gen ai document sumarization
1.0.0
该项目探讨了开源生成式人工智能模型(特别是基于 Transformer 架构的模型)在自动总结文档内容方面的潜力。目标是评估和应用现有的生成式人工智能模型来分析、理解上下文并生成非结构化文档的摘要。
为了实现这一目标,我对两个著名的模型进行了微调:t5-small 和 facebook/bart-base,重点是增强它们的摘要性能。
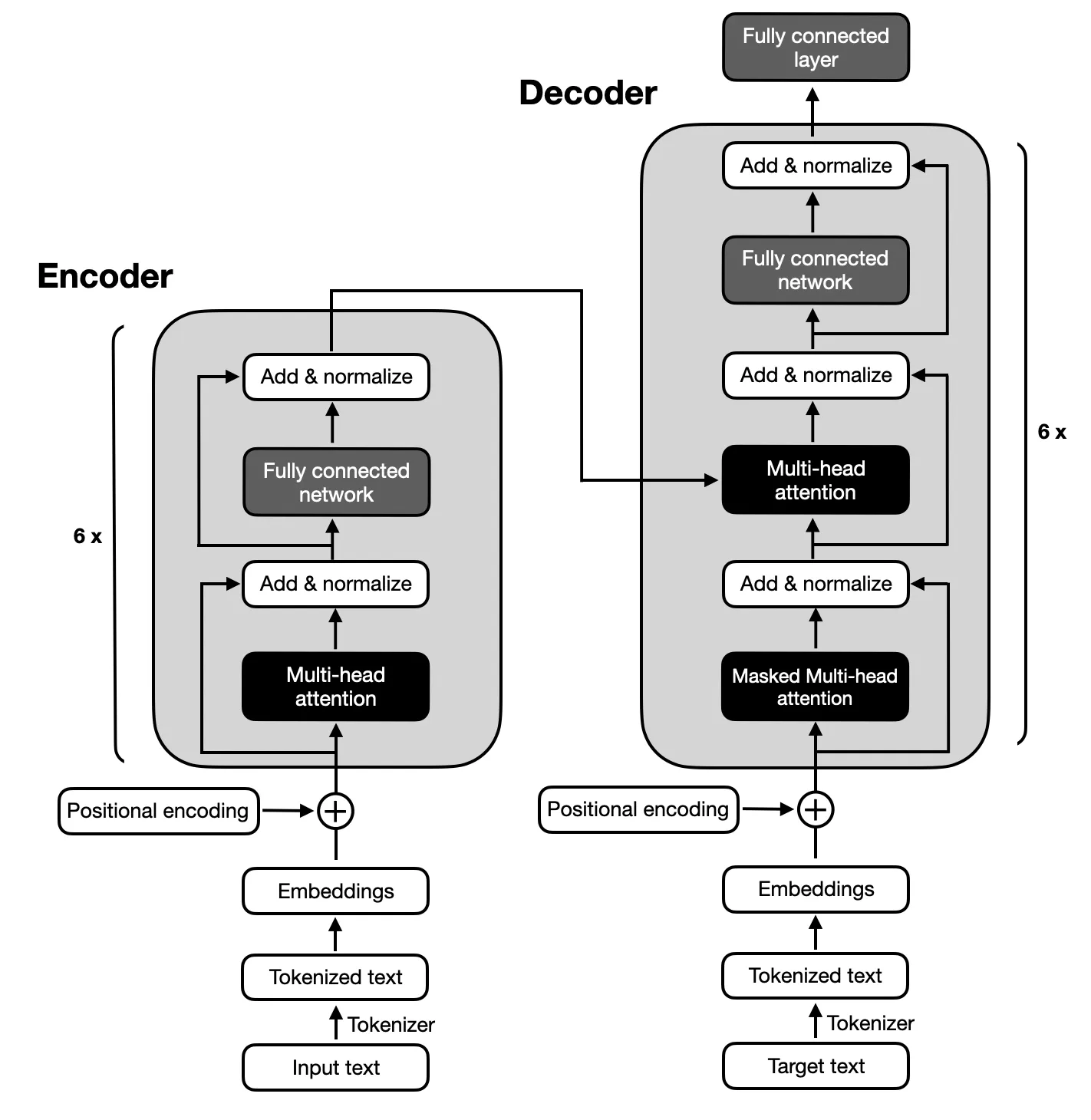
由于文本摘要所需的输入和输出序列之间的复杂映射,重点是遵循原始 Transformer 提出的架构的编码器-解码器模型。编码器-解码器模型擅长捕获这些序列内的关系,使其适合此任务。
确保您的系统上安装了 Python 3.x。然后,按照以下步骤设置您的环境:
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.py该项目包括六个主要阶段:
用于微调 T5 和 BART 模型的数据集是大专利数据集,该数据集由 130 万份美国专利文档及其人工撰写的摘要摘要组成。该数据集中的每个文档均按照合作专利分类 (CPC) 代码进行分类,涵盖从人类必需品到物理和电力的广泛主题。这种多样性确保模型能够遇到各种各样的语言使用和技术术语,这对于开发强大的摘要能力至关重要。
选择大专利数据集是因为它与总结复杂文档的项目目标相关。专利本质上是详细和技术性的,这使得它们成为测试模型在保留核心内容和背景的同时压缩信息的能力的理想挑战。该数据集的结构化格式和高质量摘要的存在为训练和评估模型在生成准确且连贯的摘要方面的性能奠定了坚实的基础。
使用 ROUGE 指标评估模型的性能,强调它们生成与人类撰写的摘要密切相关的摘要的能力。 BART和T5模型均使用专利大数据集进行微调,重点是实现高质量的摘要摘要。
| 公制 | 价值 |
|---|---|
| 评估损失(Eval Loss) | 1.9244 |
| 胭脂-1 | 0.5007 |
| 胭脂2号 | 0.2704 |
| 胭脂-L | 0.3627 |
| 红-Lsum | 0.3636 |
| 平均世代长度 (Gen Len) | 122.1489 |
| 运行时间(秒) | 1459.3826 |
| 每秒采样数 | 1.312 |
| 每秒步数 | 0.164 |
| 公制 | 价值 |
|---|---|
| 评估损失(Eval Loss) | 1.9984 |
| 胭脂-1 | 0.503 |
| 胭脂2号 | 0.286 |
| 胭脂-L | 0.3813 |
| 红-Lsum | 0.3813 |
| 平均世代长度 (Gen Len) | 151.918 |
| 运行时间(秒) | 714.4344 |
| 每秒采样数 | 2.679 |
| 每秒步数 | 0.336 |


