thumb
1.0.0
一个简单的法学硕士即时测试库。
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])默认情况下,每个提示异步运行 10 次,这比顺序运行快大约 9 倍。在 Jupyter Notebooks 中,会显示一个简单的用户界面,用于盲评响应(您看不到哪个提示生成了响应)。
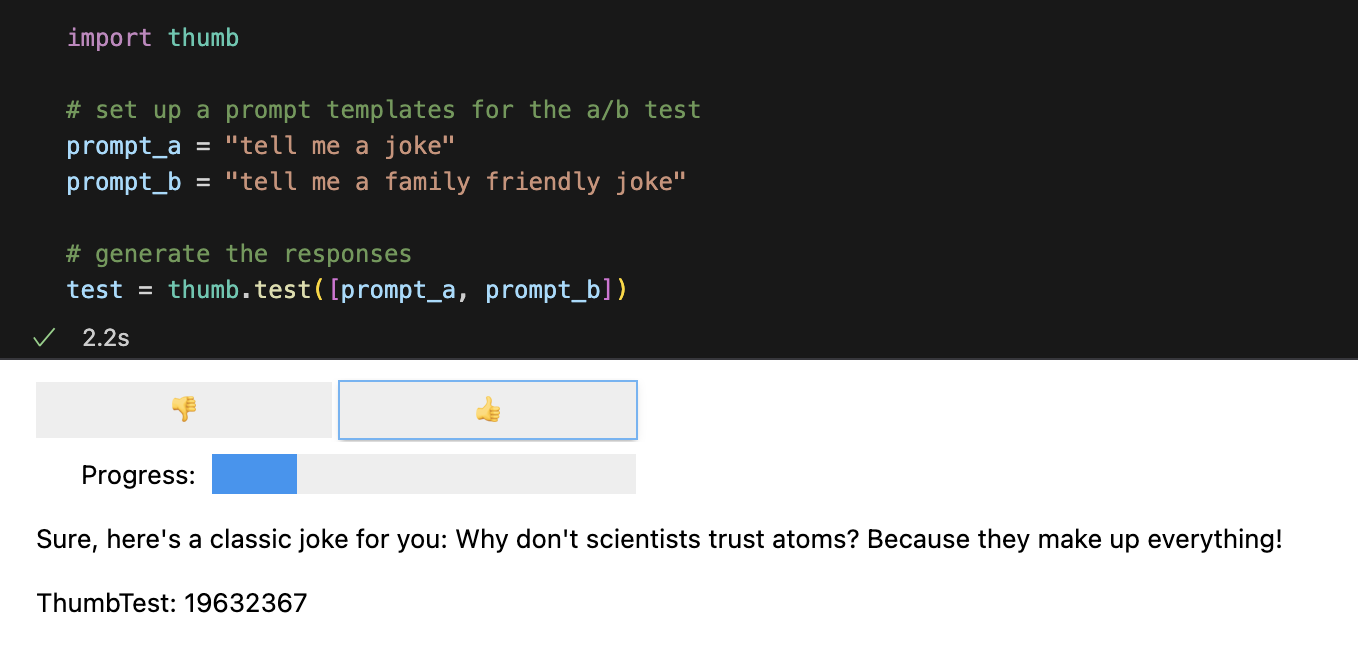
对所有响应进行评级后,将按提示模板细分计算以下性能统计数据:
avg_score正反馈量占所有运行的百分比avg_tokens :提示和响应中使用了多少个令牌avg_cost :平均运行提示成本的估计笔记本中会显示一个简单的报告,完整的数据将保存到 CSV 文件thumb/ThumbTest-{TestID}.csv中。

测试用例是指当您想要使用不同的输入变量测试提示模板时。例如,如果您想要测试包含喜剧演员姓名变量的提示模板,您可以为不同的喜剧演员设置测试用例。
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )每个测试用例都将针对每个提示模板运行,因此在本示例中,您将获得 6 个组合(3 个测试用例 x 2 个提示模板),每个组合将运行 10 次(总共 60 次对 OpenAI 的调用)。每个测试用例必须包含提示模板中每个变量的值。
每个测试用例中的提示可能有多个变量。例如,如果您想要测试包含喜剧演员姓名变量和笑话主题的提示模板,您可以为不同的喜剧演员和主题设置测试用例。
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )每个案例都会针对每个提示进行测试,以便在给定相同输入数据的情况下对每个提示的性能进行公平比较。通过 4 个测试用例和 2 个提示,您将获得 8 种组合(4 个测试用例 x 2 个提示模板),每个组合将运行 10 次(总共 80 次对 OpenAI 的调用)。
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])这将针对每个模型运行每个提示,以便在给定相同输入数据的情况下对每个提示的性能进行公平比较。通过 2 个提示和 2 个模型,您将获得 4 种组合(2 个提示 x 2 个模型),每个组合将运行 10 次(总共 40 次调用 OpenAI)。
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )提示可以是字符串或字符串数组。如果提示是数组,则第一个字符串用作系统消息,其余提示在人类消息和助理消息之间交替( [system, human, ai, human, ai, ...] )。这对于测试包含系统消息或使用预热的提示(将先前的消息插入聊天中以引导 AI 实现所需的行为)非常有用。
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )测试完成后,您将获得一份完整的评估报告,按 PID、CID 和型号细分,以及按所有组合细分的总体报告。如果您只测试一种模型或一种情况,这些故障将被丢弃。报告底部显示一个按键,可查看哪个 ID 对应于哪个提示或案例。
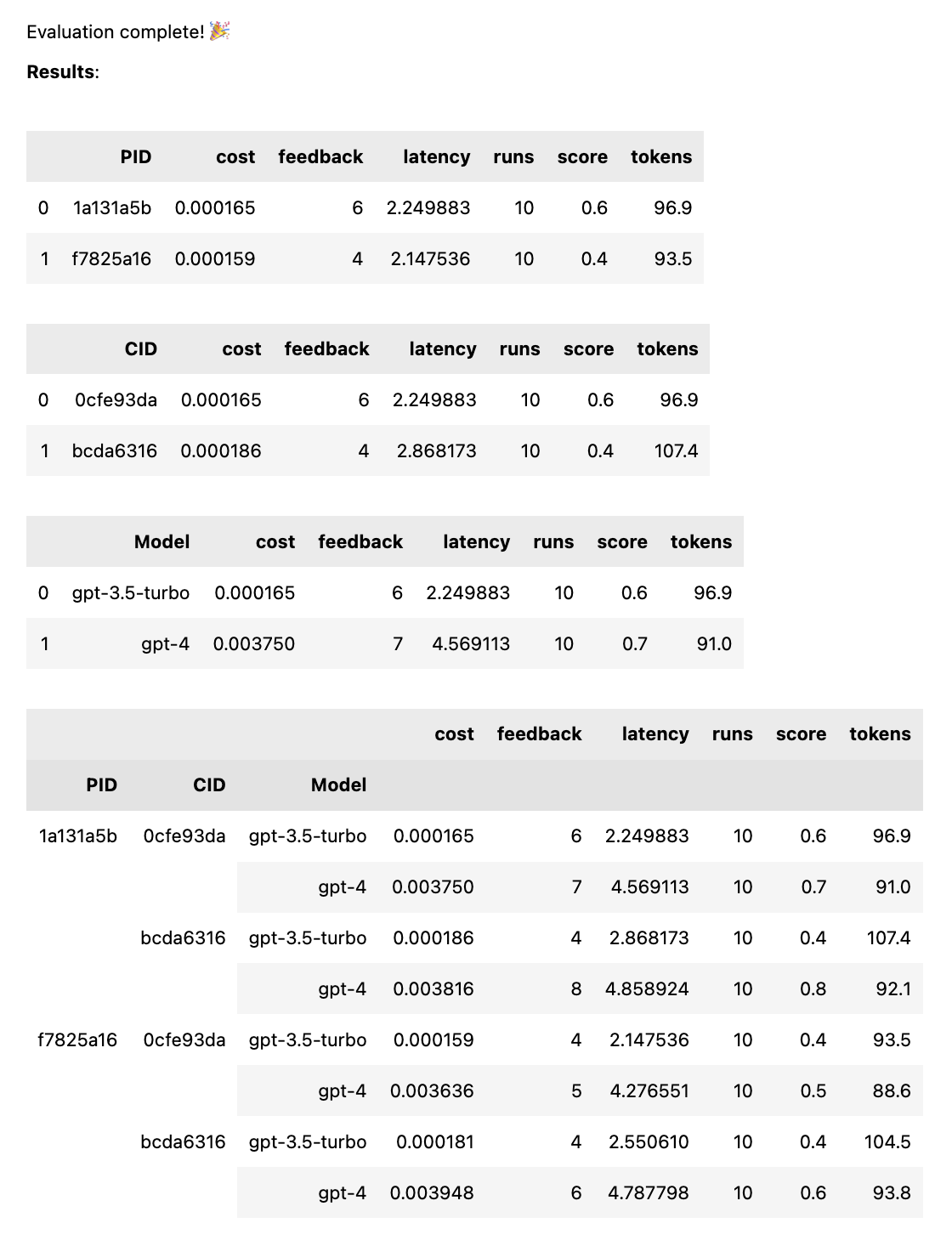
thumb.test函数采用以下参数:
None )10 )gpt-3.5-turbo ])True )如果您使用 2 个提示模板和 3 个测试用例运行 10 次测试,则需要10 x 2 x 3 = 60调用 OpenAI。请注意:特别是使用 GPT-4 时,成本会迅速增加!
如果LANGCHAIN_API_KEY设置为环境变量(可选),则会自动启用对 LangSmith 的 Langchain 跟踪。
.test()函数返回一个ThumbTest对象。您可以向测试添加更多提示或案例,或者多次运行测试。您还可以随时生成、评估和导出测试数据。
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv ()每个提示模板从每个测试用例获取相同的输入数据,但提示不需要使用测试用例中的所有变量。如上例所示, tell me a knock knock joke提示不使用subject变量,但它仍然为每个测试用例生成一次(没有变量)。
在为提示和大小写组合生成每组运行后,测试数据缓存在本地 JSON 文件thumb/.cache/{TestID}.json中。如果你的测试被中断,或者你想添加测试,你可以使用thumb.load函数从缓存加载测试数据。
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv ()提示和案例的每种组合的每次运行都存储在对象(和缓存)中,因此,如果未添加更多提示、案例或运行,再次调用test.generate()将不会生成任何新响应。同样,再次调用test.evaluate()不会重新评估您已经评分的响应,而只会在测试结束时重新显示结果。
仅仅使用 ChatGPT 的人和在生产中使用 AI 的人之间的区别在于评估。法学硕士的反应是不确定的,因此测试在各种场景中扩展时的结果非常重要。如果没有评估框架,您将只能盲目地猜测提示中的内容有效(或无效)。
认真的提示工程师正在测试和了解哪些输入会可靠且大规模地产生有用或所需的输出。这个过程称为提示优化,如下所示:
拇指测试填补了大规模专业评估机制和盲目试错提示之间的空白。如果您要将提示转换到生产环境,使用thumb测试提示可以帮助您捕获边缘情况,并尽早获得用户或团队对结果的反馈。
这些人在业余时间制作thumb是为了好玩。 ?
锤子山 |


