mae
1.0.0
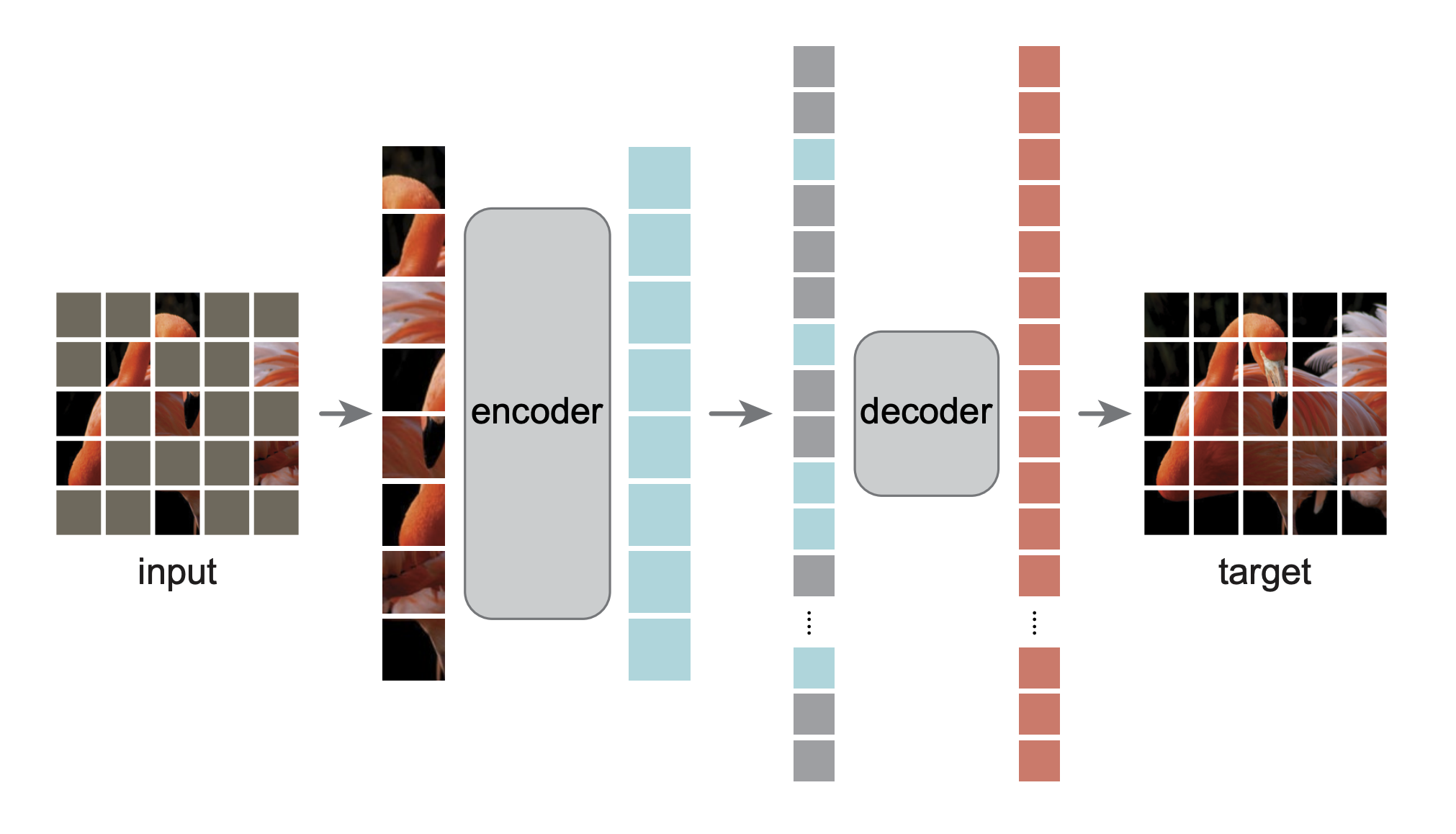
这是论文 Masked Autoencoders Are Scalable Vision Learners 的 PyTorch/GPU 重新实现:
@Article{MaskedAutoencoders2021,
author = {Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll{'a}r and Ross Girshick},
journal = {arXiv:2111.06377},
title = {Masked Autoencoders Are Scalable Vision Learners},
year = {2021},
}
最初的实现是在 TensorFlow+TPU 中实现的。这次重新实现是在 PyTorch+GPU 中进行的。
该存储库是 DeiT 存储库的修改。安装和准备遵循该存储库。
此存储库基于timm==0.3.2 ,需要修复才能与 PyTorch 1.8.1+ 一起使用。
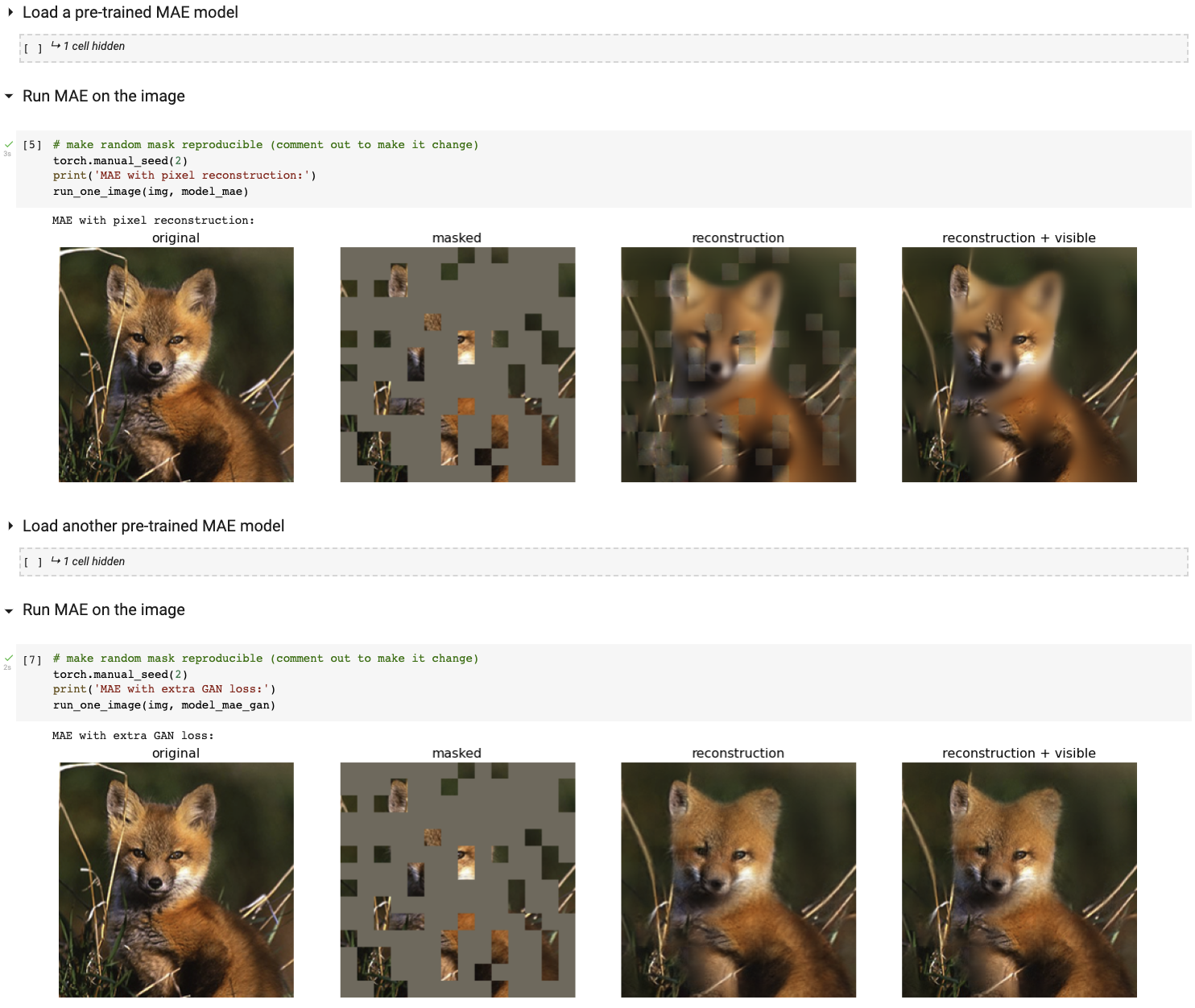
使用 Colab 笔记本运行我们的交互式可视化演示(无需 GPU):
下表提供了论文中使用的预训练检查点,从 TF/TPU 转换为 PT/GPU:
| ViT-基础 | ViT-大号 | ViT-巨大 | |
|---|---|---|---|
| 预训练检查点 | 下载 | 下载 | 下载 |
| MD5 | 8cad7c | b8b06e | 9bdbb0 |
微调指令位于 FINETUNE.md 中。
通过微调这些预训练模型,我们在这些分类任务中排名第一(论文中有详细介绍):
| 维生素B | 维T-L | ViT-H | 维特-H 448 | 上一个最佳 | |
|---|---|---|---|---|---|
| ImageNet-1K(无外部数据) | 83.6 | 85.9 | 86.9 | 87.8 | 87.1 |
| 以下是对相同模型权重的评估(在原始 ImageNet-1K 中进行了微调): | |||||
| ImageNet-损坏(错误率) | 51.7 | 41.8 | 33.8 | 36.8 | 42.5 |
| ImageNet-对抗性 | 35.9 | 57.1 | 68.2 | 76.7 | 35.8 |
| ImageNet 渲染 | 48.3 | 59.9 | 64.4 | 66.5 | 48.7 |
| ImageNet-Sketch | 34.5 | 45.3 | 49.6 | 50.9 | 36.0 |
| 以下是通过在目标数据集上微调预训练的 MAE 进行的迁移学习: | |||||
| i自然主义者 2017 | 70.5 | 75.7 | 79.3 | 83.4 | 75.4 |
| i自然主义者 2018 | 75.4 | 80.1 | 83.0 | 86.8 | 81.2 |
| iNaturalists 2019 | 80.5 | 83.4 | 85.7 | 88.3 | 84.1 |
| 地点205 | 63.9 | 65.8 | 65.9 | 66.8 | 66.0 |
| 地点365 | 57.9 | 59.4 | 59.8 | 60.3 | 58.0 |
预训练指令位于 PRETRAIN.md 中。
该项目采用 CC-BY-NC 4.0 许可证。有关详细信息,请参阅许可证。


