LLM4Decompile
1.0.0
![]()
结果 | ?型号| 快速入门 | HumanEval-反编译 | ?引文| 纸| 科拉布 |
逆向工程:使用大型语言模型反编译二进制代码
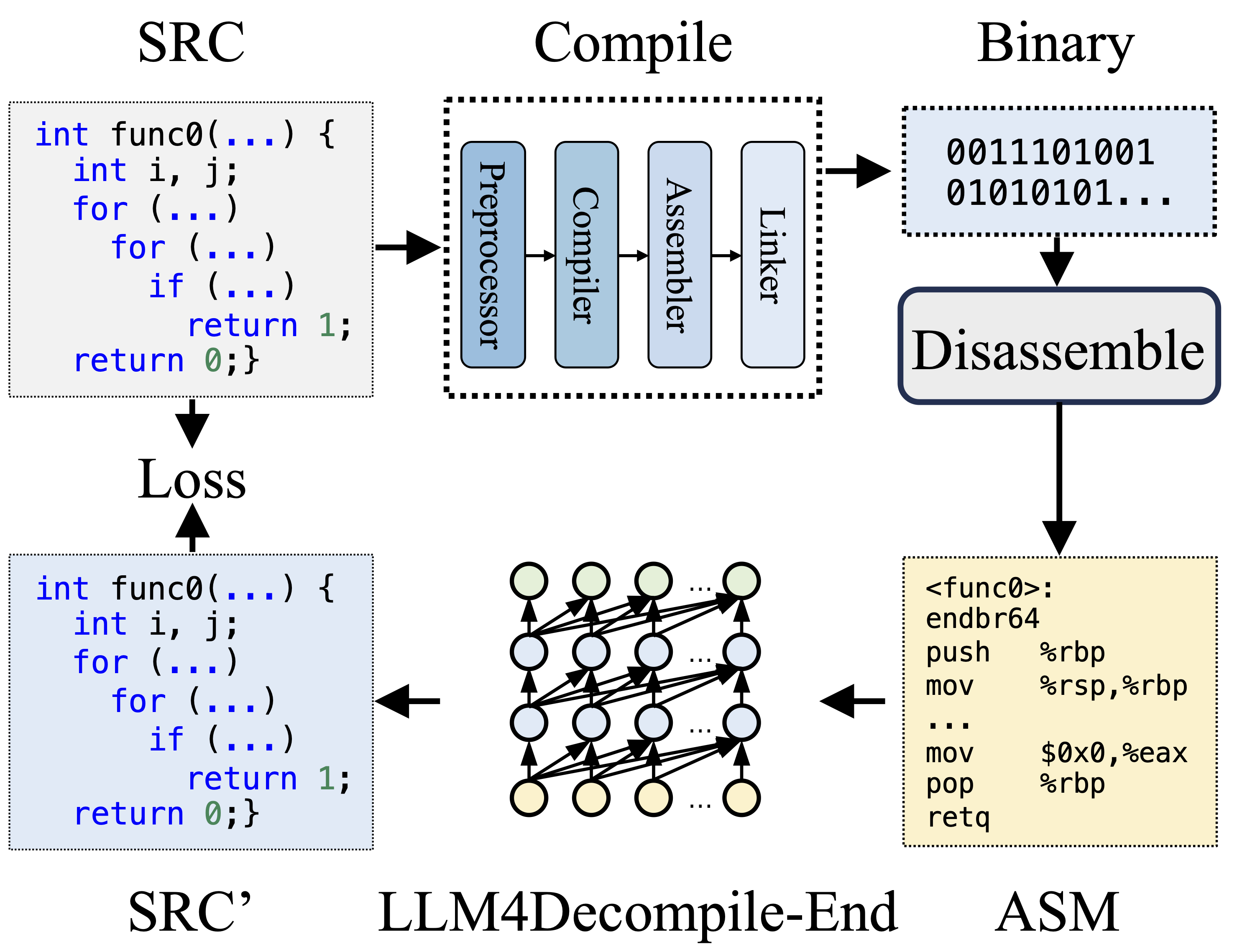
在编译期间,预处理器处理源代码 (SRC) 以消除注释并扩展宏或包含。然后,清理后的代码被转发到编译器,编译器将其转换为汇编代码 (ASM)。该 ASM 由汇编器转换为二进制代码(0 和 1)。链接器通过链接函数调用来创建可执行文件来完成该过程。另一方面,反编译涉及将二进制代码转换回源文件。受过文本训练的法学硕士缺乏直接处理二进制数据的能力。因此,二进制文件必须首先被Objdump反汇编为汇编语言(ASM)。应该注意的是,二进制和反汇编的 ASM 是等效的,它们可以相互转换,因此我们可以互换使用它们。最后,计算反编译代码和源代码之间的损失以指导训练。为了评估反编译代码 (SRC') 的质量,通过测试断言(可重新执行性)对其功能进行测试。
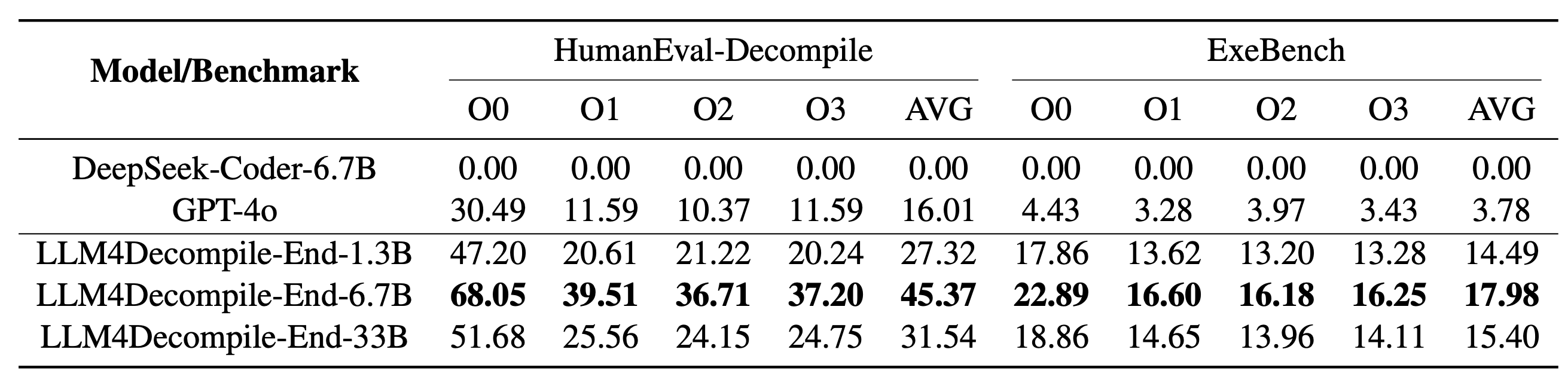
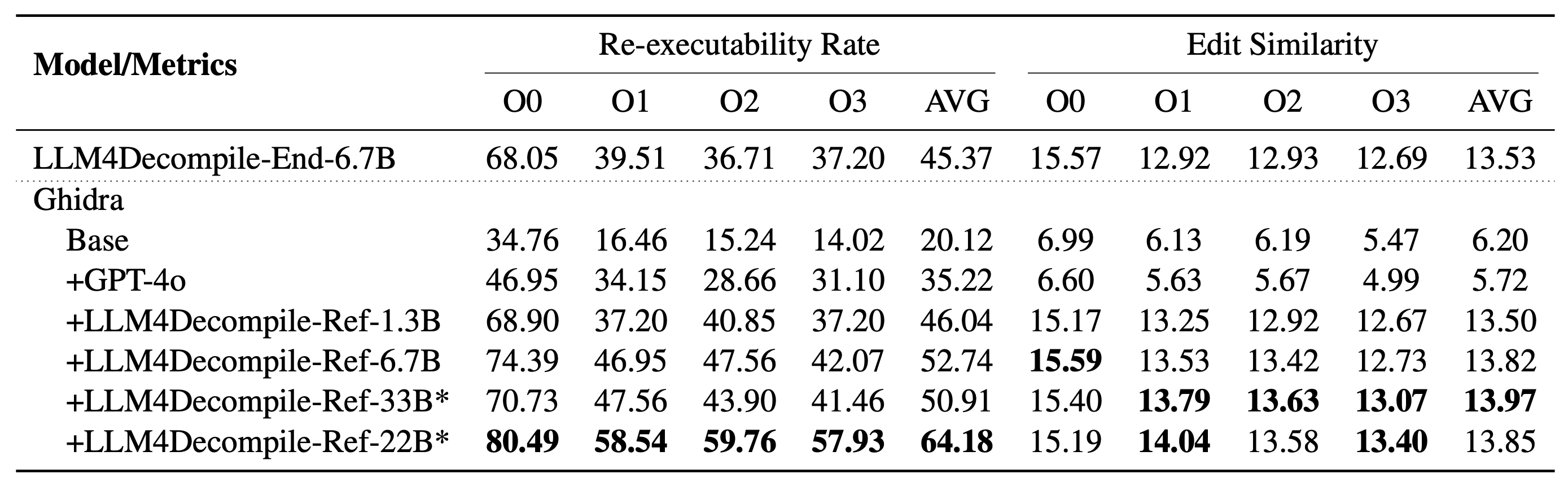
我们的 LLM4Decompile 包含参数大小在 13 亿到 330 亿之间的模型,并且我们已在 Hugging Face 上提供这些模型。
| 模型 | 检查站 | 尺寸 | 可重复执行性 | 笔记 |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ?高频链路 | 1.3B | 27.3% | 注3 |
| llm4decompile-6.7b-v1.5 | ?高频链路 | 6.7B | 45.4% | 注3 |
| llm4decompile-1.3b-v2 | ?高频链路 | 1.3B | 46.0% | 注4 |
| llm4decompile-6.7b-v2 | ?高频链路 | 6.7B | 52.7% | 注4 |
| llm4decompile-9b-v2 | ?高频链路 | 9B | 64.9% | 注4 |
| llm4decompile-22b-v2 | ?高频链路 | 22B | 63.6% | 注4 |
注3:V1.5系列使用更大的数据集(15B token)和最大token大小4,096进行训练,与之前的模型相比,具有显着的性能(超过100%的改进)。
注 4:V2 系列基于Ghidra构建,并在 20 亿个代币上进行训练,以细化Ghidra 反编译的伪代码。检查 ghidra 文件夹以获取详细信息。
安装:请使用下面的脚本安装必要的环境。
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
以下是如何使用我们的模型的示例(针对 V1.5 进行了修订。对于以前的模型,请在 HF 上查看相应的模型页面)。注意:将“func0”替换为你要反编译的函数名。
预处理:将C代码编译为二进制,并将二进制反汇编为汇编指令。
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )组装说明应采用以下格式:
<FUNCTION_NAME>:n操作n操作n
典型的组装指令可能如下所示:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
反编译:使用LLM4Decompile将汇编指令翻译成C:
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' )数据存储在llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json中,使用 JSON 列表格式。有 164*4(O0、O1、O2、O3)个样本,每个样本有 5 个键:
task_id :表示问题的ID。type :优化阶段,是[O0, O1, O2, O3]之一。c_func :HumanEval 问题的 C 解决方案。c_test :C 测试断言。input_asm_prompt :带有提示的汇编指令,可以像我们的预处理示例一样导出。请检查评估脚本。
此代码存储库已根据 MIT 和 DeepSeek 许可证获得许可。
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


