lance
v0.20.0

适用于 ML 的现代柱状数据格式。使用 2 行代码从 Parquet 进行转换,实现速度提高 100 倍的随机访问、向量索引、数据版本控制等。
与 pandas、DuckDB、Polars 和 pyarrow 兼容,并将有更多集成。
文档 • 博客 • Discord • Twitter
Lance 是一种现代柱状数据格式,针对 ML 工作流程和数据集进行了优化。兰斯非常适合:
兰斯的主要特点包括:
高性能随机访问:比 Parquet 快 100 倍,且不牺牲扫描性能。
向量搜索:以毫秒为单位查找最近邻居,并将 OLAP 查询与向量搜索相结合。
零拷贝、自动版本控制:无需额外的基础设施即可管理数据版本。
生态系统集成: Apache Arrow、Pandas、Polars、DuckDB 等即将推出。
提示
Lance 正在积极开发中,我们欢迎贡献。请参阅我们的贡献指南以获取更多信息。
安装
pip install pylance要安装预览版:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylance提示
预览版本比完整版本发布得更频繁,并且包含最新功能和错误修复。它们接受与完整版本相同级别的测试。我们保证它们将保持发布并可供下载至少 6 个月。当您想要固定到特定版本时,最好选择稳定版本。
转换为兰斯
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )读取兰斯数据
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )熊猫
df = dataset . to_table (). to_pandas ()
df鸭数据库
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()矢量搜索
下载 sift1m 子集
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gz将其转换为兰斯
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )建立索引
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQ搜索数据集
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
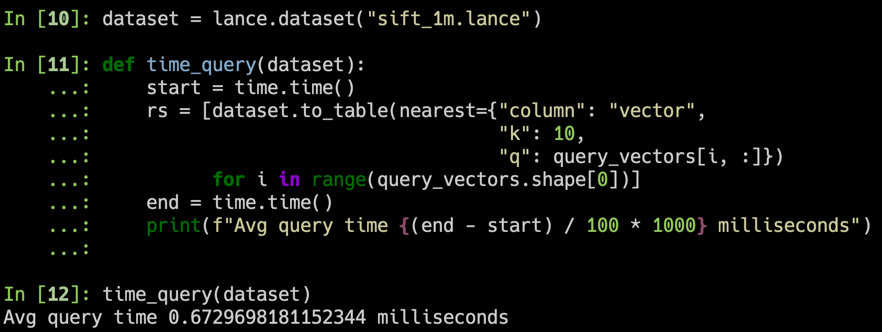
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| 目录 | 描述 |
|---|---|
| 锈 | 核心 Rust 实现 |
| Python | Python 绑定 (pyo3) |
| 文档 | 文档来源 |
在这里我们将重点介绍兰斯设计的几个方面。有关更多详细信息,请参阅完整的 Lance 设计文档。
向量索引:用于嵌入空间上相似性搜索的向量索引。支持 CPU( x86_64和arm )和 GPU( Nvidia (cuda)和Apple Silicon (mps) )。
编码:为了实现快速柱状扫描和次线性点查询,Lance 使用自定义编码和布局。
嵌套字段:Lance 将每个子字段存储为单独的列,以支持高效的过滤器,例如“查找检测到的对象包括猫的图像”。
版本控制:清单可用于记录快照。目前我们支持通过追加、覆盖和创建索引自动创建新版本。
快速更新(路线图):将通过预写日志支持更新。
丰富的二级索引(ROADMAP):
我们使用 SIFT 数据集对 1M 个 128D 向量的结果进行基准测试
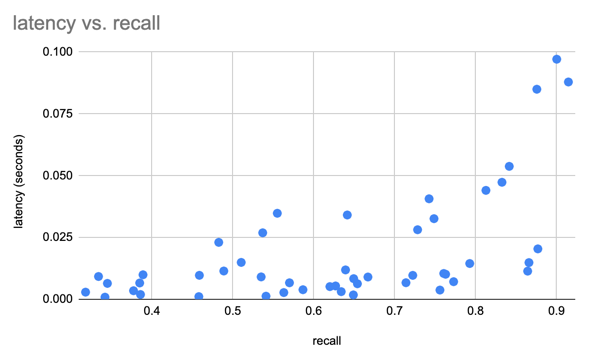
我们使用 Oxford Pet 数据集创建 Lance 数据集,与 Parquet 和原始图像/XML 相比,对 Lance 进行一些初步性能测试。对于分析查询,Lance 比读取原始元数据好 50-100 倍。对于批量随机访问,Lance 比 parquet 和原始文件好 100 倍。

机器学习开发周期涉及以下步骤:
图LR
A[收藏] --> B[探索];
B --> C[分析];
C --> D[功能工程师];
D --> E[训练];
E --> F[评估];
F-->C;
E --> G[部署];
G --> H[监控];
H-->A;
人们在不同阶段使用不同的数据表示来提高性能或受到可用工具的限制。学术界主要使用 XML / JSON 进行注释,并使用压缩图像/传感器数据进行深度学习,这些数据很难集成到数据基础设施中,并且在云存储上训练速度很慢。虽然业界使用数据湖(基于 Parquet 的技术,即 Delta Lake、Iceberg)或数据仓库(AWS Redshift 或 Google BigQuery)来收集和分析数据,但他们必须将数据转换为适合训练的格式,例如 Rikai/ Petastorm 或 TFRecord。多个单一用途的数据转换以及将云存储之间的副本同步到本地训练实例已成为常见做法。
虽然每种现有数据格式都能够胜任其最初设计的工作负载,但我们需要一种针对多阶段 ML 开发周期量身定制的新数据格式,以减少数据孤岛。
机器学习开发周期每个阶段不同数据格式的比较。
| 槊 | 实木复合地板和兽人 | JSON 和 XML | TF记录 | 数据库 | 仓库 | |
|---|---|---|---|---|---|---|
| 分析 | 快速地 | 快速地 | 慢的 | 慢的 | 体面的 | 快速地 |
| 特征工程 | 快速地 | 快速地 | 体面的 | 慢的 | 体面的 | 好的 |
| 训练 | 快速地 | 体面的 | 慢的 | 快速地 | 不适用 | 不适用 |
| 勘探 | 快速地 | 慢的 | 快速地 | 慢的 | 快速地 | 体面的 |
| 基础设施支持 | 富有的 | 富有的 | 体面的 | 有限的 | 富有的 | 富有的 |
Lance 目前用于生产的有:


