paxml
paxml release 1.4.0
Pax 是一个在 Jax 之上配置和运行机器学习实验的框架。
我们参考此页面以获取有关启动 Cloud TPU 项目的更详尽文档。以下命令足以从企业计算机创建具有 8 个核心的 Cloud TPU VM。
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR如果您使用 TPU Pod 切片,请参阅本指南。使用 gcloud 和--worker=all选项从本地计算机运行所有命令:
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "以下快速入门部分假设您在单主机 TPU 上运行,因此您可以通过 ssh 连接到虚拟机并在其中运行命令。
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE通过 ssh 连接虚拟机后,您可以从 PyPI 安装 paxml 稳定版本,或从 github 安装开发版本。
从 PyPI 安装稳定版本 (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html如果您遇到传递依赖问题,并且您使用的是本机 Cloud TPU VM 环境,请导航到相应的发行分支 rX.YZ 并下载paxml/pip_package/requirements.txt 。该文件包含本机 Cloud TPU VM 环境中所需的所有传递依赖项的确切版本,我们在其中构建/测试相应的版本。
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txt用于从 github 安装开发版本,并方便编辑代码:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=True请访问我们的文档文件夹以获取文档和 Jupyter Notebook 教程。请参阅以下部分,了解在 Cloud TPU VM 上运行 Jupyter Notebook 的说明。
您可以在刚刚安装 paxml 的 TPU VM 中运行示例笔记本。 ####在v4-8中启用笔记本的步骤
TPU VM 中的 ssh 端口转发gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
在TPU虚拟机上安装jupyter笔记本并降级markupsafe
pip install notebook
pip install markupsafe==2.0.1
导出jupyter路径export PATH=/home/$USER/.local/bin:$PATH
scp 将示例笔记本复制到您的 TPU VM gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
从 TPU VM 启动 jupyter Notebook 并记下 Jupyter Notebook 生成的令牌jupyter notebook --no-browser --port=8080
然后在本地浏览器中访问:http://localhost:8080/ 并输入提供的令牌
注意:如果您需要在第一个笔记本仍在占用 TPU 时开始使用第二个笔记本,您可以运行pkill -9 python3来释放 TPU。
注意:NVIDIA 发布了 Pax 的更新版本,支持 H100 FP8 并进行了广泛的 GPU 性能改进。请访问 NVIDIA Rosetta 存储库以获取更多详细信息和使用说明。
配置文件引导延迟估计器 (PGLE) 工作流程可测量计算和集合的实际运行时间,配置文件信息将反馈到 XLA 编译器以做出更好的调度决策。
配置文件引导延迟估计器可以手动或自动使用。在自动模式下,JAX 将收集配置文件信息并在一次运行中重新编译模块。在手动模式下,您需要运行任务两次,第一次收集并保存配置文件,第二次使用提供的数据进行编译和运行。
可以通过设置以下环境变量来打开自动 PGLE:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
或者在 JAX 中可以设置如下:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
您可以通过更改JAX_PGLE_PROFILING_RUNS来控制用于收集配置文件数据的重新运行量。增加此参数将带来更好的配置文件信息,但也会增加非优化训练步骤的数量。
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY参数允许将主机回调与自动 PGLE 一起使用。
如果步骤之间的性能噪音太大而无法过滤掉不相关的度量,则减小JAX_PGLE_AGGREGATION_PERCENTILE参数可能会有所帮助。
注意: Auto PGLE 不适用于预编译模块。由于 JAX 需要在执行期间重新编译模块,因此自动 PGLE 既不适用于 AoT,也不适用于以下情况:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
如果您仍想使用手动配置文件引导延迟估计器,XLA/GPU 中的工作流程为:
您可以通过设置来做到这一点:
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile )完成这一步后,您将在代码中打印的rundir下得到一个profile.pb文件。
您需要将profile.pb文件传递给--xla_gpu_pgle_profile_file_or_directory_path标志。
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb "要在 XLA 中启用日志记录并检查配置文件是否良好,请将日志记录级别设置为包含INFO :
export TF_CPP_MIN_LOG_LEVEL=0运行真正的工作流程,如果您在运行日志中发现这些日志记录,则意味着在延迟隐藏调度程序中使用了分析器:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax 在 Jax 上运行,您可以在此处找到有关在 Cloud TPU 上运行 Jax 作业的详细信息,也可以在此处找到有关在 Cloud TPU pod 上运行 Jax 作业的详细信息
如果遇到依赖性错误,请参阅与您正在安装的稳定版本对应的分支中的requirements.txt文件。例如,对于稳定版本 0.4.0,请使用分支r0.4.0并参阅requirements.txt 以获取用于稳定版本的依赖项的确切版本。
以下是在 c4 数据集上运行的一些收敛示例。
您可以使用 c4.py 中的配置C4Spmd1BAdam4Replicas在 TPU v4-8上的 c4 数据集上运行1B参数模型,如下所示:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
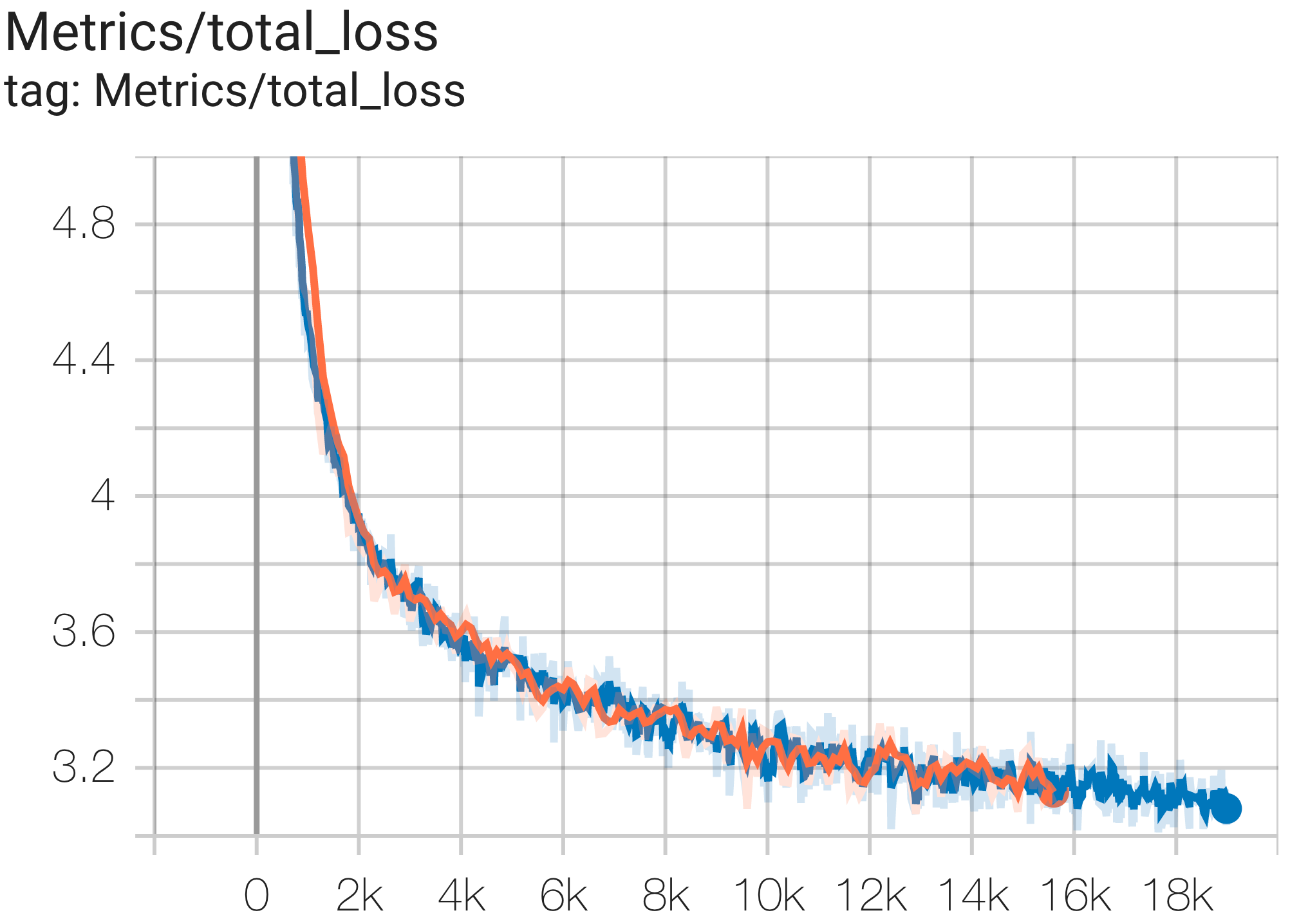
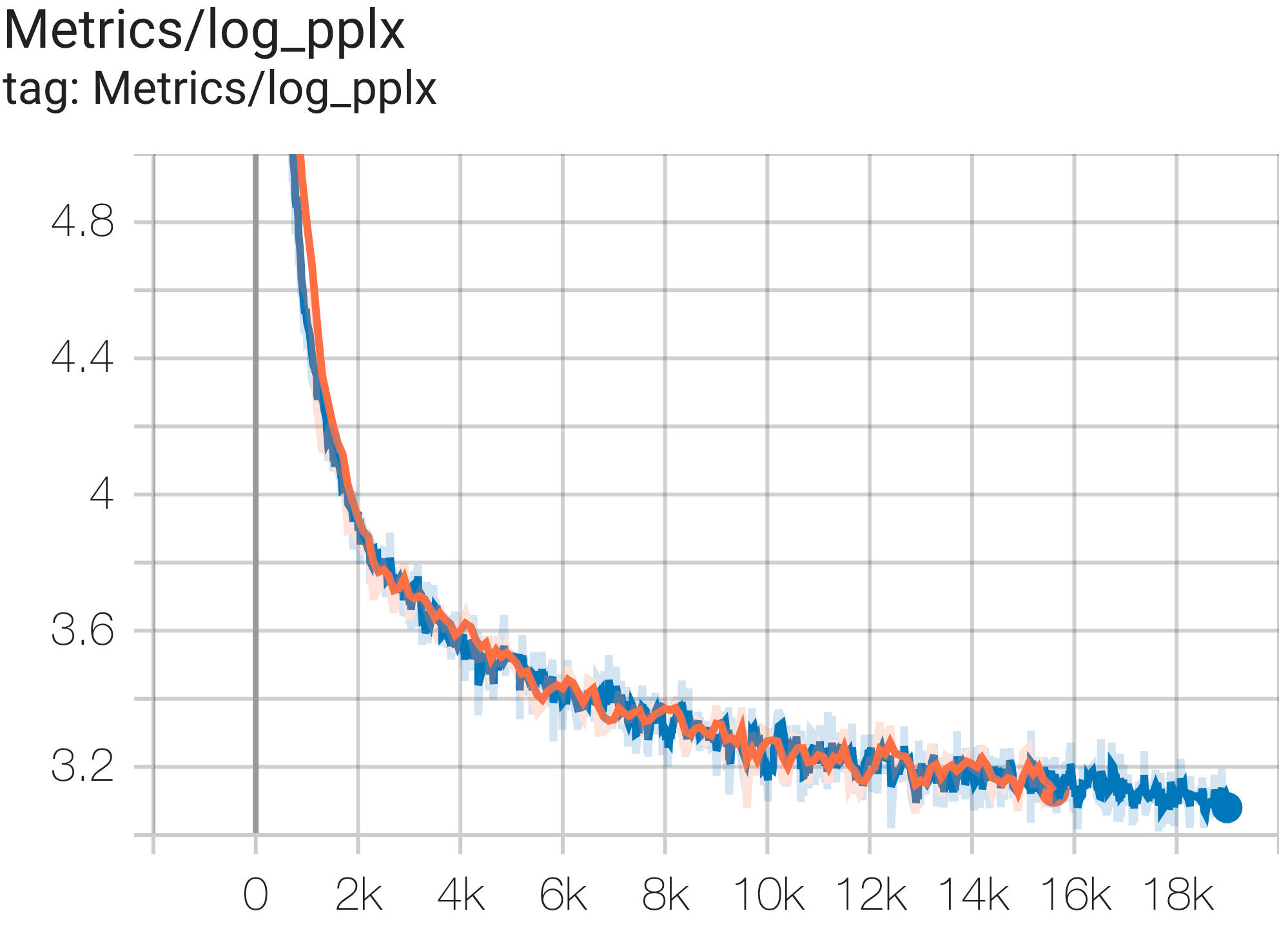
--job_log_dir=gs:// < your-bucket >可以观察loss曲线和log perplexity图如下:
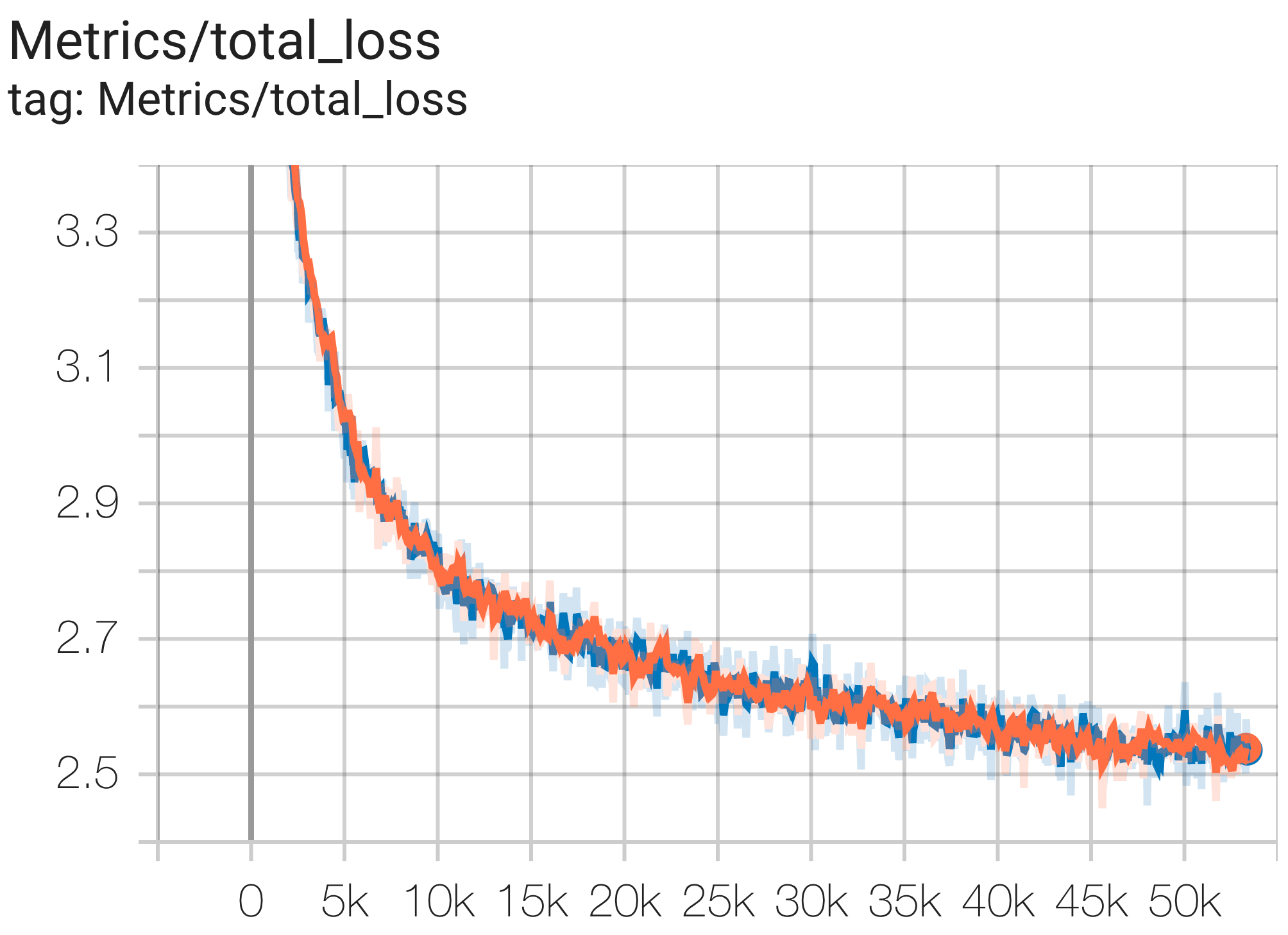
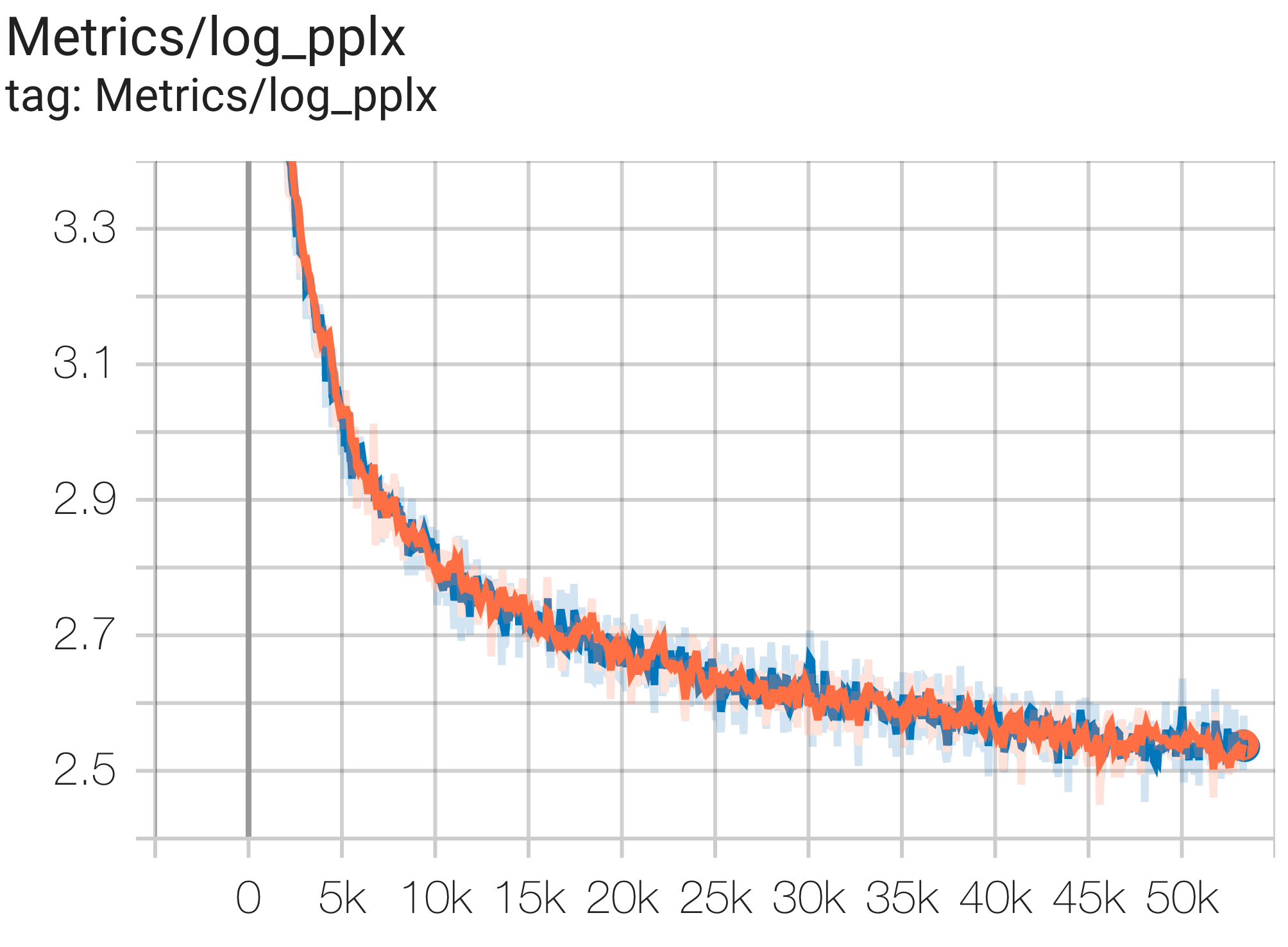
您可以使用 c4.py 中的配置C4Spmd16BAdam32Replicas在 TPU v4-64上的 c4 数据集上运行16B参数模型,如下所示:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket >可以观察loss曲线和log perplexity图如下:
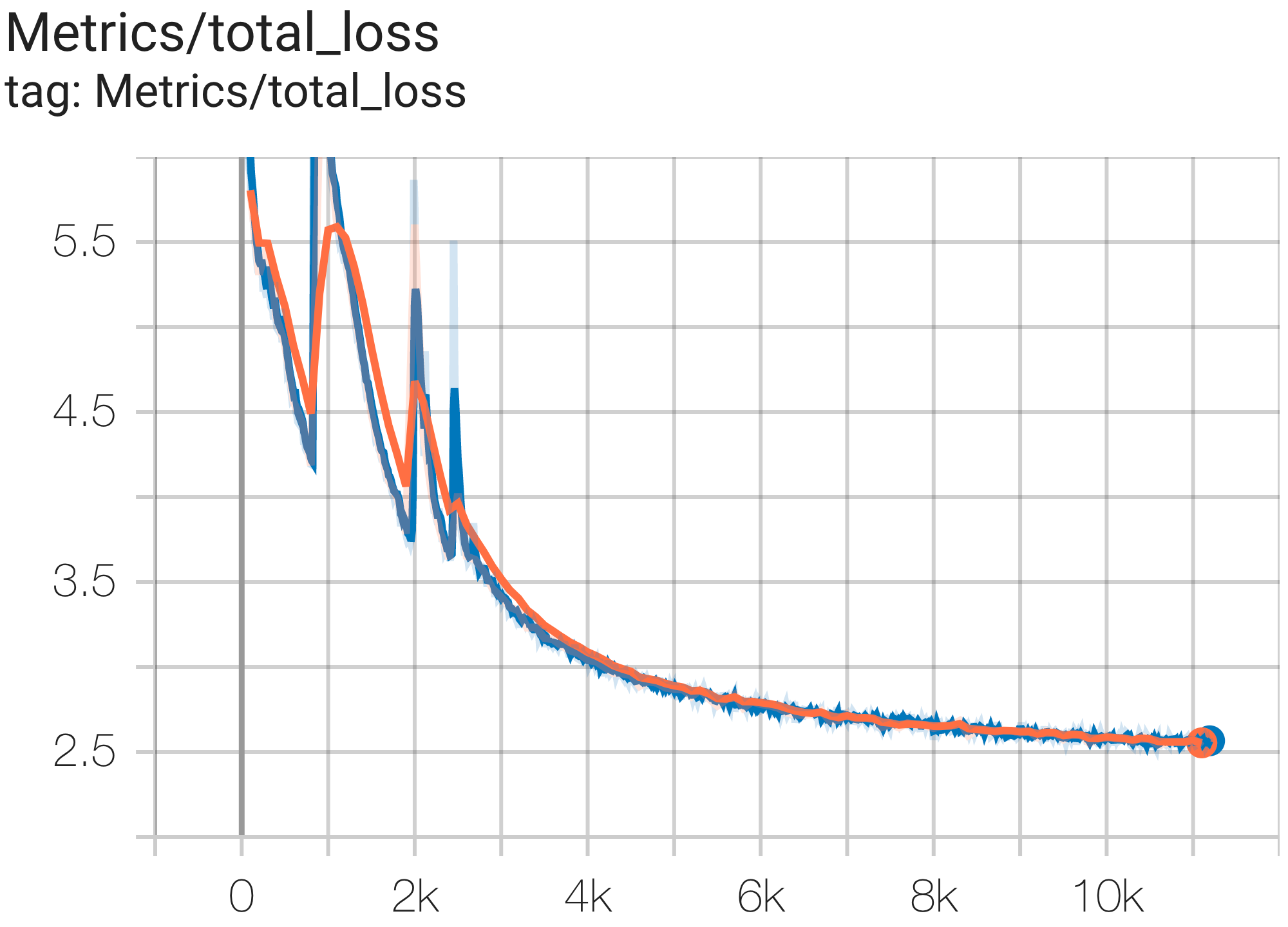
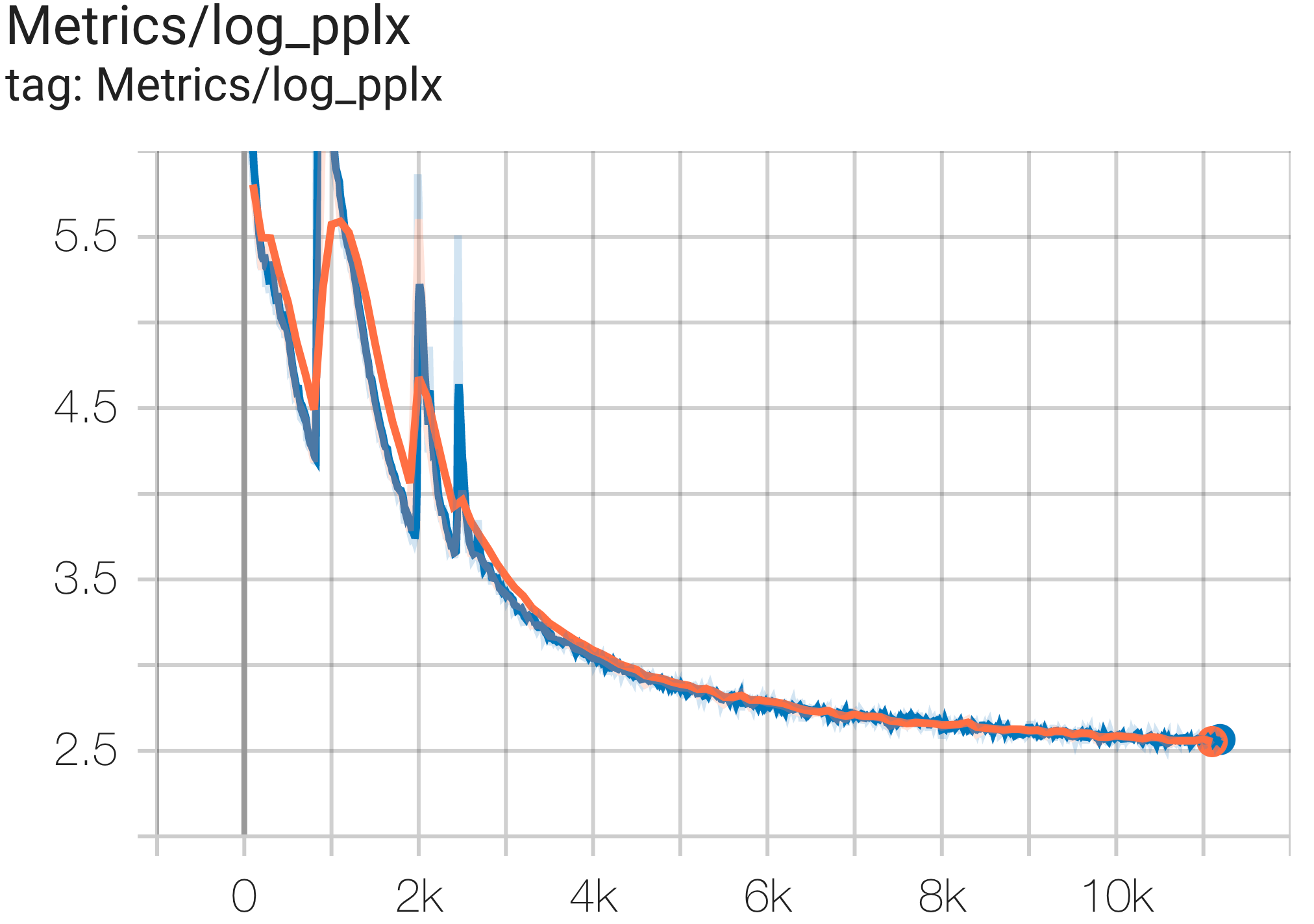
您可以使用 c4.py 中的配置C4SpmdPipelineGpt3SmallAdam64Replicas在 TPU v4-128上的 c4 数据集上运行 GPT3-XL 模型,如下所示:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket >可以观察loss曲线和log perplexity图如下:
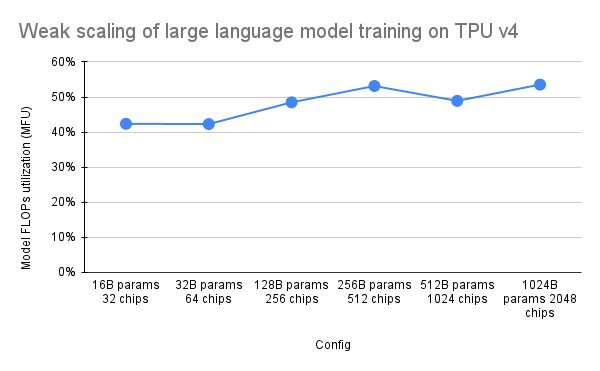
PaLM 论文引入了一种称为模型 FLOP 利用率 (MFU) 的效率指标。这是通过观察到的吞吐量(例如,语言模型每秒的令牌数)与利用 100% 峰值 FLOP 的系统的理论最大吞吐量的比率来衡量的。它与测量计算利用率的其他方法不同,因为它不包括向后传递过程中激活重新实现所花费的 FLOP,这意味着 MFU 测量的效率可直接转化为端到端训练速度。
为了评估带有 Pax 的 TPU v4 Pod 上一类关键工作负载的 MFU,我们对一系列仅解码器的 Transformer 语言模型 (GPT) 配置进行了深入的基准测试,这些配置的参数大小从数十亿到数万亿不等。在 c4 数据集上。下图显示了使用“弱缩放”模式的训练效率,其中我们根据所使用的芯片数量按比例增加模型大小。
此存储库中的多切片配置指的是 1. 用于语法/模型架构的单切片配置和 2. 用于配置值的 MaxText 存储库。
我们提供在 c4_multislice.py` 下运行的示例,作为多切片上 Pax 的起点。
我们参考此页面以获取有关在多切片 Cloud TPU 项目中使用排队资源的更详尽文档。以下显示了设置 TPU 以运行此存储库中的示例配置所需的步骤。
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run比如说,要在 2 个 v4-128 切片上运行C4Spmd22BAdam2xv4_128 ,您需要按以下方式设置 TPU:
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX前面描述的设置命令需要在所有切片中的所有工作线程上运行。您可以 1) 分别通过 ssh 进入每个工作进程和每个切片;或 2) 使用带有--worker=all标志的 for 循环,如下命令。
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done为了运行多切片配置,请打开与 $NODE_COUNT 相同数量的终端。对于我们在 2 个切片 ( C4Spmd22BAdam2xv4_128 ) 上的实验,打开两个终端。然后,从每个终端单独运行这些命令。
从终端 0,运行切片 0 的训练命令,如下所示:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "从终端 1,同时运行切片 1 的训练命令,如下所示:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "此表详细介绍了如何将 MaxText 变量名称转换为 Pax。
请注意,MaxText 有一个“比例”,它乘以几个参数(base_num_decoder_layers、base_emb_dim、base_mlp_dim、base_num_heads)以获得最终值。
另外要提到的是,虽然 Pax 将 DCN 和 ICN MESH_SHAPE 作为数组涵盖,但在 MaxText 中,DCN 和 ICI 有单独的 data_parallelism、fsdp_parallelism 和 tensor_parallelism 变量。由于这些值默认设置为 1,因此只有值大于 1 的变量才会记录在该转换表中。
即, ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism]和DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| 帕克斯 C4Spmd22BAdam2xv4_128 | MaxText 2xv4-128.sh | (应用比例后) | ||
|---|---|---|---|---|
| 规模(应用于接下来的 4 个变量) | 3 | |||
| NUM_LAYERS 个 | 48 | base_num_decoder_layers | 16 | 48 |
| 模型_DIMS | 6144 | 基础嵌入尺寸 | 2048 | 6144 |
| 隐藏_DIMS | 24576 | MODEL_DIMS * 4(= base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS 个 | 24 | 基数头数 | 8 | 24 |
| DIMS_PER_HEAD | 256 | 头昏暗 | 256 | |
| PERCORE_BATCH_SIZE | 16 | 每设备批量大小 | 16 | |
| 最大序列长度 | 1024 | 最大目标长度 | 1024 | |
| VOCAB_SIZE | 32768 | 词汇大小 | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | 数据类型 | bfloat16 | |
| 使用重复层 | 真的 | |||
| 摘要_间隔_步骤 | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_并行度 | 64 | |
| DCN_MESH_SHAPE | [2,1,1] | DCN_数据_并行性 | 2 |
Input 是BaseInput类的一个实例,用于将数据输入模型以进行训练/评估/解码。
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass它的作用就像一个迭代器: get_next()返回一个NestedMap ,其中每个字段都是一个数值数组,以批量大小作为其前导维度。
每个输入均由BaseInput.HParams的子类配置。在此页面中,我们使用p表示BaseInput.Params的实例,并将其实例化为input 。
在 Pax 中,数据始终是多主机的:每个 Jax 进程都会实例化一个单独的、独立的input 。它们的参数将具有不同的p.infeed_host_index ,由 Pax 自动设置。
因此,每个主机上看到的本地批量大小为p.batch_size ,全局批量大小为(p.batch_size * p.num_infeed_hosts) 。人们经常会看到p.batch_size设置为jax.local_device_count() * PERCORE_BATCH_SIZE 。
由于这种多主机性质, input必须正确分片。
对于训练,每个input绝不能发出相同的批次,对于有限数据集上的评估,每个input必须在相同数量的批次后终止。最好的解决方案是让输入实现正确地对数据进行分片,以便不同主机上的每个input不会重叠。如果做不到这一点,我们还可以使用不同的随机种子来避免训练期间重复批次。
input.reset()永远不会在训练数据上调用,但可以用于评估(或解码)数据。
对于每次 eval(或解码)运行,Pax 通过调用input.get_next() N次从input中获取N批次。使用的批次数量N可以是用户通过p.eval_loop_num_batches指定的固定数量;或者N可以是动态的( p.eval_loop_num_batches=None ),即我们调用input.get_next()直到耗尽其所有数据(通过引发StopIteration或tf.errors.OutOfRange )。
如果p.reset_for_eval=True ,则忽略p.eval_loop_num_batches并动态确定N作为耗尽数据的批次数。在这种情况下, p.repeat应设置为 False,否则会导致无限解码/评估。
如果p.reset_for_eval=False ,Pax 将获取p.eval_loop_num_batches批次。应使用p.repeat=True设置此值,以便数据不会过早耗尽。
请注意,LingvoEvalAdaptor 输入需要p.reset_for_eval=True 。
N :静态 | N :动态 | |
|---|---|---|
p.reset_for_eval=True | 每次评估运行都使用 | 每次评估运行一个时期。 |
: : 前N批。不是: eval_loop_num_batches : | ||
| : : 还支持。 : 被忽略。输入必须: | ||
| : : : 是有限的: | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | 每次评估运行都使用 | 不支持。 |
: : 不重叠N : : | ||
| : : 滚动批量: : | ||
| : : 依据,根据 : : | ||
: : eval_loop_num_batches : : | ||
| : : 。输入必须重复: : | ||
| : : 无限期 : : | ||
: : ( p.repeat=True ) 或 : : | ||
| : : 否则可能会提出: : | ||
| : : 例外 : : |
如果在一个 epoch 上运行解码/评估(即当p.reset_for_eval=True时),输入必须正确处理分片,以便每个分片在生成完全相同数量的批次后在同一步骤中引发。这通常意味着输入必须填充评估数据。这是由SeqIOInput和LingvoEvalAdaptor自动完成的(请参阅下文)。
对于大多数输入,我们只对它们调用get_next()来获取批量数据。一种类型的评估数据是一个例外,其中“如何计算指标”也在输入对象上定义。
仅定义一些规范评估基准的SeqIOInput支持此功能。具体来说,Pax 使用 SeqIO 任务上定义的predict_metric_fns和score_metric_fns()来计算 eval 指标(尽管 Pax 不直接依赖于 SeqIO 评估器)。
当模型使用多个输入时,无论是在训练/评估之间还是在预训练/微调之间使用不同的训练数据,用户必须确保输入使用的分词器相同,尤其是在导入其他人实现的不同输入时。
用户可以通过使用input.ids_to_strings()解码一些 id 来检查分词器的完整性。
通过查看几个批次来对数据进行健全性检查总是一个好主意。用户可以轻松地在 Colab 中重现参数并检查数据:
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b )训练数据通常不应使用固定的随机种子。这是因为如果训练作业被抢占,训练数据将开始重复。特别是,对于 Lingvo 输入,我们建议为训练数据设置p.input.file_random_seed = 0 。
要测试分片是否正确处理,用户可以手动为p.num_infeed_hosts, p.infeed_host_index设置不同的值,并查看实例化的输入是否发出不同的批次。
Pax 支持 3 种类型的输入:SeqIO、Lingvo 和自定义。
SeqIOInput可用于导入数据集。
SeqIO 输入自动处理评估数据的正确分片和填充。
LingvoInputAdaptor可用于导入数据集。
输入完全委托给 Lingvo 实现,它可能会也可能不会自动处理分片。
对于使用固定packing_factor的基于 GenericInput 的 Lingvo 输入实现,我们建议使用LingvoInputAdaptorNewBatchSize为内部 Lingvo 输入指定更大的批量大小,并将所需(通常要小得多)的批量大小放在p.batch_size上。
对于评估数据,我们建议使用LingvoEvalAdaptor来处理分片和填充,以便在一个 epoch 上运行评估。
BaseInput的自定义子类。用户通常使用tf.data或 SeqIO 来实现自己的子类。
用户还可以继承现有的输入类来仅自定义批次的后处理。例如:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batch超参数是定义模型和配置实验的重要组成部分。
为了更好地与 Python 工具集成,Pax/Praxis 使用基于 Pythonic 数据类的超参数配置样式。
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0也可以嵌套HParams数据类,在下面的示例中,线性_tpl属性是嵌套的Linear.HParams。
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )层表示可能具有可训练参数的任意函数。一个图层可以包含其他图层作为子图层。层是模型的基本构建块。层继承自 Flax nn.Module。
通常层定义两种方法:
此方法创建可训练的权重和子层。
该方法定义了前向传播函数,根据输入计算一些输出。此外,fprop 可能会添加摘要或跟踪辅助损失。
Fiddle 是一个开源的 Python-first 配置库,专为 ML 应用程序设计。 Pax/Praxis 支持与 Fiddle Config/Partial 的互操作性以及一些高级功能,例如急切的错误检查和共享参数。
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )使用 Fiddle,层可以配置为共享(例如:使用共享的可训练权重仅实例化一次)。
模型仅定义网络,通常是层的集合,并定义用于与模型交互的接口,例如解码等。
一些示例基本模型包括:
一项任务包含多个模型和学习器/优化器。最简单的 Task 子类是SingleTask ,它需要以下 Hparam:
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| PyPI版本 | 犯罪 |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


