super json mode
1.0.0
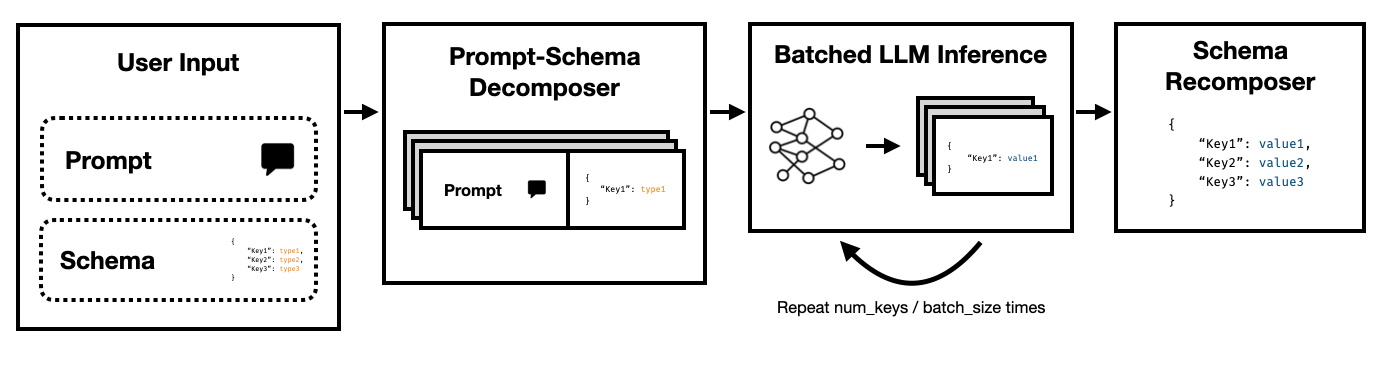
Super JSON Mode เป็นเฟรมเวิร์ก Python ที่ช่วยให้การสร้างเอาต์พุตที่มีโครงสร้างอย่างมีประสิทธิภาพจาก LLM โดยการแยกสคีมาเป้าหมายเป็นส่วนประกอบอะตอมแล้วทำการรุ่นในแบบคู่ขนาน
รองรับทั้ง State of the Art LLMs ผ่าน API ของ OpenAI ที่สมบูรณ์และ Open Source LLM เช่นผ่าน การกอด Transformers และ VLLM LLMS จะได้รับการสนับสนุนเพิ่มเติมในไม่ช้า!
เมื่อเทียบกับท่อส่ง JSON ที่ไร้เดียงสาอาศัยการแจ้งเตือนและหม้อแปลง HF เราพบว่าโหมด Super JSON สามารถสร้างผลลัพธ์ ได้เร็วถึง 10 เท่า นอกจากนี้ยังมีความมุ่งมั่นมากขึ้นและมีโอกาสน้อยที่จะพบปัญหาการแยกวิเคราะห์เมื่อเปรียบเทียบกับการสร้างที่ไร้เดียงสา
การติดตั้งง่าย: pip install super-json-mode
รูปแบบเอาต์พุตที่มีโครงสร้างเช่น JSON หรือ YAML มีโครงสร้างแบบขนานหรือลำดับชั้นโดยธรรมชาติ
พิจารณาข้อความที่ไม่มีโครงสร้างต่อไปนี้ (สร้างโดย GPT-4):
ยินดีต้อนรับสู่ 123 Azure Lane ที่พักที่สวยงามในซานฟรานซิสโกซึ่งมีการออกแบบร่วมสมัยที่ยอดเยี่ยมตอนนี้อยู่ในตลาดราคา $ 2,500,000 กระจายไปทั่ว 3,000 ตารางฟุตที่หรูหราสถานที่ให้บริการนี้รวมความซับซ้อนและความสะดวกสบายเพื่อสร้างประสบการณ์การใช้ชีวิตที่ไม่เหมือนใครอย่างแท้จริง
บ้านที่งดงามสำหรับครอบครัวหรือมืออาชีพที่อยู่อาศัยพิเศษของเรามีห้องนอนกว้างขวางห้าห้องแต่ละห้องนอนที่อบอุ่นและความสง่างามที่ทันสมัย ห้องนอนมีการวางแผนอย่างรอบคอบเพื่อให้แสงธรรมชาติและพื้นที่จัดเก็บที่กว้างขวาง ด้วยห้องน้ำเต็มรูปแบบที่ได้รับการออกแบบอย่างหรูหราสามห้องที่พักรับประกันความสะดวกสบายและความเป็นส่วนตัวสำหรับผู้อยู่อาศัย
ทางเข้าที่ยิ่งใหญ่นำคุณไปสู่พื้นที่นั่งเล่นที่กว้างขวางซึ่งให้บรรยากาศที่ยอดเยี่ยมสำหรับการชุมนุมหรือยามเย็นที่เงียบสงบด้วยไฟ ห้องครัวของพ่อครัวรวมถึงเครื่องใช้ไฟฟ้าที่ทันสมัยตู้เก็บของที่กำหนดเองและเคาน์เตอร์หินแกรนิตที่สวยงามทำให้มันเป็นความฝันสำหรับทุกคนที่ชอบทำอาหาร
หากเราต้องการแยก address , square footage , number of bedrooms , number of bathrooms และ price โดยใช้ LLM เราสามารถขอให้แบบจำลองเติมสคีมาตามคำอธิบาย
สคีมาที่มีศักยภาพ (เช่นที่สร้างขึ้นจากวัตถุ pydantic) อาจมีลักษณะเช่นนี้:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
และผลลัพธ์ที่ถูกต้องอาจมีลักษณะเช่นนี้:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
วิธีการที่ชัดเจนคือการทำรังสคีมาตามความพร้อมและขอให้โมเดลเติมเต็มนี่เป็นวิธีที่ทีมส่วนใหญ่แยกเอาต์พุตที่มีโครงสร้างจากข้อความที่ไม่มีโครงสร้างโดยใช้ LLMS
อย่างไรก็ตามสิ่งนี้ไม่มีประสิทธิภาพด้วยเหตุผลสามประการ
สังเกตว่าแต่ละปุ่มเหล่านี้เป็นอิสระจากกันอย่างไร โหมด Super JSON ใช้ประโยชน์จาก การขนานกันอย่างรวดเร็ว โดยการรักษาคู่คีย์-ค่าทุกคู่ในสคีมาเป็นคำถามแยกต่างหาก ตัวอย่างเช่นเราสามารถแยก num_baths โดยไม่ต้องสร้าง address แล้ว!
การร้องขอแบบจำลองเพื่อสร้าง JSON ตั้งแต่เริ่มต้นใช้โทเค็น (และเวลาก่อนหน้า) โดยไม่จำเป็นสำหรับไวยากรณ์ที่คาดการณ์ได้เช่นชื่อวงเล็บปีกกาและคีย์ซึ่งคาดว่าจะเกิดขึ้นในเอาท์พุทแล้ว นี่เป็นสิ่งที่แข็งแกร่งก่อนหน้านี้ในรุ่นที่เราควรจะสามารถใช้เพื่อปรับปรุงเวลาแฝง
LLMS นั้นขนานกันอย่างน่าอายและการสืบค้นในแบทช์นั้นเร็วกว่าลำดับ ดังนั้นเราสามารถแยกสคีมาผ่านการสืบค้นหลายครั้ง LLM จะเติมสคีมาสำหรับแต่ละคีย์อิสระ ในแบบขนาน และปล่อยโทเค็นน้อยลงในการผ่านครั้งเดียวทำให้เวลาการอนุมานเร็วขึ้นมาก
เรียกใช้คำสั่งต่อไปนี้:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
เราได้พยายามทำให้โหมด Super JSON ใช้งานง่ายมาก ดูโฟลเดอร์ examples สำหรับตัวอย่างเพิ่มเติมและการใช้ vLLM
ใช้ OpenAI และ gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }การใช้ Mistral 7B กับ HuggingFace Transformers:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } มีคุณสมบัติมากมายที่สามารถทำให้โหมด Super JSON ดีขึ้น นี่คือแนวคิดบางอย่าง
การวิเคราะห์ผลลัพธ์เชิงคุณภาพ : เราใช้มาตรฐานประสิทธิภาพ แต่เราควรหาวิธีที่เข้มงวดมากขึ้นในการตัดสินผลลัพธ์เชิงคุณภาพของโหมด Super JSON
การสุ่มตัวอย่างที่มีโครงสร้าง : เป็นการดีที่เราควรปกปิดบันทึกของ LLM เพื่อบังคับใช้ข้อ จำกัด ประเภทคล้ายกับ JSONFORMER มีแพ็คเกจสองสามอย่างที่ทำอยู่แล้วและทั้งสองอย่างควรรวมท่อส่ง JSON แบบขนานของเราหรือเราควรสร้างมันออกมาเป็นโหมด Super JSON
การสนับสนุนกราฟการพึ่งพา : โหมด Super JSON มีกรณีความล้มเหลวที่ชัดเจนมาก: เมื่อคีย์มีการพึ่งพาคีย์อื่น พิจารณาหยด json ที่มีสองปุ่ม thought และ response เอาท์พุทที่ต้องการแบบนี้เป็นเรื่องธรรมดาสำหรับการใช้โซ่ของแบบจำลองภาษาขนาดใหญ่และเป็นที่ชัดเจนว่า response นั้นขึ้นอยู่กับ thought เราควรจะสามารถส่งผ่านกราฟของการพึ่งพาและการแจ้งเตือนแบทช์ในลักษณะที่เอาต์พุตของผู้ปกครองจะเสร็จสมบูรณ์และส่งผ่านไปยังรายการสคีมาเด็ก
การสนับสนุนโมเดลท้องถิ่น : โหมด Super JSON ทำงานได้ดีที่สุดในสถานการณ์ท้องถิ่นโดยทั่วไปขนาดแบทช์โดยทั่วไป 1 คุณสามารถใช้ประโยชน์จากการแบตช์เพื่อลดเวลาแฝงคล้ายกับการถอดรหัสแบบเก็งกำไร llama.cpp เป็นเฟรมเวิร์กชั้นนำสำหรับโมเดลท้องถิ่น + การอนุมาน CPU ฉันชอบที่จะใช้สิ่งนี้โดยใช้ Ollama ถ้าเป็นไปได้
การสนับสนุน TRT-LLM : VLLM นั้นยอดเยี่ยมและใช้งานง่าย แต่เราก็รวมเข้ากับกรอบการทำงานที่มีประสิทธิภาพมากกว่าเช่น TRT-LLM
เราขอขอบคุณถ้าคุณโปรดอ้างอิง repo นี้หากคุณพบว่าห้องสมุดมีประโยชน์สำหรับงานของคุณ:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
โครงการนี้ถูกสร้างขึ้นสำหรับ CS 229: ระบบสำหรับการเรียนรู้ของเครื่อง ขอบคุณมากสำหรับทีมการสอนและ TAs สำหรับคำแนะนำของพวกเขาตลอดโครงการนี้


