WilmerAI
1.0.0
这是一个正在大力开发的个人项目。它可能而且很可能包含错误、不完整的代码或其他意外问题。因此,该软件按原样提供,不提供任何形式的保证。
WilmerAI 反映了单个开发人员的工作及其个人时间和资源的努力;其中的任何观点、方法等均为他自己的观点,不应反映其雇主。
WilmerAI 是一个复杂的中间件系统,旨在接收传入的提示并在将它们发送到 LLM API 之前对其执行各种任务。这项工作包括利用大型语言模型 (LLM) 对提示进行分类并将其路由到适当的工作流程或处理大型上下文(200,000+ 标记)以生成适合大多数本地模型的更小、更易于管理的提示。
WilmerAI 代表“如果语言模型专业地路由所有推理会怎样?”
由多个法学硕士串联提供支持的助理:传入的提示可以路由到“类别”,每个类别都由工作流程提供支持。每个工作流程可以有任意数量的节点,每个节点由不同的 LLM 提供支持。例如,如果您问您的助手“您可以用 python 为我编写一个贪吃蛇游戏吗?”,这可能会被归类为“编码”并进入您的编码工作流程。该工作流程的第一个节点可能会要求 Codestral-22b(或 ChatGPT 4o,如果您愿意)回答问题。第二个节点可能会要求 Deepseek V2 或 Claude Sonnet 对其进行代码审查。下一个节点可能会要求 Codestral 进行最后一次检查,然后回复您。无论您的工作流程只是单个模型响应(因为它是您最好的编码器),还是不同法学硕士的许多节点一起工作以生成响应,选择权都在您手中。
支持离线维基百科 API :WilmerAI 有一个可以调用 OfflineWikipediaTextApi 的节点。这意味着您可以有一个类别(例如“FACTUAL”),它会查看传入的消息,从中生成查询,查询 wikipedia API 中的相关文章,并使用该文章作为 RAG 上下文注入来响应。
持续生成聊天摘要以模拟“记忆” :“聊天摘要”节点将通过对消息进行分块然后汇总并将其保存到文件中来生成“记忆”。然后,它将获取这些摘要块并生成整个对话的持续、不断更新的摘要,可以在 LLM 的提示中提取和使用。结果允许您进行 200k+ 上下文对话,并保持相对跟踪所说内容,即使将 LLM 的提示限制为 5k 上下文或更少。
使用多台计算机并行处理记忆和响应:如果您有 2 台可以运行 LLM 的计算机,您可以指定其中一台作为“响应者”,另一台负责生成记忆/摘要。这种工作流程可以让您在更新记忆/摘要的同时继续与法学硕士交谈,同时仍然使用现有的记忆。这意味着不需要等待摘要更新,即使您分配一个大型且强大的模型来处理该任务,以便您拥有更高质量的记忆。 (参见示例用户convo-role-dual-model )
SillyTavern 中的多个 LLM 群组聊天:如果您愿意,可以使用 Wilmer 在 ST 中进行群组聊天,其中每个角色都是不同的 LLM(作者亲自这样做)。Docs DocsSillyTavern中提供了示例角色,分成两组。这些示例字符/组是作者使用的较大组的子集。
中间件功能: WilmerAI 位于用于与 LLM 通信的接口(例如 SillyTavern、OpenWebUI,甚至 Python 程序的终端)和为 LLM 提供服务的后端 API 之间。它可以同时处理多个后端 LLM。
一次使用多个 LLM:示例设置:SillyTavern -> WilmerAI -> KoboldCpp 的多个实例。例如,Wilmer 可以连接到 Command-R 35b、Codestral 22b、Gemma-2-27b,并在返回给用户的响应中使用所有这些。只要您选择的 LLM 通过 v1/Completion 或 chat/Completion 端点或 KoboldCpp 的生成端点公开,您就可以使用它。
可自定义的预设:预设保存在您可以轻松自定义的 json 文件中。几乎所有 about 预设都可以通过 json 进行管理,包括参数名称。这意味着您不必等待 Wilmer 更新即可使用新功能。例如,DRY 最近在 KoboldCpp 上发布。如果 Wilmer 的预设 json 中没有该内容,您应该能够简单地添加它并开始使用它。
API 端点:它提供 OpenAI API 兼容的chat/Completions和v1/Completions端点以通过前端连接,并且可以连接到后端的任一类型。这允许进行复杂的配置,例如作为 v1/Completion API 连接到 Wilmer,然后让 Wilmer 连接到聊天/Completion、v1/Completion KoboldCpp 同时生成端点。
提示模板:支持v1/Completions API 端点的提示模板。 WilmerAI 还拥有自己的提示模板,用于通过v1/Completions从前端进行连接。该模板可以在“Docs”文件夹中找到,并且可以上传到 SillyTavern。
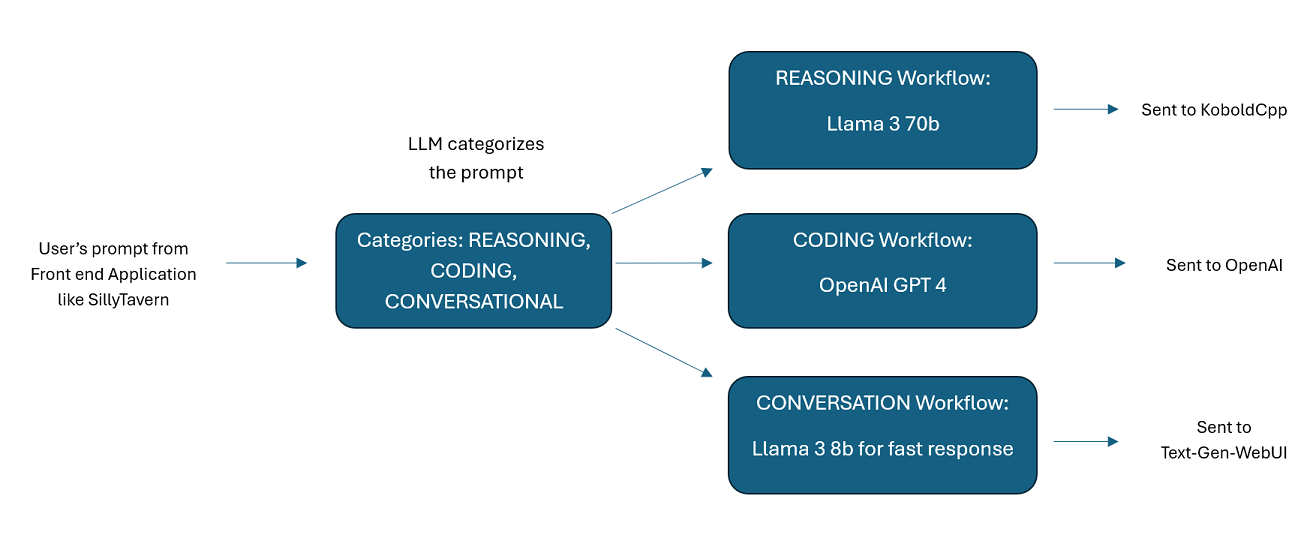
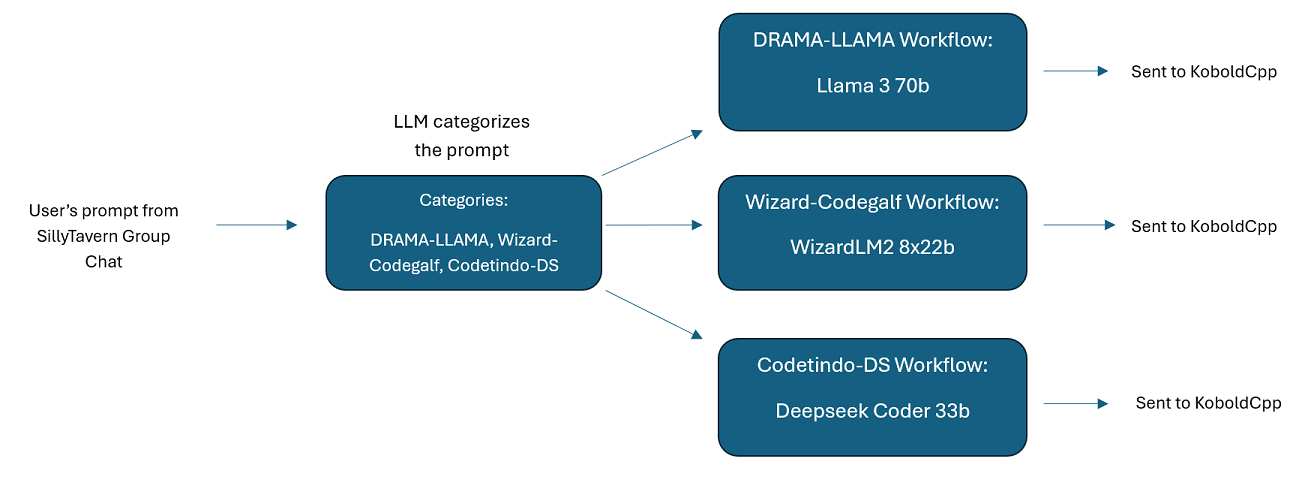
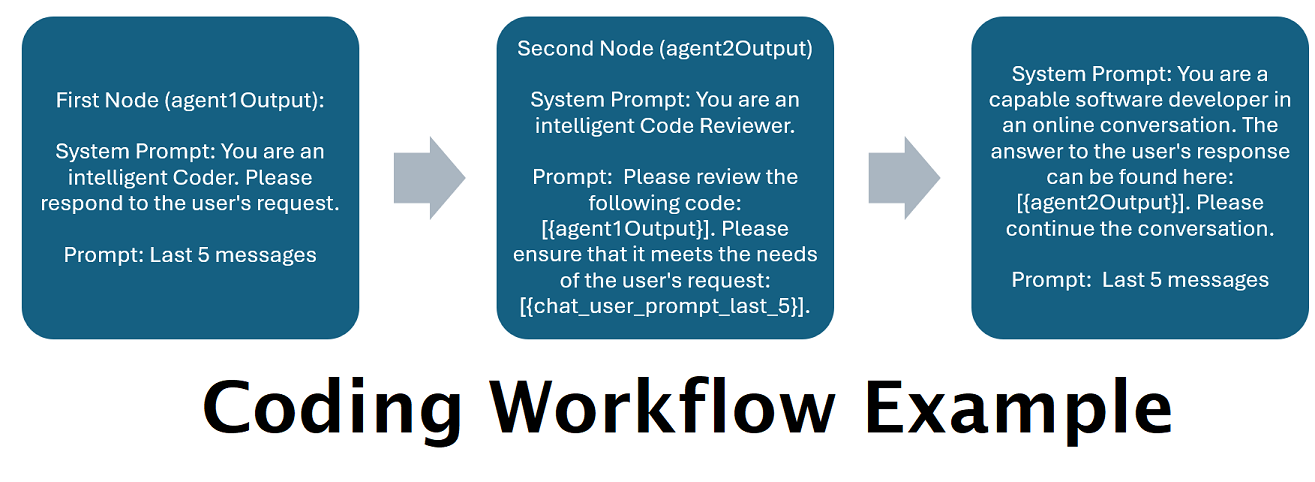
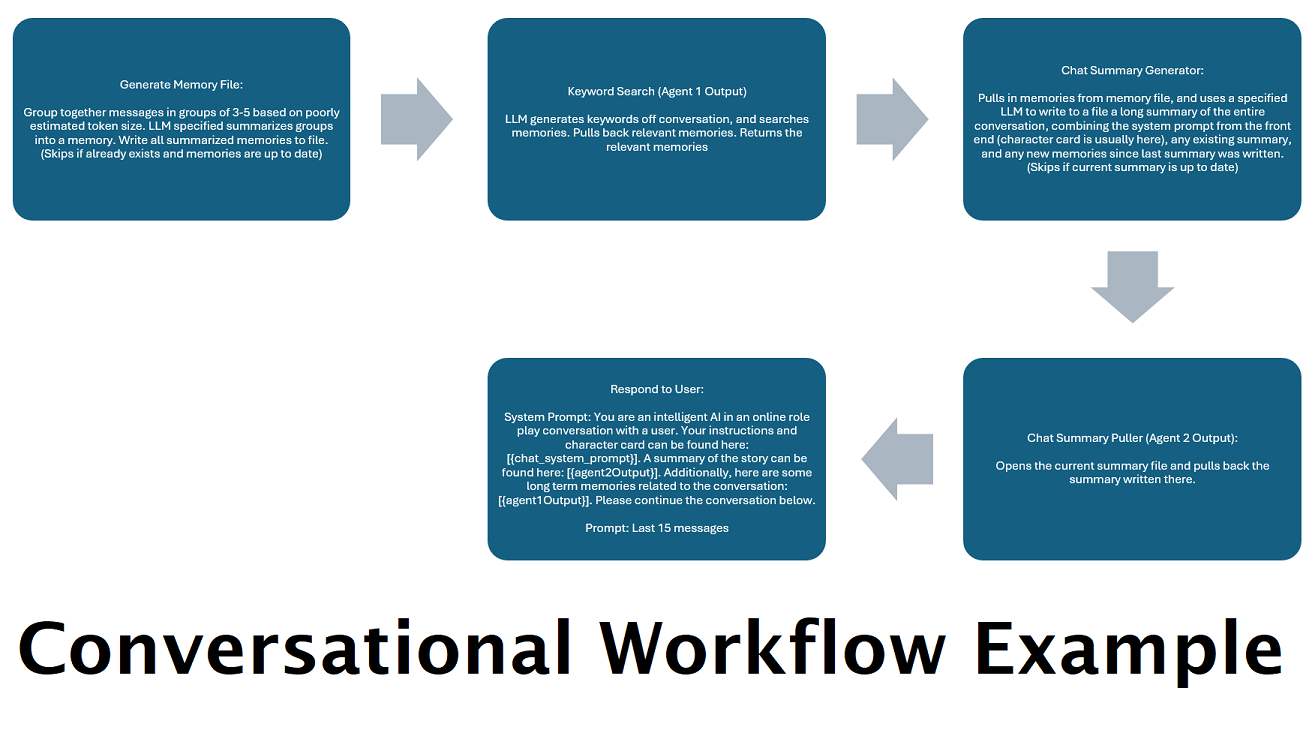

请记住,工作流就其本质而言,可能会根据您的设置方式对 API 端点进行多次调用。 WilmerAI 不跟踪代币使用情况,不通过其 API 报告准确的代币使用情况,也不提供任何可行的方法来监控代币使用情况。因此,如果出于成本原因,令牌使用跟踪对您很重要,请务必通过 LLM API 向您提供的任何仪表板跟踪您正在使用的令牌数量,尤其是在您习惯该软件的早期。
你的LLM直接影响WilmerAI的质量。这是一个法学硕士驱动的项目,其中的流量和输出几乎完全取决于所连接的法学硕士及其响应。如果您将 Wilmer 连接到产生较低质量输出的模型,或者您的预设或提示模板有缺陷,那么 Wilmer 的整体质量也会低得多。在这方面,它与代理工作流程没有太大不同。
虽然作者正在尽最大努力做出有用且高质量的东西,但这是一个雄心勃勃的个人项目,必然会遇到问题(特别是因为作者本身并不是 Python 开发人员,并且严重依赖人工智能来帮助他实现这一目标)远的)。不过,他正在慢慢弄清楚。
Wilmer 公开了 OpenAI v1/Completions 和聊天/Completions 端点,使其与大多数前端兼容。虽然我主要将其与 SillyTavern 一起使用,但它也可能与 Open-WebUI 一起使用。
要在 SillyTavern 中作为文本完成进行连接,请按照以下步骤操作(以下屏幕截图来自 SillyTavern):
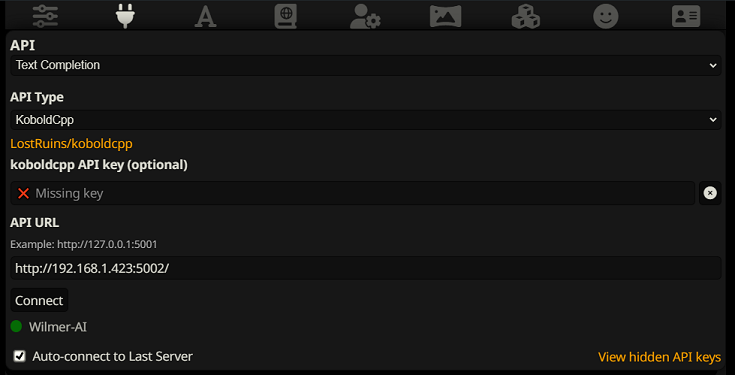
使用文本补全时,您需要使用 WilmerAI 特定的提示模板格式。可以在Docs/SillyTavern/InstructTemplate中找到可导入的 ST 文件。如果您也想使用上下文模板,那么它也包含在内。
指令模板如下所示:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
来自愚蠢的酒馆:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
标签之间没有预期的换行符或字符。
请确保上下文模板处于“启用”状态(下拉列表上方的复选框)
要在 SillyTavern 中作为聊天完成进行连接,请按照以下步骤操作(以下屏幕截图来自 SillyTavern):
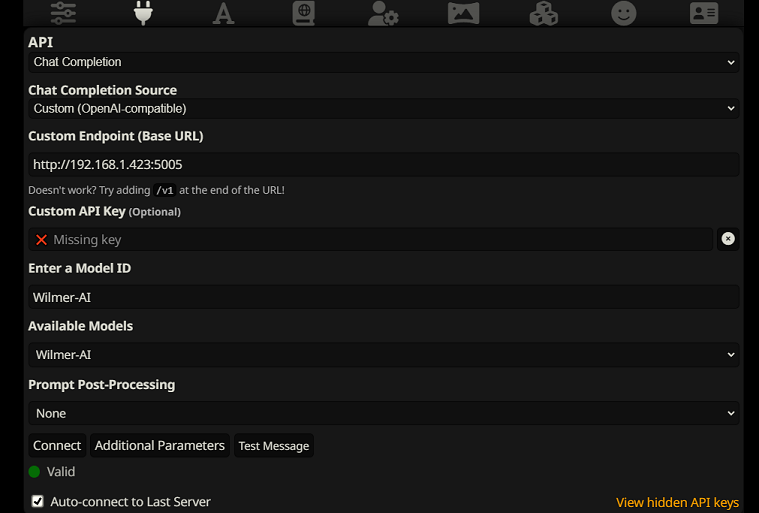
chatCompleteAddUserAssistant设置为 true。 (我不建议同时将两者设置为 true。要么使用 SillyTavern 中的角色名称,要么使用 Wilmer 中的用户/助理。否则 AI 可能会感到困惑。)对于任一连接类型,我建议转到 SillyTavern 中的“A”图标,并在指示模式下选择“包含名称”和“强制组和角色”,然后转到最左侧的图标(采样器所在的位置)并选中“左上角的“stream”,然后右上角检查上下文下的“解锁”并将其拖动到 200,000+。让威尔默担心上下文吧。
Wilmer 目前没有用户界面;一切都通过位于“Public”文件夹中的 JSON 配置文件进行控制。该文件夹包含所有必要的配置。更新或下载 WilmerAI 的新副本时,您只需将“公共”文件夹复制到新安装即可保留您的设置。
本节将引导您完成 Wilmer 的设置。我已将这些部分分成步骤;我可能建议将每个步骤一一复制到法学硕士中,并要求它帮助您设置该部分。这可能会让事情变得容易得多。
重要注意事项
关于 Wilmer 设置,需要注意三件事,这一点很重要。
A) 预设文件是 100% 可定制的。该文件中的内容将发送至 llm API。这是因为云 API 不处理本地 LLM API 处理的各种预设中的一些。因此,如果您使用 OpenAI API 或其他云服务,并且使用常规本地 AI 预设之一,则调用可能会失败。请参阅预设的“OpenAI-API”,了解 openAI 接受的示例。
B) 我最近替换了 Wilmer 中的所有提示,从使用第二人称变为第三人称。这对我来说已经取得了相当不错的结果,我希望对你来说也是如此。
C) 默认情况下,所有用户文件都设置为打开流响应。您要么需要在调用 Wilmer 的前端中启用此功能,以便两者匹配,要么需要进入 Users/username.json 并将 Stream 设置为“false”。如果出现不匹配,即前端期望/不期望流式传输,而您的 wilmer 期望相反,则前端可能不会显示任何内容。
安装 Wilmer 非常简单。确保你已经安装了Python;作者一直在Python 3.10和3.12上使用该程序,并且都运行良好。
选项 1:使用提供的脚本
为方便起见,Wilmer 包含一个适用于 Windows 的 BAT 文件和适用于 macOS 的 .sh 文件。这些脚本将创建一个虚拟环境,从requirements.txt安装所需的软件包,然后运行 Wilmer。您每次都可以使用这些脚本来启动 Wilmer。
.bat文件。.sh文件。重要信息:切勿在未先检查的情况下运行 BAT 或 SH 文件,因为这可能存在风险。如果您不确定此类文件的安全性,请在记事本/文本编辑中打开它,复制内容,然后要求您的法学硕士检查是否存在任何潜在问题。
选项 2:手动安装
或者,您可以手动安装依赖项并按照以下步骤运行 Wilmer:
安装所需的软件包:
pip install -r requirements.txt启动程序:
python server.py提供的脚本旨在通过设置虚拟环境来简化流程。但是,如果您更喜欢手动安装,则可以安全地忽略它们。
注意:当运行 bat 文件、sh 文件或 python 文件时,这三个文件现在都接受以下可选参数:
因此,例如,考虑以下可能的运行:
bash run_macos.sh (将使用 _current-user.json 中指定的用户,“Public”中的配置,“logs”中的日志)bash run_macos.sh --User "single-model-assistant" (配置默认为 public,日志默认为“log”)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (仅使用“logs”的默认值bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"这些可选参数允许用户启动 WilmerAI 的多个实例,每个实例使用不同的用户配置文件,登录到不同的位置,并在需要时在不同的位置指定配置。
在 Public/Configs 中,您将找到一系列包含 json 文件的文件夹。您最感兴趣的两个是Endpoints文件夹和Users文件夹。
注意: assistant-single-model 、 assistant-multi-model和group-chat-example用户的 Factual 工作流程节点将尝试利用 OfflineWikipediaTextApi 项目将完整的维基百科文章拉至 RAG。如果您没有此 API,工作流程应该不会有任何问题,但我个人使用此 API 来帮助改进我得到的事实响应。您可以在您选择的用户 json 中指定 API 的 IP 地址。
首先,选择您要使用的模板用户:
Assistant-single-model :此模板适用于在所有节点上使用的单个小模型。它还具有许多不同类别类型的路由,并为每个节点使用适当的预设。如果您想知道为什么只有 1 个模型时会有不同类别的路线:这样您就可以为每个类别提供自己的预设,并且还可以为它们制定自定义工作流程。也许您希望编码器进行多次迭代来检查自身,或者通过多个步骤进行推理来思考问题。
Assistant-multi-model :此模板用于串联使用多个模型。查看该用户的端点,您可以看到每个类别都有自己的端点。绝对没有什么可以阻止您为多个类别重复使用相同的 API。例如,您可以使用 Llama 3.1 70b 进行编码、数学和推理,使用 Command-R 35b 08-2024 进行分类、对话和事实分析。不要觉得您需要 10 个不同的模型。这只是为了让您可以根据需要携带那么多。该用户对工作流程中的每个节点使用适当的预设。
convo-roleplay-single-model :该用户使用具有自定义工作流程的单个模型,该模型适合对话,并且应该适合角色扮演(等待反馈以根据需要进行调整)。这会绕过所有路由。
convo-roleplay-dual-model :该用户使用两个具有自定义工作流程的模型,该工作流程适合对话,并且应该适合角色扮演(等待反馈以根据需要进行调整)。这会绕过所有路由。注意:如果您有 2 台可以运行 LLM 的计算机,则此工作流程效果最佳。根据该用户的当前设置,当您向 Wilmer 发送消息时,响应者模型(计算机 1)将回复您。然后工作流将在此时应用“工作流锁”。然后,记忆/聊天摘要模型(计算机 2)将开始更新迄今为止对话的记忆和摘要,并将其传递给响应者以帮助其记住内容。如果您在写入内存时发送另一个提示,响应者(计算机 1)将获取存在的任何摘要并继续响应您。工作流程锁将阻止您重新进入新的记忆部分。这意味着您可以在写入新记忆的同时继续与响应者模型对话。这是一个巨大的性能提升。我已经尝试过,对我来说,响应时间非常惊人。如果没有这个,我会在 30 秒内得到 3-5 次回复,然后突然需要等待 2 分钟才能产生记忆。这样,在我的 Mac Studio 上的 Llama 3.1 70b 上,每条消息每次都是 30 秒。
group-chat-example :该用户是我自己的个人群聊的示例。所包含的角色和组是我使用的实际角色和实际组。您可以在Docs/SillyTavern文件夹中找到示例字符。这些是 SillyTavern 兼容的字符,您可以将它们直接导入到该程序或任何支持 .png 字符导入类型的程序中。开发团队角色每个工作流程只有 1 个节点:他们只是对您做出响应。咨询组角色每个工作流程有 2 个节点:第一个节点生成响应,第二个节点强制角色的“角色”(负责此的端点是businessgroup-speaker端点)。即使您只使用一种模型,群聊角色也能极大地改变您得到的响应。然而,我的目标是为每个角色使用不同的模型(但在组之间重复使用模型;因此,例如,我在每个组中有一个 Llama 3.1 70b 模型角色)。
选择要使用的用户后,需要执行几个步骤:
在 Public/Configs/Endpoints 下更新用户的端点。示例字符被分类到每个文件夹中。用户的端点文件夹在其 user.json 文件的底部指定。您需要为您正在使用的法学硕士正确填写每个端点。您可以在_example-endpoints文件夹下找到一些示例端点。
您需要设置当前用户。您可以在运行 bat/sh/py 文件时使用 --User 参数执行此操作,也可以在 Public/Configs/Users/_current-user.json 中执行此操作。只需将用户名设置为当前用户并保存即可。
您将需要打开您的用户 json 文件并查看选项。您可以在此处设置是否想要流式传输,可以将 IP 地址设置为离线 wiki API(如果您正在使用它),指定您希望回忆/摘要文件在 DiscussionId 流期间的位置,还可以指定您的位置如果您使用工作流锁,希望 sqllite 数据库继续运行。
就是这样!运行 Wilmer,连接到它,你就可以开始了。
首先,我们将设置端点和模型。在 Public/Configs 文件夹中,您应该会看到以下子文件夹。让我们来看看您需要什么。
这些配置文件代表您连接到的 LLM API 端点。例如,以下 JSON 文件SmallModelEndpoint.json定义了一个端点:
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}这些配置文件代表您在使用 Wilmer 时可能遇到的不同 API 类型。
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
}这些文件指定模型的提示模板。考虑以下示例llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
}这些模板适用于所有 v1/Completion 端点调用。如果您不想使用模板,可以使用一个名为_chatonly.json的文件,该文件仅使用换行符来分解消息。
创建和激活用户涉及四个主要步骤。请按照以下说明设置新用户。
首先,在Users文件夹中,为新用户创建一个 JSON 文件。最简单的方法是复制现有的用户 JSON 文件,将其粘贴为副本,然后重命名。以下是用户 JSON 文件的示例:
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0上,如果在另一台计算机上运行,则它在您的网络上可见。支持在不同端口上运行 Wilmer 的多个实例。true时,路由器被禁用,所有提示仅转到指定的工作流,使其成为 Wilmer 的单个工作流实例。customWorkflowOverride为true时要使用的自定义工作流。Routing文件夹中的路由配置文件的名称,不带.json扩展名。DiscussionId时崩溃。chatCompleteAddUserAssistant为true时才使用此选项。DataFinder字符。接下来,更新_current-user.json文件以指定要使用的用户。匹配新用户 JSON 文件的名称,不带.json扩展名。
注意:如果您想在运行 Wilmer 时使用 --User 参数,则可以忽略此选项。
在Routing文件夹中创建路由 JSON 文件。该文件可以任意命名。使用此名称更新用户 JSON 文件中的routingConfig属性,减去.json扩展名。这是路由配置文件的示例:
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json扩展名,如果选择类别,则会触发。 在Workflow文件夹中,创建一个与Users文件夹中的用户名匹配的新文件夹。最快的方法是复制现有用户的文件夹,复制并重命名。
如果您选择不进行其他更改,则需要完成工作流程并更新端点以指向所需的端点。如果您使用的是由 Wilmer 添加的示例工作流程,那么您在这里应该已经没问题了。
在“公共”文件夹中,您应该有:
此项目中的工作流程在用户的特定工作流程文件夹内的Public/Workflows夹中进行修改和控制。例如,如果您的用户名为socg ,并且您的Users文件夹中有一个socg.json文件,那么在工作流中您应该有一个Workflows/socg文件夹。
以下是工作流 JSON 的示例:
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]上述工作流程由对话节点组成。两个节点都做一件简单的事情:向端点处指定的 LLM 发送消息。
title类似。将这些以“One”、“Two”等结尾的名称命名有助于跟踪代理输出。第一个节点的输出保存到{agent1Output} ,第二个节点的输出保存到{agent2Output} ,依此类推。Endpoints文件夹中的 JSON 文件名匹配,不带.json扩展名。Presets文件夹中的 JSON 文件名匹配,不带.json扩展名。false (请参阅上面的第一个示例节点)。如果您发送提示,请将其设置为true (请参阅上面的第二个示例节点)。 NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
您可以在这些提示中使用几个变量。这些将在运行时得到适当替换:
{chat_user_prompt_last_one} :对话中的最后一条消息,没有提示模板标签包装消息。{templated_user_prompt_last_one} :对话中的最后一条消息,包裹在适当的用户/助手提示模板标签中。{chat_system_prompt} :从前端发送的系统提示。通常包含字符卡和其他重要信息。{templated_system_prompt} :从前端的系统提示,包裹在适当的系统提示模板标签中。{agent#Output} : #被您想要的数字替换。每个节点都会生成代理输出。第一个节点始终为1,每个后续节点的增量为{agent2Output} {agent1Output}{category_colon_descriptions} :从Routing JSON文件中摘下类别和描述。{categoriesSeparatedByOr} :拉动类别名称,由“或”隔开。[TextChunk] :并行处理器独有的特殊变量,可能不经常使用。注意:要更深入地了解记忆的工作方式,请参阅《理解回忆》部分
该节点将删除n个记忆次数(或者如果不存在讨论,则最新消息),并在它们之间添加自定义定界符。因此,如果您有一个带有3个记忆的内存文件,然后选择“ n ------------ n”的定界符,那么您可能会得到以下内容:
This is the first memory
---------
This is the second memory
---------
This is the third memory
将此节点与聊天摘要结合在一起,可以使LLM不仅可以收到整个对话的摘要分解,还可以收到摘要所建立的所有记忆的列表,其中可能包含有关有关的更多详细信息它。将这两种内容与最后15-20条消息一起发送在一起,可以使整个聊天的连续和持久记忆的印象到最新消息。特殊护理为产生记忆的良好提示可以帮助确保捕获您所关心的细节,而忽略相关细节的细节。
该节点不会产生新的记忆。因此,如果您在多计算机设置上使用了工作流锁,则可以尊重工作流锁。目前,生成记忆的最佳方法是FullChatsummary节点。


