./imagesDockerfile以包含您的二进制文件f()中进行编码、解码和计算度量TUPLE_CODECS
docker build -t image_compression_comparison .
docker run -it -v $(pwd):/image_compression_comparison image_compression_comparison
python3 script_compress_parallel.py
执行针对某些指标值的编码并将结果存储在相应的数据库文件中,例如:
main(metric='ssim', target_arr=[0.92, 0.95, 0.97, 0.99], target_tol=0.005, db_file_name='encoding_results_ssim.db')main(metric='vmaf', target_arr=[75, 80, 85, 90, 95], target_tol=0.5, db_file_name='encoding_results_vmaf.db')
compression_results_[PID]_[TIMESTAMP].txt中compression_results_worker_[PID]_[TIMESTAMP].txt 在sqlite3数据库文件中,例如encoding_results_vmaf.db和encoding_results_ssim.db 。
BD 百分比可以使用名为compute_BD_rates.py的脚本来计算。该脚本采用一个参数:
python3 compute_BD_rates.py [db file name]
并打印每个源图像的BD Rate VMAF 、 BD Rate SSIM 、 BDRate MS_SSIM 、 BDRate VIF 、 BDRate PSNR_Y和BDRate PSNR_AVG的值以及源数据集的平均值。 420和444子采样都会打印 BD 速率。 PSNR_AVG源自MSE_AVG ,MSE_AVG 是所有颜色分量的加权 MSE,根据各个颜色分量中的样本数量进行加权。
还包括一个名为analyze_encoding_results.py的脚本,该脚本
该脚本有两个参数:
python3 analyze_encoding_results.py [metric_name like vmaf OR ssim] [db file name]
应该注意的是,BD 速率提供了整个目标质量范围内的一个聚合数字。仅考虑 BD 速率,可能会错过某些见解,例如,具体来说 VMAF=95 工作点的压缩效率如何比较?
另一个例子是,假设 BD 比率为零。完全有可能速率-质量曲线交叉,并且一种编解码器在 VMAF=95 操作点明显优于另一种,而在较低比特率区域则较差。
理想情况下,当对图像资源进行编码以便在 UI 中使用时,人们希望具有明确定义的操作质量,例如 VMAF=95。可以说,低质量区域的结果可能并不重要。 (b) 中描述的见解因此增强了 BD 速率提供的“整体”见解。
并发工作进程的数量可以在
pool = multiprocessing.Pool(processes=4, initializer=initialize_worker)
考虑到您正在运行的系统,合理的并发性可能会受到处理器核心数量或可用 RAM 数量与正在测试的编解码器集合中最苛刻的编码器进程消耗的内存的限制。例如,如果编码器_A 实例通常消耗 5GB RAM,而您的总 RAM 为 32GB,那么即使您有 24 个(或大于 6 个)处理器核心,合理的并发性也可能会限制为 6 (32 / 5)。
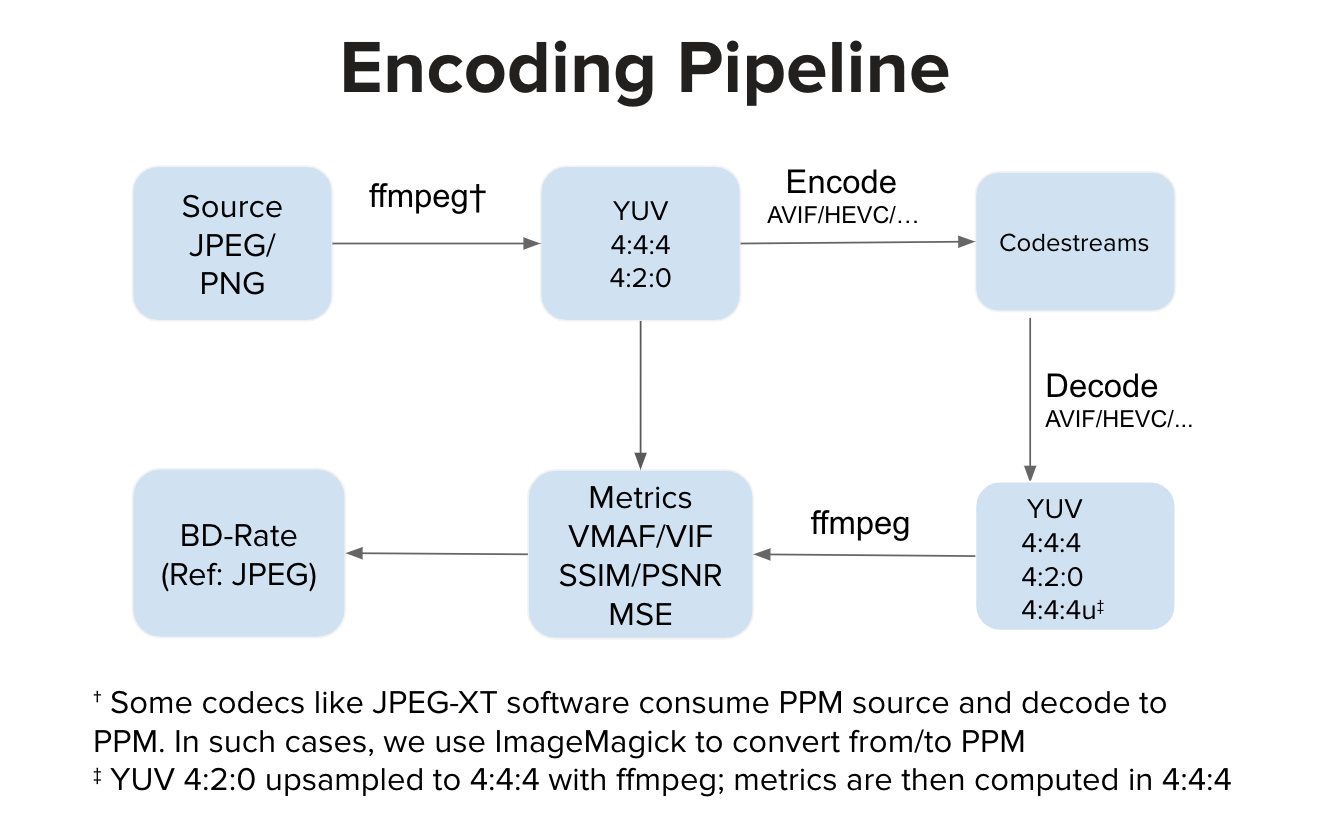
理想情况下,编码器实现消耗 YUV 输入并生成码流。理想情况下,解码器实现会消耗码流并解码为 YUV 输出。然后我们计算 YUV 空间中的度量。然而,有些实现(例如 JPEG-XT 软件)会消耗 PPM 输入并产生 PPM 输出。在这种情况下,在 YUV 空间中的质量计算之前可能存在源 PPM 到 YUV 的转换以及解码的 PPM 到 YUV 的转换。与常规管道相比,额外的转换步骤可能会引入轻微的失真,但在我们的实验中,这些步骤不会对 VMAF 分数产生任何明显的影响。