Awesome Attention Heads
vey on LLM attention heads
重要的
关于这个仓库。这是一个获取不同类型法学硕士注意力头最新研究的平台。此外,我们还发布了基于这些精彩作品的调查。
如果您想引用我们的工作,这里是我们的 bibtex 条目:CITATION.bib。
如果您只想查看相关论文列表,请直接跳至此处。
如果您想为此存储库做出贡献,请参阅此处。
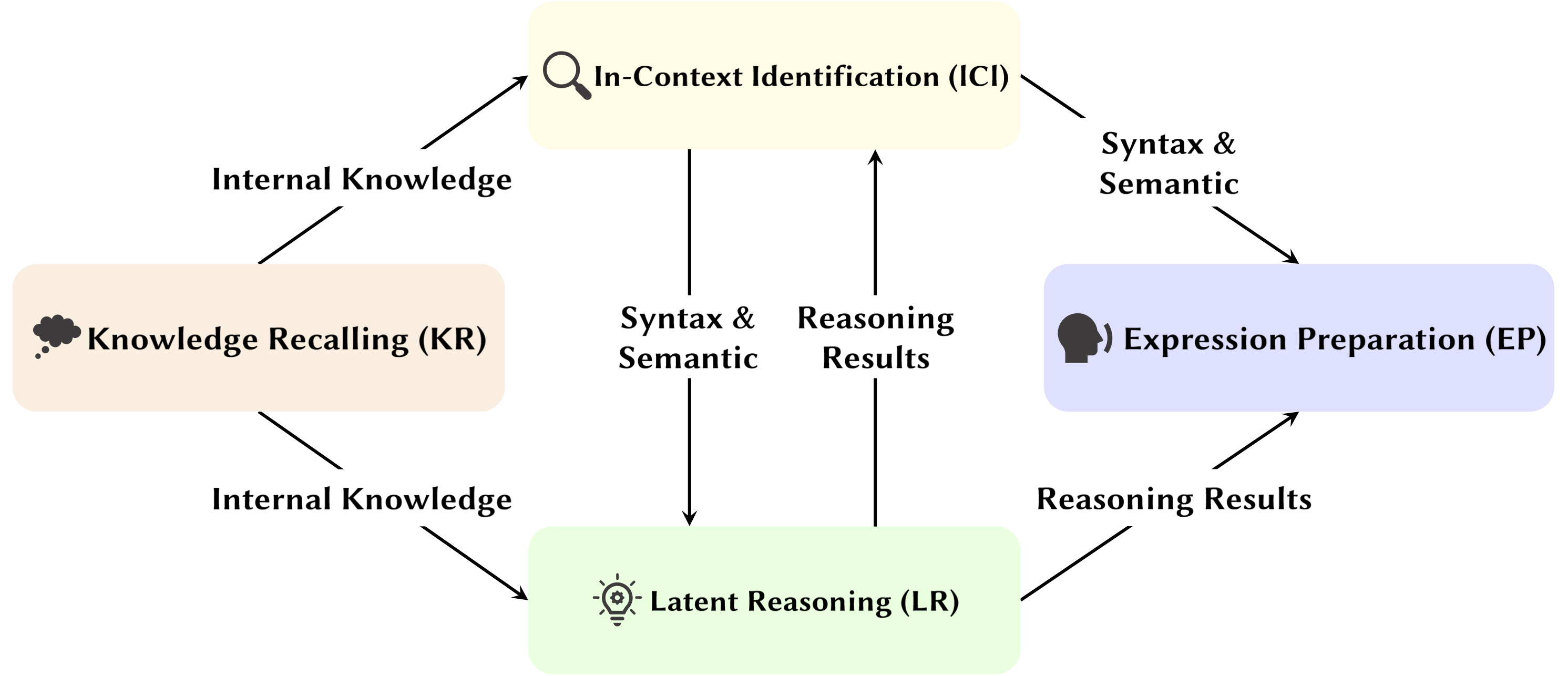
随着大型语言模型(LLM)的发展,其底层网络结构Transformer正在被广泛研究。研究Transformer结构有助于我们增强对这个“黑匣子”的理解,提高模型的可解释性。最近,越来越多的工作表明该模型包含两个不同的部分:用于行为、推理和分析的注意力机制,以及用于知识存储的前馈网络(FFN)。前者对于揭示模型的功能能力至关重要,从而引发了一系列探索注意力机制内各种功能的研究,我们将其称为“注意力头挖掘” 。
在这项调查中,我们深入研究了法学硕士注意力头如何促进推理过程的潜在机制。
亮点:
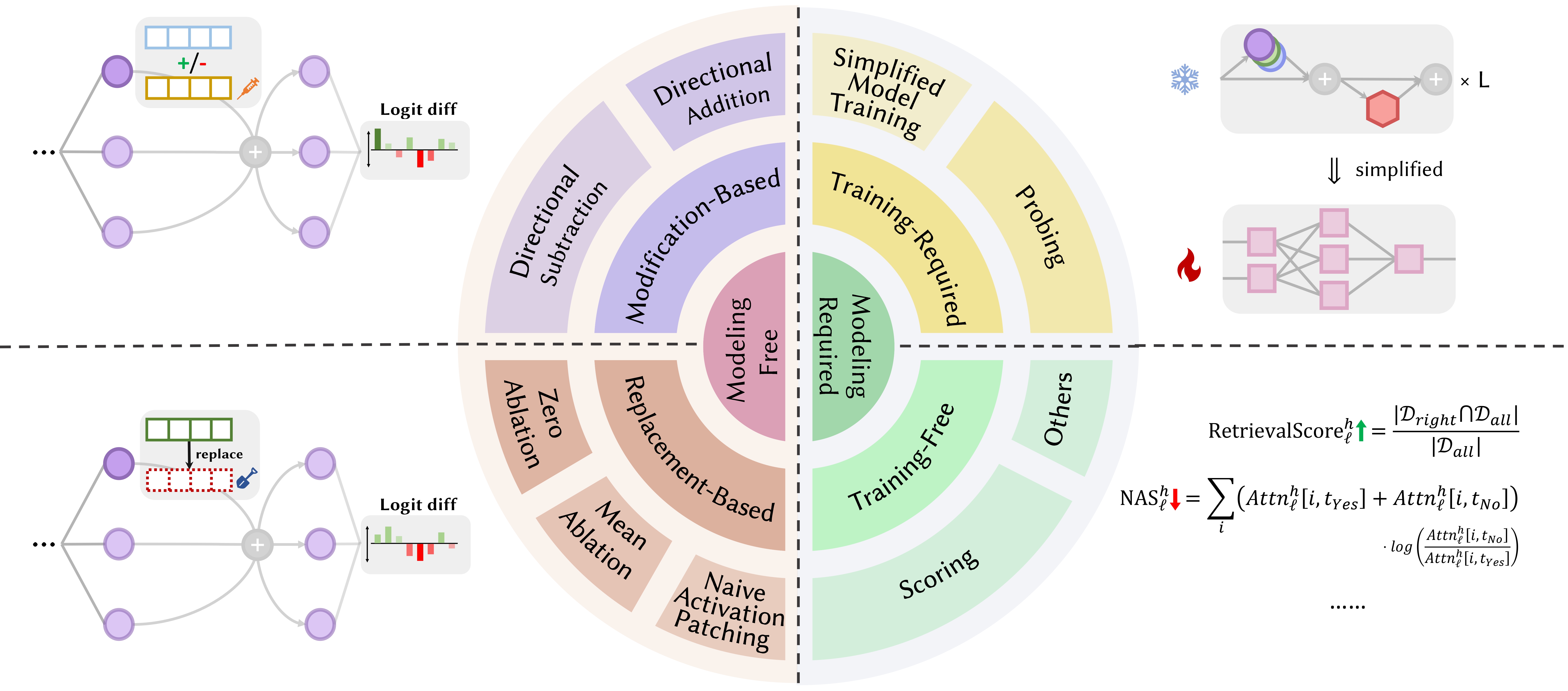
以下论文按发表日期排序:
2024年
| 日期 | 论文及摘要 | 标签 | 链接 |
| 2024-11-15 | SEEKR:选择性注意引导的知识保留,用于大型语言模型的持续学习 | ||
| • 提出SEEKR,一种用于法学硕士持续学习的选择性注意力引导知识保留方法,重点关注关键注意力头以实现高效提炼。 • 根据持续学习基准TRACE 和SuperNI 进行评估。 • 与其他方法相比,SEEKR 仅用 1% 的重放数据即可实现相当或更好的性能。 | |||
| 2024-11-06 | Transformers 如何解决命题逻辑问题:机械分析 | ||
| • 识别解决命题逻辑问题的变压器中的特定注意电路,重点关注“规划”和“推理”机制。 • 分析小型变压器和Mistral-7B,使用激活修补来揭示推理路径。 • 找到专门从事规则定位、事实处理和逻辑推理决策的独特注意力头。 | |||
| 2024-11-01 | 注意力跟踪器:检测法学硕士中的即时注入攻击 | ||
| • 提议的注意力跟踪器,一种简单而有效的免培训防护,可根据已识别的重要头检测即时注入攻击。 • 仅使用一小组LLM 生成的随机句子并结合天真的忽略攻击来识别重要的头部。 • 注意力跟踪器对小型和大型 LM 都有效,解决了以前免训练检测方法的重大限制。 | |||
| 2024-10-28 | 没有算法的算术:语言模型通过启发式方法解决数学问题 | ||
| • 确定模型的一个子集(电路),用于解释基本算术逻辑的大部分模型行为并检查其功能。 • 使用阿拉伯数字和四个基本运算符(+、−、×、÷)的双操作数算术提示分析注意力模式。 • 对于加法、减法和除法,6 个注意力头可产生高忠实度(平均 97%),而乘法则需要 20 个注意力头才能超过 90% 的忠实度。 | |||
| 2024-10-21 | 语言模型对论证角色敏感性的心理语言学评估 | ||
| • 在更普遍的环境中观察主题头部。 • 分析了交换参数和替换参数条件下的注意力模式。 • 尽管能够区分角色,但模型可能很难正确使用参数角色信息,因为问题在于如何将这些信息编码为动词表示,从而导致角色敏感性较弱。 | |||
| 2024-10-17 | 活跃-休眠注意力头:机械地揭秘法学硕士中的极端令牌现象 | ||
| • 证明极端标记现象是由注意头中的活跃-休眠机制以及预训练期间的相互强化机制引起的。 • 使用在Biggram-Backcopy (BB) 任务上训练的简单变压器来分析极端标记现象并将其扩展到预先训练的LLM。 • BB 任务预测的极端标记现象的许多静态和动态特性与预训练的LLM 中的观察结果一致。 | |||
| 2024-10-17 | 论注意力头在大语言模型安全中的作用 | ||
| • 提出了一种专为多头注意力而设计的新颖指标,即安全头重要得分(船舶),以评估各个头对模型安全性的贡献。 • 对这些安全注意头的功能进行分析,探索其特征和机制。 • 某些注意力头对于安全至关重要,安全头在经过微调的模型中重叠,并且消除这些头对帮助的影响最小。 | |||
| 2024-10-14 | DuoAttention:具有检索和流处理头的高效长上下文 LLM 推理 | ||
| • 引入了DuoAttention,这是一个基于LLM 中检索头和流头的发现的框架,可减少LLM 的解码和预填充内存以及延迟,同时又不影响其长上下文能力。 • 测试框架对LLM 在短上下文和长上下文任务中的表现及其推理效率的影响。 • 通过仅将完整的KV 缓存应用于检索头,DuoAttention 显着减少了长上下文应用程序中解码和预填充的内存使用量和延迟。 | |||
| 2024-10-14 | 锁定微调法学硕士的安全 | ||
| • 推出了SafetyLock,这是一种新颖且有效的方法,基于LLM 中安全头的发现,用于在各种风险级别和攻击场景中维护经过微调的大型语言模型的安全性。 • 评估SafetyLock 在增强模型安全性和推理效率方面的有效性。 • 通过将干预向量应用于安全头,SafetyLock 可以在推理过程中将模型的内部激活修改为无害,从而实现精确的安全调整,同时将对响应的影响降至最低。 | |||
| 2024-10-11 | 相同但不同:多语言语言建模的结构异同 | ||
| • 对多语言模型在执行需要特定语言形态过程的任务时所依赖的特定组件进行了深入研究。 • 研究执行英文和中文任务时内部模型组件的功能差异。 • 仿形中心词在两种语言中都有相似的高激活频率,而过去时中心词仅在英语中频繁激活。 | |||
| 2024-10-08 | 我们一圈又一圈地走!旋转位置编码有何用处? | ||
| • 对经过训练的Gemma 7B 模型的内部结构进行了深入分析,以了解如何在机械层面使用RoPE。 • 了解查询和键中不同频率的用法。 • 发现Gemma 7B 巧妙地使用RoPE 中的最高频率来构建特殊的“位置”注意头(对角线头、前记号头),而低频则由撇号头使用。 | |||
| 2024-10-06 | 重新审视大型语言模型中的上下文学习推理电路 | ||
| • 提出了一个全面的三步推理电路来表征ICL 的推理过程。 • 将ICL分为三个阶段:Summarize、Semantics Merge、Feature Retrieval and Copy,分析各个阶段在ICL中的作用及其运行机制。 • 发现在归纳头之前,先行者令牌头首先将先行者令牌中的演示文本表示合并到其相应的标签令牌中,有选择地基于演示和标签语义之间的兼容性。 | |||
| 2024-10-01 | 稀疏注意力分解在电路追踪中的应用 | ||
| • 引入稀疏注意力分解,在注意力头矩阵上使用SVD 来跟踪GPT-2 模型中的通信路径。 • 适用于间接对象识别(IOI) 任务的GPT-2 小电路跟踪。 • 识别注意力头之间稀疏的、功能上重要的通信信号,提高可解释性。 | |||
| 2024-09-09 | 揭晓感应头:变压器中可证明的训练动力学和特征学习 | ||
| • 本文介绍了一种广义感应头机制,解释了变压器组件如何协作在n-gram 马尔可夫链上执行上下文学习(ICL)。 • 它分析具有梯度流的两个注意力层变压器,以预测马尔可夫链中的标记。 • 梯度流收敛,通过基于学习特征的感应头机制实现 ICL。 | |||
| 2024-08-16 | 自回归语言模型中三段论推理的机械解释 | ||
| • 该研究引入了语言模型中三段论推理的机械解释,确定了与内容无关的推理电路。 • 用于推理和调查注意力头中信念偏差污染的电路发现。 • 确定了可跨三段论方案转移的必要推理电路,但容易受到预先训练的世界知识的污染。 | |||
| 2024-08-01 | 通过模型编辑增强大型语言模型的语义一致性:一种面向可解释性的方法 | ||
| • 引入一种经济高效的模型编辑方法,重点关注注意力头,以增强法学硕士的语义一致性,而无需进行大量参数更改。 • 分析注意力头、注入偏差,并在 NLU 和 NLG 数据集上进行测试。 • 在语义一致性和任务性能方面取得显着改进,并具有跨其他任务的强大泛化能力。 | |||
| 2024-07-31 | 通过负注意力分数对齐来纠正大型语言模型中的负偏差 | ||
| • 引入负面注意力评分(NAS)来量化和纠正语言模型中的负面偏见。 • 识别出负向偏见的注意力头,并提出用于微调的负向注意力分数对齐(NASA)。 • NASA 有效地缩小了精确回忆差距,同时保留了二元决策任务的泛化能力。 | |||
| 2024-07-29 | 通过机械可解释性检测和理解语言模型中的漏洞 | ||
| • 介绍了一种使用机械可解释性(MI) 来检测和理解LLM 中的漏洞,特别是对抗性攻击的方法。 • 分析GPT-2 Small 在预测3 字母缩写词方面的漏洞。 • 成功识别并解释模型中与任务相关的特定漏洞。 | |||
| 2024-07-22 | RazorAttention:通过检索头进行高效的 KV 缓存压缩 | ||
| • 引入了RazorAttention,这是一种免训练的KV 缓存压缩技术,使用检索头和补偿令牌来保留关键令牌信息。 • 评估了大型语言模型(LLM) 上的RazorAttention 的效率。 • KV 缓存大小减少了 70% 以上,且没有明显的性能影响。 | |||
| 2024-07-21 | 回答、组装、王牌:了解变形金刚如何回答多项选择题 | ||
| • 本文介绍了词汇投影和激活修补来定位隐藏状态,从而预测正确的 MCQA 答案。 • 确定了变压器中负责答案选择的关键关注头和层。 • 中层注意力头对于准确的答案预测至关重要,一组稀疏的注意力头发挥着独特的作用。 | |||
| 2024-07-09 | 感应头作为情境学习中模式匹配的基本机制 | ||
| • 该文章指出感应头对于情境学习 (ICL) 中的模式匹配至关重要。 • 评估Llama-3-8B 和InternLM2-20B 的抽象模式识别和NLP 任务。 • 烧蚀感应头可将 ICL 性能降低高达约 32%,使其接近随机模式识别。 | |||
| 2024-07-02 | 通过比较神经元分析解释大型语言模型中的算术机制 | ||
| • 引入比较神经元分析(CNA)来映射大型语言模型注意力头中的算术机制。 • 分析算术能力、算术任务的模型修剪以及模型编辑以减少性别偏见。 • 识别负责算术的特定神经元,通过有针对性的神经元操作来提高性能并减轻偏差。 | |||
| 2024-07-01 | 引导大型语言模型进行跨语言信息检索 | ||
| • 引入激活引导多语言检索 (ASMR),使用引导激活来指导法学硕士改进跨语言信息检索。 • 确定法学硕士中影响准确性和语言连贯性的注意力头,并应用转向激活。 • ASMR 在 XOR-TyDi QA 和 MKQA 等 CLIR 基准测试中实现了最先进的性能。 | |||
| 2024-06-25 | Transformers 如何通过梯度下降学习因果结构 | ||
| • 解释了 Transformer 如何通过基于梯度的训练算法学习因果结构。 • 分析了两层变压器在称为具有因果结构的随机序列的任务中的性能。 • 简化的两层变压器上的梯度下降学习通过在第一个注意层中编码潜在因果图来解决此任务。作为一种特殊情况,当从上下文中的马尔可夫链生成序列时,变压器学会开发感应头。 | |||
| 2024-06-21 | MoA:用于自动大型语言模型压缩的稀疏注意力混合 | ||
| • 本文介绍了混合注意力(MoA),它为不同的头和层定制不同的稀疏注意力配置,优化内存、吞吐量和准确性-延迟权衡。 • MoA 分析模型、探索注意力配置并改进LLM 压缩。 • MoA 将有效上下文长度增加了 3.9 倍,同时将 GPU 内存使用量减少了 1.2-1.4 倍。 | |||
| 2024-06-19 | 论大型语言模型中忠实思维链推理的难度 | ||
| • 引入了上下文学习、微调和激活编辑的新颖策略,以提高法学硕士的思想链(CoT)推理可信度。 • 通过多个基准测试这些策略以评估其有效性。 • 发现在提高CoT 忠诚度方面只取得了有限的成功,突显了法学硕士实现真正忠实推理的挑战。 | |||
| 2024-06-04 | 迭代头:思想链的机制研究 | ||
| • 引入“迭代头”,这是一种专门的注意力头,可以在变压器中针对思想链(CoT) 任务进行迭代推理。 • 分析注意力机制、跟踪CoT 出现并测试CoT 技能在任务之间的可转移性。 • 迭代头有效支持CoT 推理,提高模型可解释性和任务性能。 | |||
| 2024-06-03 | LoFiT:LLM 表示的本地化微调 | ||
| • 引入了LLM 表示的本地化微调(LoFiT),这是一个两步框架,用于识别给定任务的重要注意头并学习特定于任务的偏移向量以干预已识别头的表示。 • 确定重要注意力头的稀疏集合,以提高下游真实性和推理的准确性。 • LoFiT 优于其他表示干预方法,并在 TruthfulQA、CLUTRR 和 MQuAKE 上取得了与 PEFT 方法相当的性能,尽管仅对法学硕士中总注意力头的 10% 进行干预。 | |||
| 2024-05-28 | 预训练 Transformer 中的知识电路 | ||
| • 在 Transformer 中引入了“知识电路”,揭示了如何通过注意力头、关系头和 MLP 之间的交互来编码特定知识。 • 分析GPT-2 和TinyLLAMA 以识别知识回路;评估知识编辑技术。 • 展示了知识回路如何促进幻觉和情境学习等模型行为。 | |||
| 2024-05-23 | 将变形金刚中的情境学习与人类情景记忆联系起来 | ||
| • 将Transformer 模型中的情境学习与人类情景记忆联系起来,突出归纳头与情境维护和检索(CMR) 模型之间的相似性。 • 分析基于Transformer 的LLM,以展示注意力头中类似CMR 的行为。 • 类似CMR 的头部出现在中间层,反映了人类的记忆偏差。 | |||
| 2024-05-07 | GPT-2 如何预测首字母缩略词?通过机械解释提取和理解电路 | ||
| • GPT-2 的首次机械可解释性研究,用于使用注意力头预测多标记首字母缩略词。 • 识别并解释负责首字母缩略词预测的8 个注意力头电路。 • 证明这8 个头(约占总数的5%)集中了首字母缩略词预测功能。 | |||
| 2024-05-02 | 解释和改进算术计算中的大型语言模型 | ||
| • 遵循“识别-分析-微调”流程,通过数学任务详细研究法学硕士的内部机制。 • 分析模型执行涉及两个操作数的算术任务的能力,例如加法、减法、乘法和除法。 • 发现法学硕士经常涉及一小部分(< 5%)的注意力头,这些注意力头在计算过程中关注操作数和运算符方面发挥着关键作用。 | |||
| 2024-05-02 | 感应头需要什么?情境学习回路及其形成的机制研究 | ||
| • 引入了受光遗传学启发的因果框架来研究变压器中感应头(IH) 的形成。 • 使用综合数据分析变压器中 IH 的出现,并确定导致 IH 形成的三个底层子电路。 • 发现这些子电路相互作用以驱动IH 形成,与模型损失的相变相一致。 | |||
| 2024-04-24 | 检索头机械地解释长上下文事实 | ||
| • 确定变压器模型中的“检索头”,负责跨长上下文检索信息。 • 对各种模型的检索头进行系统研究,包括分析它们在思想链推理中的作用。 • 修剪检索头会导致幻觉,而修剪非检索头不会影响检索能力。 | |||
| 2024-03-27 | 非线性推理时间干预:提高LLM的真实性 | ||
| • 引入非线性推理时间干预(NL-ITI),通过多标记探测和干预增强LLM 真实性,无需微调。 • 在多项选择数据集(包括TruthfulQA)上评估NL-ITI。 • 与基线ITI 相比,TruthfulQA 的MC1 准确度相对提高了16%。 | |||
| 2024-02-28 | 如何逐步思考:对思维链推理的机械理解 | ||
| • 从神经功能成分方面对法学硕士中CoT 介导的推理进行了深入分析。 • 对虚构推理进行基于 CoT 的剖析推理,将其视为由固定数量的子任务组成,需要决策、复制和归纳推理,并分别分析其机制。 • 发现注意力头在本体相关(或负相关)标记之间执行信息移动,从而产生这些标记对的明显可识别的表示。 | |||
| 2024-02-28 | 砍掉头部结束冲突:解释和缓解语言模型中知识冲突的机制 | ||
| • 引入PH3 方法来修剪冲突的注意力头,从而在无需更新参数的情况下减轻语言模型中的知识冲突。 • 应用PH3 来控制LM 对内部存储器与外部上下文的依赖,并测试其在开放域QA 任务中的有效性。 • PH3 将内部内存使用率提高了 44.0%,将外部上下文使用率提高了 38.5%。 | |||
| 2024-02-27 | 信息流路线:大规模自动解释语言模型 | ||
| • 引入“信息流路由”,使用归因来对语言模型进行基于图形的解释,从而避免激活修补。 • 使用 Llama 2 进行实验,识别不同领域和任务的关键注意力头和行为模式。 • 未发现的专用模型组件;确定了注意力头的一致角色,例如处理相同词性的标记。 | |||
| 2024-02-20 | 识别语义归纳头以理解情境学习 | ||
| • 识别并研究大语言模型(LLM)中与上下文学习能力相关的“语义归纳头”。 • 分析注意力头以编码句法依赖性和知识图关系。 • 某些注意力头通过回忆相关标记来增强输出逻辑,这对于理解法学硕士的情境学习至关重要。 | |||
| 2024-02-16 | 统计归纳头的演变:上下文学习马尔可夫链 | ||
| • 引入马尔可夫链序列建模任务来分析上下文学习(ICL) 功能如何在变压器中出现,形成“统计归纳头”。 • 变压器在马尔可夫链任务上的多阶段训练的实证和理论研究。 • 演示从一元模型到二元模型预测的相变,受变压器层相互作用的影响。 | |||
| 2024-02-11 | 总结事实:法学硕士事实回忆背后的附加机制 | ||
| • 识别并解释事实回忆中的“附加主题”,其中法学硕士使用多种独立机制建设性地干扰事实回忆。 • 扩展直接logit 归因来分析注意力头并解开混合头的行为。 • 证明法学硕士中的事实记忆是由多个独立的不足贡献的总和产生的。 | |||
| 2024-02-05 | 大型语言模型如何在上下文中学习?上下文头部的查询矩阵和关键矩阵是度量学习的两座塔 | ||
| • 引入上下文头中的查询矩阵和关键矩阵作为度量学习的“双塔”运行的概念,促进标签特征之间的相似性计算。 • 分析情境学习机制;确定了对 ICL 至关重要的特定注意力头。 • 通过仅对这些头部的 1% 进行干预,将 ICL 准确度从 87.6% 降低至 24.4%。 | |||
| 2024-01-23 | 情境语言学习:架构和算法 | ||
| • 引入“n-gram 头”,即专门的 Transformer 注意力头,通过输入条件标记预测增强上下文语言学习 (ICLL)。 • 评估来自随机有限自动机的常规语言的神经模型。 • 硬连线n-gram 头在SlimPajama 数据集上将困惑度提高了6.7%。 | |||
| 2024-01-16 | 上下文分类任务中数据依赖和突然学习的机制基础 | ||
| • 该论文通过仅注意网络中感应头的突然形成来模拟上下文学习(ICL)的机制基础。 • 使用简化的输入数据和基于注意力的两层网络模拟ICL 任务。 • 感应头的形成驱动了向ICL 的突然过渡,通过嵌套非线性进行追踪。 | |||
| 2024-01-16 | Transformer 语言模型中跨任务的电路组件重用 | ||
| • 该论文证明,GPT-2 中的特定电路可以泛化到不同的任务,挑战了此类电路是特定于任务的概念。 • 它检查彩色对象任务中间接对象识别(IOI) 任务中电路的重用。 • 调整四个注意力头可将彩色物体任务的准确度从 49.6% 提高到 93.7%。 | |||
| 2024-01-16 | 后继头:在野外反复出现、可解释的注意力头 | ||
| • 本文介绍了“后继头”,即法学硕士中的注意力头,它以自然顺序(如天或数字)增加标记。 • 它分析了各种模型大小和架构(例如GPT-2 和Llama-2)的后继头的形成。 • 后继头出现在从 31M 到 12B 参数的模型中,揭示了抽象的、重复出现的数字表示。 | |||
| 2024-01-16 | 大型语言模型中的函数向量 | ||
| • 本文介绍了“函数向量 (FV)”,即自回归变压器模型中任务的紧凑因果表示。 • FV 在不同的情境学习 (ICL) 任务、模型和层中进行了测试。 • FV 可以相加来创建触发新的复杂任务的向量,展示内部向量组成。 | |||
| 日期 | 论文及摘要 | 标签 | 链接 |
| 2023-12-23 | 事实调查:尝试在神经元水平上对事实回忆进行逆向工程 | ||
| • 研究Pythia 2.8B 中的早期MLP 层如何使用分布式电路对事实回忆进行编码,重点关注叠加和多标记嵌入。 • 探索MLP 层中的事实查找,测试关于去标记化和散列机制的假设。 • 事实回忆功能类似于分布式查找表,但没有易于解释的内部机制。 | |||
| 2023-11-07 | 迈向可解释的序列延续:分析大型语言模型中的共享电路 | ||
| • 证明了用于类似序列延续任务的共享电路的存在。 • 分析和比较类似序列延续任务的电路,其中包括阿拉伯数字、数字词和月份的递增序列。 • 语义相关的序列依赖于具有类似角色的共享电路子图以及在具有类似功能的模型中查找类似的子电路。 | |||
| 2023-10-23 | 大型语言模型中情感的线性表示 | ||
| • 该论文确定了激活空间中的线性方向,该方向捕获大型语言模型(LLM)中的情感表示。 • 他们隔离了这种情绪方向,并在包括斯坦福情绪树库在内的任务上对其进行了测试。 • 消除这种情绪方向会导致分类准确度下降 76%,凸显了其重要性。 | |||
| 2023-10-06 | 复制抑制:全面理解注意力头 | ||
| • 本文介绍了GPT-2小型注意力头(L10H7)中复制抑制的概念,这减少了天真的令牌复制,增强了模型校准。 • 本文研究并解释了复制抑制的机制及其在自我修复中的作用。 • GPT-2 Small 中L10H7 76.9% 的影响得到了解释,使其成为对注意力头角色最全面的描述。 | |||
| 2023-09-22 | 推理时间干预:从语言模型中得出真实答案 | ||
| • 引入推理时间干预(ITI),通过调整选定注意力头中的模型激活来增强LLM 的真实性。 • 改进了LLaMA 模型在TruthfulQA 基准上的性能。 • ITI 将羊驼模型的真实性从 32.5% 提高到 65.1%。 | |||
| 2023-09-22 | 变形金刚的诞生:记忆观点 | ||
| • 本文提出了基于记忆的变压器视角,强调了权重矩阵中的联想记忆及其梯度驱动的学习。 • 使用合成数据对简化变压器模型的训练动态进行实证分析。 • 发现快速全局二元组学习以及上下文二元组“归纳头”的较慢出现。 | |||
| 2023-09-13 | 损失突然下降:MLM 中的语法习得、相变和简单性偏差 | ||
| • 确定句法注意结构(SAS) 作为掩码语言模型(MLM) 中自然出现的属性及其在句法习得中的作用。 • 在训练期间分析SAS 并对其进行操作以研究其对语法能力的因果影响。 • SAS 对于语法开发是必要的,但短暂抑制它可以提高模型性能。 | |||
| 2023-07-18 | 电路分析的可解释性是否可扩展?来自龙猫多项选择能力的证据 | ||
| • 将可扩展电路分析应用于70B Chinchilla 语言模型,以理解多项选择题的回答。 • Logit 归因、注意力模式可视化和激活修补,以识别和分类关键注意力头。 • 在注意头中确定了“枚举中的第N 项”功能,尽管这只是部分解释。 | |||
| 2023-02-02 | 野外可解释性:GPT-2 Small 中的间接对象识别电路 | ||
| • 本文详细介绍了GPT-2小型如何使用涉及分为7类的28个注意力头的大型电路来执行间接对象识别(IOI)。 • 他们使用因果干预和预测对GPT-2小型中的IOI任务进行了逆向工程。 • 研究表明大型语言模型的机械解释是可行的。 | |||
| 日期 | 论文及摘要 | 标签 | 链接 |
| 2022-03-08 | 情境学习和归纳头 | ||
| • 该论文确定了 Transformer 模型中的“感应头”,它可以通过识别和复制序列中的模式来实现上下文学习。 • 分析不同Transformer 模型中各个层的注意力模式和感应头。 • 发现归纳头对于使 Transformer 能够有效地概括和执行情境学习任务至关重要。 | |||
| 2021-12-22 | 变压器电路的数学框架 | ||
| • 引入了一个数学框架来对小型仅注意力变压器进行逆向工程,重点是将注意力头理解为独立的附加组件。 • 分析零层、一层和两层转换器,以确定注意力头在信息移动和构成中的作用。 • 发现了“归纳头”,这对于两层变压器的上下文学习至关重要。 | |||
| 2021-05-18 | Heads 假设:理解 BERT 中多头注意力的统一统计方法 | ||
| • 本文提出了一种称为“稀疏注意力”的新方法,通过选择性地关注重要标记来降低注意力机制的计算复杂性。 • 该方法在机器翻译和文本分类任务上进行了评估。 • 稀疏注意力模型实现了与密集注意力相当的准确性,同时显着降低了计算成本。 | |||
| 2021-04-01 | BERT 中的注意力头学过选区语法吗? | ||
| • 该研究引入了句法距离方法来分析 BERT 和 RoBERTa 注意力头中的选区语法。 • 在SMS 和NLI 任务的微调前后提取和分析选区语法。 • NLI 任务提高了选区语法归纳能力,而 SMS 任务则降低了上层的能力。 | |||
| 2019-11-27 | BERT 中的注意力头是否跟踪句法依赖性? | ||
| • 本文研究了 BERT 中的各个注意力头是否捕获句法依赖关系,使用注意力权重来提取依赖关系。 • 使用最大注意力权重和最大生成树分析BERT 的注意力头,并将它们与通用依赖树进行比较。 • 一些注意力头比基线更好地跟踪特定的语法依赖关系,但没有一个头能够更好地执行整体解析。 | |||
| 2019-11-01 | 自适应稀疏变压器 | ||
| • 引入了使用 alpha-entmax 的自适应稀疏 Transformer,以允许注意头中灵活的、上下文相关的稀疏性。 • 应用于机器翻译数据集以评估可解释性和头部多样性。 • 在不影响准确性的情况下实现了多样化的注意力分布并提高了可解释性。 | |||
| 2019-08-01 | BERT 关注什么? BERT注意力分析 | ||
| • 本文介绍了分析 BERT 注意力机制的方法,揭示了与语法和共指等语言结构相一致的模式。 • 分析注意力头,识别句法和共指模式,以及开发基于注意力的探测分类器。 •Bert的注意力负责人捕获了大量的句法信息,尤其是在识别直接对象和核心方面的任务中。 | |||
| 2019-07-01 | 分析多头自我注意力:专业负责人进行繁重的举重,其余的可以修剪 | ||
| •本文引入了一种用于多头自我注意力的新型修剪方法,该方法有选择地去除重要的头部而没有重大绩效损失。 •分析个人注意力头,识别其专业角色以及在变压器模型上的修剪方法的应用。 •编码器中的48个头部中的38个修剪仅导致0.15 BLEU得分下降。 | |||
| 2018-11-01 | 基于变压器的机器翻译中编码器表示的分析 | ||
| •本文分析了变压器编码器层的内部表示,重点是自我注意力主管学到的句法和语义信息。 •探测任务,依赖关系提取和转移学习方案。 •下层捕获语法,而较高的图层编码更多的语义信息。 | |||
| 2016-03-21 | 将复制机制纳入顺序到序列学习 | ||
| •将复制机制引入序列到序列模型中,以直接复制输入令牌,从而改善了稀有单词的处理。 •应用于机器翻译和摘要任务。 •与标准序列到序列模型相比,翻译精度的实质性改善,尤其是在稀有单词翻译上。 | |||
问题模板:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


