ffhq dataset
1.0.0

Flickr-Faces-HQ (FFHQ) 是一个高质量的人脸图像数据集,最初是作为生成对抗网络 (GAN) 的基准创建的:
用于生成对抗网络的基于样式的生成器架构
Tero Karras (NVIDIA)、Samuli Laine (NVIDIA)、Timo Aila (NVIDIA)
https://arxiv.org/abs/1812.04948
该数据集由 70,000 张分辨率为 1024×1024 的高质量 PNG 图像组成,并且在年龄、种族和图像背景方面包含相当大的差异。它还对眼镜、太阳镜、帽子等配饰有很好的覆盖。这些图像是从 Flickr 爬取的,因此继承了该网站的所有偏见,并使用 dlib 自动对齐和裁剪。仅收集经过许可的图像。使用各种自动过滤器来修剪场景,最后使用 Amazon Mechanical Turk 删除偶尔出现的雕像、绘画或照片。
请注意,该数据集并非旨在也不应用于开发或改进面部识别技术。如需业务咨询,请访问我们的网站并提交表格:NVIDIA 研究许可
各个图像由各自的作者根据知识共享 BY 2.0、知识共享 BY-NC 2.0、公共领域标记 1.0、公共领域 CC0 1.0 或美国政府作品许可在 Flickr 上发布。所有这些许可证都允许出于非商业目的免费使用、重新分发和改编。然而,其中一些要求对原作者给予适当的认可,并注明对图像所做的任何更改。每个图像的许可和原始作者都在元数据中标明。
数据集本身(包括 JSON 元数据、下载脚本和文档)由 NVIDIA Corporation 根据 Creative Commons BY-NC-SA 4.0 许可提供。您可以出于非商业目的使用、重新分发和改编它,只要您 (a) 通过引用我们的论文给予适当的认可,(b)表明您所做的任何更改,以及 (c) 分发任何衍生作品在同一许可证下。
所有数据都托管在 Google Drive 上:
| 小路 | 尺寸 | 文件 | 格式 | 描述 |
|---|---|---|---|---|
| ffhq-数据集 | 2.56TB | 210,014 | 主文件夹 | |
| ├ ffhq-数据集-v2.json | 255MB | 1 | JSON | 元数据包括版权信息、URL 等。 |
| ├ 图片1024x1024 | 89.1GB | 70,000 | 巴布亚新几内亚 | 1024×1024 对齐和裁剪的图像 |
| ├ 缩略图128x128 | 1.95GB | 70,000 | 巴布亚新几内亚 | 缩略图为 128×128 |
| ├ 野外图像 | 955GB | 70,000 | 巴布亚新几内亚 | 原始图片来自 Flickr |
| ├ tf记录 | 273GB | 9 | tf记录 | StyleGAN 和 StyleGAN2 的多分辨率数据 |
| └ 拉链 | 1.28TB | 4 | 拉链 | 每个文件夹的内容作为 ZIP 存档。 |
高级统计数据:
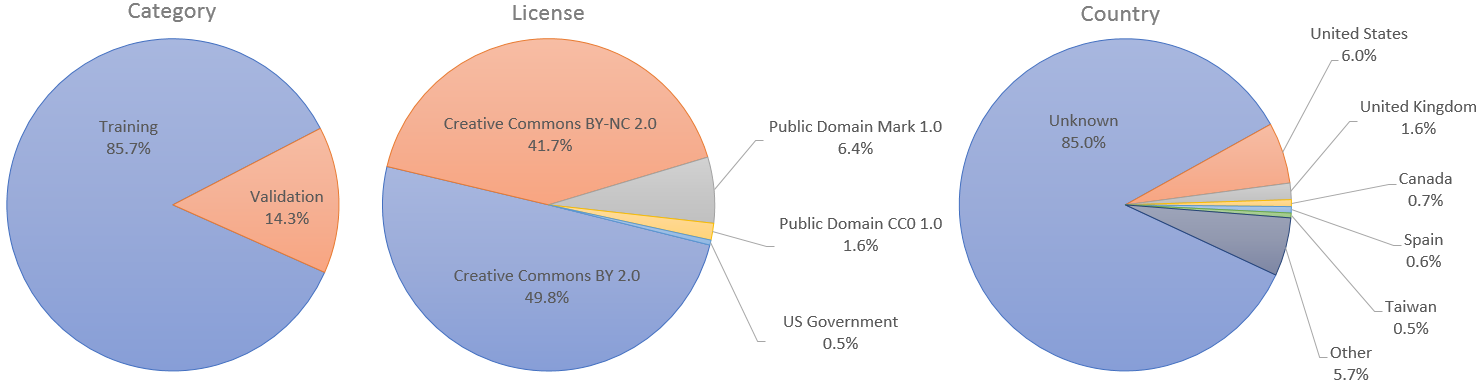
对于需要单独训练和验证集的用例,我们指定前 60,000 个图像用于训练,其余 10,000 个图像用于验证。然而,在 StyleGAN 论文中,我们使用了全部 70,000 张图像进行训练。
我们已明确确保数据集本身不存在重复的图像。但是,请注意,如果我们从同一图像中提取多个不同的面部,则in-the-wild文件夹可能包含同一图像的多个副本。
您可以直接从 Google Drive 获取数据,也可以使用提供的下载脚本。该脚本通过自动下载所有请求的文件、验证其校验和、在错误时重试每个文件多次以及采用多个并发连接来最大化带宽,使事情变得更加容易。
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
该脚本还用作我们用来对齐和裁剪图像的自动化方案的参考实现。使用python download_ffhq.py --wilds下载野外图像后,您可以运行python download_ffhq.py --align以使用元数据中包含的面部标志位置来重现对齐的 1024×1024 图像的精确副本。
要重现 Alias-Free Generative Adversarial Networks 论文中使用的“未对齐的 FFHQ”数据集,请使用以下选项:
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
ffhq-dataset-v2.json文件以机器可读的格式包含每个图像的以下信息:
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
我们感谢 Jaakko Lehtinen、David Luebke 和 Tuomas Kynkäänniemi 的深入讨论和有益的评论; Janne Hellsten、Tero Kuosmanen 和 Pekka Jänis 负责计算基础设施并帮助发布代码。
我们还感谢 Vahid Kazemi 和 Josephine Sullivan 在自动人脸检测和对齐方面所做的工作,使我们能够首先收集数据:
使用回归树集合进行一毫秒人脸对齐
瓦希德·卡泽米,约瑟芬·沙利文
过程。 2014年CVPR
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Millisecond_Face_2014_CVPR_paper.pdf
在收集数据时,我们小心翼翼地仅包含据我们所知的旨在由各自作者免费使用和重新分发的照片。也就是说,我们致力于保护那些不希望自己的照片被包含在内的个人的隐私。
要了解您的照片是否包含在 Flickr-Faces-HQ 数据集中,请单击此链接以使用您的 Flickr 用户名搜索数据集。
要从 Flickr-Faces-HQ 数据集中删除您的照片:
no_cv标记照片以表明您不希望将其用于计算机视觉研究。None (保留所有权利)或任何具有NoDerivs的知识共享许可证,以表明您不希望重新分发它。

