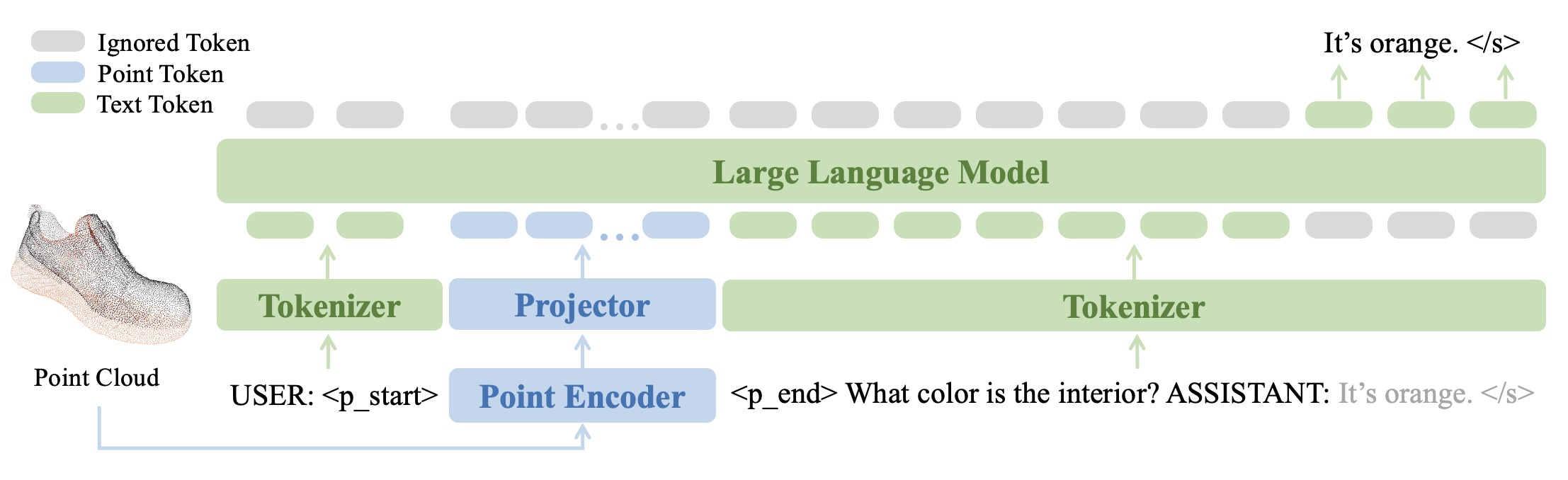
PointLLM
1.0.0
 PointLLM:使大型语言模型能够理解点云
PointLLM:使大型语言模型能够理解点云润森 徐小龙 王泰 王以伦 陈江苗 庞* 林大华
香港中文大学上海人工智能实验室浙江大学

点LLM上线了!请在 http://101.230.144.196 或 OpenXLab/PointLLM 尝试。
您可以与 PointLLM 讨论 Objaverse 数据集的模型或您自己的点云!
如果您有任何反馈,请随时告诉我们! ?
| 对话1 | 对话2 | 对话3 | 对话4 |
|---|---|---|---|
 |  |  |  |
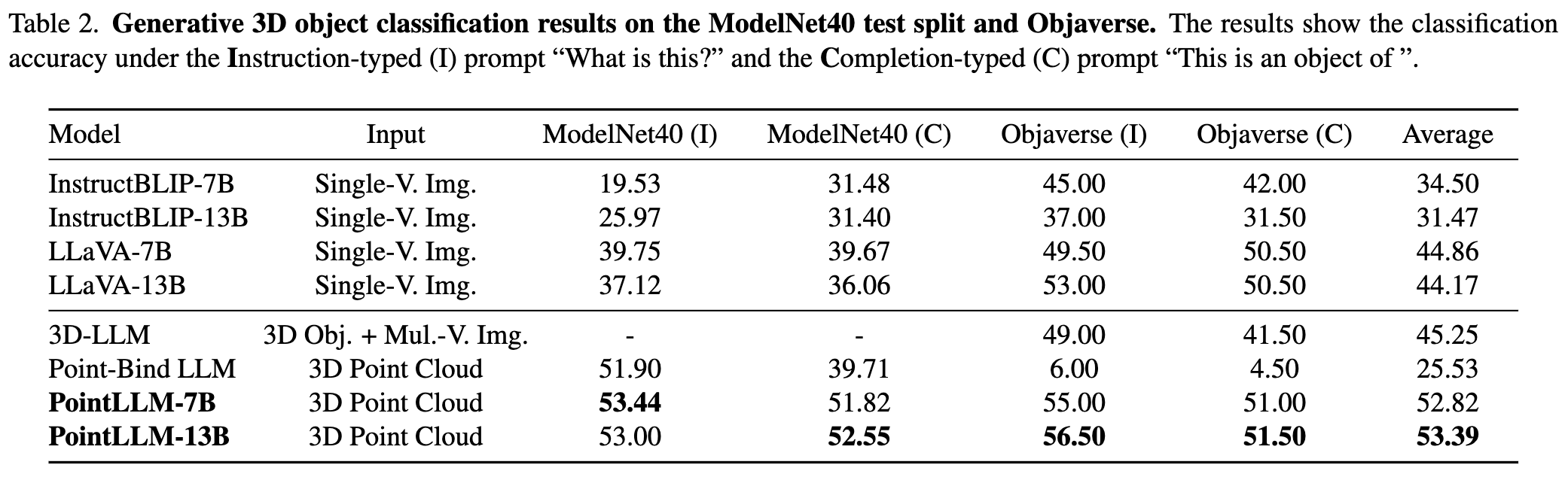
请参阅我们的论文了解更多结果。
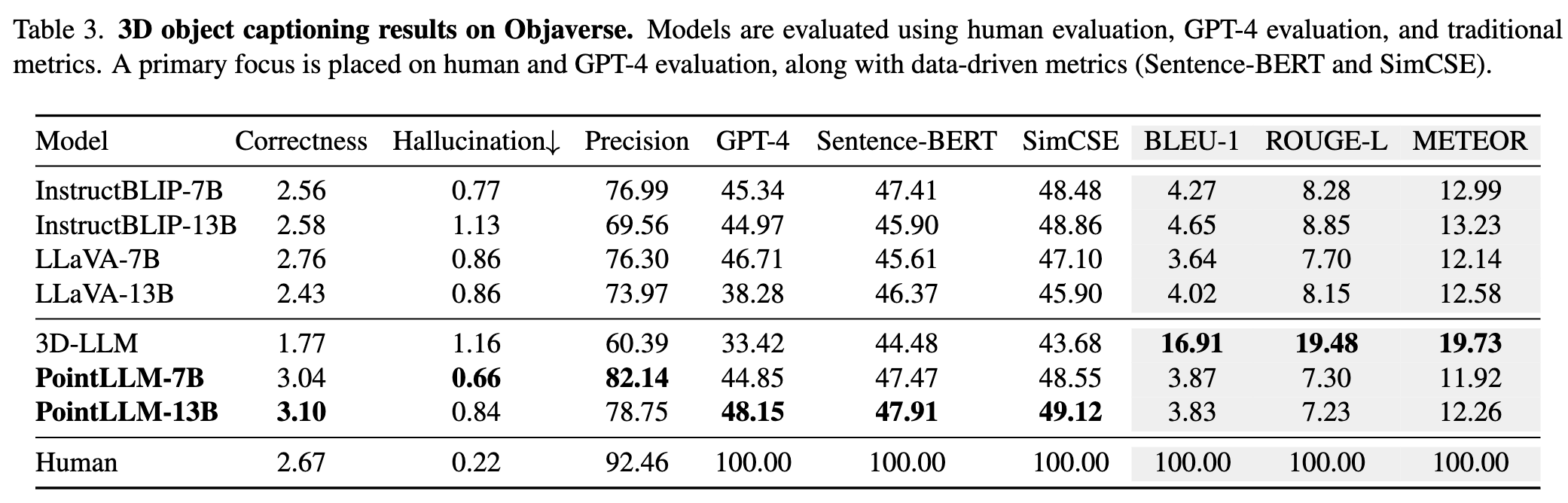
请参阅我们的论文了解更多结果。

我们在以下环境下测试我们的代码:
开始:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy的文件夹,其中包含名为{Objaverse_ID}_8192.npy 660K 点云文件。每个文件都是一个维度为 (8192, 6) 的 numpy 数组,其中前三个维度是xyz ,后三个维度是 [0, 1] 范围内的rgb 。 cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM文件夹中,创建一个文件夹data ,并在该目录下创建一个指向未压缩文件的软链接。 cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data文件夹中,创建一个名为anno_data的目录。anno_data目录中。该目录应如下所示: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json是通过删除我们保留作为验证集的 3000 个对象从PointLLM_brief_description_660K.json中过滤出来的。如果您想重现我们论文中的结果,您应该使用PointLLM_brief_description_660K_filtered.json进行训练。 PointLLM_complex_instruction_70K.json包含训练集中的对象。pointllm/data/data_generation/system_prompt_gpt4_0613.txt 。 PointLLM_brief_description_val_200_GT.json ,并将其放入PointLLM/data/anno_data 。我们还提供了我们在训练期间过滤的 3000 个对象 ID 以及它们相应的引用 GT,可用于对所有 3000 个对象进行评估。PointLLM/data中创建名为modelnet40_data的目录。在此处下载 ModelNet40 点云modelnet40_test_8192pts_fps.dat的测试分割并将其放入PointLLM/data/modelnet40_data中。PointLLM文件夹中,创建一个名为checkpoints的目录。checkpoints目录中。 cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.sh通常情况下,您不必关心以下内容。它们仅用于重现我们 v1 论文 (PointLLM-v1.1) 中的结果。如果您想与我们的模型进行比较或使用我们的模型进行下游任务,请使用PointLLM-v1.2(参考我们的v2论文),它具有更好的性能。
PointLLM v1.1 和 v1.2 使用略有不同的预训练点编码器和投影仪。如果要重现PointLLM v1.1,请编辑初始LLM和点编码器权重目录中的config.json文件,例如vim checkpoints/PointLLM_7B_v1.1_init/config.json 。
更改键"point_backbone_config_name"以指定另一个点编码器配置:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1在scripts/train_stage1.sh中编辑点编码器的检查点路径:
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32数据类型启动聊天机器人,以讨论 Objaverse 的 3D 模型。模型检查点将自动下载。您还可以手动下载模型检查点并指定其路径。这是一个例子: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32您还可以轻松修改使用 Objaverse 以外的点云的代码,只要输入模型的点云具有维度 (N, 6),其中前三个维度为xyz ,后三个维度为rgb (在 [0, 1] 范围内)。您可以对点云进行采样以获得 8192 个点,因为我们的模型是在此类点云上进行训练的。
下表显示了不同模型和数据类型的 GPU 要求。如果适用,我们建议使用torch.bfloat16 ,它在我们论文的实验中使用。
| 模型 | 数据类型 | 显存 |
|---|---|---|
| 点LLM-7B | 火炬.float16 | 14GB |
| 点LLM-7B | 火炬.float32 | 28GB |
| PointLLM-13B | 火炬.float16 | 26GB |
| PointLLM-13B | 火炬.float32 | 52GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation中,格式如下: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C中断评估过程。这将保存临时结果。如果评估过程中发生错误,脚本也会保存当前状态。您可以通过再次运行相同的命令从中断处恢复评估。{model_name}/evaluation中。部分指标解释如下: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval标志并指定--gpt_type在推理后立即开始评估。例如: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_output欢迎社区贡献!?如果您需要任何支持,请随时提出问题或联系我们。
如果您发现我们的工作和此代码库有帮助,请考虑为该存储库加注星标?并引用:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
本作品采用知识共享署名-非商业性-相同方式共享 4.0 国际许可证。
让我们一起让 3D 法学硕士变得更伟大!


