llm data annotation
1.0.0
该框架将人类专业知识与 OpenAI 的 GPT-3.5 等大型语言模型 (LLM) 的效率相结合,以简化数据集注释和模型改进。迭代方法确保了数据质量的持续改进,从而确保使用这些数据微调模型的性能。这不仅节省了时间,还可以创建定制的法学硕士,利用人工注释者和基于法学硕士的精度。
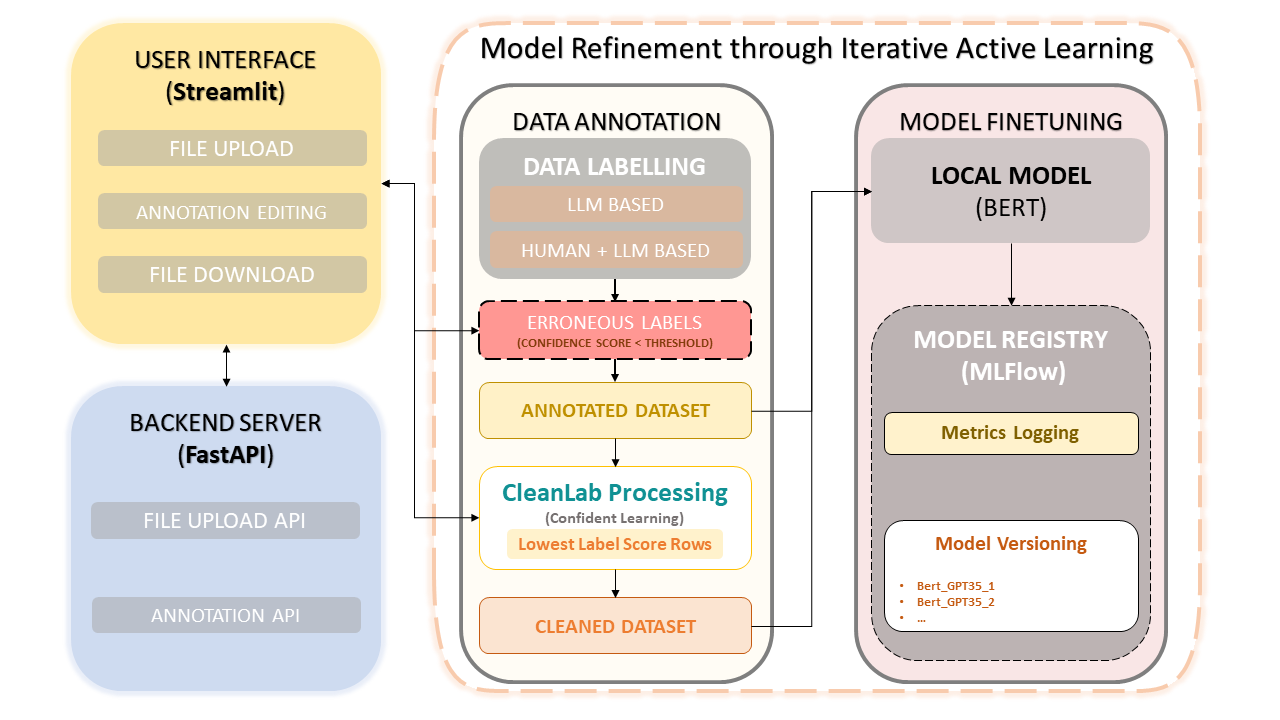
数据集上传与标注
手动注释更正
CleanLab:自信的学习方法
数据版本控制和保存
模型训练
pip install -r requirements.txt启动 FastAPI 后端:
uvicorn app:app --reload运行 Streamlit 应用程序:
streamlit run frontend.py启动 MLflow UI :要查看模型、指标和注册模型,您可以使用以下命令访问 MLflow UI:
mlflow ui在网络浏览器中访问提供的链接:
http://127.0.0.1:5000 。按照屏幕上的提示上传、注释、更正和训练数据集。
置信学习已成为监督学习和弱监督领域的突破性技术。它的目的是表征标签噪声,发现标签错误,并利用噪声标签进行有效学习。通过修剪噪声数据并对示例进行排序以自信地进行训练,该方法可确保数据集干净可靠,从而提高整体模型性能。
该项目是根据 MIT 许可证开源的。


