SwiftInfer
1.0.0
Streaming-LLM是一种支持无限输入长度进行 LLM 推理的技术。它利用注意力池来防止注意力窗口转移时模型崩溃。原始工作是在 PyTorch 中实现的,我们提供SwiftInfer ,这是一个 TensorRT 实现,使 StreamingLLM 更具生产级。我们的实现基于最近发布的TensorRT-LLM项目。
我们使用TensorRT-LLM中的 API 来构建模型并运行推理。由于 TensorRT-LLM 的 API 不稳定且变化很快,我们将我们的实现与版本为v0.6.0的42af740db51d6f11442fd5509ef745a4c043ce51提交绑定。随着 TensorRT-LLM 的 API 变得更加稳定,我们可能会升级此存储库。
如果您已经构建了TensorRT-LLM V0.6.0 ,只需运行:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .否则,您应该先安装 TensorRT-LLM。
如果使用docker,可以按照TensorRT-LLM安装来安装TensorRT-LLM V0.6.0 。
通过使用 docker,您只需运行以下命令即可安装 SwiftInfer:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . 如果不使用 docker,我们提供了一个脚本来自动安装 TensorRT-LLM。
先决条件
请确保您已安装以下软件包:
确保 TensorRT >= 9.1.0 和 CUDA 工具包的版本 >= 12.2。
安装张量:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )要下载 nccl,请访问 NCCL 下载页面。
要下载 cudnn,请关注 cuDNN 下载页面。
命令
在运行以下命令之前,请确保您已正确设置nvcc 。要检查它,请运行:
nvcc --version要安装 TensorRT-LLM 和 SwiftInfer,请运行:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install .要运行 Llama 示例,您需要首先克隆 meta-llama/Llama-2-7b-chat-hf 模型或其他基于 Llama 的变体(例如 lmsys/vicuna-7b-v1.3)的 Hugging Face 存储库。然后,您可以运行以下命令来构建TensorRT引擎。您需要将<model-dir>替换为 Llama 模型的实际路径。
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1接下来,您需要下载LMSYS-FastChat提供的MT-Bench数据。
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonl最后,您可以使用以下命令运行 Llama 示例。
❗️❗️❗️在此之前,请注意:
only_n_first参数用于控制要评估的样本数量。如果您想评估所有样本,请删除此参数。 python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5您应该期望看到这一代的结果如下:
我们使用原始 PyTorch 版本对 Streaming-LLM 的实现进行了基准测试。我们的实现的基准命令在运行 Llama 示例部分中给出,而原始 PyTorch 实现的基准命令在 torch_streamingllm 文件夹中给出。使用的硬件如下所示:
结果(20轮对话)是:
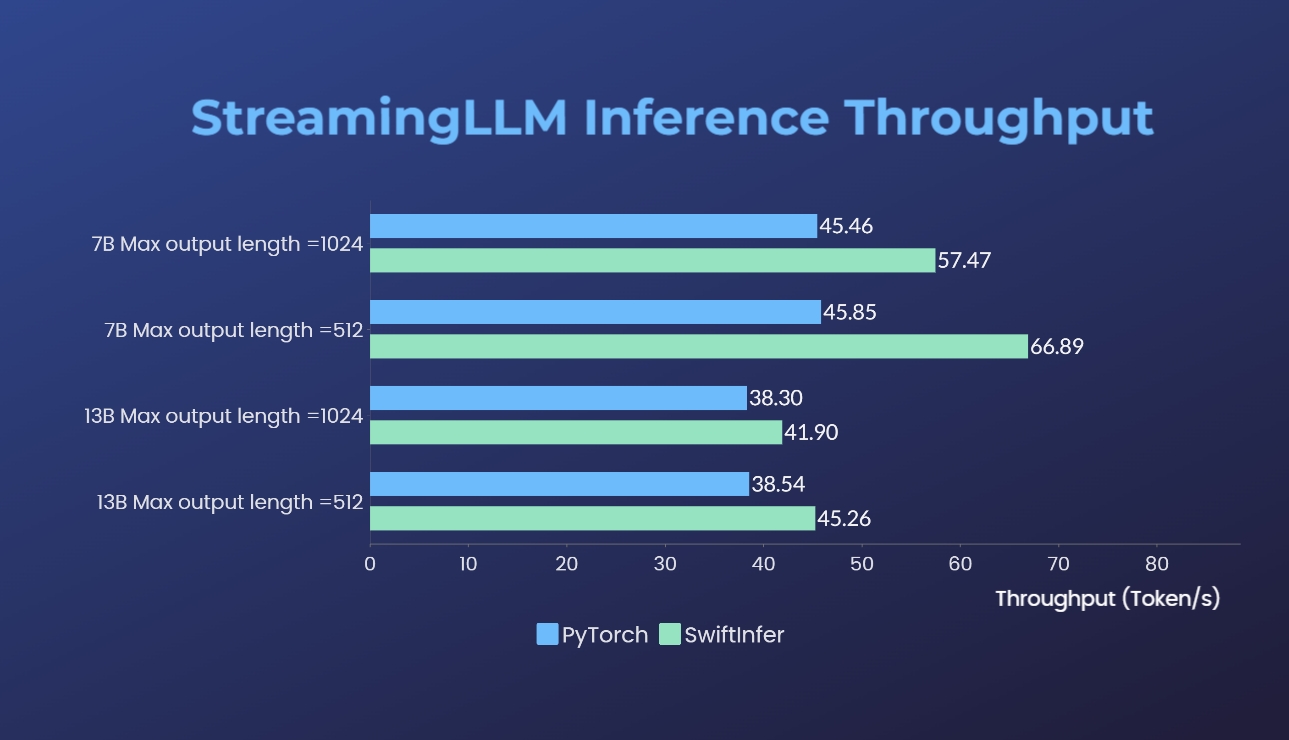
我们仍在努力进一步提高性能并适应 TensorRT V0.7.1 API。我们还注意到 TensorRT-LLM 在他们的示例中集成了 StreamingLLM,但它似乎更适合单文本生成而不是多轮对话。
这项工作受到 Streaming-LLM 的启发,使其可用于生产。在整个开发过程中,我们参考了以下材料,我们希望感谢他们对开源社区和学术界的努力和贡献。
如果您发现 StreamingLLM 和我们的 TensorRT 实现很有用,请引用我们的存储库和肖等人提出的原始工作。来自麻省理工学院汉实验室。
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

