visual chatgpt
1.0.0
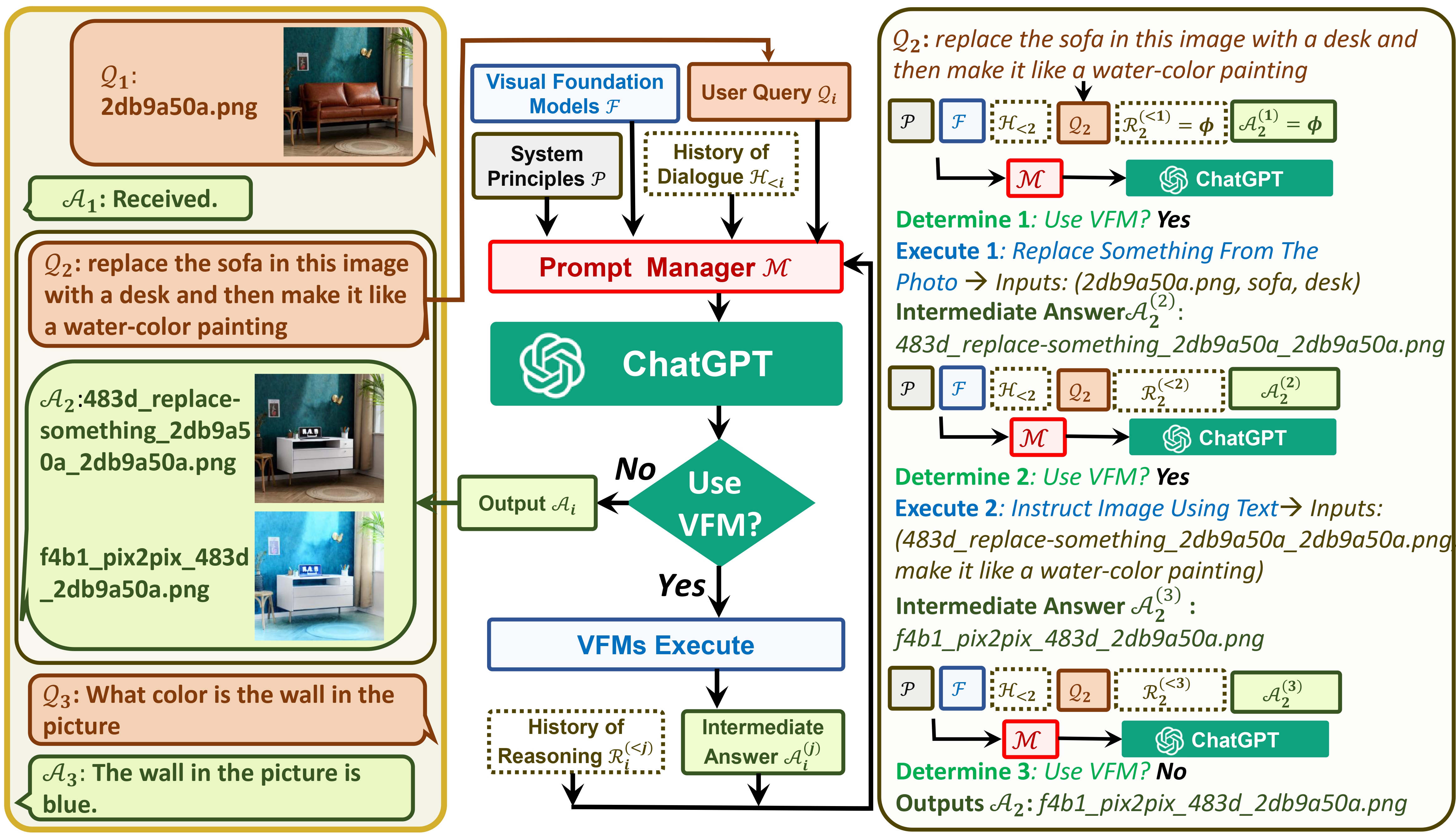
Visual ChatGPT连接 ChatGPT 和一系列 Visual Foundation 模型,以实现在聊天期间发送和接收图像。
请参阅我们的论文:Visual ChatGPT:使用 Visual Foundation 模型进行对话、绘图和编辑
一方面, ChatGPT(或 LLM)充当通用界面,提供对广泛主题的广泛且多样化的理解。另一方面,基础模型通过提供特定领域的深入知识来充当领域专家。通过利用一般知识和深层知识,我们的目标是构建一个能够处理各种任务的人工智能。

# clone the repo
git clone https://github.com/microsoft/visual-chatgpt.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start Visual ChatGPT !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are sperated by underline '_', the different models are seperated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
这里我们列出了每个 Visual Foundation 模型的 GPU 内存使用情况,您可以指定您喜欢哪一个:
| 基础模型 | GPU 内存 (MB) |
|---|---|
| 图像编辑 | 3981 |
| 指导Pix2Pix | 2827 |
| 文字转图像 | 3385 |
| 图像字幕 | 1209 |
| 图像2Canny | 0 |
| CannyText2Image | 3531 |
| 图像2线 | 0 |
| 行文字转图像 | 3529 |
| 图像2Hed | 0 |
| HedText2Image | 3529 |
| 图像2涂鸦 | 0 |
| 涂鸦文字转图像 | 3531 |
| 图像2姿势 | 0 |
| 姿势文本2图像 | 3529 |
| 图像2段 | 919 |
| 分段文本2图像 | 3529 |
| 图像2深度 | 0 |
| 深度文本2图像 | 3531 |
| 图像2法线 | 0 |
| 普通文本转图像 | 3529 |
| 视觉问答 | 1495 |
我们赞赏以下项目的开源:
拥抱脸 LangChain 稳定扩散 ControlNet InstructPix2Pix CLIPSeg BLIP
如需使用 Visual ChatGPT 的帮助或问题,请提交 GitHub 问题。
如需其他沟通,请联系 Chenfei WU ([email protected]) 或 Nan DUAN ([email protected])。


