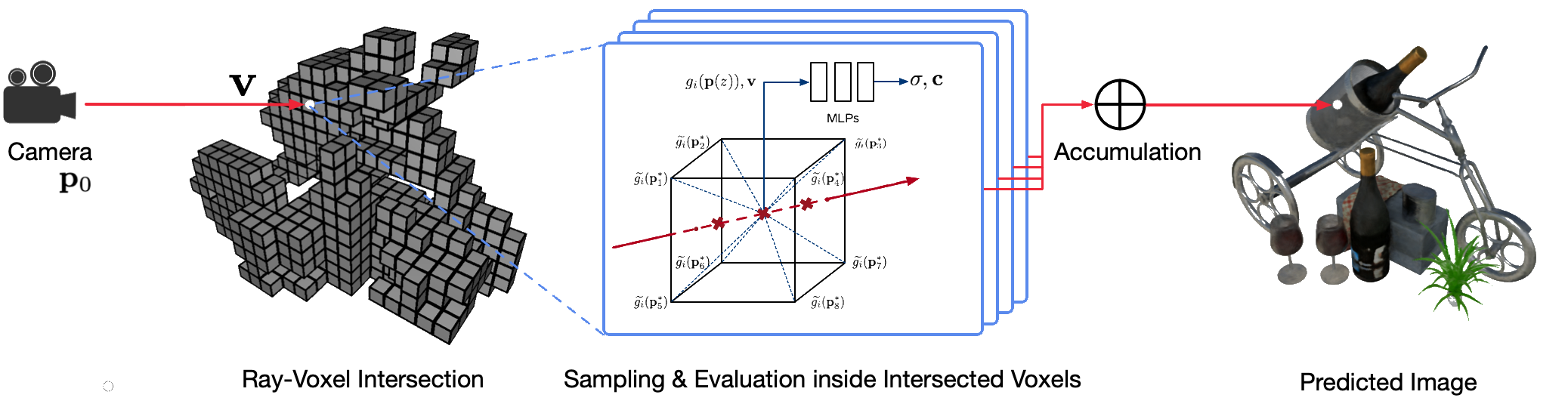
使用经典计算机图形技术对现实世界场景进行逼真的自由视点渲染是一个具有挑战性的问题,因为它需要捕获详细外观和几何模型的困难步骤。神经渲染是一个新兴领域,它采用深度神经网络隐式学习场景表示,其中包含来自有或没有粗略几何形状的 2D 观察中的几何形状和外观。然而,该领域的现有方法经常显示模糊的渲染或渲染过程缓慢。我们提出了神经稀疏体素场(NSVF),这是一种新的神经场景表示,用于快速、高质量的自由视点渲染。
这是该论文的官方存储库:
我们还提供以下非官方实施:
该代码是使用 fairseq 框架在 PyTorch 中实现的。
该代码已在以下系统上测试:
仅支持 GPU 上的学习和渲染。
要安装,首先克隆此存储库并安装所有依赖项:
pip install -r requirements.txt然后,运行
pip install --editable ./或者,如果您想在本地安装代码,请运行:
python setup.py build_ext --inplace您可以下载我们论文中使用的预处理的合成数据集和真实数据集。如果您在工作中使用其中任何论文,也请引用原始论文。
| 数据集 | 下载链接 | 数据集分割注意事项 |
|---|---|---|
| 合成NSVF | 下载(.zip) | 0_*(训练)1_*(验证)2_*(测试) |
| 合成NeRF | 下载(.zip) | 0_*(训练)1_*(验证)2_*(测试) |
| 混合MVS | 下载(.zip) | 0_*(训练)1_*(测试) |
| 坦克&镜腿 | 下载(.zip) | 0_*(训练)1_*(测试) |
要准备单个场景的新数据集用于训练和测试,请遵循以下数据结构:
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4)其中bbox.txt文件包含一行描述初始边界框和体素大小的行:
x_min y_min z_min x_max y_max z_max initial_voxel_size需要注意的是,目标图像的文件名和对应的相机位姿文件的文件名不需要完全相同。但是,这两种文件的顺序(按字符串排序)必须匹配。数据集按视图索引进行分割。例如,“ train (0..100) 、 valid (100..200)和test (200..400) ”表示前 100 个视图用于训练,第 100-199 个视图用于验证,第 200-399 个视图用于测试。
给定单个场景的数据集 ( {DATASET} ),我们使用以下命令训练 NSVF 模型以合成800x800像素的新颖视图,批量大小为每个 GPU 4图像和每个图像2048光线。默认情况下,代码将自动检测所有可用的 GPU。
在以下示例中,我们使用带有特定参数的预定义架构nsvf_base :
--no-sampling-at-reader ,模型仅对稀疏体素的投影图像区域中的像素进行采样以进行训练。1/8 (0.125)这通常在bbox.txt文件中描述。--use-octree 。它将构建一个稀疏体素八叉树来加速射线-体素相交,特别是当体素数量大于10000时。--pruning-every-steps设置为2500 ,模型每2500步执行一次自修剪。--half-voxel-size-at和--reduce-step-size-at设置为5000,25000,75000 ,体素大小和步长分别减半为5k 、 25k和75k 。请注意,尽管本文中的大多数实验都使用上述参数设置,但可以调整这些参数以获得更好的质量。除上述参数外,其他参数也可以采用默认设置。
除了nsvf_base架构之外,您还可以检查其他架构或在文件fairnr/models/nsvf.py中定义自己的架构。
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log检查点保存在{SAVE}中。您可以启动tensorboard来检查训练进度:
tensorboard --logdir= ${SAVE} /tensorboard --port=10000在示例下有更多训练脚本的示例来重现我们论文的结果。
模型训练完成后,将使用以下命令来评估给定{MODEL_PATH}测试视图上的渲染质量。
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' 请注意,我们将raymarching_tolerance覆盖为0.01以启用提前终止以加速渲染。
一旦训练好模型并指定渲染轨迹,就可以实现自由视点渲染。例如,以下命令用于使用圆形轨迹进行渲染(角速度3度/帧,每个GPU 15帧)。这会输出每个视图渲染的图像,并将图像合并到${SAVE}/output中的.mp4视频中,如下所示:

默认情况下,代码可以检测所有可用的 GPU。
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple "我们的代码还支持给定相机姿势的渲染。例如,以下命令用于使用文件夹${DATASET}/pose下第 200-399 个文件中定义的相机姿势进行渲染:
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple "该代码还支持使用.txt文件中定义的相机姿势进行渲染。请参考这个例子。
我们还支持运行行进立方体,从经过训练的 NSVF 模型中将等值面提取为三角形网格,并保存为{SAVE}/{NAME}.ply 。
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5还可以通过设置--format 'voxel_mesh'导出学习到的稀疏体素。输出.ply文件可以使用任何 3D 查看器(例如 MeshLab)打开。

NSVF 获得 MIT 许可。该许可证也适用于预先训练的模型。
请引用为
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

