open_llama
1.0.0
TL;DR :我们正在发布 OpenLLaMA 的公共预览版,这是 Meta AI 的 LLaMA 的许可开源复制品。我们正在发布一系列针对不同数据混合进行训练的 3B、7B 和 13B 模型。我们的模型权重可以作为现有实现中 LLaMA 的替代品。
在此存储库中,我们展示了 Meta AI 的 LLaMA 大语言模型的许可开源复制品。我们正在发布一系列在 1T 代币上训练的 3B、7B 和 13B 模型。我们提供预训练 OpenLLaMA 模型的 PyTorch 和 JAX 权重,以及评估结果以及与原始 LLaMA 模型的比较。 v2 模型比在不同数据混合上训练的旧 v1 模型更好。
我们正在发布 OpenLLaMA 3Bv3 模型,这是一个 3B 模型,在与 7Bv2 模型相同的数据集混合上训练 1T 令牌。
我们很高兴发布 OpenLLaMA 7Bv2 模型,该模型是在 Falcon 精细化 Web 数据集、starcoder 数据集以及 wikipedia、arxiv 以及来自 RedPajama 的 books 和 stackexchange 上进行训练的。
我们很高兴发布 OpenLLaMA 13B 的最终 1T 代币版本。我们已经更新了评估结果。对于当前版本的 OpenLLaMA 模型,我们的分词器经过训练,可以在分词之前将多个空白空间合并为一个,类似于 T5 分词器。因此,我们的分词器将无法处理代码生成任务(例如 HumanEval),因为代码涉及许多空白区域。对于与代码相关的任务,请使用 v2 模型。
我们很高兴发布 OpenLLaMA 3B 和 7B 的最终 1T 代币版本。我们已经更新了评估结果。我们还很高兴发布 13B 模型的 600B 代币预览版,该模型是与 Stability AI 合作训练的。
我们很高兴为 OpenLLaMA 7B 模型发布 700B 代币检查点,为 3B 模型发布 600B 代币检查点。我们还更新了评估结果。我们预计完整的 1T 代币训练将于本周末完成。
在收到社区的反馈后,我们发现之前的检查点版本的分词器配置不正确,导致新行未被保留。为了解决这个问题,我们重新训练了分词器并重新开始了模型训练。我们还观察到使用这个新的分词器可以降低训练损失。
我们以两种格式发布权重:一种是与我们的 EasyLM 框架一起使用的 EasyLM 格式,另一种是与 Hugging Face 转换器库一起使用的 PyTorch 格式。我们的训练框架 EasyLM 和检查点权重均获得 Apache 2.0 许可证的许可。
预览检查点可以直接从 Hugging Face Hub 加载。请注意,建议暂时避免使用 Hugging Face 快速标记生成器,因为我们观察到自动转换的快速标记生成器有时会给出不正确的标记化。这可以通过直接使用LlamaTokenizer类或为AutoTokenizer类传入use_fast=False选项来实现。使用方法请参见以下示例。
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))如需更高级的使用,请遵循 Transformers LLaMA 文档。
可以使用 lm-eval-harness 评估模型。然而,由于上述分词器问题,我们需要避免使用快速分词器来获得正确的结果。这可以通过将use_fast=False传递到 lm-eval-harness 的这一部分来实现,如下例所示:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)有关在 EasyLM 框架中使用权重的信息,请参阅 EasyLM 的 LLaMA 文档。请注意,与原始 LLaMA 模型不同,我们的 OpenLLaMA 分词器和权重完全从头开始训练,因此不再需要获取原始 LLaMA 分词器和权重。
v1 模型在 RedPajama 数据集上进行训练。 v2 模型在 Falcon Fine-Web 数据集、StarCoder 数据集以及 RedPajama 数据集的 wikipedia、arxiv、book 和 stackexchange 部分的混合上进行训练。我们遵循与原始 LLaMA 论文完全相同的预处理步骤和训练超参数,包括模型架构、上下文长度、训练步骤、学习率计划和优化器。我们的设置与原始设置之间的唯一区别是使用的数据集:OpenLLaMA 使用开放数据集,而不是原始 LLaMA 使用的数据集。
我们使用 EasyLM 在云 TPU-v4 上训练模型,EasyLM 是我们为训练和微调大型语言模型而开发的基于 JAX 的训练管道。我们采用普通数据并行性和完全分片数据并行性(也称为 ZeRO 第 3 阶段)的组合来平衡训练吞吐量和内存使用量。总体而言,我们的 7B 模型的 TPU-v4 芯片的吞吐量达到了超过 2200 个令牌/秒。训练损失如下图所示。
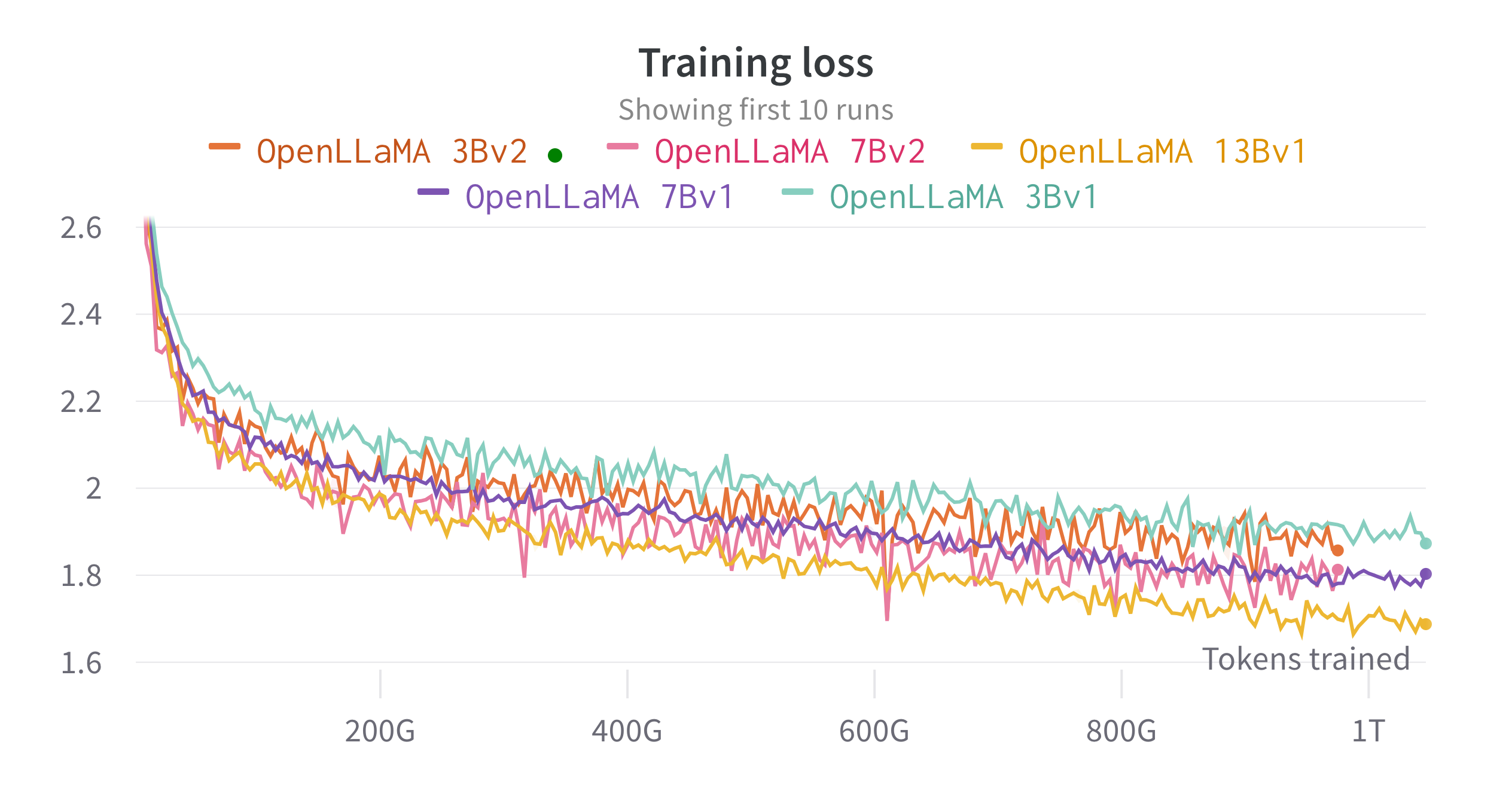
我们使用 lm-evaluation-harness 在广泛的任务上评估了 OpenLLaMA。 LLaMA 结果是通过在相同的评估指标上运行原始 LLaMA 模型来生成的。我们注意到,我们的 LLaMA 模型结果与原始 LLaMA 论文略有不同,我们认为这是不同评估协议的结果。本期 lm-evaluation-harness 也报告了类似的差异。此外,我们还展示了 GPT-J 的结果,这是一个由 EleutherAI 在 Pile 数据集上训练的 6B 参数模型。
最初的 LLaMA 模型针对 1 万亿个代币进行了训练,而 GPT-J 则针对 5000 亿个代币进行了训练。我们将结果呈现在下表中。 OpenLLaMA 在大多数任务中表现出与原始 LLaMA 和 GPT-J 相当的性能,并且在某些任务中优于它们。
| 任务/指标 | GPT-J 6B | 美洲驼7B | 美洲驼13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | OpenLLAMA 3B | OpenLLAMA 7B | OpenLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/acc | 0.32 | 0.35 | 0.35 | 0.33 | 0.34 | 0.33 | 0.33 | 0.33 |
| anli_r2/acc | 0.34 | 0.34 | 0.36 | 0.36 | 0.35 | 0.32 | 0.36 | 0.33 |
| anli_r3/acc | 0.35 | 0.37 | 0.39 | 0.38 | 0.39 | 0.35 | 0.38 | 0.40 |
| arc_challenge/acc | 0.34 | 0.39 | 0.44 | 0.34 | 0.39 | 0.34 | 0.37 | 0.41 |
| arc_challenge/acc_norm | 0.37 | 0.41 | 0.44 | 0.36 | 0.41 | 0.37 | 0.38 | 0.44 |
| arc_easy/acc | 0.67 | 0.68 | 0.75 | 0.68 | 0.73 | 0.69 | 0.72 | 0.75 |
| arc_easy/acc_norm | 0.62 | 0.52 | 0.59 | 0.63 | 0.70 | 0.65 | 0.68 | 0.70 |
| 布尔克/acc | 0.66 | 0.75 | 0.71 | 0.66 | 0.72 | 0.68 | 0.71 | 0.75 |
| 海拉斯瓦格/acc | 0.50 | 0.56 | 0.59 | 0.52 | 0.56 | 0.49 | 0.53 | 0.56 |
| hellaswag/acc_norm | 0.66 | 0.73 | 0.76 | 0.70 | 0.75 | 0.67 | 0.72 | 0.76 |
| 开卷质量保证/ACC | 0.29 | 0.29 | 0.31 | 0.26 | 0.30 | 0.27 | 0.30 | 0.31 |
| openbookqa/acc_norm | 0.38 | 0.41 | 0.42 | 0.38 | 0.41 | 0.40 | 0.40 | 0.43 |
| 皮卡/ACC | 0.75 | 0.78 | 0.79 | 0.77 | 0.79 | 0.75 | 0.76 | 0.77 |
| piqa/acc_norm | 0.76 | 0.78 | 0.79 | 0.78 | 0.80 | 0.76 | 0.77 | 0.79 |
| 记录/em | 0.88 | 0.91 | 0.92 | 0.87 | 0.89 | 0.88 | 0.89 | 0.91 |
| 记录/f1 | 0.89 | 0.91 | 0.92 | 0.88 | 0.89 | 0.89 | 0.90 | 0.91 |
| 实时通讯/加速器 | 0.54 | 0.56 | 0.69 | 0.55 | 0.57 | 0.58 | 0.60 | 0.64 |
| truefulqa_mc/mc1 | 0.20 | 0.21 | 0.25 | 0.22 | 0.23 | 0.22 | 0.23 | 0.25 |
| truefulqa_mc/mc2 | 0.36 | 0.34 | 0.40 | 0.35 | 0.35 | 0.35 | 0.35 | 0.38 |
| wic/acc | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.48 | 0.51 | 0.47 |
| 维诺格兰德/ACC | 0.64 | 0.68 | 0.70 | 0.63 | 0.66 | 0.62 | 0.67 | 0.70 |
| 平均的 | 0.52 | 0.55 | 0.57 | 0.53 | 0.56 | 0.53 | 0.55 | 0.57 |
我们从基准测试中删除了任务 CB 和 WSC,因为我们的模型在这两个任务上的表现令人怀疑。我们假设训练集中可能存在基准数据污染。
我们很乐意获得社区的反馈。如果您有任何疑问,请提出问题或联系我们。
OpenLLaMA 由来自 Berkeley AI Research 的 Xinyang Geng* 和 Hao Liu* 开发。 *平等贡献
我们感谢 Google TPU Research Cloud 计划提供部分计算资源。我们要特别感谢 TPU Research Cloud 的 Jonathan Caton 帮助我们组织计算资源、Google Cloud 团队的 Rafi Witten 和 Google JAX 团队的 James Bradbury 帮助我们优化训练吞吐量。我们还要感谢 Charlie Snell、Gautier Izacard、Eric Wallace、Lianmin Cheng 以及我们的用户社区的讨论和反馈。
OpenLLaMA 13B v1 模型是与 Stability AI 合作训练的,我们感谢 Stability AI 提供的计算资源。我们要特别感谢 David Ha 和 Shivanshu Purohit 协调后勤工作并提供工程支持。
如果您发现 OpenLLaMA 对您的研究或应用有用,请使用以下 BibTeX 进行引用:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


