lang2sql
1.0.0
repo นี้ให้คำแนะนำทีละขั้นตอนและเทมเพลตสำหรับการตั้งค่าภาษาธรรมชาติให้กับตัวสร้างรหัส SQL ด้วย Opneai API
บทช่วยสอนยังมีอยู่ในสื่อ
อัปเดตล่าสุด: 7 ม.ค. 2024
การพัฒนาอย่างรวดเร็วของแบบจำลองภาษาธรรมชาติโดยเฉพาะแบบจำลองภาษาขนาดใหญ่ (LLMS) ได้นำเสนอความเป็นไปได้มากมายสำหรับสาขาต่าง ๆ หนึ่งในแอพพลิเคชั่นที่พบบ่อยที่สุดคือการใช้ LLMs สำหรับการเข้ารหัส ตัวอย่างเช่นรหัส Llama ของ OpenAi และ Meta เป็น LLM ที่ให้ภาษาธรรมชาติที่ทันสมัยแก่ผู้สร้างรหัส กรณีการใช้งานที่มีศักยภาพอย่างหนึ่งคือภาษาธรรมชาติในการสร้างรหัส SQL ซึ่งสามารถช่วยเหลือผู้เชี่ยวชาญที่ไม่ใช่ด้านเทคนิคด้วยคำขอข้อมูลที่เรียบง่ายและหวังว่าจะช่วยให้ทีมข้อมูลมุ่งเน้นไปที่งานที่ต้องใช้ข้อมูลมากขึ้น บทช่วยสอนนี้มุ่งเน้นไปที่การตั้งค่าภาษาสำหรับตัวสร้างรหัส SQL โดยใช้ OpenAI API
แอปพลิเคชั่นหนึ่งที่เป็นไปได้คือ chatbot ที่สามารถตอบคำถามผู้ใช้ด้วยข้อมูลที่เกี่ยวข้อง (รูปที่ 1) chatbot สามารถรวมเข้ากับช่อง Slack โดยใช้แอปพลิเคชัน Python ที่ทำตามขั้นตอนต่อไปนี้:
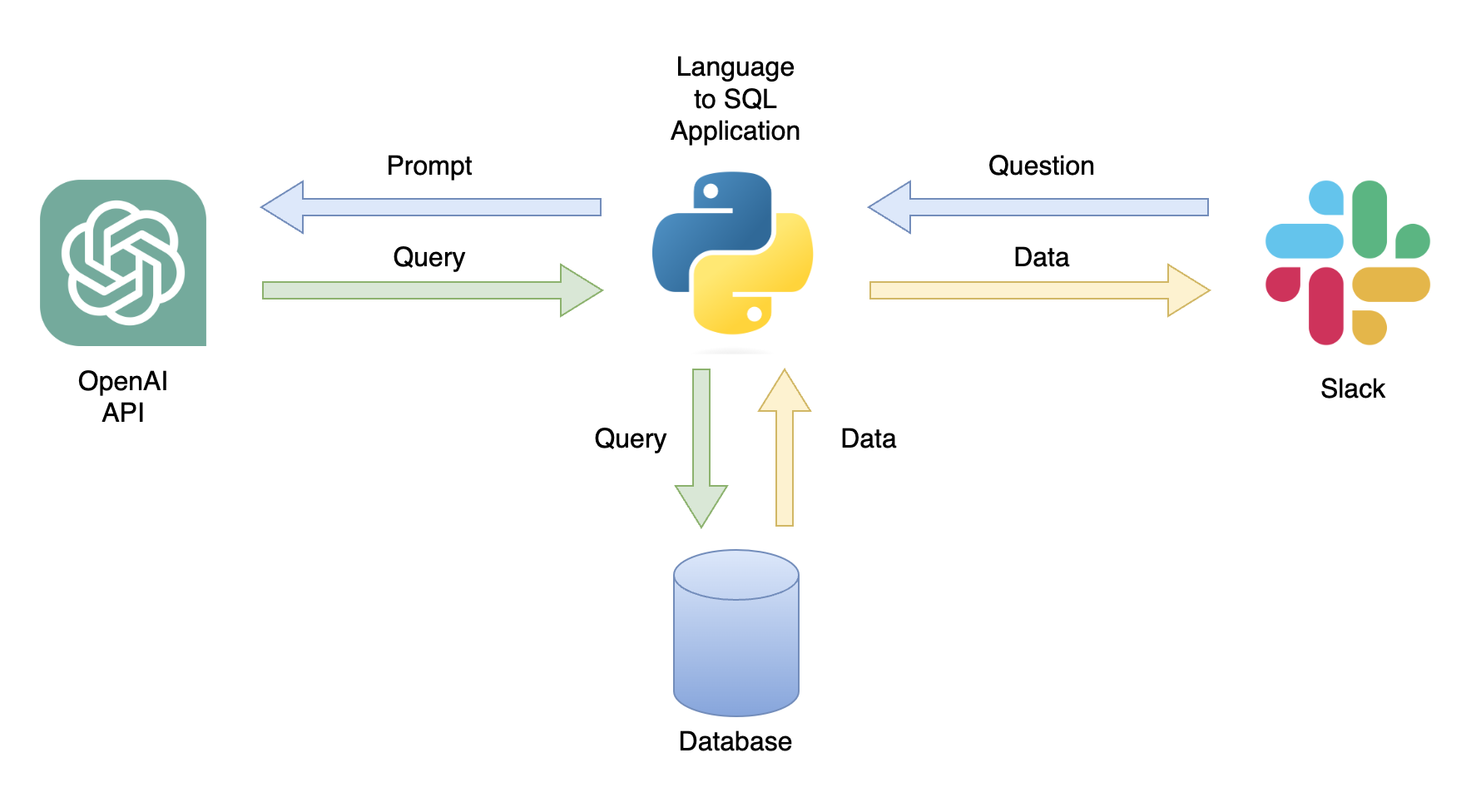
ในบทช่วยสอนนี้เราจะสร้างแอปพลิเคชัน Python ทีละขั้นตอนที่แปลงคำถามผู้ใช้เป็นแบบสอบถาม SQL
บทช่วยสอนนี้ให้คำแนะนำทีละขั้นตอนเกี่ยวกับวิธีการตั้งค่าแอปพลิเคชัน Python ที่แปลงคำถามทั่วไปเป็นแบบสอบถาม SQL โดยใช้ OpenAI API ซึ่งรวมถึงฟังก์ชั่นต่อไปนี้:
รูปที่ 2 ด้านล่างอธิบายสถาปัตยกรรมทั่วไปของภาษาง่าย ๆ ไปยังตัวสร้างรหัส SQL
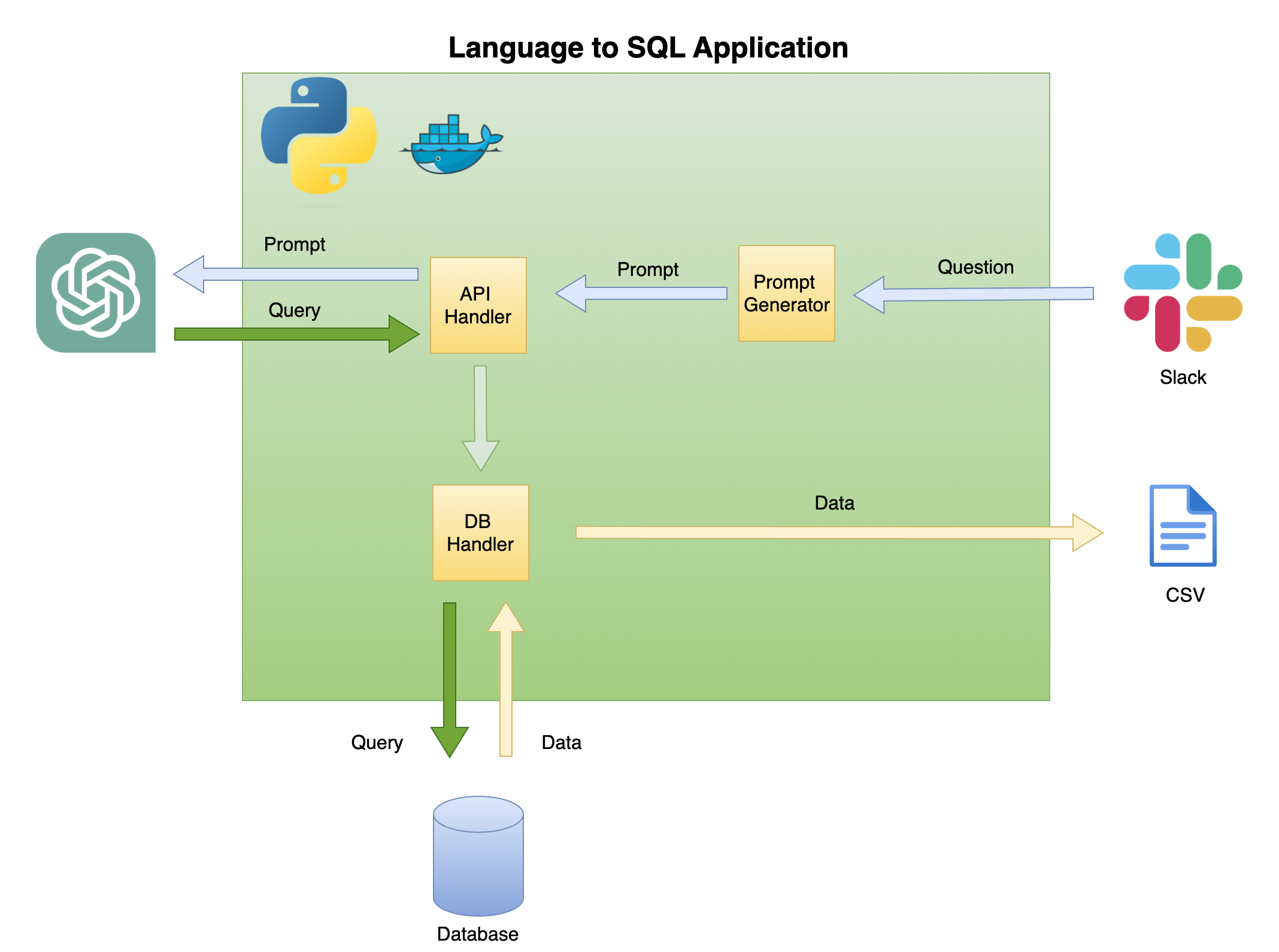
ขอบเขตและจุดสนใจของบทช่วยสอนนี้อยู่ในกล่องสีเขียว - สร้างฟังก์ชันการทำงานต่อไปนี้:
คำถามที่จะแจ้ง - แปลงคำถามเป็นรูปแบบที่รวดเร็ว:
API Handler - ฟังก์ชั่นที่ใช้งานได้กับ OpenAI API:
DB Handler - ฟังก์ชั่นที่ส่งแบบสอบถาม SQL ไปยังฐานข้อมูลและส่งคืนข้อมูลที่ต้องการ
ข้อกำหนดเบื้องต้นหลักสำหรับบทช่วยสอนนี้คือความรู้พื้นฐานของ Python ซึ่งรวมถึงฟังก์ชั่นต่อไปนี้:
นอกจากนี้จำเป็นต้องมีความรู้พื้นฐานเกี่ยวกับ SQL และการเข้าถึง OpenAI API
ในขณะที่ไม่จำเป็นการมีความรู้พื้นฐานเกี่ยวกับนักเทียบท่ามีประโยชน์เนื่องจากการสอนถูกสร้างขึ้นในสภาพแวดล้อมที่เกี่ยวข้องโดยใช้ส่วนขยายของ VSCODE DEV Containers หากคุณไม่มีประสบการณ์กับ Docker หรือส่วนขยายคุณยังสามารถเรียกใช้การสอนได้โดยการสร้างสภาพแวดล้อมเสมือนจริงและติดตั้งไลบรารีที่ต้องการ (ตามที่อธิบายไว้ด้านล่าง) ความรู้เกี่ยวกับวิศวกรรมที่รวดเร็วและ OpenAI API ก็มีประโยชน์เช่นกัน
ฉันสร้างบทช่วยสอนโดยละเอียดเกี่ยวกับการตั้งค่าสภาพแวดล้อมการเชื่อมต่อ Python ด้วย VSCODE และส่วนขยายคอนเทนเนอร์ DEV:
https://github.com/ramikrispin/vscode-python
ในการตั้งค่าภาษาธรรมชาติเป็นการสร้างรหัส SQL เราจะใช้ไลบรารี Python ต่อไปนี้:
pandas - เพื่อประมวลผลข้อมูลตลอดกระบวนการduckdb - เพื่อจำลองการทำงานกับฐานข้อมูลopenai - ทำงานร่วมกับ Openai APItime และ os - เพื่อโหลดไฟล์ CSV และฟิลด์ฟอร์แมตพื้นที่เก็บข้อมูลนี้มีการตั้งค่าที่จำเป็นเพื่อเรียกใช้สภาพแวดล้อมการเชื่อมต่อพร้อมข้อกำหนดการสอนใน VSCODE และส่วนขยายคอนเทนเนอร์ DEV รายละเอียดเพิ่มเติมมีอยู่ในส่วนถัดไป
หรือคุณสามารถตั้งค่าสภาพแวดล้อมเสมือนจริงและติดตั้งข้อกำหนดการสอนโดยทำตามคำแนะนำด้านล่างโดยใช้คำแนะนำในส่วนการใช้สภาพแวดล้อมเสมือนจริง
บทช่วยสอนนี้ถูกสร้างขึ้นภายในสภาพแวดล้อมที่มีการเชื่อมต่อด้วย VSCODE และส่วนขยายคอนเทนเนอร์ DEV ในการเรียกใช้ด้วย VSCODE คุณจะต้องติดตั้งส่วนขยายคอนเทนเนอร์ DEV และเปิด Docker Desktop (หรือเทียบเท่า) การตั้งค่าของสภาพแวดล้อมมีอยู่ภายใต้โฟลเดอร์ .devcontainer :
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
devcontainer.json มีคำแนะนำในการสร้างและการตั้งค่า VSCODE สำหรับสภาพแวดล้อมที่เชื่อมต่อนี้:
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
ในกรณีที่อาร์กิวเมนต์ build กำหนดวิธี docker build และตั้งค่าอาร์กิวเมนต์สำหรับการสร้าง ในกรณีนี้เราตั้งค่าเวอร์ชัน Python เป็น 3.10 และสภาพแวดล้อมเสมือนจริงของ Conda เป็น ang2sql METHOD วิธีการกำหนดประเภทของสภาพแวดล้อม - openai เพื่อติดตั้งไลบรารีข้อกำหนดสำหรับบทช่วยสอนนี้โดยใช้ OpenAI API หรือ transformers เพื่อตั้งค่าสภาพแวดล้อมสำหรับ HuggingFaces API (ซึ่งอยู่นอกขอบเขตสำหรับบทช่วยสอนนี้)
อาร์กิวเมนต์ remoteEnv เปิดใช้งานตัวแปรสภาพแวดล้อม เราจะใช้มันเพื่อตั้งค่าคีย์ OpenAI API ในกรณีนี้ฉันตั้งค่าตัวแปรในเครื่องเป็น OPENAI_KEY และฉันกำลังโหลดโดยใช้อาร์กิวเมนต์ localEnv
หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการตั้งค่าสภาพแวดล้อมการพัฒนา Python ด้วย VScode และ Docker ให้ตรวจสอบบทช่วยสอนนี้
หากคุณไม่ได้ใช้สภาพแวดล้อมการสอนการเชื่อมต่อคุณสามารถสร้างสภาพแวดล้อมเสมือนจริงในท้องถิ่นจากบรรทัดคำสั่งโดยใช้สคริปต์ด้านล่าง:
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
หมายเหตุ: ฉันใช้ conda และควรใช้งานได้ดีกับวิธีการสภาพแวดล้อมของไวรัสอื่น ๆ
เราใช้ตัวแปร ENV_NAME และ PYTHON_VER เพื่อตั้งค่าสภาพแวดล้อมเสมือนจริงและรุ่น Python ตามลำดับ
เพื่อยืนยันว่าสภาพแวดล้อมของคุณถูกตั้งค่าอย่างถูกต้องให้ใช้ conda list เพื่อยืนยันว่ามีการติดตั้งไลบรารี Python ที่ต้องการ คุณควรคาดหวังผลลัพธ์ด้านล่าง:
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
เราจะใช้ OpenAI API เพื่อเข้าถึง CHATGPT โดยใช้เอ็นจิ้น Text-DavincI-003 สิ่งนี้จำเป็นต้องมีบัญชี OpenAI ที่ใช้งานอยู่และคีย์ API การตั้งค่าบัญชีและคีย์ API นั้นตรงไปตรงมาตามคำแนะนำในลิงค์ด้านล่าง:
https://openai.com/product
เมื่อคุณตั้งค่าการเข้าถึง API และคีย์แล้วฉันขอแนะนำให้เพิ่มคีย์เป็นตัวแปรสภาพแวดล้อมในไฟล์ .zshrc ของคุณ (หรือรูปแบบอื่น ๆ ที่คุณใช้ในการจัดเก็บตัวแปรสภาพแวดล้อมในระบบเชลล์ของคุณ) ฉันเก็บคีย์ API ของฉันไว้ภายใต้ตัวแปรสภาพแวดล้อม OPENAI_KEY ด้วยเหตุผลที่น่าเชื่อถือฉันขอแนะนำให้คุณใช้อนุสัญญาการตั้งชื่อเดียวกัน
ในการตั้งค่าตัวแปรบนไฟล์ .zshrc (หรือเทียบเท่า) ให้เพิ่มบรรทัดด้านล่างลงในไฟล์:
export OPENAI_KEY= " YOUR_API_KEY " หากใช้ VSCODE หรือรันจากเทอร์มินัลคุณต้องรีสตาร์ทเซสชันของคุณหลังจากเพิ่มตัวแปรลงในไฟล์. .zshrc
เพื่อจำลองการทำงานของฐานข้อมูลเราจะใช้ชุดข้อมูลอาชญากรรมในชิคาโก ชุดข้อมูลนี้ให้ข้อมูลเชิงลึกเกี่ยวกับอาชญากรรมที่บันทึกไว้ในเมืองชิคาโกตั้งแต่ปี 2544 ด้วยบันทึกเกือบ 8 ล้านระเบียนและคอลัมน์ 22 คอลัมน์ชุดข้อมูลรวมถึงข้อมูลเช่นการจำแนกอาชญากรรมสถานที่เวลาผลลัพธ์ ฯลฯ ข้อมูลสามารถดาวน์โหลดได้จากพอร์ทัลข้อมูลชิคาโก เนื่องจากเราจัดเก็บข้อมูลในพื้นที่เป็นเฟรมข้อมูลแพนด้าและใช้ DuckDB เพื่อจำลองการสืบค้น SQL เราจะดาวน์โหลดชุดย่อยของข้อมูลโดยใช้สามปีที่ผ่านมา
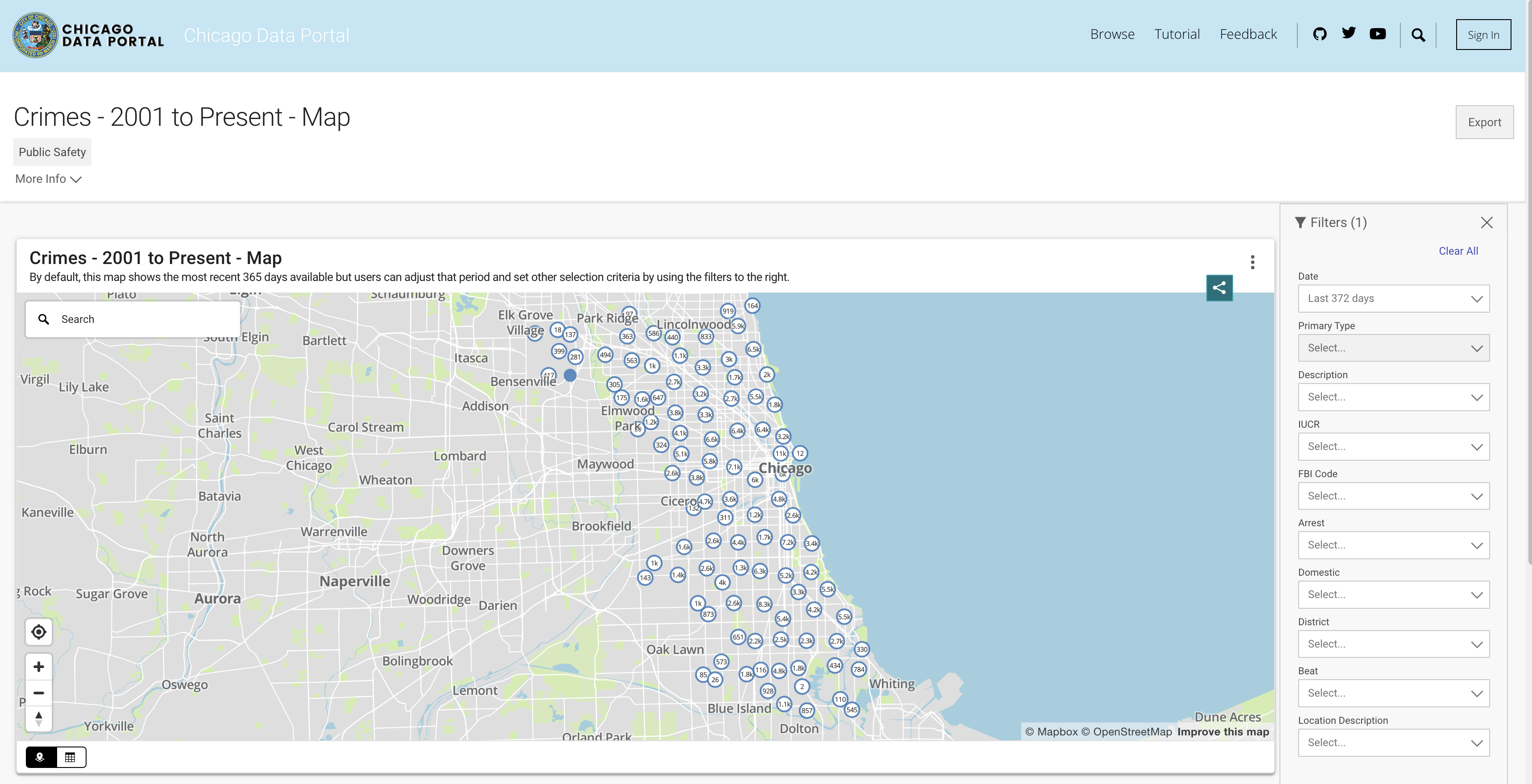
คุณสามารถดึงข้อมูลจาก API หรือดาวน์โหลดไฟล์ CSV เพื่อหลีกเลี่ยงการเรียก API ทุกครั้งที่เรียกใช้สคริปต์ฉันดาวน์โหลดไฟล์และจัดเก็บไว้ใต้โฟลเดอร์ Data ด้านล่างนี้คือลิงก์ไปยังชุดข้อมูลตามปี:
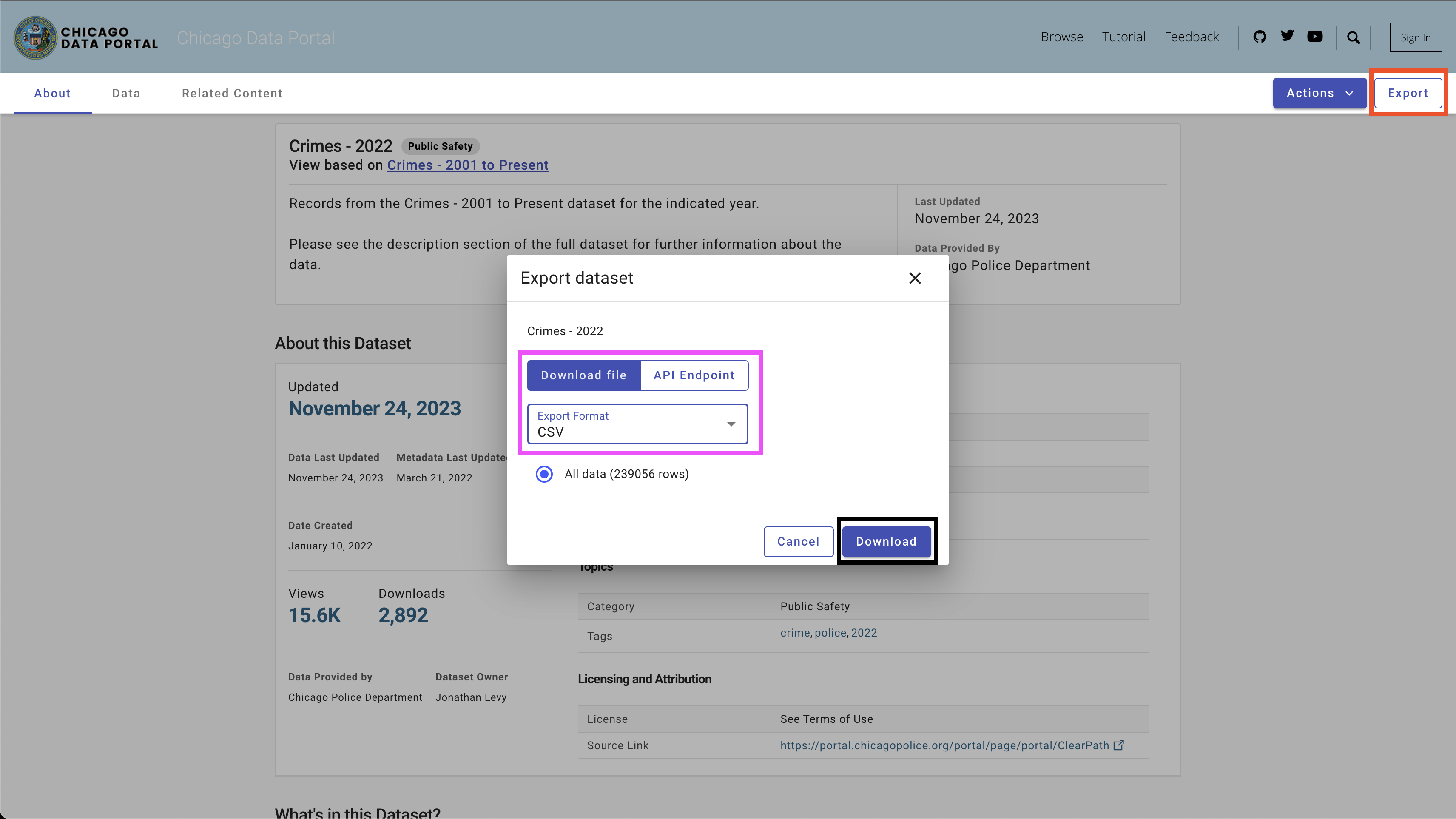
ในการดาวน์โหลดข้อมูลให้ใช้ปุ่ม Export ที่ด้านบนขวาเลือกตัวเลือก CSV และคลิกปุ่ม Download ดังที่เห็นในรูปที่ 4
ฉันใช้อนุสัญญาการตั้งชื่อต่อไปนี้ - chicago_crime_year.csv และบันทึกไฟล์ในโฟลเดอร์ data แต่ละขนาดไฟล์ใกล้ถึง 50 MB ดังนั้นฉันจึงเพิ่มพวกเขาลงในไฟล์ GIT ละเว้นภายใต้โฟลเดอร์ data และไม่สามารถใช้งานได้ใน repo นี้ หลังจากดาวน์โหลดไฟล์และตั้งชื่อคุณควรมีไฟล์ต่อไปนี้ในโฟลเดอร์:
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
หมายเหตุ: ณ เวลาของการสร้างบทช่วยสอนนี้ข้อมูลสำหรับปี 2023 ยังคงได้รับการอัปเดต ดังนั้นคุณอาจได้รับผลลัพธ์ที่แตกต่างกันเล็กน้อยเมื่อเรียกใช้แบบสอบถามบางส่วนในส่วนต่อไปนี้
ลองไปยังส่วนที่น่าตื่นเต้นซึ่งกำลังตั้งค่าตัวสร้างรหัส SQL ในส่วนนี้เราจะสร้างฟังก์ชั่น Python ที่ใช้ในคำถามของผู้ใช้ตาราง SQL ที่เกี่ยวข้องและคีย์ OpenAI API และส่งออก SQL แบบสอบถามที่ตอบคำถามของผู้ใช้
เริ่มต้นด้วยการโหลดชุดข้อมูลอาชญากรรมชิคาโกและไลบรารี Python ที่ต้องการ
สิ่งแรกก่อน - มาโหลดไลบรารี Python ที่จำเป็น:
import pandas as pd
import duckdb
import openai
import time
import osเราจะใช้ประโยชน์จากไลบรารี OS และ เวลา เพื่อโหลดไฟล์ CSV และฟอร์แมตฟิลด์บางอย่าง ข้อมูลจะถูกประมวลผลโดยใช้ไลบรารี Pandas และเราจะจำลองคำสั่ง SQL ด้วยไลบรารี Duckdb สุดท้ายเราจะสร้างการเชื่อมต่อกับ OpenAI API โดยใช้ไลบรารี OpenAI
ต่อไปเราจะโหลดไฟล์ CSV จากโฟลเดอร์ DATA รหัสด้านล่างอ่านไฟล์ CSV ทั้งหมดที่มีอยู่ในโฟลเดอร์ Data:
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]หากคุณดาวน์โหลดไฟล์ที่เกี่ยวข้องสำหรับปี 2021 ถึง 2023 และใช้การประชุมการตั้งชื่อเดียวกันคุณควรคาดหวังผลลัพธ์ต่อไปนี้:
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]ต่อไปเราจะอ่านและโหลดไฟล์ทั้งหมดและต่อท้ายลงในเฟรมข้อมูลแพนด้า:
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headหากคุณโหลดไฟล์อย่างถูกต้องคุณควรคาดหวังผลลัพธ์ต่อไปนี้:
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) หมายเหตุ: เมื่อสร้างบทช่วยสอนนี้ข้อมูลบางส่วนสำหรับปี 2566 พร้อมใช้งาน การต่อท้ายไฟล์สามไฟล์จะส่งผลให้แถวมากกว่าที่แสดง (แถว 648830)
ก่อนที่เราจะเข้าสู่รหัส Python ให้หยุดและตรวจสอบว่าวิศวกรรมที่รวดเร็วทำงานอย่างไรและเราจะช่วย CHATGPT (และโดยทั่วไปแล้ว LLM) สร้างผลลัพธ์ที่ดีที่สุด เราจะใช้ในส่วนนี้เว็บอินเตอร์เฟส chatgpt
ปัจจัยสำคัญอย่างหนึ่งในรูปแบบทางสถิติและการเรียนรู้ของเครื่องคือคุณภาพเอาต์พุตขึ้นอยู่กับคุณภาพอินพุต ดังที่วลีที่มีชื่อเสียงกล่าวว่า- ขยะในขยะ ในทำนองเดียวกันคุณภาพของเอาต์พุต LLM ขึ้นอยู่กับคุณภาพของพรอมต์
ตัวอย่างเช่นสมมติว่าเราต้องการนับจำนวนกรณีที่จบลงด้วยการจับกุม
หากเราใช้พรอมต่อไปนี้:
Create an SQL query that counts the number of records that ended up with an arrest.
นี่คือผลลัพธ์จาก CHATGPT:
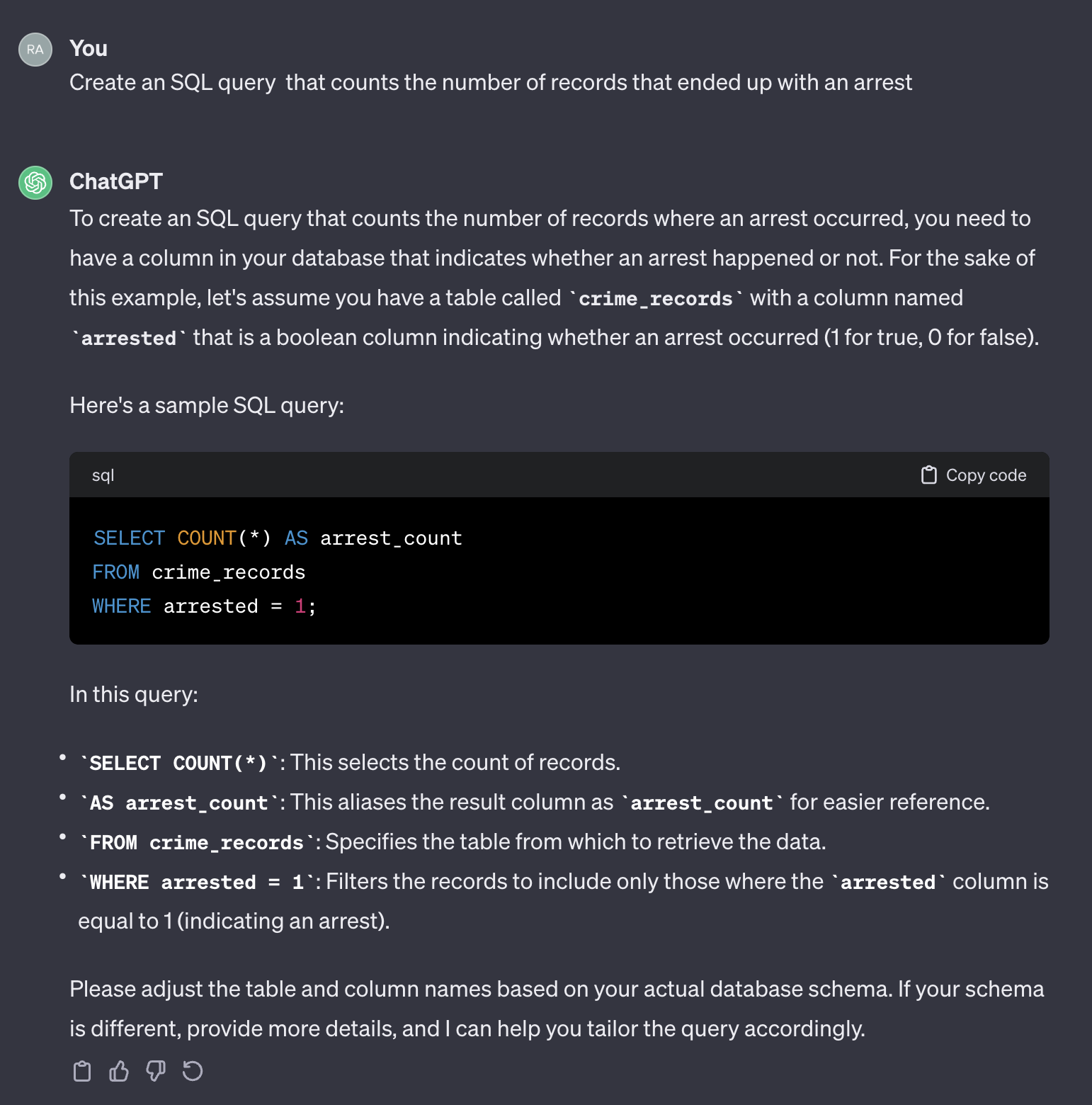
เป็นที่น่าสังเกตว่า CHATGPT ให้การตอบกลับทั่วไป แม้ว่าโดยทั่วไปจะถูกต้อง แต่ก็อาจไม่สามารถใช้งานได้ในกระบวนการอัตโนมัติ ประการแรกชื่อฟิลด์ในการตอบกลับไม่ตรงกับชื่อในตารางจริงที่เราต้องสอบถาม ประการที่สองฟิลด์ที่แสดงถึงผลลัพธ์การจับกุมคือบูลีน ( true หรือ false ) แทนที่จะเป็นจำนวนเต็ม ( 0 หรือ 1 )
ในแง่นั้นพูดว่าทำตัวเหมือนมนุษย์ ไม่น่าเป็นไปได้ที่คุณจะได้รับคำตอบที่แม่นยำยิ่งขึ้นจากมนุษย์โดยโพสต์คำถามเดียวกันในแบบฟอร์มการเข้ารหัสเช่นสแต็กล้นหรือแพลตฟอร์มอื่น ๆ ที่คล้ายกัน เนื่องจากเราไม่ได้ให้บริบทหรือข้อมูลเพิ่มเติมใด ๆ เกี่ยวกับลักษณะของตารางโดยคาดว่า Chatgpt จะคาดเดาชื่อฟิลด์และค่าของพวกเขาจะไม่มีเหตุผล บริบทเป็นปัจจัยสำคัญในพรอมต์ใด ๆ เพื่อแสดงให้เห็นถึงจุดนี้มาดูกันว่า CHATGPT จัดการพรอมต์ต่อไปนี้ได้อย่างไร:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
นี่คือผลลัพธ์จาก CHATGPT:
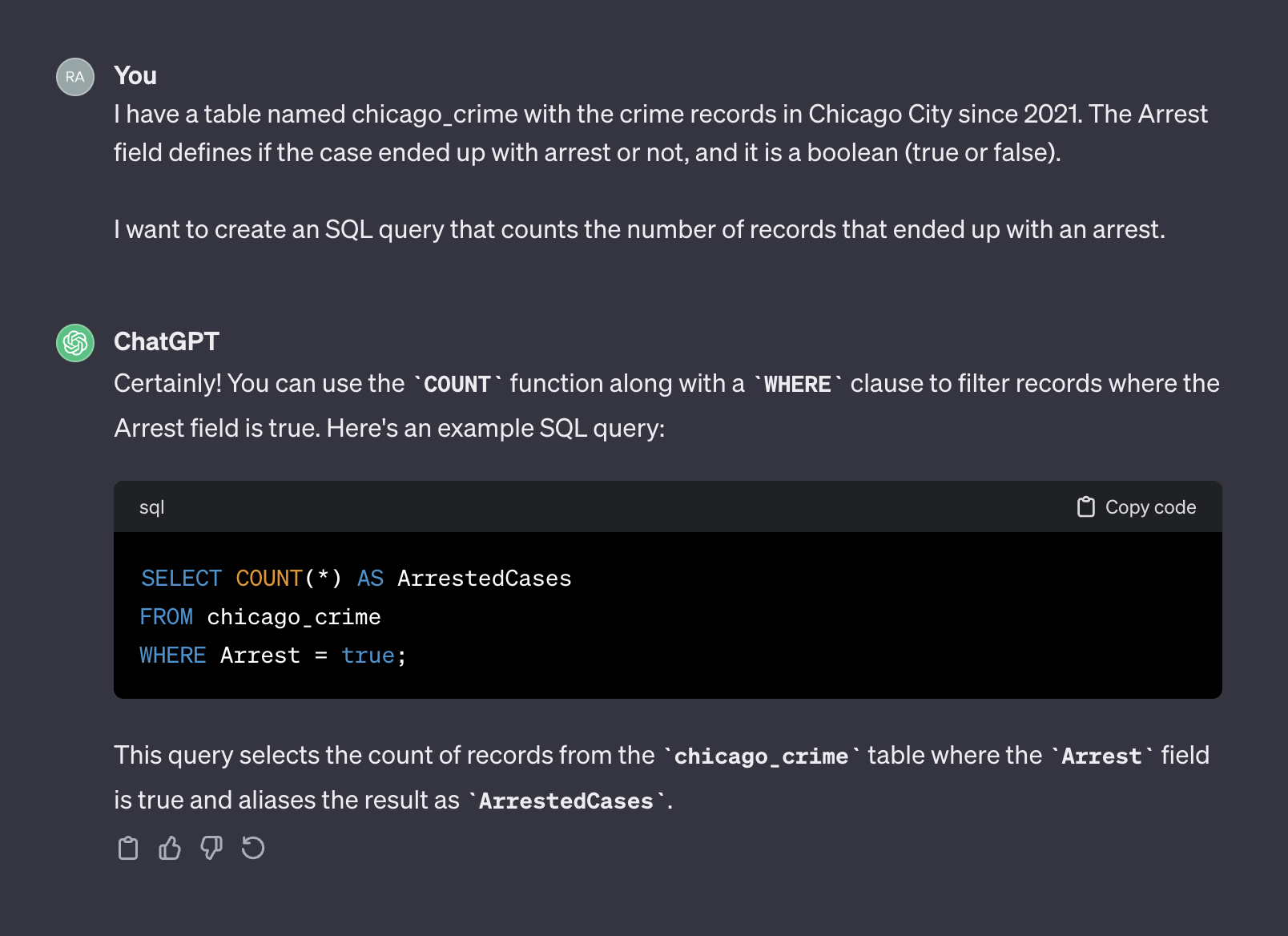
เวลานี้หลังจากเพิ่มบริบทแล้ว CHATGPT จะส่งกลับแบบสอบถามที่ถูกต้องที่เราสามารถใช้ได้ตามที่เป็นอยู่ โดยทั่วไปเมื่อทำงานกับเครื่องกำเนิดข้อความพรอมต์ควรมีสององค์ประกอบ - บริบทและคำขอ ในพรอมต์ข้างต้นย่อหน้าแรกแสดงถึงบริบทของพรอมต์:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
ในกรณีที่ย่อหน้าที่สองแสดงถึงคำขอ:
I want to create an SQL query that counts the number of records that ended up with an arrest.
OpenAI API หมายถึงบริบทเป็น system และขอเป็น user
เอกสาร OpenAI API ให้คำแนะนำสำหรับวิธีการตั้งค่า system และส่วนประกอบของ user ในพรอมต์เมื่อขอสร้างรหัส SQL:
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
ในส่วนถัดไปเราจะใช้ตัวอย่าง OpenAI ข้างต้นและสรุปให้เป็นเทมเพลตอเนกประสงค์ทั่วไป
ในส่วนก่อนหน้านี้เราได้กล่าวถึงความสำคัญของวิศวกรรมที่รวดเร็วและวิธีการให้บริบทที่ดีสามารถปรับปรุงความแม่นยำในการตอบสนองของ LLM ได้อย่างไร นอกจากนี้เรายังเห็นโครงสร้างพรอมต์ที่แนะนำ OpenAI สำหรับการสร้างรหัส SQL ในส่วนนี้เราจะมุ่งเน้นไปที่การสรุปกระบวนการสร้างพรอมต์สำหรับการสร้าง SQL ตามหลักการเหล่านั้น เป้าหมายคือการสร้างฟังก์ชั่น Python ที่ได้รับชื่อตารางและคำถามผู้ใช้และสร้างพรอมต์ตามลำดับ ตัวอย่างเช่นสำหรับตาราง Table chicago_crime ที่เราโหลดมาก่อนและคำถามที่เราถามในส่วนก่อนหน้าฟังก์ชั่นควรสร้างพรอมต์ด้านล่าง:
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
เริ่มต้นด้วยโครงสร้างที่รวดเร็ว เราจะนำรูปแบบ openai มาใช้และใช้เทมเพลตต่อไปนี้:
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" โดยที่ system_template ได้รับสององค์ประกอบ:
สำหรับบทช่วยสอนนี้เราจะใช้ไลบรารี Duckdb เพื่อจัดการกรอบข้อมูลของแพนด้าเนื่องจากเป็นตาราง SQL และแยกชื่อฟิลด์และแอตทริบิวต์ของตารางโดยใช้ฟังก์ชัน duckdb.sql ตัวอย่างเช่นลองใช้คำสั่ง SQL DESCRIBE เพื่อแยกข้อมูลฟิลด์ตาราง chicago_crime : ข้อมูล:
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )ซึ่งควรส่งคืนตารางด้านล่าง:
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘หมายเหตุ: ข้อมูลที่เราต้องการ - ชื่อคอลัมน์และแอตทริบิวต์ของมันมีอยู่ในสองคอลัมน์แรก ดังนั้นเราจะต้องแยกคอลัมน์เหล่านั้นและรวมเข้าด้วยกันกับรูปแบบต่อไปนี้:
Column_Name Column_Attribute
ตัวอย่างเช่นคอลัมน์ Case Number ควรถ่ายโอนไปยังรูปแบบต่อไปนี้:
Case Number VARCHAR
ฟังก์ชั่น create_message ด้านล่างแต่งกระบวนการของการใช้ชื่อตารางและคำถามและสร้างพรอมต์โดยใช้ตรรกะด้านบน:
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m ฟังก์ชั่นสร้างเทมเพลตพรอมต์และส่งคืน system พรอมต์และส่วนประกอบ user และชื่อคอลัมน์และแอตทริบิวต์ ตัวอย่างเช่นลองเรียกใช้จำนวนคำถามการจับกุม:
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )สิ่งนี้จะกลับมา:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object ผลลัพธ์ของฟังก์ชั่น create_message ได้รับการออกแบบมาเพื่อให้พอดีกับอาร์กิวเมนต์ฟังก์ชั่น OpenAI API ChatCompletion.create ซึ่งเราจะตรวจสอบในส่วนถัดไป
ส่วนนี้มุ่งเน้นไปที่ฟังก์ชั่นไลบรารี OpenAI Python ห้องสมุด OpenAI ช่วยให้สามารถเข้าถึง OpenAI REST API ได้อย่างราบรื่น เราจะใช้ไลบรารีเพื่อเชื่อมต่อกับ API และส่งคำขอรับด้วยพรอมต์ของเรา
เริ่มต้นด้วยการเชื่อมต่อกับ API โดยให้อาหาร API ของเราไปยังฟังก์ชัน openai.api_key :
openai . api_key = os . getenv ( 'OPENAI_KEY' ) หมายเหตุ: เราใช้ฟังก์ชั่น getenv จากไลบรารี os เพื่อโหลดตัวแปรสภาพแวดล้อม OpenAI_KEY หรือคุณสามารถป้อนคีย์ API ของคุณโดยตรง:
openai . api_key = "YOUR_OPENAI_API_KEY"OpenAI API ให้การเข้าถึง LLM ที่หลากหลายด้วยฟังก์ชันที่แตกต่างกัน คุณสามารถใช้ฟังก์ชัน OpenAI.Model.List เพื่อรับรายการรุ่นที่มีอยู่:
openai . Model . list () ในการแปลงเป็นรูปแบบที่ดีคุณสามารถห่อมันในกรอบข้อมูล pandas :
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . headและควรคาดหวังผลลัพธ์ต่อไปนี้:
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
สำหรับกรณีการใช้งานของเราการสร้างข้อความเราจะใช้รุ่น gpt-3.5-turbo ซึ่งเป็นการปรับปรุงรุ่น GPT3 รุ่น gpt-3.5-turbo แสดงถึงชุดของรุ่นที่ได้รับการอัปเดตและโดยค่าเริ่มต้นหากไม่ได้ระบุรุ่นรุ่น API จะชี้ให้เห็นถึงการเปิดตัวที่เสถียรล่าสุด เมื่อสร้างบทช่วยสอนนี้รุ่น 3.5 เริ่มต้นคือ gpt-3.5-turbo-0613 โดยใช้โทเค็น 4,096 และได้รับการฝึกฝนด้วยข้อมูลจนถึงเดือนกันยายน 2564
ในการส่งคำขอ GET ด้วยพรอมต์ของเราเราจะใช้ฟังก์ชั่น ChatCompletion.create ฟังก์ชั่นมีข้อโต้แย้งมากมายและเราจะใช้สิ่งต่อไปนี้:
model - ID รุ่นที่จะใช้รายการทั้งหมดที่มีอยู่ที่นี่messages - รายการข้อความที่ประกอบด้วยการสนทนาจนถึงตอนนี้ (เช่นพรอมต์)temperature - จัดการการสุ่มหรือกำหนดระดับของเอาต์พุตกระบวนการโดยการตั้งค่าระดับอุณหภูมิการสุ่มตัวอย่าง ระดับอุณหภูมิยอมรับค่าระหว่าง 0 ถึง 2 เมื่อค่าอาร์กิวเมนต์สูงขึ้นเอาต์พุตจะสุ่มมากขึ้น ในทางกลับกันเมื่อค่าอาร์กิวเมนต์อยู่ใกล้กับ 0 เอาต์พุตจะกำหนดขึ้นได้มากขึ้น (ทำซ้ำได้)max_tokens - จำนวนโทเค็นสูงสุดที่จะสร้างในการเสร็จสิ้นรายการทั้งหมดของอาร์กิวเมนต์ฟังก์ชั่นที่มีอยู่ใน API DocumentaIton
ในตัวอย่างด้านล่างเราจะใช้พรอมต์เดียวกับที่ใช้ในเว็บอินเตอร์เฟส ChatGPT (เช่นรูปที่ 5) คราวนี้ใช้ API เราจะสร้างพรอมต์ด้วยฟังก์ชั่น create_message :
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) ลองแปลงพรอมต์ข้างต้นเป็นโครงสร้างของ ChatCompletion.create messages ฟังก์ชั่นอาร์กิวเมนต์:
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] ต่อไปเราจะส่งพรอมต์ (เช่นวัตถุ message ) ไปยัง API โดยใช้ฟังก์ชั่น ChatCompletion.create :
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) เราจะตั้งค่าอาร์กิวเมนต์ temperature เป็น 0 เพื่อให้แน่ใจว่าการทำซ้ำสูงและ จำกัด จำนวนโทเค็นในการทำให้ข้อความเสร็จสมบูรณ์เป็น 256 ฟังก์ชั่นส่งคืนวัตถุ JSON ด้วยการทำให้ข้อความเสร็จสิ้นข้อมูลเมตาและข้อมูลอื่น ๆ :
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}การใช้การตอบสนองของ Indies เราสามารถสกัดแบบสอบถาม SQL:
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' ใช้ฟังก์ชัน duckdb.sql เพื่อเรียกใช้รหัส SQL:
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘ในส่วนถัดไปเราจะสรุปและใช้งานได้ทุกขั้นตอน
ในส่วนก่อนหน้านี้เราแนะนำรูปแบบพรอมต์ตั้งค่าฟังก์ชั่น create_message และตรวจสอบฟังก์ชั่นของฟังก์ชัน ChatCompletion.create ในส่วนนี้เราเย็บมันทั้งหมดเข้าด้วยกัน
สิ่งหนึ่งที่ควรทราบเกี่ยวกับรหัส SQL ที่ส่งคืนจากฟังก์ชั่น ChatCompletion.create คือตัวแปรไม่ได้กลับมาพร้อมกับราคา นั่นอาจเป็นปัญหาเมื่อชื่อตัวแปรในแบบสอบถามรวมสองคำขึ้นไป ตัวอย่างเช่นการใช้ตัวแปรเช่น Case Number หรือ Primary Type จาก chicago_crime ภายในแบบสอบถามโดยไม่ต้องใช้เครื่องหมายคำพูดจะส่งผลให้เกิดข้อผิดพลาด
เราจะใช้ฟังก์ชั่นผู้ช่วยด้านล่างเพื่อเพิ่มราคาลงในตัวแปรในแบบสอบถามหากแบบสอบถามที่ส่งคืนไม่มี:
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) อินพุตฟังก์ชั่นคือการสืบค้นและชื่อคอลัมน์ของตารางที่สอดคล้องกัน มันวนซ้ำชื่อคอลัมน์และเพิ่มเครื่องหมายคำพูดหากพบการจับคู่ภายในแบบสอบถาม ตัวอย่างเช่นเราสามารถเรียกใช้กับ SQL Query ที่เราแยกวิเคราะห์จาก ChatCompletion.create function output:
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' คุณสามารถสังเกตได้ว่ามันเพิ่มราคาลงในตัวแปร Arrest
ตอนนี้เราสามารถแนะนำฟังก์ชั่น lang2sql ที่ใช้ประโยชน์จากฟังก์ชั่นทั้งสามที่เราแนะนำจนถึงตอนนี้ - create_message , ChatCompletion.create และ add_quotes เพื่อแปลคำถามผู้ใช้เป็นรหัส SQL:
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output ฟังก์ชั่นได้รับเป็นอินพุตคีย์ OpenAI API ชื่อตารางและพารามิเตอร์หลักของฟังก์ชั่น ChatCompletion.create และส่งคืนวัตถุด้วยพรอมต์การตอบสนอง API และแบบสอบถามที่แยกวิเคราะห์ ตัวอย่างเช่นลองเรียกใช้แบบสอบถามเดียวกันกับที่เราใช้ในส่วนก่อนหน้าด้วยฟังก์ชัน lang2sql :
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )เราสามารถแยกสืบค้น SQL ออกจากวัตถุเอาต์พุต:
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;เราสามารถทดสอบผลลัพธ์ที่เกี่ยวข้องกับผลลัพธ์ที่เราได้รับในส่วนก่อนหน้า:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘ตอนนี้ขอเพิ่มความซับซ้อนเพิ่มเติมให้กับคำถามและขอกรณีที่จบลงด้วยการจับกุมในช่วงปี 2565:
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) อย่างที่คุณเห็นโมเดลระบุฟิลด์ที่เกี่ยวข้องอย่างถูกต้องเป็น Year และสร้างแบบสอบถามที่ถูกต้อง:
print ( response . sql )รหัส SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;การทดสอบแบบสอบถามในตาราง:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘นี่คือตัวอย่างของคำถามง่ายๆที่ต้องมีการจัดกลุ่มโดยตัวแปรเฉพาะ:
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )คุณสามารถดูได้จากผลลัพธ์การตอบกลับที่รหัส SQL ในกรณีนี้ถูกต้อง:
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "นี่คือผลลัพธ์ของแบบสอบถาม:
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘สุดท้าย แต่ไม่ท้ายสุด LLM สามารถระบุบริบท (เช่นตัวแปรใด) แม้ว่าเราจะให้ชื่อตัวแปรบางส่วน:
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )มันส่งคืนรหัส SQL ด้านล่าง:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;นี่คือผลลัพธ์ของแบบสอบถาม:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘ในบทช่วยสอนนี้เราได้สาธิตวิธีการสร้างเครื่องกำเนิดรหัส SQL ด้วยรหัส Python สองสามบรรทัดและใช้ OpenAI API เราได้เห็นแล้วว่าคุณภาพของพรอมต์เป็นสิ่งสำคัญสำหรับความสำเร็จของรหัส SQL ที่เกิดขึ้น นอกเหนือจากบริบทที่ได้รับจากพรอมต์ชื่อฟิลด์ควรให้ข้อมูลเกี่ยวกับลักษณะของฟิลด์เพื่อช่วย LLM ระบุความเกี่ยวข้องของฟิลด์กับคำถามผู้ใช้
แม้ว่าบทช่วยสอนนี้ถูก จำกัด ให้ทำงานกับตารางเดียว (เช่นไม่มีการรวมระหว่างตาราง) LLM บางตัวเช่นที่มีอยู่ใน OpenAI สามารถจัดการกรณีที่ซับซ้อนมากขึ้นรวมถึงการทำงานกับหลายตารางและระบุการดำเนินการเข้าร่วมที่ถูกต้อง การปรับฟังก์ชั่น Lang2SQL เพื่อจัดการหลายตารางอาจเป็นขั้นตอนต่อไปที่ดี
บทช่วยสอนนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต International Creative Commons-Noncommercial-Shareike 4.0


