datablations
1.0.0
该存储库提供了《扩展数据约束语言模型》一文中所有组件的概述。纸上谈话:
我们研究数据受限条件下的扩展语言模型。我们进行了大量不同数据重复程度和计算预算的实验,范围高达 9000 亿个训练令牌和 90 亿个参数模型。根据我们的运行,我们提出并凭经验验证计算最优性的缩放法则,该法则解释了重复标记和多余参数的值递减的情况。我们还尝试了缓解数据稀缺的方法,包括使用代码数据增强训练数据集、困惑过滤和重复数据删除。我们 400 次训练运行的模型和数据集可通过此存储库获取。
我们对 C4 上的重复数据和 OSCAR 的非重复数据英文分割进行了实验。对于每个数据集,我们下载数据并将其转换为单个 jsonl 文件,分别为c4.jsonl和oscar_en.jsonl 。
然后我们决定独特标记的数量以及我们需要从数据集中获取的样本数量。请注意,C4 每个样本有478.625834583个令牌,OSCAR 使用 GPT2Tokenizer 有1312.0951072 。这是通过对整个数据集进行标记并将标记数量除以样本数量来计算的。我们使用这些数字来计算所需的样本。
例如,对于 1.9B 唯一令牌,我们需要1.9B / 478.625834583 = 3969697.96178个样本用于1.9B / 1312.0951072 = 1448065.76107个样本用于 OSCAR。为了标记数据,我们首先需要克隆 Megatron-DeepSpeed 存储库并遵循其设置指南。然后我们选择这些样本并对它们进行标记,如下所示:
C4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64奥斯卡:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64其中gpt2指向包含 https://huggingface.co/gpt2/tree/main 中的所有文件的文件夹。通过使用head ,我们确保不同的子集将具有重叠的样本,以减少随机性。
对于训练期间的评估和最终评估,我们使用 C4 的验证集:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2对于没有官方验证集的 OSCAR,我们通过执行tail -364608 oscar_en.jsonl > oscarvalidation.jsonl来获取训练集的一部分,然后将其标记化如下:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2我们已经上传了几个预处理的子集以供 megatron 使用:
一些 bin 文件对于 git 来说太大,因此使用split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin.并split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. 。要使用它们进行训练,您需要使用cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin和cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin将它们再次组合在一起。
我们使用来自 the-stack-dedup 的 Python 拆分来尝试将代码与自然语言数据混合。我们下载数据,将其转换为单个 jsonl 文件,并使用与上述相同的方法对其进行预处理。
我们在这里上传了用于 megatron 的预处理版本:https://huggingface.co/datasets/datablations/python-megatron。我们使用split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. ,因此您需要使用cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin再次将它们放在一起进行训练。
我们创建了具有困惑度和重复数据删除相关过滤元数据的 C4 和 OSCAR 版本:
要重新创建这些元数据数据集,请参阅filtering/README.md中的说明。
我们提供可用于威震天训练的标记化版本:
.bin文件使用split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. ,因此您需要通过cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin 。
要重新创建给定元数据数据集的标记化版本,
filtering/deduplication/filter_oscar_jsonl.py要创建困惑度百分位数,请按照以下说明操作。
C4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )奥斯卡:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )然后,您可以对生成的 jsonl 文件进行标记,以便使用 Megatron 进行训练,如重复部分中所述。
C4:对于 C4,您只需删除填充repetitions字段的所有样本,例如
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR:对于 OSCAR,我们在filtering/filter_oscar_jsonl.py中提供了一个脚本,用于在给定具有过滤元数据的数据集的情况下创建去重数据集。
然后,您可以对生成的 jsonl 文件进行标记,以便使用 Megatron 进行训练,如重复部分中所述。
所有模型均可在 https://huggingface.co/datablations 下载。
模型通常命名如下: lm1-{parameters}-{tokens}-{unique_tokens} ,具体而言,文件夹中的各个模型命名为: {parameters}{tokens}{unique_tokens}{optional specifier} ,例如1b12b8100m将是11 亿个参数、28 亿个代币、1 亿个独特代币。 xby ( 1b1 、 2b8等)约定引入了一些模糊性,即数字属于参数还是令牌,但您始终可以检查相应文件夹中的 sbatch 脚本以查看确切的参数/令牌/唯一令牌。如果您想将尚未转换的模型转换为huggingface/transformers ,可以按照 Training 中的说明进行操作。
下载单个模型的最简单方法是:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553如果这需要太长时间,您还可以使用wget直接从文件夹中下载单个文件,例如:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt对于与论文中的实验相对应的模型,请查阅以下存储库:
lm1-misc/*dedup*用于附录中 100M 唯一标记的重复数据删除比较论文中未分析的其他模型:
我们使用与 AMD GPU(通过 ROCm)配合使用的 Megatron-DeepSpeed 分支来训练模型:https://github.com/TurkuNLP/Megatron-DeepSpeed 如果您想使用 NVIDIA GPU(通过 cuda),您可以使用原始库:https://github.com/bigscience-workshop/Megatron-DeepSpeed
您需要按照任一存储库的设置说明来创建您的环境(我们特定于 LUMI 的设置在training/megdssetup.md中有详细说明)。
每个模型文件夹都包含一个用于训练模型的 sbatch 脚本。您可以使用这些作为参考来训练您自己的模型,以适应必要的环境变量。 sbatch 脚本引用了一些附加文件:
*txt文件指定数据路径。您可以在utils/datapaths/*找到它们,但是,您可能需要调整路径以指向您的数据集。model_params.sh ,位于utils/model_params.sh并包含架构预设。training/launch.sh找到launch.sh 。它包含特定于我们的设置的命令,您可能想要删除它们。训练后,您可以使用例如python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1将模型转换为变压器。
对于重复模型,我们还在训练后使用tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar"上传其张量板,这使得它们易于在论文中用于可视化。
对于附录中的 muP 消融,我们使用training_scripts/mup.py中的脚本。它包含设置说明。
您可以使用我们的公式来计算给定参数、数据和唯一令牌的预期损失,如下所示:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
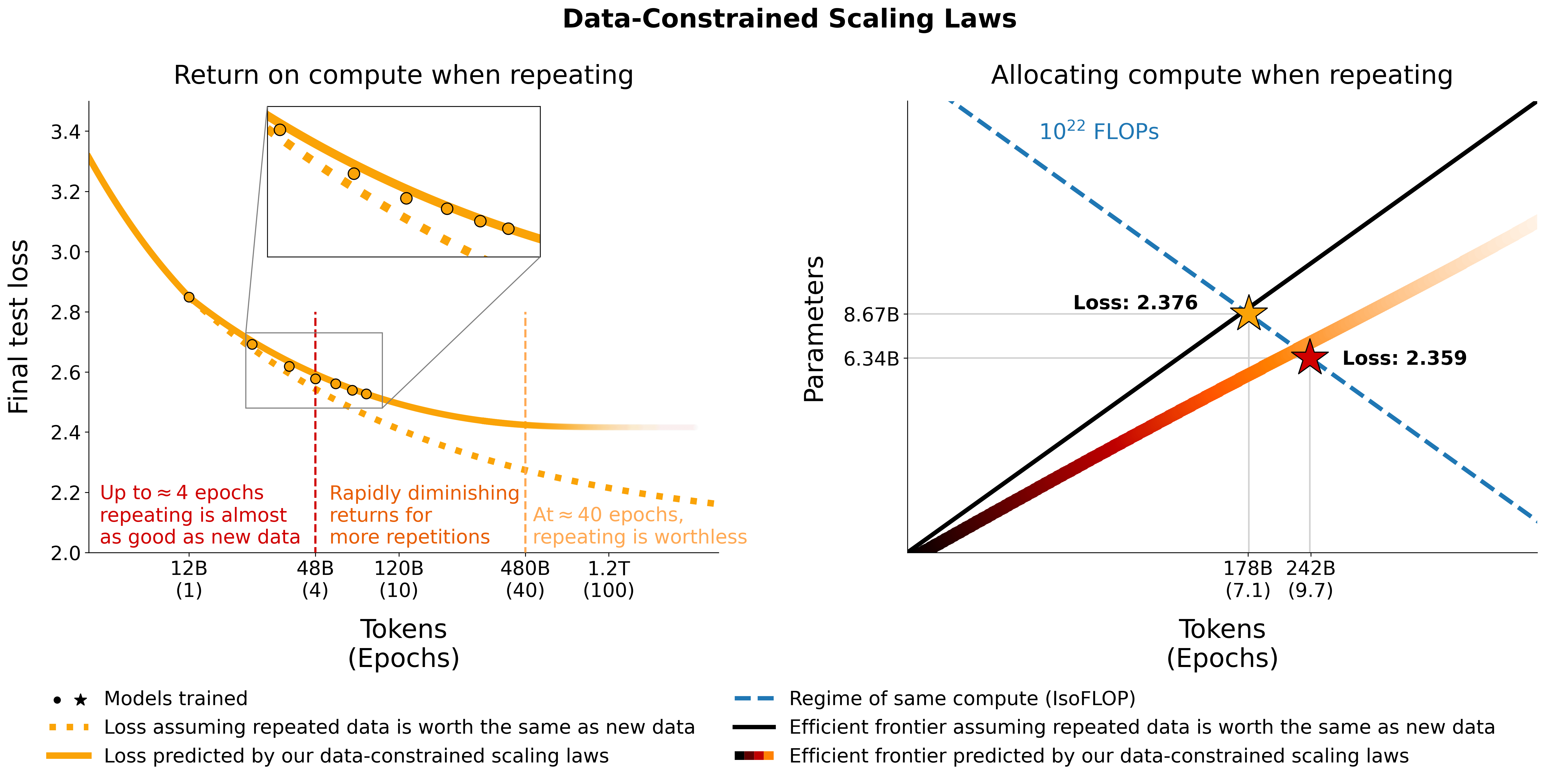
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867请注意,实际损失值不太可能有用,而是损失的趋势,例如参数数量的增加或比较两个模型,如上例所示。要计算最佳分配,您可以使用简单的网格搜索:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test如果您导出最佳分配的封闭式表达式而不是上述网格搜索,请告诉我们:)我们使用与此 colab 等效的utils/parametric_fit.ipynb中的代码来拟合数据约束的缩放法则和 C4 缩放系数。
Training > Regular models部分中的说明设置训练环境。pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git 。我们使用的是 0.2.0 版本,但较新的版本应该也可以工作。sbatch utils/eval_rank.sh首先修改脚本中必要的变量python Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.json将每个文件转换为 csvaddtasks分支: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13即除了promptsource之外的所有要求,它是从具有正确提示的fork安装的sbatch utils/eval_generative.sh首先修改脚本中必要的变量python utils/merge_generative.py合并生成文件,然后使用python utils/csv_generative.py merged.json将它们转换为 csvbabi分支: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (请注意,此分支与生成任务的addtasks分支不兼容,因为它源于EleutherAI/lm-evaluation-harness ,而addtasks基于bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh首先修改脚本中必要的变量plotstables/return_alloc.pdf 、 plotstables/return_alloc.ipynb 、colabplotstables/dataset_setup.pdf 、 plotstables/dataset_setup.ipynb 、colabplotstables/contours.pdf 、 plotstables/contours.ipynb 、colabplotstables/isoflops_training.pdf 、 plotstables/isoflops_training.ipynb 、colabplotstables/return.pdf 、 plotstables/return.ipynb 、colabplotstables/strategies.pdf 、 plotstables/strategies.drawioplotstables/beyond.pdf 、 plotstables/beyond.ipynb 、colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf & 与图 3 相同的 colabplotstables/mup.pdf 、 plotstables/dd.pdf 、 plotstables/dedup.pdf 、 plotstables/mup_dd_dd.ipynb 、colabplotstables/isoloss_alphabeta_100m.pdf & 与图 3 相同的 colabplotstables/galactica.pdf 、 plotstables/galactica.ipynb 、colabtraining_c4.pdf 、 validation_c4oscar.pdf 、 training_oscar.pdf 、 validation_epochs_c4oscar.pdf和与图 4 相同的 colabplotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf 、 plotstables/training_validation_filter.pdf 、 plotstables/beyond_losses.ipynb和 colabutils/parametric_fit.ipynb中。plotstables/repetition.ipynb和 colabplotstables/python.ipynb和 colabplotstables/filtering.ipynb和 colab所有模型和代码均在 Apache 2.0 下获得许可。过滤后的数据集使用与其来源的数据集相同的许可证进行发布。
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

