GenerativeRL
v0.0.1
英语 | 简体中文(简体中文)
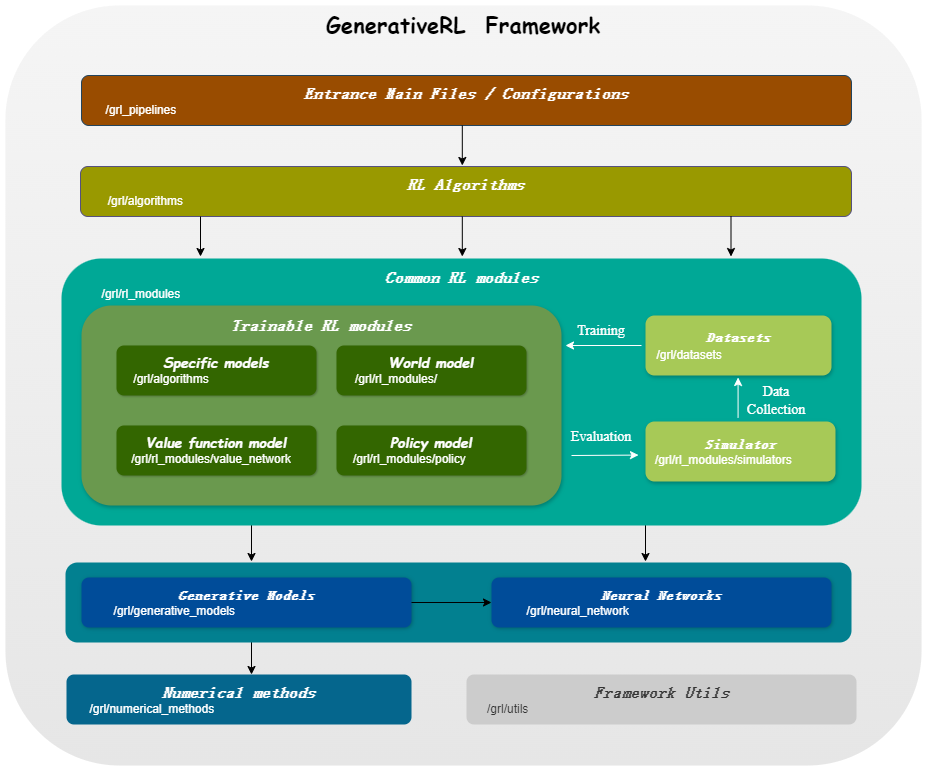
GenerativeRL是生成强化学习的缩写,是一个 Python 库,用于使用生成模型(例如扩散模型和流模型)解决强化学习 (RL) 问题。该库旨在提供一个框架,将生成模型的强大功能与强化学习算法的决策能力相结合。
| 分数匹配 | 流量匹配 | |
|---|---|---|
| 扩散模型 | ||
| 线性VP SDE | ✔ | ✔ |
| 广义VP SDE | ✔ | ✔ |
| 线性SDE | ✔ | ✔ |
| 流动模型 | ||
| 独立条件流匹配 | ✔ | |
| 最优传输条件流量匹配 | ✔ |
| 算法/模型 | 扩散模型 | 流动模型 |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| GMPG | ✔ | ✔ |
pip install GenerativeRL或者,如果您想从源安装:
git clone https://github.com/opendilab/GenerativeRL.git
cd GenerativeRL
pip install -e .或者您可以使用 docker 镜像:
docker pull opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bash以下示例展示了如何使用 GenerativeRL 在 LunarLanderContinously-v2 环境中训练用于 Q 引导策略优化 (QGPO) 的扩散模型。
安装所需的依赖项:
pip install ' gym[box2d]==0.23.1 '(对于box2d环境,gym版本可以从0.23到0.25,但建议使用0.23.1以兼容D4RL。)
从这里下载数据集并将其保存为当前目录中的data.npz 。
GenerativeRL 使用 WandB 进行记录。当您使用它时,它会要求您登录您的帐户。您可以通过运行以下命令来禁用它:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )有关更详细的示例和文档,请参阅 GenerativeRL 文档。
GenerativeRL 的完整文档可以在 GenerativeRL 文档中找到。
我们提供了多个案例教程来帮助您更好地理解 GenerativeRL。请参阅教程了解更多内容。
我们提供一些基线实验来评估生成强化学习算法的性能。在基准测试中查看更多信息。
我们欢迎为 GenerativeRL 做出贡献!如果您有兴趣贡献,请参阅贡献指南。
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}GenerativeRL 根据 Apache License 2.0 获得许可。有关更多详细信息,请参阅许可证。


