synthetic data generator
0.2.3
切换语言:简体中文 | 最新 API 文档 | 路线图 | 加入微信群
Colab 示例:法学硕士:数据合成 | 法学硕士:表外推理| 十亿级数据支持CTGAN
综合数据生成器 (SDG) 是一个专门的框架,旨在生成高质量的结构化表格数据。
合成数据不包含任何敏感信息,但保留了原始数据的基本特征,使其不受 GDPR 和 ADPPA 等隐私法规的约束。
高质量的合成数据可以在数据共享、模型训练和调试、系统开发和测试等各个领域安全地利用。
我们很高兴您能来到这里,并期待您的贡献,通过此贡献概述指南开始该项目!
我们目前的主要成就和时间表如下:
2024 年 11 月 21 日:1) 模型集成 - 我们已将GaussianCopula模型集成到我们的数据处理器系统中。查看此 PR 中的代码示例; 2)合成质量——我们实现了数据列关系的自动检测并允许关系规范,提高了合成数据的质量(代码示例); 3) 性能增强 - 我们显着减少了 GaussianCopula 在处理离散数据时的内存使用量,从而能够使用2C4G设置对数千个分类数据条目进行训练!
2024年5月30日:数据处理器模块正式合并。该模块将:1)帮助SDG在输入模型之前转换一些数据列(例如Datetime列)的格式(以避免被视为离散类型),并将模型生成的数据反向转换为原始格式; 2)对各种数据类型进行更多定制化的预处理和后处理; 3)轻松处理原始数据中的空值等问题; 4)支持插件系统。
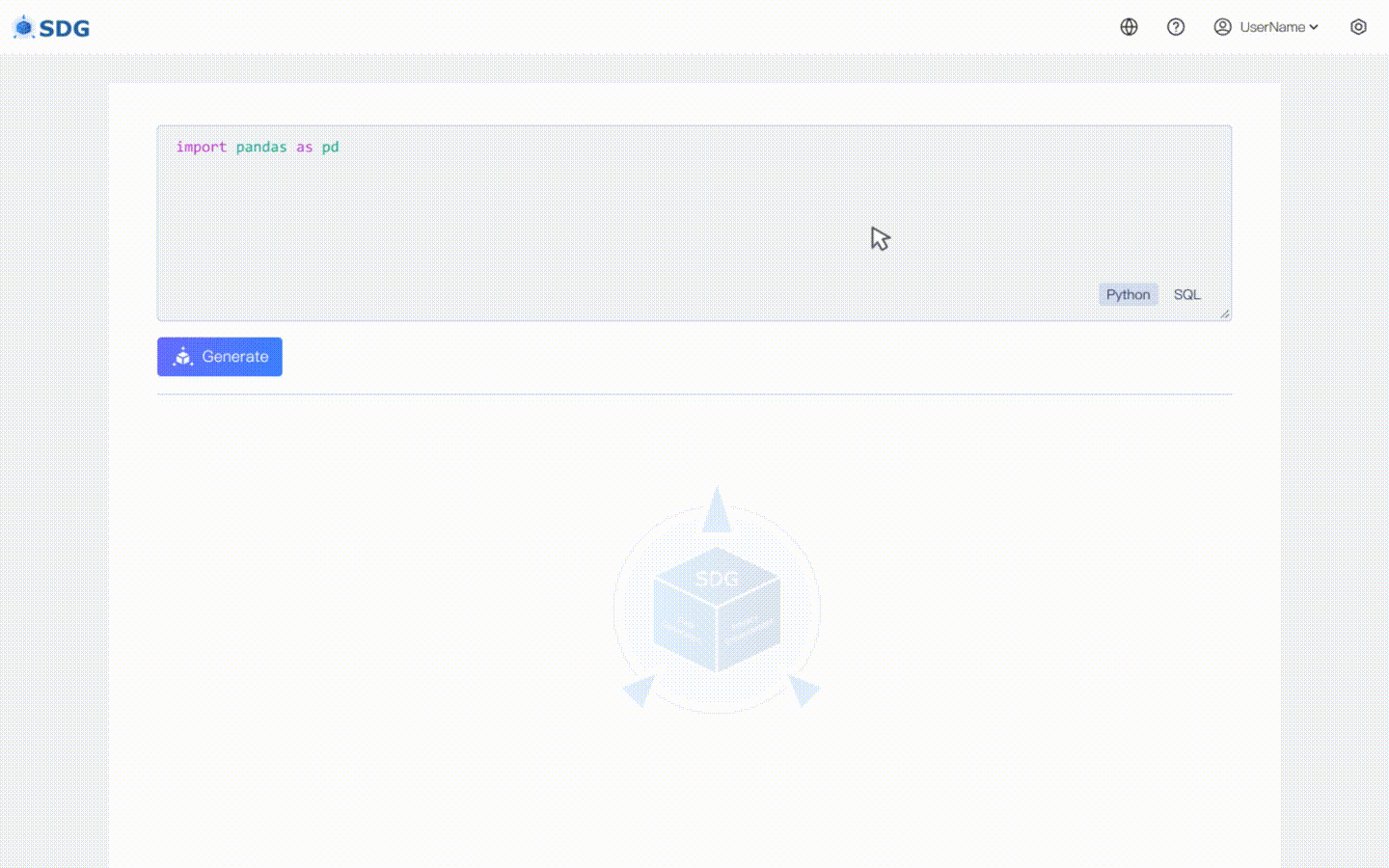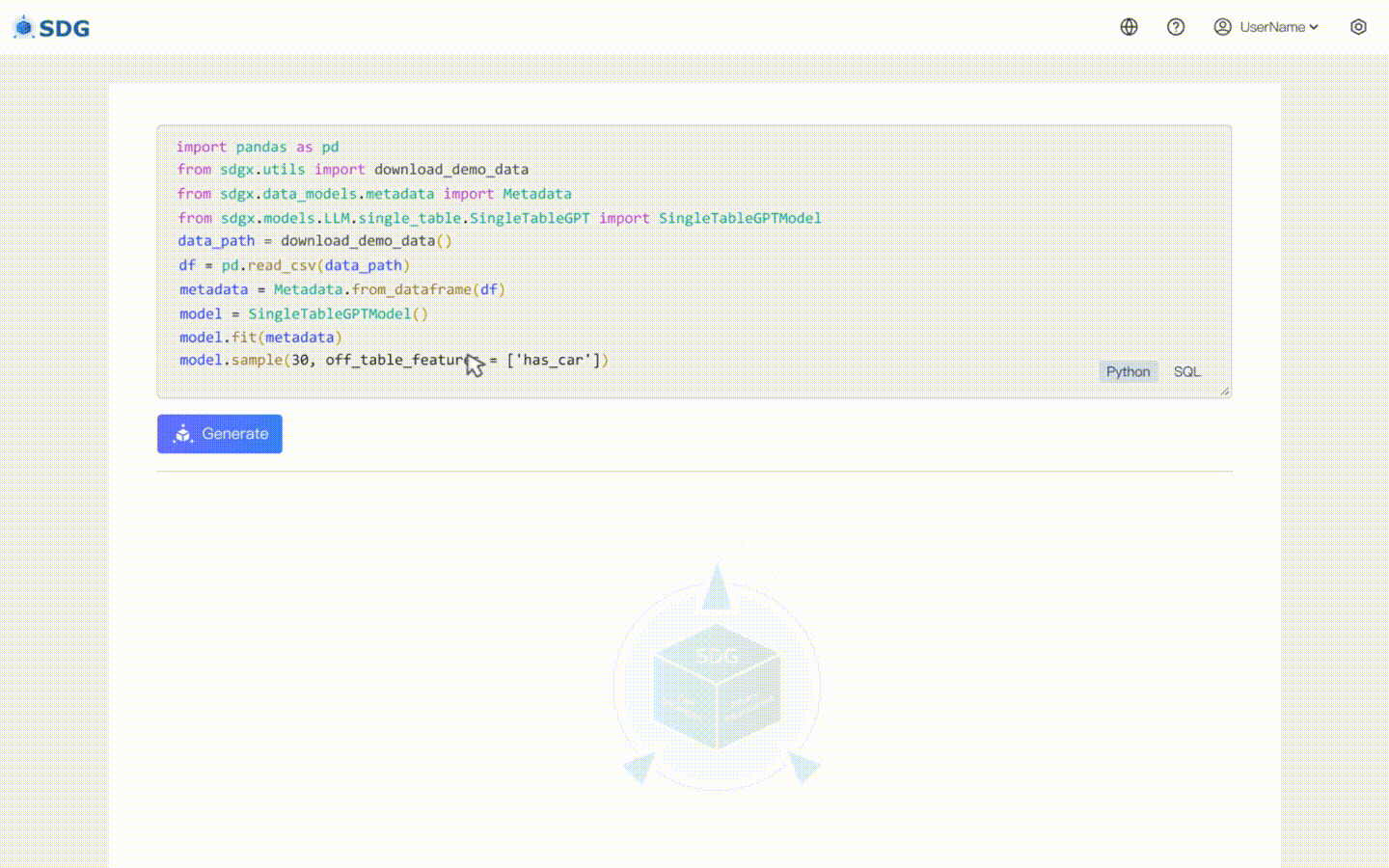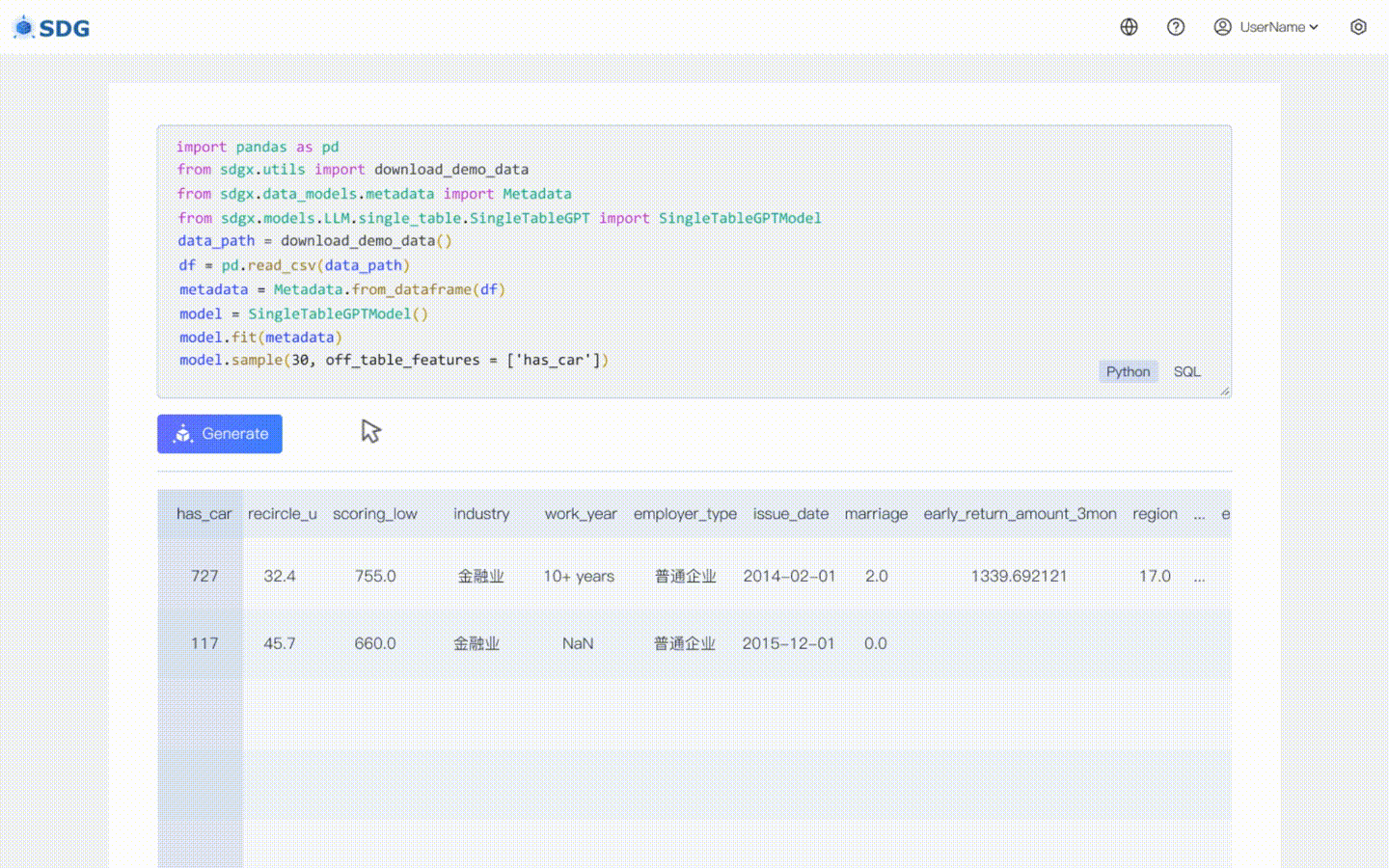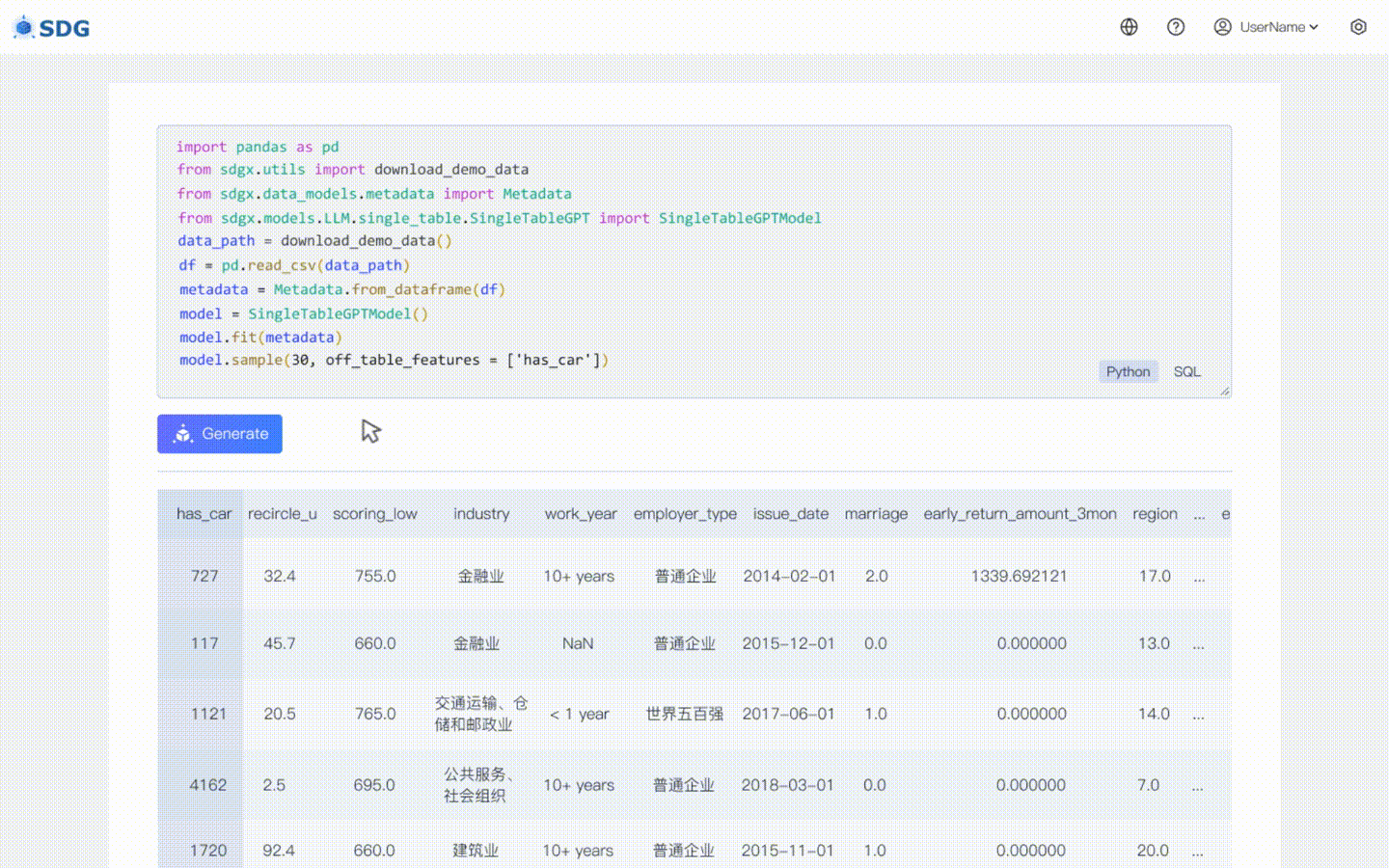
2024年2月20日:包含基于LLM的单表数据合成模型,查看colab示例:LLM:数据合成和LLM:表外特征推理。
2024年2月7日:我们改进了sdgx.data_models.metadata ,支持单表和多表的元数据信息描述,支持多种数据类型,支持自动数据类型推断。查看colab示例:SDG单表元数据。
2023年12月20日:v0.1.0发布,包含支持数十亿数据处理能力的CTGAN模型,查看我们针对SDV的基准测试,其中SDG实现了更少的内存消耗并避免了训练期间的崩溃。具体使用请查看colab示例:Billion-Level-Data支持的CTGAN。
2023 年 8 月 10 日:提交 SDG 代码的第一行。
长期以来,LLM一直被用来理解和生成各种类型的数据。事实上,LLM在表格数据生成方面也有一定的能力。而且,它还具有一些传统(基于GAN方法或统计方法)无法实现的能力。
我们的sdgx.models.LLM.single_table.gpt.SingleTableGPTModel实现了两个新功能:
不需要训练数据,可以根据元数据生成合成数据,请在我们的 Colab 示例中查看。
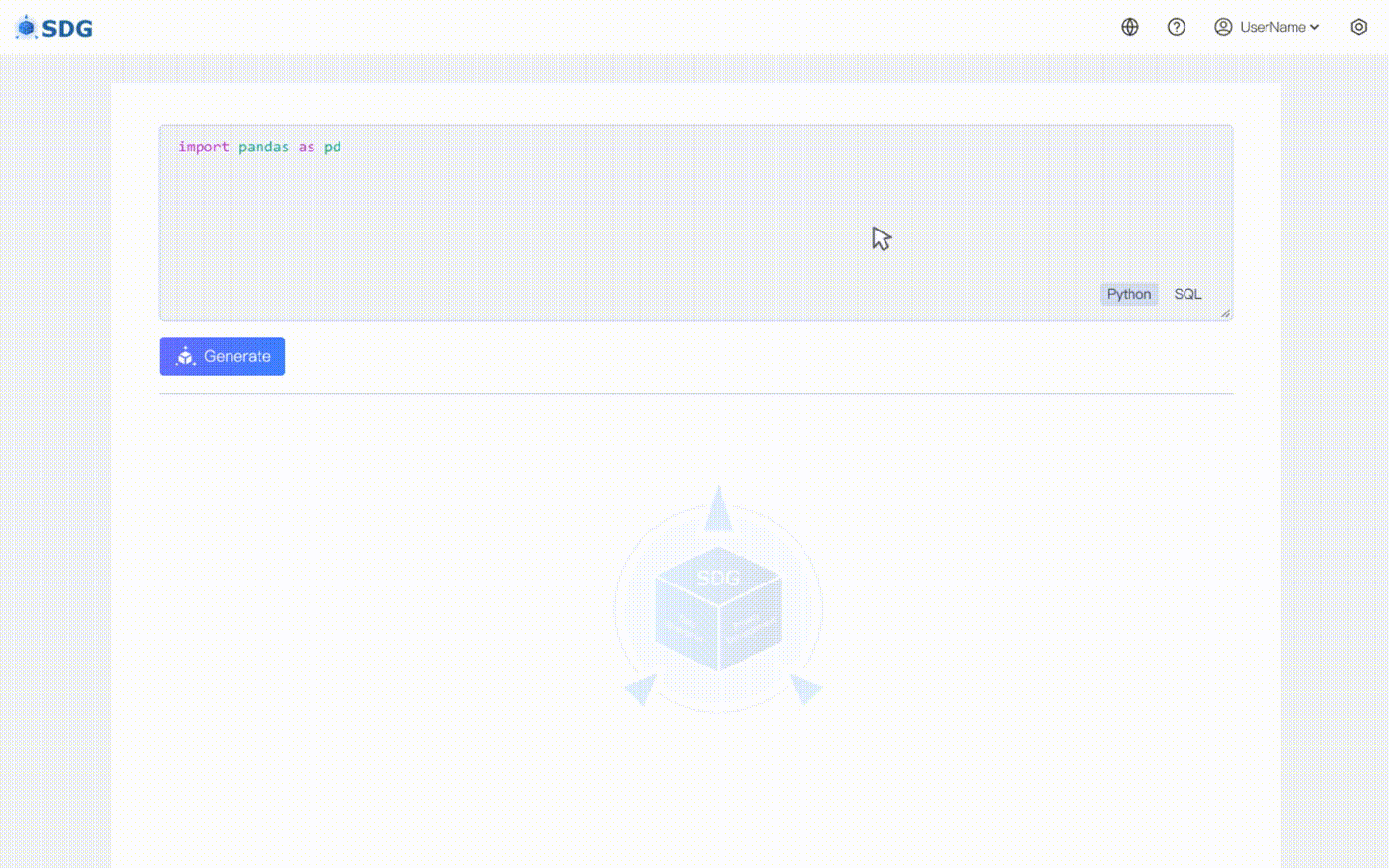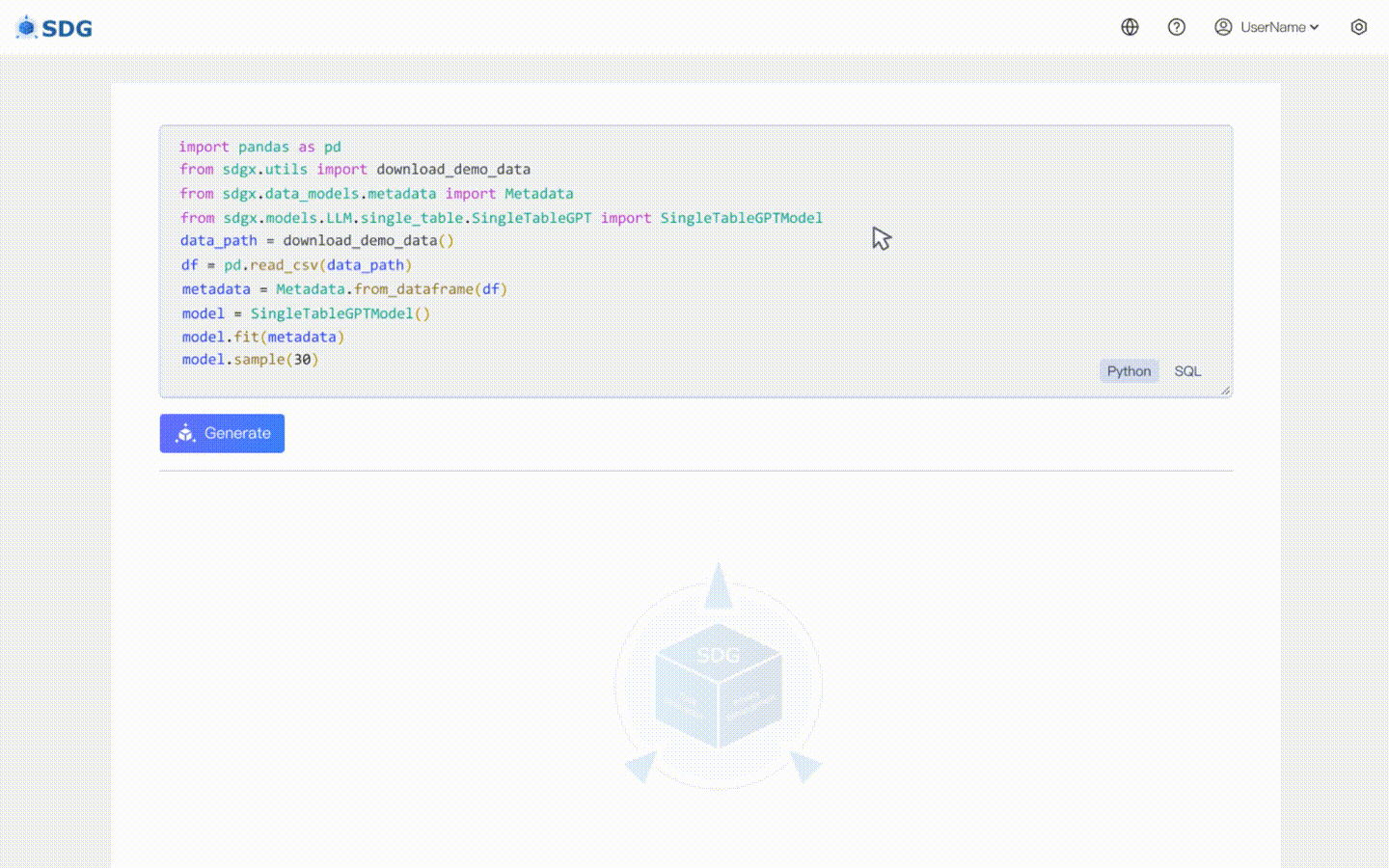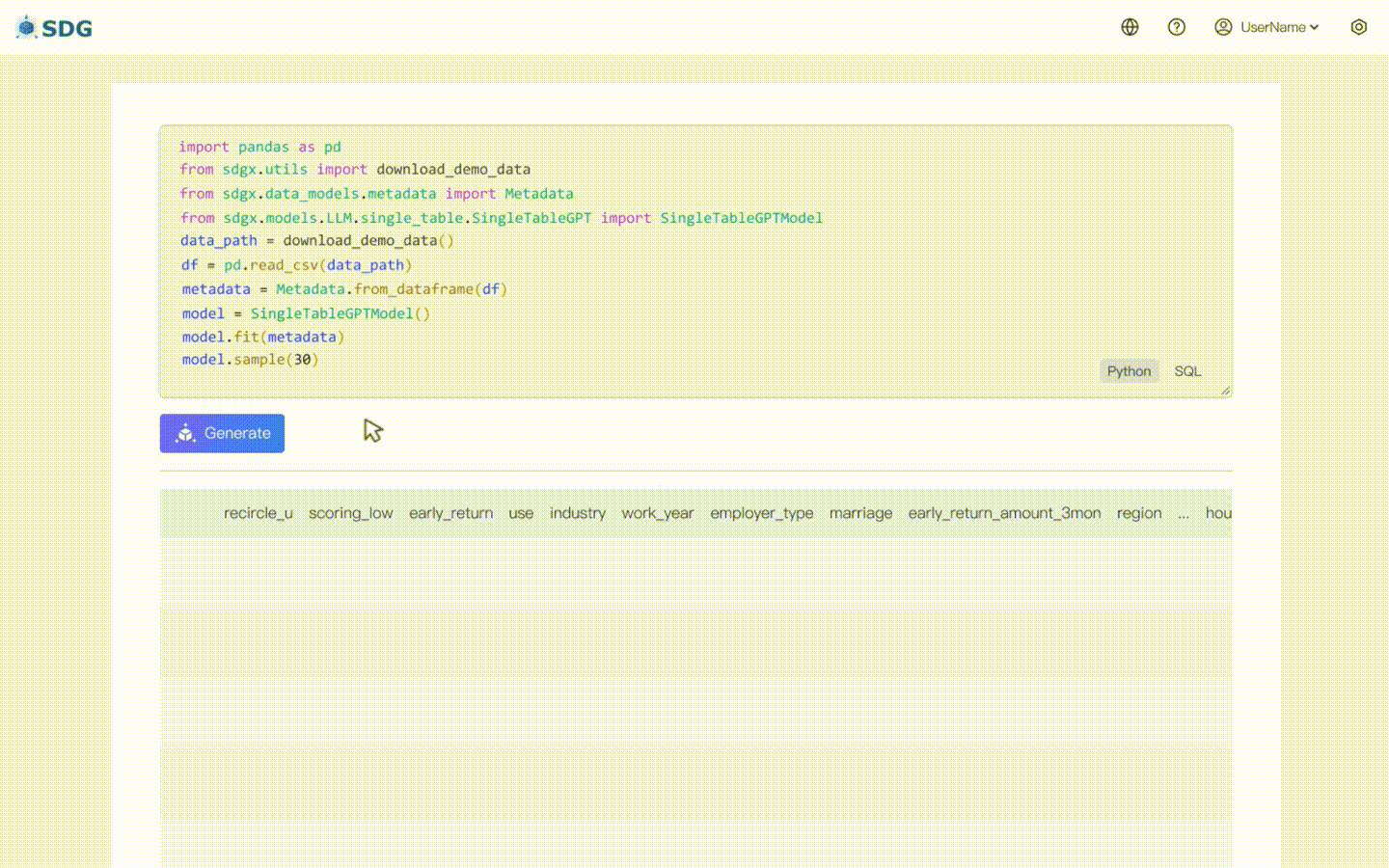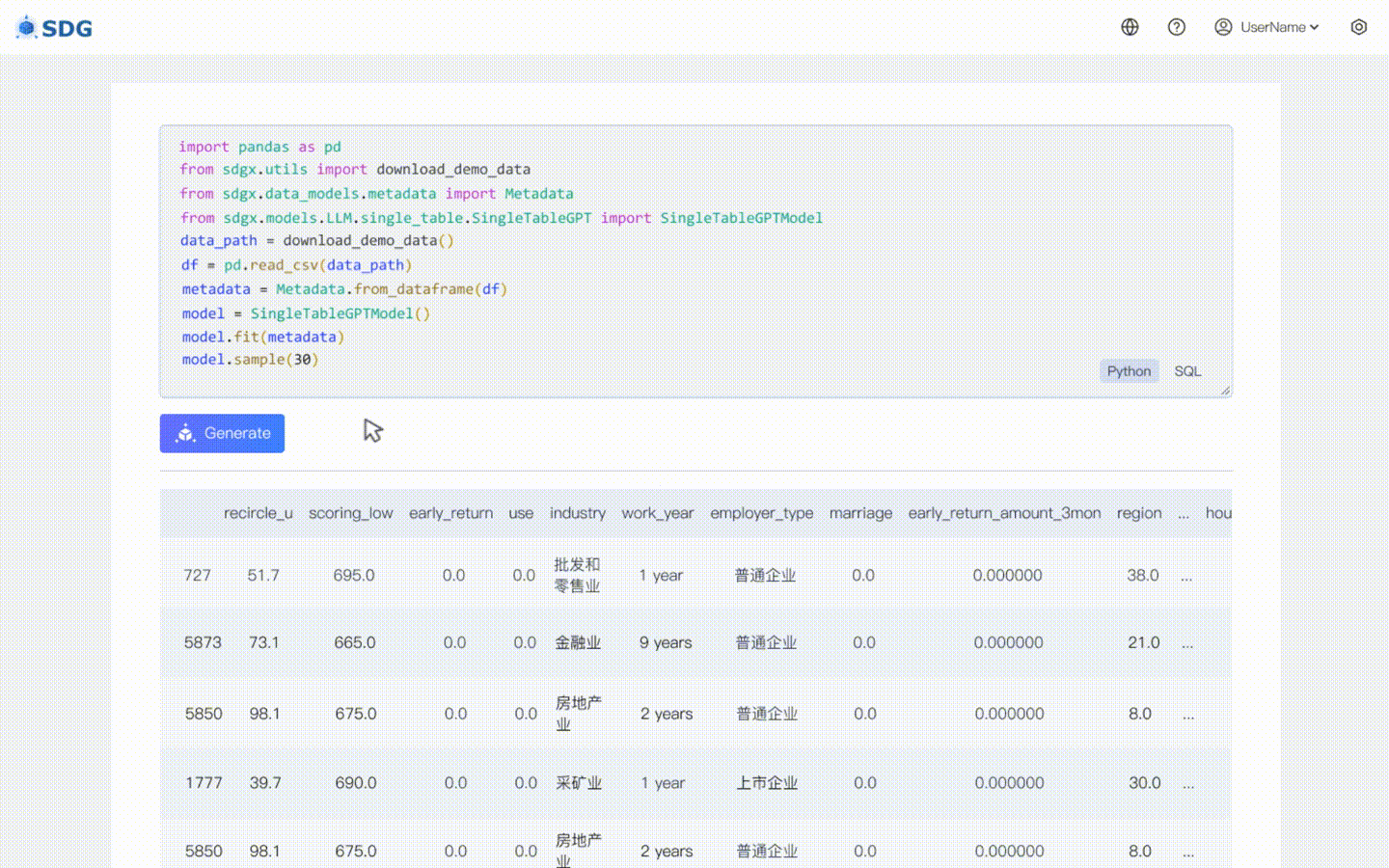
根据表中现有数据和LLM掌握的知识推断新的列数据,请参见我们的colab示例。
技术进步:
支持多种统计数据合成算法,还集成了基于LLM的合成数据生成模型;
针对大数据进行优化,有效降低内存消耗;
持续跟踪学术界和工业界的最新进展,及时推出对优秀算法和模型的支持。
隐私增强功能:
SDG支持差分隐私、匿名化等方法来增强合成数据的安全性。
易于扩展:
支持以插件包的形式扩展模型、数据处理、数据连接器等。
您可以使用预先构建的镜像来快速体验最新功能。
docker pull idsteam/sdgx:最新
pip 安装 sdgx
通过源代码安装 SDG 来使用它。
git 克隆 [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# 或者从 git 安装 pip install git+https://github.com/hitsz-ids/synthetic-data-generator.git
from sdgx.data_connectors.csv_connector import CsvConnectorfrom sdgx.models.ml.single_table.ctgan import CTGANSynthesizerModelfrom sdgx.synthesizer import Synthesizerfrom sdgx.utils import download_demo_data# 这会将演示数据下载到 ./datasetdataset_csv = download_demo_data()# 创建 csv 的数据连接器filedata_connector = CsvConnector(path=dataset_csv)# 初始化合成器,使用 CTGAN modelsynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # 用于快速演示data_connector=data_connector, )# 拟合模型synthesizer.fit()# Samplesampled_data = Synthesizer.sample(1000)print(sampled_data)
真实数据如下:
>>> data_connector.read() 年龄 工作类别 fnlwgt 教育 ... 每周资本损失小时数 本国类别0 2 州政府 77516 学士 ... 0 2 美国 <=50K1 3 自营非公司 83311 学士 .. . 0 0 美国 <=50K2 2 私立 215646 高中毕业生 ... 0 2 美国<=50K3 3 私人 234721 11th ... 0 2 美国 <=50K4 1 私人 338409 学士 ... 0 2 古巴 <=50K... ... ... ... ... ... . .. ... ... ...48837 2 私人 215419 学士 ... 0 2 美国 <=50K48838 4 NaN 321403 HS-grad ... 0 2 美国 <=50K48839 2 私立 374983 学士 ... 0 3 美国 <=50K48840 2 私立 83891 学士 ... 0 2 美国 <=50K48841 1 Self-emp-inc 182148 学士 ... 0 3 美国>50K[48842 行 x 15 列]
综合数据如下:
>>> 样本数据年龄 工人阶级 fnlwgt 教育 ... 每周资本损失小时数 本国阶级 0 1 NaN 28219 某大学 ... 0 2 波多黎各 <=50K1 2 私立 250166 高中毕业生 ... 0 2 美国 >50K2 2 私人 50304 HS-grad ... 0 2 美国 <=50K3 4 私人89318 学士 ... 0 2 波多黎各 >50K4 1 私立 172149 学士 ... 0 3 美国 <=50K.. ... ... ... ... ... ... ... ... ...995 2 NaN 208938 学士 ... 0 1 美国 <=50K996 2 私立 166416 学士 ... 2 2 美国<=50K997 2 NaN 336022 HS-grad ... 0 1 美国 <=50K998 3 Private 198051 Masters ... 0 2 美国 >50K999 1 NaN 41973 HS-grad ... 0 2 美国 <= 50K[1000行×15列]
CTGAN:使用条件 GAN 对表格数据建模
C3-TGAN:C3-TGAN-具有显式相关性和属性约束的可控表格数据合成
TVAE:使用条件 GAN 对表格数据建模
table-GAN:基于生成对抗网络的数据合成
CTAB-GAN:CTAB-GAN:有效的表数据合成
OCT-GAN:OCT-GAN:基于神经 ODE 的条件表格 GAN
SDG项目由哈尔滨工业大学数据安全研究所发起。如果您对我们的项目感兴趣,欢迎加入我们的社区。我们欢迎与我们一样致力于通过开源实现数据保护和安全的组织、团队和个人:
在起草拉取请求之前阅读 CONTRIBUTING。
通过查看 View Good First Issue 或提交 Pull Request 来提交问题。
通过二维码加入我们的微信群。


