qlib
v0.9.5 ?

最近发布的功能
 :基于法学硕士的工业数据驱动研发自主进化代理
:基于法学硕士的工业数据驱动研发自主进化代理我们很高兴地宣布推出RD-Agent™ ,这是一款支持量化投资研发中自动因子挖掘和模型优化的强大工具。
RD-Agent 现已在 GitHub 上发布,我们欢迎您的star?!
要了解更多信息,请访问我们的♾️演示页面。在这里,您可以找到中英文演示视频,帮助您更好地了解RD-Agent的场景和使用。
我们为您准备了几个演示视频:
| 设想 | 演示视频(英文) | 演示视频(中文) |
|---|---|---|
| 量化因子挖掘 | 关联 | 关联 |
| 从报告中挖掘量化因素 | 关联 | 关联 |
| 定量模型优化 | 关联 | 关联 |
| 特征 | 地位 |
|---|---|
| 用于端到端学习的 BPQP | ?即将推出!(审核中) |
| 法学硕士驱动的汽车定量工厂 | 于 2024 年 8 月 8 日在♾️RD-Agent 发布 |
| KRNN 和三明治模型 | ?发布于 2023 年 5 月 26 日 |
| 发布Qlib v0.9.0 | 发布于 2022 年 12 月 9 日 |
| 强化学习学习框架 | ? ?发布于 2022 年 11 月 10 日。#1332、#1322、#1316、#1299、#1263、#1244、#1169、#1125、#1076 |
| HIST 和 IGMTF 模型 | ?发布于 2022 年 4 月 10 日 |
| Qlib笔记本教程 | 发布于 2022 年 4 月 7 日 |
| 伊博维斯帕指数数据 | ?发布于 2022 年 4 月 6 日 |
| 时间点数据库 | ?发布于 2022 年 3 月 10 日 |
| Arctic 提供商后端和订单簿数据示例 | ?发布于 2022 年 1 月 17 日 |
| 基于元学习的框架和 DDG-DA | ? ?发布于 2022 年 1 月 10 日 |
| 基于规划的投资组合优化 | ?发布于 2021 年 12 月 28 日 |
| 发布 Qlib v0.8.0 | 发布于 2021 年 12 月 8 日 |
| 添加模型 | ?发布于 2021 年 11 月 22 日 |
| ADARNN模型 | ?发布于 2021 年 11 月 14 日 |
| TCN模型 | ?发布于 2021 年 11 月 4 日 |
| 嵌套决策框架 | ?发布于 2021 年 10 月 1 日。示例和文档 |
| 时间路由适配器 (TRA) | ?发布于 2021 年 7 月 30 日 |
| 变压器和本地变压器 | ?发布于 2021 年 7 月 22 日 |
| 发布 Qlib v0.7.0 | 发布于 2021 年 7 月 12 日 |
| TCTS模型 | ?发布于 2021 年 7 月 1 日 |
| 在线服务和自动模型滚动 | ?发布于 2021 年 5 月 17 日 |
| 双系综模型 | ?发布于 2021 年 3 月 2 日 |
| 高频数据处理示例 | ?发布于 2021 年 2 月 5 日 |
| 高频交易示例 | ? 2021年1月28日发布的部分代码 |
| 高频数据(1分钟) | ?发布于 2021 年 1 月 27 日 |
| 平板电脑型号 | ?发布于 2021 年 1 月 22 日 |
此处未列出 2021 年之前发布的功能。

Qlib是一个开源的、面向人工智能的量化投资平台,旨在利用人工智能技术在量化投资中从探索想法到落地产品,发挥潜力、赋能研究、创造价值。 Qlib 支持多种机器学习建模范例,包括监督学习、市场动态建模和强化学习。
Qlib 正在发布越来越多不同范式的 SOTA Quant 研究著作/论文,以协作解决量化投资中的关键挑战。例如,1) 使用监督学习从丰富且异构的金融数据中挖掘市场复杂的非线性模式,2) 使用自适应概念漂移技术对金融市场的动态性质进行建模,以及 3) 使用强化学习对持续投资进行建模决策并协助投资者优化交易策略。
它包含数据处理、模型训练、回测的完整机器学习流程;涵盖量化投资的整个链条:阿尔法寻求、风险建模、投资组合优化和订单执行。更多详情,请参阅我们的论文《Qlib:面向人工智能的量化投资平台》。
| 框架、教程、数据和 DevOps | 定量研究的主要挑战和解决方案 |
|---|---|
|
|
正在开发的新功能(按预计发布时间排序)。您对这些功能的反馈非常重要。

Qlib的高层框架可以在上面找到(用户可以在深入了解Qlib设计的详细框架时找到)。这些组件被设计为松耦合模块,每个组件都可以独立使用。
Qlib 提供了强大的基础设施来支持定量研究。数据始终是重要的组成部分。强大的学习框架旨在支持不同层次的不同学习范式(例如强化学习、监督学习)和模式(例如市场动态建模)。通过对市场进行建模,交易策略将生成将要执行的交易决策。不同级别或粒度的多个交易策略和执行器可以嵌套在一起进行优化和运行。最后,将提供全面的分析,并且模型可以低成本在线服务。
本快速入门指南试图演示
这是一个快速演示,展示了如何安装Qlib并使用qrun运行 LightGBM。但是,请确保您已经按照说明准备好数据。
下表展示了支持的Qlib Python 版本:
| 使用 pip 安装 | 从源安装 | 阴谋 | |
|---|---|---|---|
| Python 3.7 | ✔️ | ✔️ | ✔️ |
| Python 3.8 | ✔️ | ✔️ | ✔️ |
| Python 3.9 | ✔️ |
笔记:
conda环境之外使用 Python 可能会导致头文件丢失,从而导致某些包安装失败。Qlib时,在 Python 3.6 中安装 cython 会引发一些错误。如果用户在机器上使用Python 3.6,建议将Python升级到3.7版本或使用conda的Python从源安装Qlib 。Qlib支持运行工作流程,例如训练模型、进行回测并绘制大多数相关图形(笔记本中包含的图形)。不过,目前不支持模型性能绘图,我们将在将来升级依赖包时修复此问题。Qlib需要tables包,tables中的hdf5不支持python3.9。用户可以按照以下命令通过pip轻松安装Qlib 。
pip install pyqlib注意:pip 将安装最新的稳定 qlib。然而,qlib 的主要分支正在积极开发中。如果你想测试主分支中最新的脚本或函数。请使用以下方法安装qlib。
另外,用户可以按照以下步骤通过源码安装最新的开发版Qlib :
在从源代码安装Qlib之前,用户需要安装一些依赖项:
pip install numpy
pip install --upgrade cython克隆存储库并安装Qlib ,如下所示。
git clone https://github.com/microsoft/qlib.git && cd qlib
pip install . # `pip install -e .[dev]` is recommended for development. check details in docs/developer/code_standard_and_dev_guide.rst注意:您也可以使用python setup.py install安装 Qlib。但这不是推荐的方法。它会跳过pip并导致难以理解的问题。例如,仅命令pip install .可以覆盖pip install pyqlib安装的稳定版本,而命令python setup.py install则不能。
提示:如果您无法在您的环境中安装Qlib或运行示例,比较您的步骤和 CI 工作流程可能会帮助您找到问题。
Mac 提示:如果您将 Mac 与 M1 结合使用,则在构建 LightGBM 轮子时可能会遇到问题,这是由于缺少 OpenMP 的依赖项造成的。要解决该问题,请先使用brew install libomp安装openmp,然后运行pip install .才能成功构建它。
❗ 由于更严格的数据安全政策。官方数据集暂时禁用。您可以尝试一下社区贡献的这个数据源。以下是下载20240809更新数据的示例。
wget https://github.com/chenditc/investment_data/releases/download/2024-08-09/qlib_bin.tar.gz
mkdir -p ~ /.qlib/qlib_data/cn_data
tar -zxvf qlib_bin.tar.gz -C ~ /.qlib/qlib_data/cn_data --strip-components=1
rm -f qlib_bin.tar.gz下面的官方数据集将在不久的将来恢复。
通过运行以下代码加载并准备数据:
# get 1d data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
# get 1d data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
该数据集是由爬虫脚本收集的公共数据创建的,这些数据已在同一存储库中发布。用户可以用它创建相同的数据集。数据集描述
请注意,数据是从雅虎财经收集的,数据可能并不完美。如果用户拥有高质量的数据集,我们建议他们准备自己的数据。如需了解更多信息,用户可以参考相关文档。
如果用户只想在历史数据上尝试他们的模型和策略,则此步骤是可选的。
建议用户手动更新一次数据(--trading_date 2021-05-25),然后设置为自动更新。
注意:用户无法基于Qlib提供的离线数据增量更新数据(删除了一些字段以减少数据大小)。用户应该使用雅虎收集器从头开始下载雅虎数据,然后增量更新它。
更多信息请参考:yahoo Collector
每个交易日自动更新数据到“qlib”目录(Linux)
使用crontab : crontab -e
设置定时任务:
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
手动更新数据
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
docker pull pyqlib/qlib_image_stable:stabledocker run -it --name < container name > -v < Mounted local directory > :/app qlib_image_stable>>> python scripts/get_data.py qlib_data --name qlib_data_simple --target_dir ~ /.qlib/qlib_data/cn_data --interval 1d --region cn
>>> python qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml>>> exitdocker start -i -a < container name >docker stop < container name >docker rm < container name >Qlib 提供了一个名为qrun的工具来自动运行整个工作流程(包括构建数据集、训练模型、回测和评估)。您可以按照以下步骤启动自动定量研究工作流程并进行图形报告分析:
定量研究工作流程:使用 lightgbm 工作流程配置(workflow_config_lightgbm_Alpha158.yaml,如下所示)运行qrun 。
cd examples # Avoid running program under the directory contains `qlib`
qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml如果用户想在调试模式下使用qrun ,请使用以下命令:
python -m pdb qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml qrun的结果如下,更多结果请参考日内交易。
' The following are analysis results of the excess return without cost. '
risk
mean 0.000708
std 0.005626
annualized_return 0.178316
information_ratio 1.996555
max_drawdown -0.081806
' The following are analysis results of the excess return with cost. '
risk
mean 0.000512
std 0.005626
annualized_return 0.128982
information_ratio 1.444287
max_drawdown -0.091078这里有qrun和工作流程的详细文档。
图形报告分析:使用jupyter notebook运行examples/workflow_by_code.ipynb以获取图形报告
预测信号(模型预测)分析
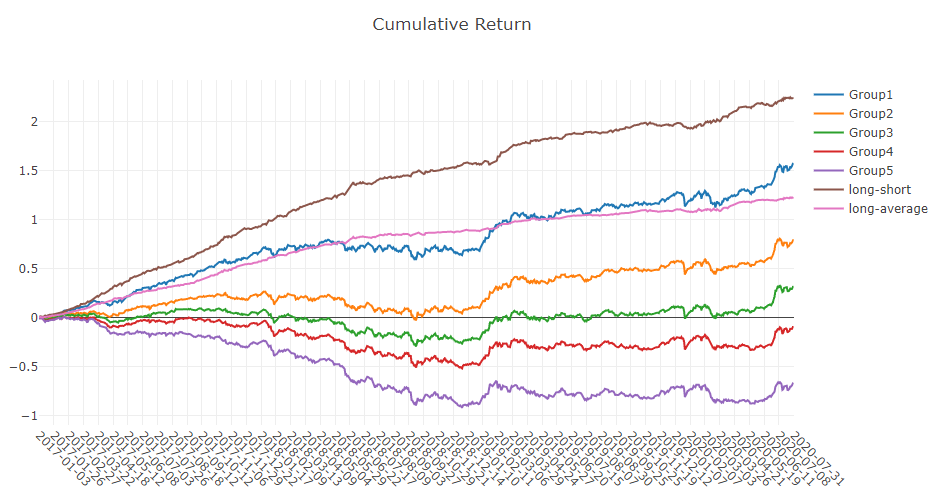
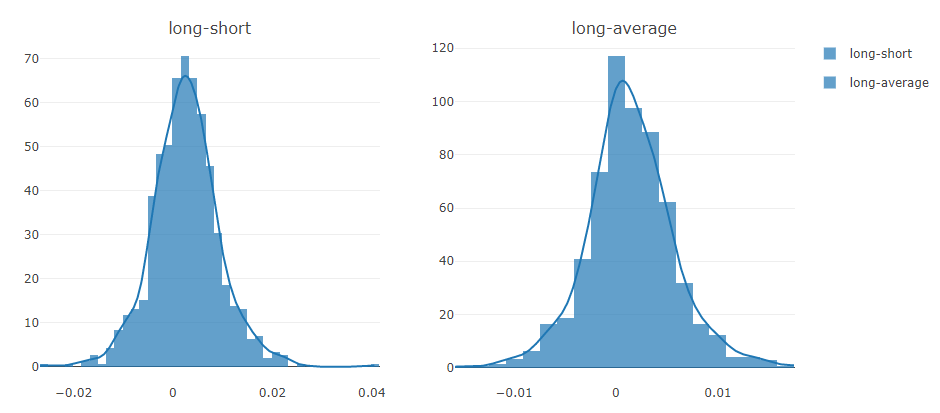
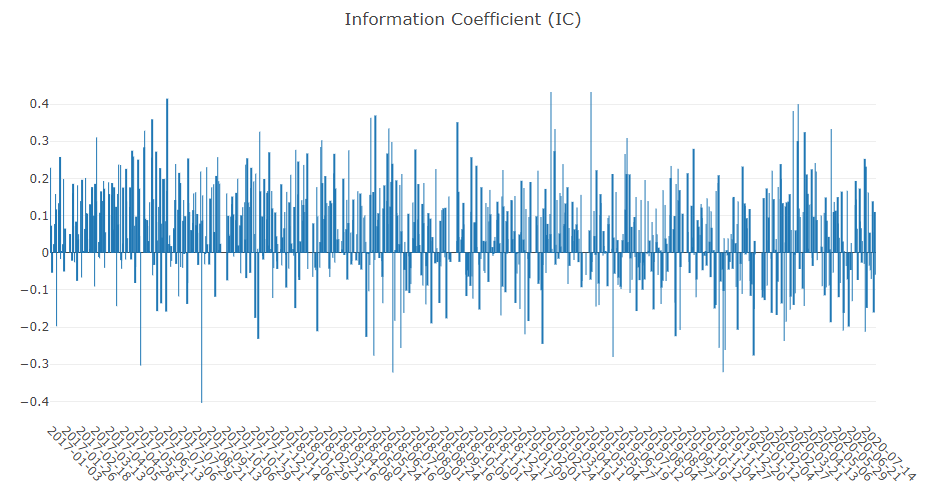
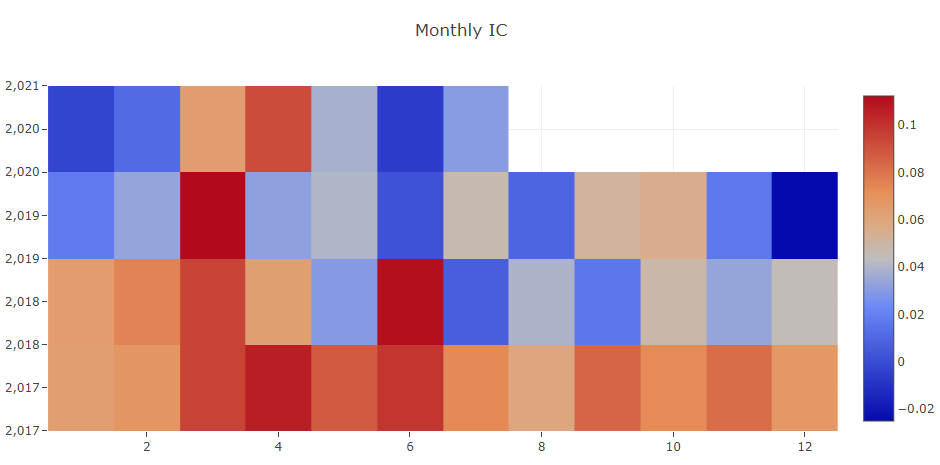
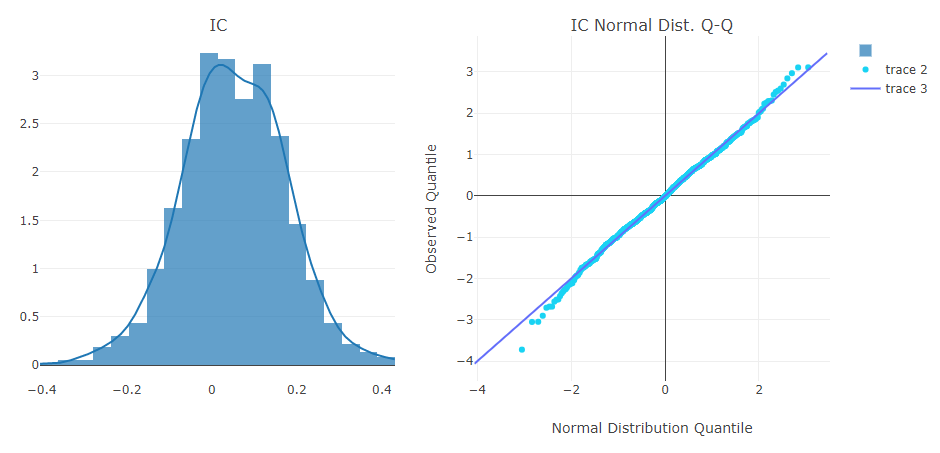
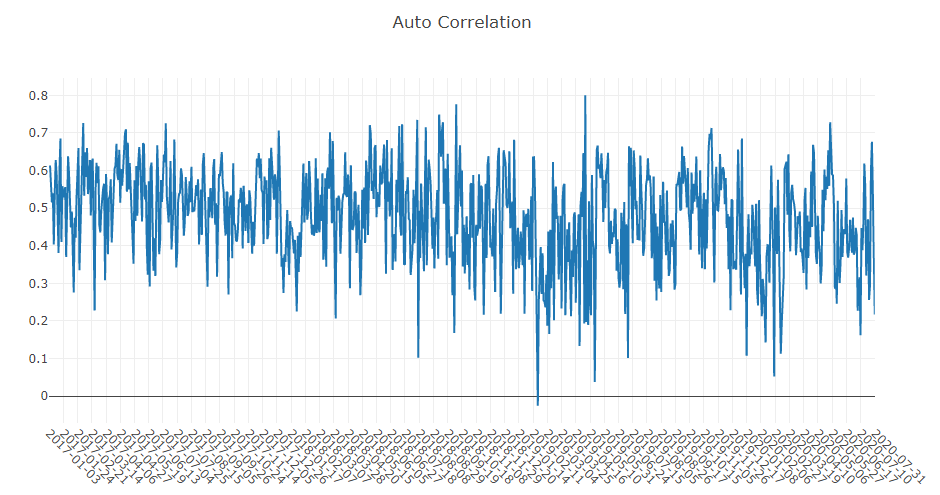
投资组合分析
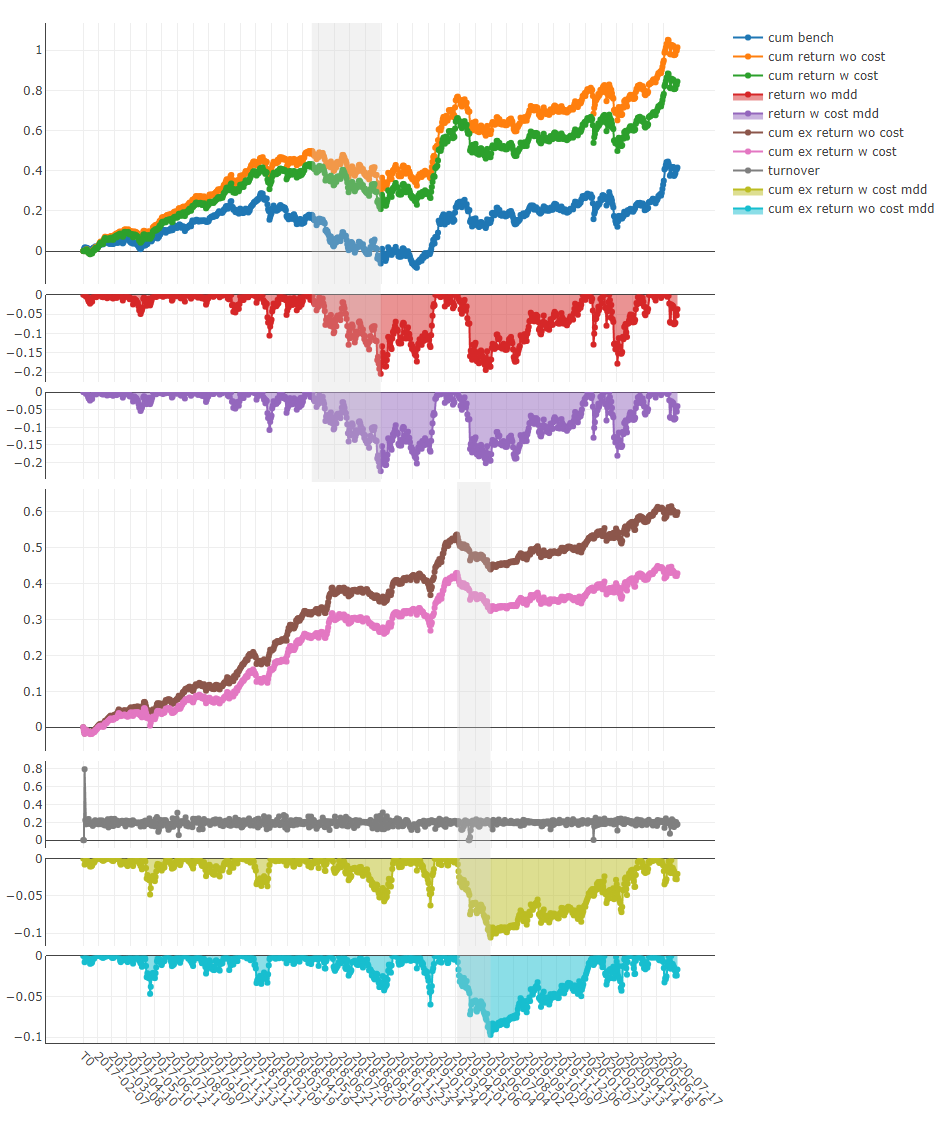
对上述结果的解释
自动工作流程可能不适合所有定量研究人员的研究工作流程。为了支持灵活的定量研究工作流程,Qlib 还提供了模块化接口,允许研究人员通过代码构建自己的工作流程。这是通过代码定制的定量研究工作流程的演示。
量化投资是一个非常独特的场景,有许多关键挑战需要解决。目前,Qlib 为其中的几个提供了一些解决方案。
准确预测股价走势是构建盈利投资组合的重要组成部分。然而,金融市场中数据量巨大、格式多样,给建立预测模型带来了挑战。
Qlib中发布了越来越多的 SOTA Quant 研究著作/论文,这些著作/论文专注于构建预测模型以挖掘复杂金融数据中的有价值的信号/模式
以下是基于Qlib构建的模型列表。
非常欢迎您对新 Quant 模型的公关。
可以在此处找到每个模型在Alpha158和Alpha360数据集上的性能。
上面列出的所有模型都可以使用Qlib运行。用户可以通过 benchmarks 文件夹找到我们提供的配置文件以及有关模型的一些详细信息。更多信息可以在上面列出的模型文件中检索。
Qlib提供了三种不同的方式来运行单个模型,用户可以选择最适合自己情况的一种:
用户可以使用上面提到的工具qrun从配置文件运行模型的工作流程。
用户可以根据examples文件夹中列出的脚本创建workflow_by_code python 脚本。
用户可以使用examples文件夹中列出的脚本run_all_model.py来运行模型。以下是要使用的特定 shell 命令的示例: python run_all_model.py run --models=lightgbm ,其中--models参数可以采用上面列出的任意数量的模型(可用模型可以在基准测试中找到)。有关更多用例,请参阅文件的文档字符串。
tensorflow==1.15.0的限制,TFT仅支持Python 3.6~3.7)Qlib还提供了一个脚本run_all_model.py ,它可以运行多个模型进行多次迭代。 (注:该脚本目前仅支持Linux ,后续会支持其他操作系统。此外,它也不支持多次并行运行同一模型,这也会在未来的开发中修复。)
该脚本将为每个模型创建一个独特的虚拟环境,并在训练后删除该环境。因此,只会生成并存储IC和backtest结果等实验结果。
以下是运行所有模型 10 次迭代的示例:
python run_all_model . py run 10它还提供 API 来立即运行特定模型。有关更多用例,请参阅文件的文档字符串。
由于金融市场环境的非平稳性,不同时期的数据分布可能会发生变化,这使得建立在训练数据上的模型的性能在未来的测试数据中出现衰减。因此,使预测模型/策略适应市场动态对于模型/策略的性能非常重要。
以下是基于Qlib构建的解决方案列表。
Qlib 现在支持强化学习,这是一项旨在模拟持续投资决策的功能。此功能可帮助投资者通过从与环境的交互中学习来优化其交易策略,以最大化累积奖励的某些概念。
以下是基于Qlib构建的解决方案列表,按场景分类。
下面是这个场景的介绍。此处对以下所有方法进行了比较。
数据集在Quant中起着非常重要的作用。以下是基于Qlib构建的数据集的列表:
| 数据集 | 美国市场 | 中国市场 |
|---|---|---|
| 阿尔法360 | √ | √ |
| 阿尔法158 | √ | √ |
这是使用Qlib构建数据集的教程。非常欢迎您构建新的定量数据集的 PR。
Qlib 具有高度可定制性,并且它的许多组件都是可以学习的。可学习组件是Forecast Model和Trading Agent的实例。它们基于Learning Framework层进行学习,然后应用于Workflow层的多个场景。学习框架也利用Workflow流层(例如共享Information Extractor 、基于Execution Env创建环境)。
根据学习范式,可以分为强化学习和监督学习。
Workflow层中的Execution Env来创建环境。值得注意的是, NestedExecutor也受支持。这使用户能够一起优化不同级别的策略/模型/代理(例如,针对特定投资组合管理策略优化订单执行策略)。如果您想快速浏览一下 qlib 最常用的组件,可以尝试这里的笔记本。
详细文档组织在 docs 中。以 html 格式构建文档需要 Sphinx 和 readthedocs 主题。
cd docs/
conda install sphinx sphinx_rtd_theme -y
# Otherwise, you can install them with pip
# pip install sphinx sphinx_rtd_theme
make html您还可以直接在线查看最新文档。
Qlib 正在积极持续的开发中。我们的计划在路线图中,它作为 github 项目进行管理。
Qlib的数据服务器可以部署为Offline模式或Online模式。默认模式为离线模式。
Offline模式下,数据将部署在本地。
Online模式下,数据将作为共享数据服务部署。数据及其缓存将由所有客户端共享。由于缓存命中率较高,预计数据检索性能将得到改善。它也会消耗更少的磁盘空间。在线模式的文档可以在Qlib-Server中找到。在线模式可以使用基于 Azure CLI 的脚本自动部署。在线数据服务器的源代码可以在Qlib-Server存储库中找到。
数据处理的性能对于人工智能技术等数据驱动方法非常重要。 Qlib作为一个面向AI的平台,提供了数据存储和数据处理的解决方案。为了演示 Qlib 数据服务器的性能,我们将其与其他几种数据存储解决方案进行比较。
我们通过完成相同的任务来评估几种存储解决方案的性能,该任务根据股票市场的基本 OHLCV 每日数据(2007 年至 2020 年每天 800 只股票)创建一个数据集(14 个特征/因子)。任务涉及数据查询和处理。
| HDF5 | MySQL | MongoDB | InfluxDB | Qlib-E-D | Qlib +E -D | Qlib +E +D | |
|---|---|---|---|---|---|---|---|
| 总计 (1CPU)(秒) | 184.4±3.7 | 365.3±7.5 | 253.6±6.7 | 368.2±3.6 | 147.0±8.8 | 47.6±1.0 | 7.4±0.3 |
| 总计 (64CPU)(秒) | 8.8±0.6 | 4.2±0.2 |
+(-)E表示with(out) ExpressionCache+(-)D表示带(out) DatasetCache大多数通用数据库需要花费太多时间来加载数据。在深入研究底层实现后,我们发现通用数据库解决方案中的数据经过了太多层接口和不必要的格式转换。这种开销极大地减慢了数据加载过程。 Qlib 数据以紧凑的格式存储,可以有效地组合成数组以进行科学计算。
Qlib做出贡献,请创建拉取请求。加入 IM 讨论组:
| 吉特 |
|---|
 |
我们感谢所有贡献并感谢所有贡献者!
在我们于 2020 年 9 月在 Github 上将 Qlib 作为开源项目发布之前,Qlib 是我们小组的内部项目。不幸的是,内部提交历史记录没有保留。我们组的很多成员也为Qlib做出了很多贡献,其中包括王瑞华、张银达、于海粟、王书宇、庞博辰和周东。特别感谢 Dong Zhou 提供的 Qlib 初始版本。
该项目欢迎贡献和建议。
以下是提交拉取请求的一些代码标准和开发指南。
做出贡献并不是一件难事。解决问题(也许只是回答问题列表或 gitter 中提出的问题)、修复/发布错误、改进文档甚至修复拼写错误都是对 Qlib 的重要贡献。
例如,如果你想为Qlib的文档/代码做出贡献,你可以按照下图的步骤进行操作。

如果您不知道如何开始贡献,可以参考以下示例。
| 类型 | 示例 |
|---|---|
| 解决问题 | 回答问题;发布或修复错误 |
| 文档 | 提高文档质量;修正一个错字 |
| 特征 | 实现这样的请求功能;重构接口 |
| 数据集 | 添加数据集 |
| 型号 | 实施新模型,贡献模型的一些说明 |
好的第一个问题被标记为表明它们很容易开始您的贡献。
您可以通过rg 'TODO|FIXME' qlib在 Qlib 中找到一些不完美的实现
如果您想成为Qlib的维护者之一,做出更多贡献(例如帮助合并PR、分类问题),请通过电子邮件联系我们([email protected])。我们很高兴帮助您升级权限。
大多数贡献都要求您同意贡献者许可协议 (CLA),声明您有权并且实际上授予我们使用您的贡献的权利。有关详细信息,请访问 https://cla.opensource.microsoft.com。
当您提交拉取请求时,CLA 机器人将自动确定您是否需要提供 CLA 并适当地修饰 PR(例如,状态检查、评论)。只需按照机器人提供的说明进行操作即可。您只需使用我们的 CLA 在所有存储库中执行一次此操作。
该项目采用了微软开源行为准则。有关详细信息,请参阅行为准则常见问题解答或联系 [email protected] 提出任何其他问题或意见。


