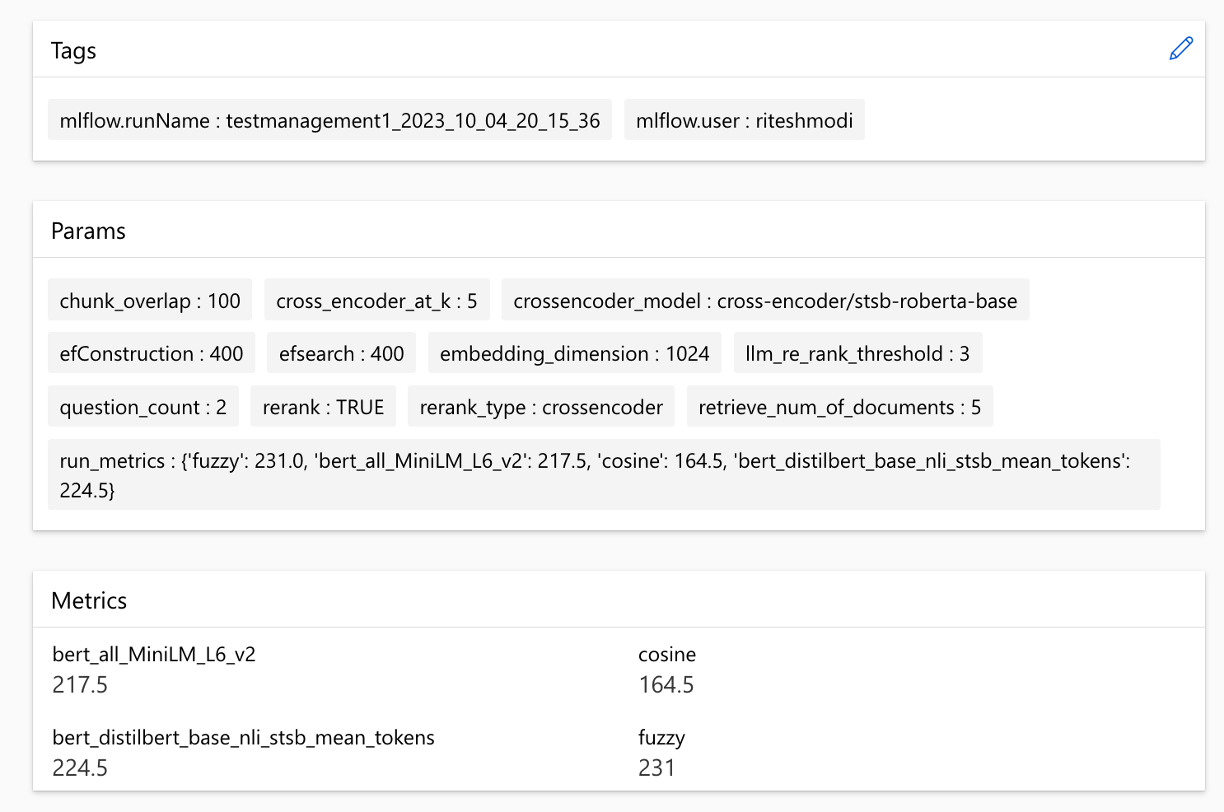
ตัวชี้วัดสามารถเปรียบเทียบได้ตลอดการวิ่ง:
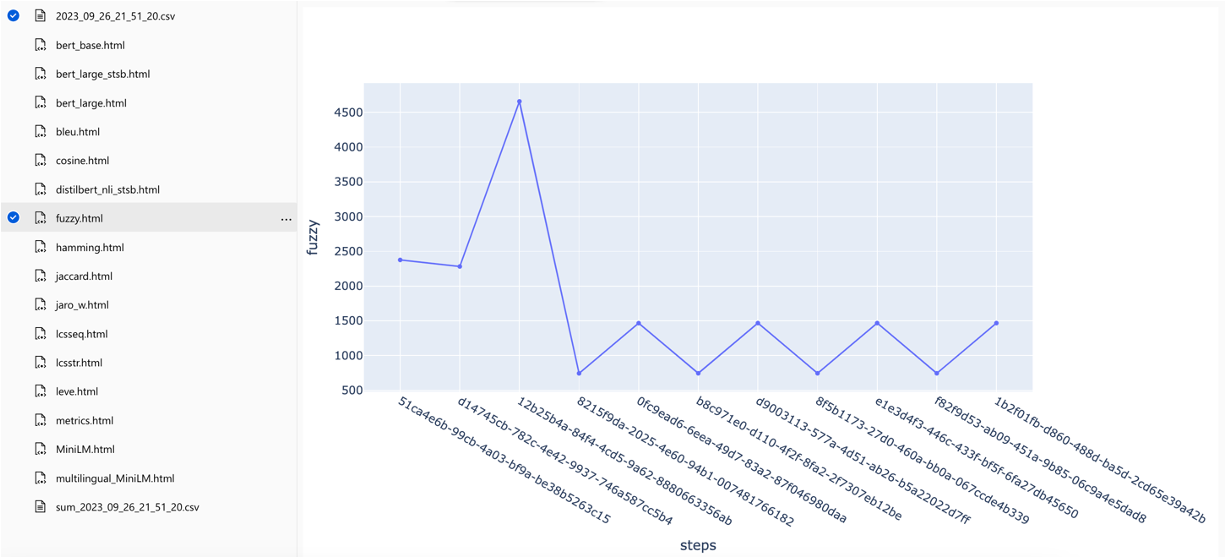
ตัวชี้วัดสามารถเปรียบเทียบได้ในกลยุทธ์การค้นหาที่แตกต่างกัน:
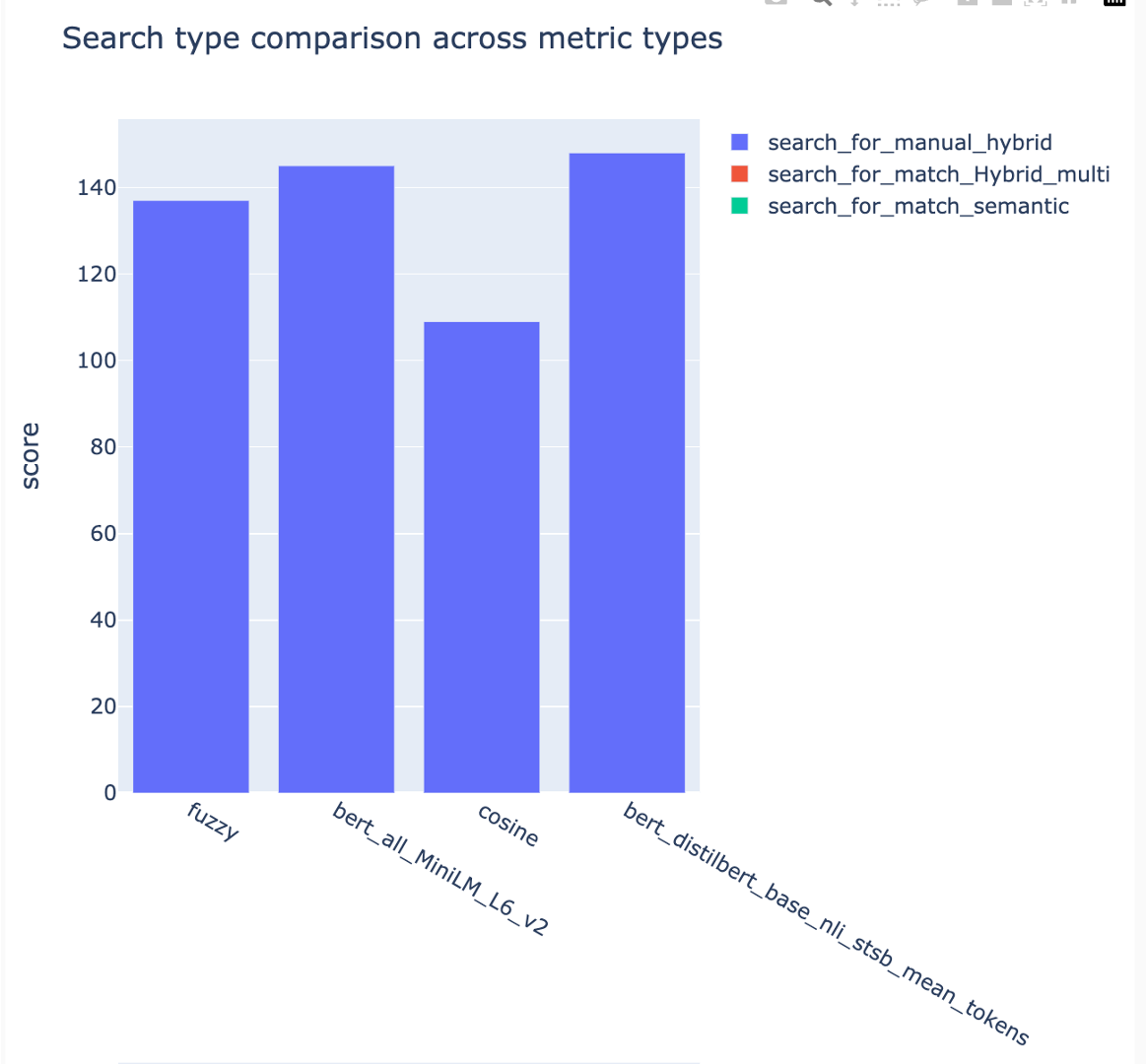
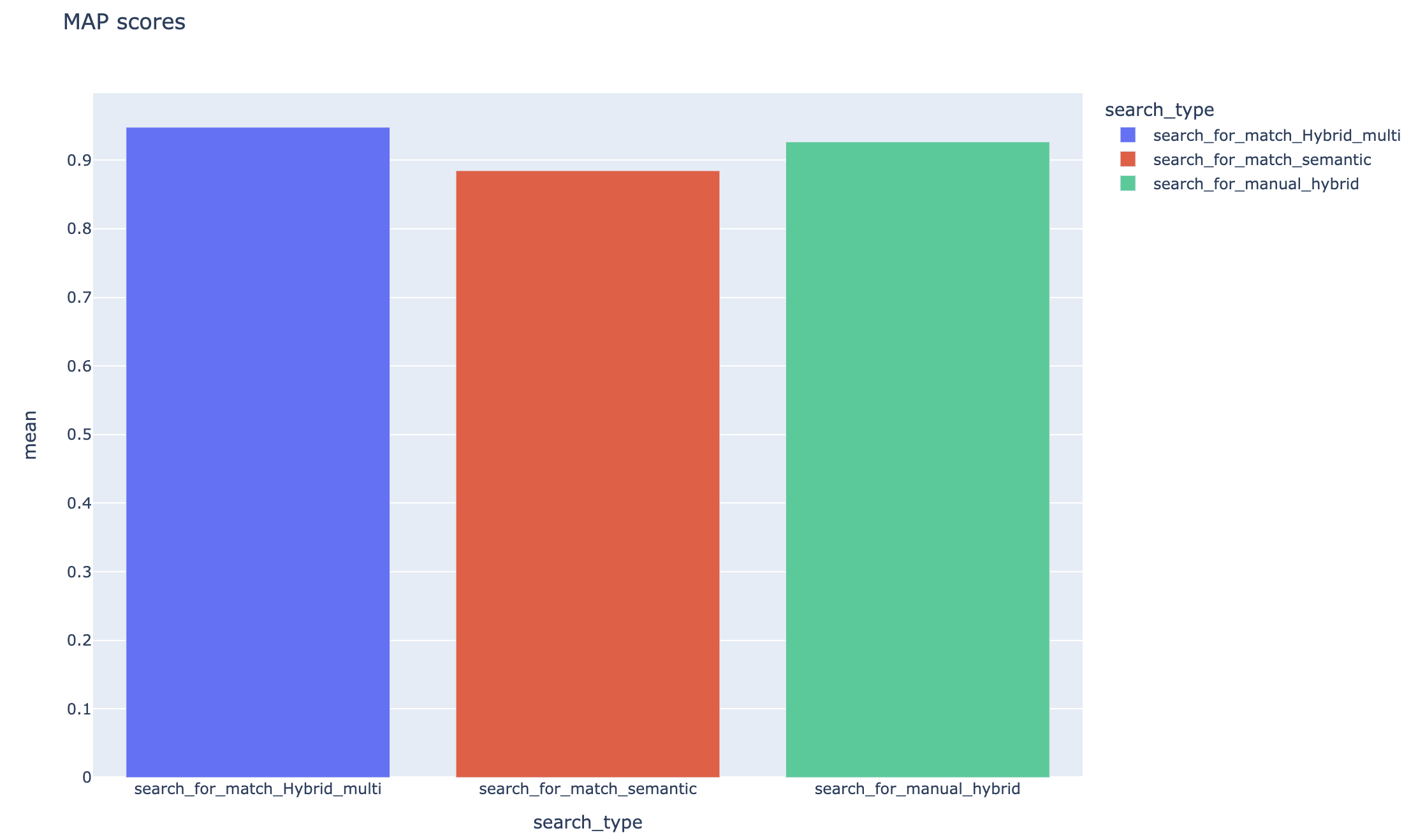
ค่าเฉลี่ยคะแนนความแม่นยำเฉลี่ยจะถูกติดตามและคะแนนแผนที่เฉลี่ยสามารถเปรียบเทียบได้ในประเภทการค้นหา:
ส่วนนี้แสดงถึง gotchas ทั่วไปหรือข้อผิดพลาดที่วิศวกร/นักพัฒนา/นักวิทยาศาสตร์ข้อมูลอาจพบในขณะที่ทำงานกับตัวเร่งการทดลอง RAG
หากต้องการใช้โซลูชันนี้สำเร็จคุณต้องตรวจสอบตัวเองก่อนโดยลงชื่อเข้าใช้บัญชี Azure ของคุณ ขั้นตอนที่สำคัญนี้ช่วยให้มั่นใจได้ว่าคุณมีสิทธิ์ที่จำเป็นในการเข้าถึงและจัดการทรัพยากร Azure ที่ใช้โดยมัน คุณอาจมีข้อผิดพลาดที่เกี่ยวข้องกับการจัดเก็บข้อมูล QNA ลงในสินทรัพย์ข้อมูลการเรียนรู้ของเครื่อง Azure การดำเนินการตามขั้นตอนการสืบค้นและการประเมินผลอันเป็นผลมาจากการอนุญาตที่ไม่เหมาะสมและการรับรองความถูกต้องของ Azure อ้างถึงจุดที่ 4 ในเอกสารนี้สำหรับการรับรองความถูกต้องและการอนุญาต
อาจมีสถานการณ์ที่วิธีแก้ปัญหาจะยังคงสร้างข้อผิดพลาดแม้จะมีการตรวจสอบสิทธิ์และการอนุญาตที่ถูกต้อง ในกรณีเช่นนี้เริ่มเซสชันใหม่ด้วยอินสแตนซ์เทอร์มินัลใหม่ล่าสุดเข้าสู่ระบบ Azure โดยใช้ขั้นตอนที่กล่าวถึงในขั้นตอนที่ 4 และตรวจสอบว่าผู้ใช้มีส่วนร่วมในการเข้าถึงทรัพยากร Azure ที่เกี่ยวข้องกับโซลูชันหรือไม่
โซลูชันนี้ใช้พารามิเตอร์การกำหนดค่าหลายอย่างใน config.json ที่ส่งผลกระทบโดยตรงต่อการทำงานและประสิทธิภาพ โปรดใส่ใจกับการตั้งค่าเหล่านี้:
RETRIEVE_NUM_OF_DOCUMENTS: การกำหนดค่านี้ควบคุมจำนวนเอกสารเริ่มต้นที่ดึงมาเพื่อการวิเคราะห์ ค่าที่สูงหรือต่ำมากเกินไปอาจนำไปสู่ข้อผิดพลาด "ดัชนีนอกช่วง" เนื่องจากการประมวลผลอันดับของผลลัพธ์การค้นหา AI
cross_encoder_at_k: การกำหนดค่านี้มีผลต่อกระบวนการจัดอันดับ มูลค่าสูงอาจส่งผลให้เอกสารที่ไม่เกี่ยวข้องรวมอยู่ในผลลัพธ์สุดท้าย
LLM_RERANK_THRESHOLD: การกำหนดค่านี้กำหนดว่าเอกสารใดที่ส่งผ่านไปยังรูปแบบภาษา (LLM) สำหรับการประมวลผลเพิ่มเติม การตั้งค่าค่านี้สูงเกินไปสามารถสร้างบริบทที่มีขนาดใหญ่เกินไปสำหรับ LLM ในการจัดการซึ่งอาจนำไปสู่ข้อผิดพลาดในการประมวลผลหรือผลลัพธ์ที่ลดลง สิ่งนี้อาจส่งผลให้เกิดข้อยกเว้นจากจุดสิ้นสุดของ Azure Openai
ก่อนที่จะเรียกใช้โซลูชันนี้โปรดตรวจสอบให้แน่ใจว่าคุณได้ตั้งค่าชื่อการปรับใช้ Azure OpenAI ของคุณอย่างถูกต้องภายในไฟล์ config.json และเพิ่มความลับที่เกี่ยวข้องในตัวแปรสภาพแวดล้อม (ไฟล์. ENV) ข้อมูลนี้มีความสำคัญสำหรับแอปพลิเคชันในการเชื่อมต่อกับทรัพยากร Azure OpenAI ที่เหมาะสมและฟังก์ชั่นตามที่ออกแบบมา หากคุณไม่แน่ใจเกี่ยวกับข้อมูลการกำหนดค่าโปรดดูไฟล์. env.template และ config.json โซลูชันได้รับการทดสอบด้วยรุ่น GPT 3.5 Turbo และต้องการการทดสอบเพิ่มเติมสำหรับรุ่นอื่น ๆ
ในระหว่างขั้นตอนการสร้าง QNA คุณอาจพบข้อผิดพลาดที่เกี่ยวข้องกับเอาท์พุท JSON ที่ได้รับจาก Azure Openai เป็นครั้งคราว ข้อผิดพลาดเหล่านี้สามารถป้องกันการสร้างคำถามและคำตอบที่ประสบความสำเร็จ นี่คือสิ่งที่คุณต้องรู้:
การจัดรูปแบบที่ไม่ถูกต้อง: เอาต์พุต JSON จาก Azure OpenAI อาจไม่เป็นไปตามรูปแบบที่คาดหวังทำให้เกิดปัญหากับกระบวนการสร้าง QNA การกรองเนื้อหา: Azure Openai มีตัวกรองเนื้อหาอยู่ หากข้อความอินพุตหรือการตอบสนองที่สร้างขึ้นนั้นถือว่าไม่เหมาะสมก็อาจนำไปสู่ข้อผิดพลาด ข้อ จำกัด ของ API: บริการ Azure OpenAI มีข้อ จำกัด ด้านโทเค็นและอัตราที่มีผลต่อเอาต์พุต
ตัวชี้วัดการประเมินแบบ end-to-end: ไม่ใช่ทุกตัวชี้วัดที่เปรียบเทียบคำตอบที่สร้างและความจริงพื้นดินสามารถจับความแตกต่างในความหมายได้ ตัวอย่างเช่นตัวชี้วัดเช่น levenshtein หรือ jaro_winkler วัดระยะทางแก้ไขเท่านั้น ตัวชี้วัด cosine ไม่อนุญาตให้มีการเปรียบเทียบความหมายเช่นกัน: ใช้การใช้งานตามโทเค็นแบบ textdistance ตามเวกเตอร์ความถี่ ในการคำนวณความคล้ายคลึงกันทางความหมายระหว่างคำตอบที่สร้างขึ้นและการตอบสนองที่คาดหวังให้พิจารณาโดยใช้ตัวชี้วัดที่ใช้การฝังเช่นคะแนน BERT ( bert_ )
ตัวชี้วัดการประเมินผลที่ชาญฉลาด: การประเมินผลการวัดโดยใช้ LLM-as-judges ไม่ได้กำหนด ตัวชี้วัด llm_ ที่รวมอยู่ในตัวเร่งความเร็วใช้โมเดลที่ระบุไว้ในฟิลด์ azure_oai_eval_deployment_name พรอมต์ที่ใช้สำหรับคำสั่งการประเมินผลสามารถปรับได้และรวมอยู่ในไฟล์ prompts.py ( llm_answer_relevance_instruction , llm_context_recall_instruction , llm_context_precision_instruction )
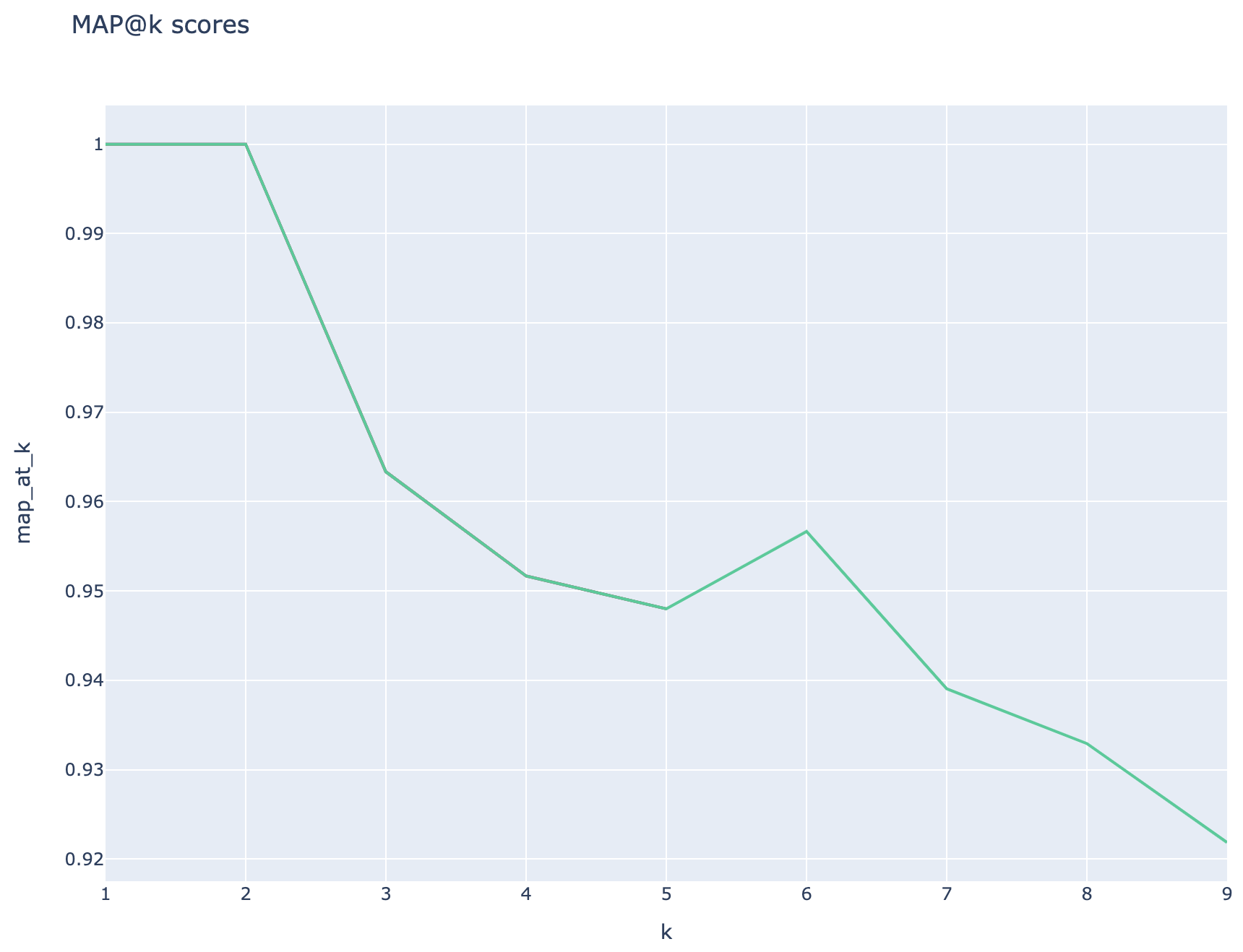
ตัวชี้วัดที่ใช้การดึงข้อมูล: คะแนนแผนที่คำนวณโดยการเปรียบเทียบแต่ละครั้งที่ดึงมากับคำถามและก้อนที่ใช้ในการสร้างคู่ QNA เพื่อประเมินว่าก้อนที่ดึงมานั้นมีความเกี่ยวข้องหรือไม่ความคล้ายคลึงกันระหว่างก้อนที่ดึงมาและการต่อเนื่องของคำถามผู้ใช้ปลายทางและก้อนที่ใช้ในขั้นตอน QNA ( 02_qa_generation.py ) คำนวณโดยใช้ SpacyEvaluator ความคล้ายคลึงกันของ Spacy มีค่าเริ่มต้นกับค่าเฉลี่ยของเวกเตอร์โทเค็นซึ่งหมายความว่าการคำนวณนั้นไม่รู้สึกถึงลำดับของคำ โดยค่าเริ่มต้นเกณฑ์ความคล้ายคลึงกันถูกตั้งค่าเป็น 80% ( spacy_evaluator.py )
เรายินดีต้อนรับการมีส่วนร่วมและข้อเสนอแนะของคุณ ในการมีส่วนร่วมคุณต้องยอมรับข้อตกลงใบอนุญาตผู้มีส่วนร่วม (CLA) ที่ยืนยันว่าคุณมีสิทธิ์และทำจริงให้สิทธิ์ในการใช้เงินสมทบของคุณ สำหรับรายละเอียดเยี่ยมชม [https://cla.opensource.microsoft.com]
เมื่อคุณส่งคำขอดึง CLA บอทจะตรวจสอบโดยอัตโนมัติว่าคุณจำเป็นต้องให้ CLA และให้คำแนะนำแก่คุณ (ตัวอย่างเช่นตรวจสอบสถานะแสดงความคิดเห็น) ทำตามคำแนะนำจากบอท คุณต้องทำสิ่งนี้เพียงครั้งเดียวสำหรับ repos ทั้งหมดที่ใช้ CLA ของเรา
ก่อนที่คุณจะมีส่วนร่วมตรวจสอบให้แน่ใจว่าได้ทำงาน
pip install -e .
pre-commit install
โครงการนี้เป็นไปตามจรรยาบรรณของ Microsoft Open Source สำหรับข้อมูลเพิ่มเติมโปรดดูที่คำถามที่พบบ่อยครั้งหรือติดต่อ [email protected] พร้อมคำถามหรือความคิดเห็นใด ๆ
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_casegit config --global user.name "First Last"โครงการนี้อาจมีเครื่องหมายการค้าหรือโลโก้สำหรับโครงการผลิตภัณฑ์หรือบริการ คุณต้องปฏิบัติตามแนวทางเครื่องหมายการค้าและแบรนด์ของ Microsoft เพื่อใช้เครื่องหมายการค้าหรือโลโก้ของ Microsoft อย่างถูกต้อง อย่าใช้เครื่องหมายการค้าหรือโลโก้ของ Microsoft ในรุ่นที่แก้ไขของโครงการนี้ในลักษณะที่ทำให้เกิดความสับสนหรือหมายถึงการสนับสนุนของ Microsoft ปฏิบัติตามนโยบายของเครื่องหมายการค้าหรือโลโก้ของบุคคลที่สามใด ๆ ที่โครงการนี้มี


