LLaMA_MPS
1.0.0
在Apple Silicon GPU 上运行LLaMA(和Stanford-Alpaca)推理。
正如您所看到的,与其他法学硕士不同,LLaMA 没有任何偏见?
1. 克隆这个仓库
git clone https://github.com/jankais3r/LLaMA_MPS
2.安装Python依赖
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e .3. 下载模型权重并将其放入名为models的文件夹中(例如LLaMA_MPS/models/7B )
4. (可选)重新分片模型权重(13B/30B/65B)
由于我们在单个 GPU 上运行推理,因此需要将较大模型的权重合并到单个文件中。
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. 运行推理
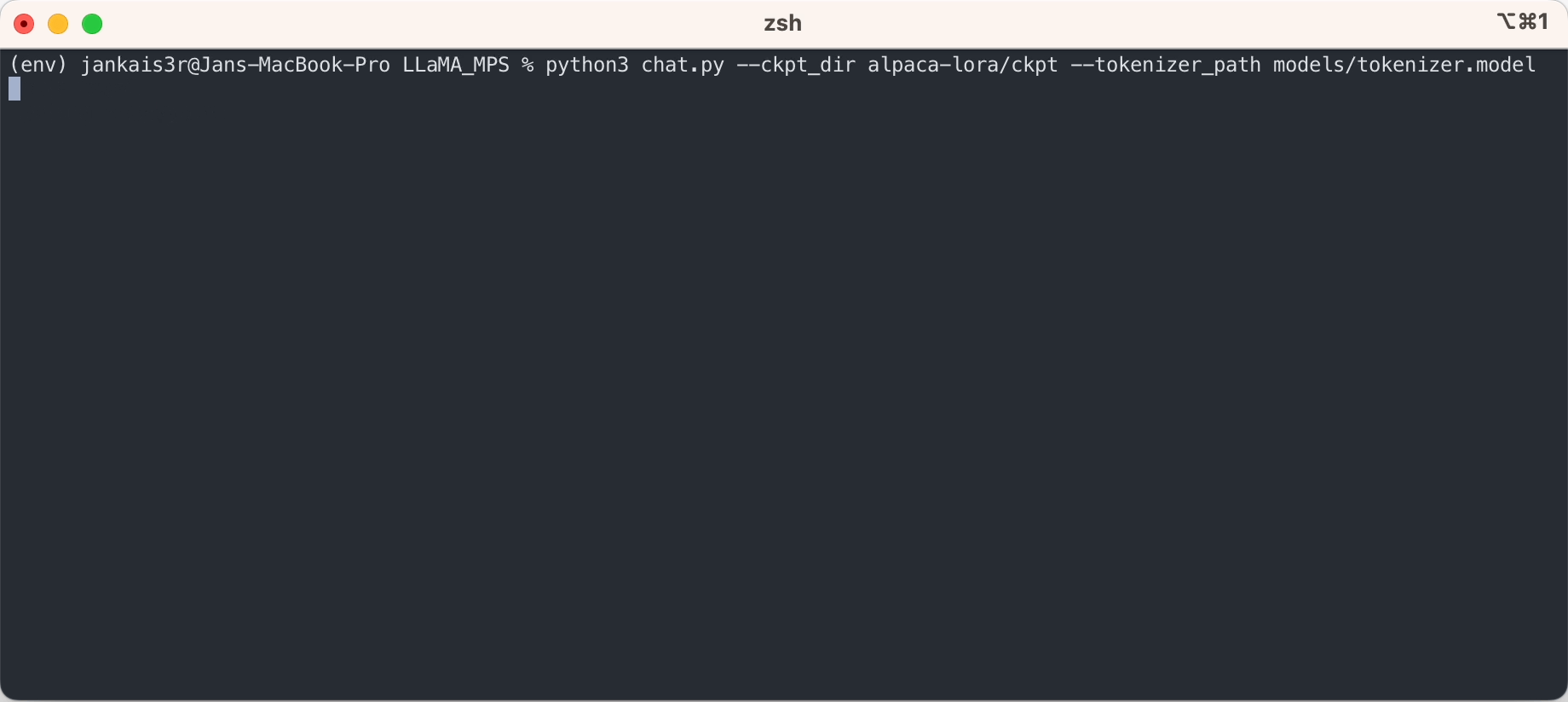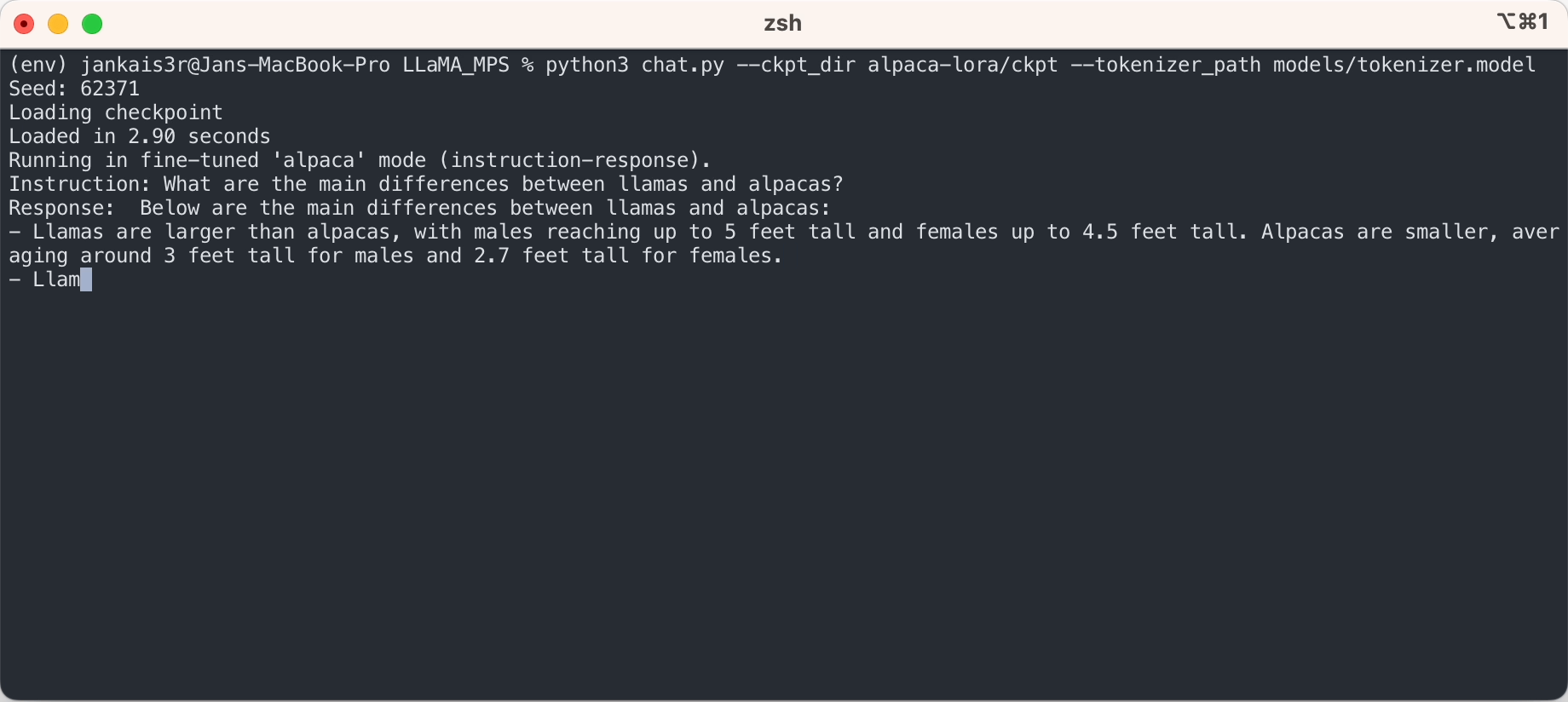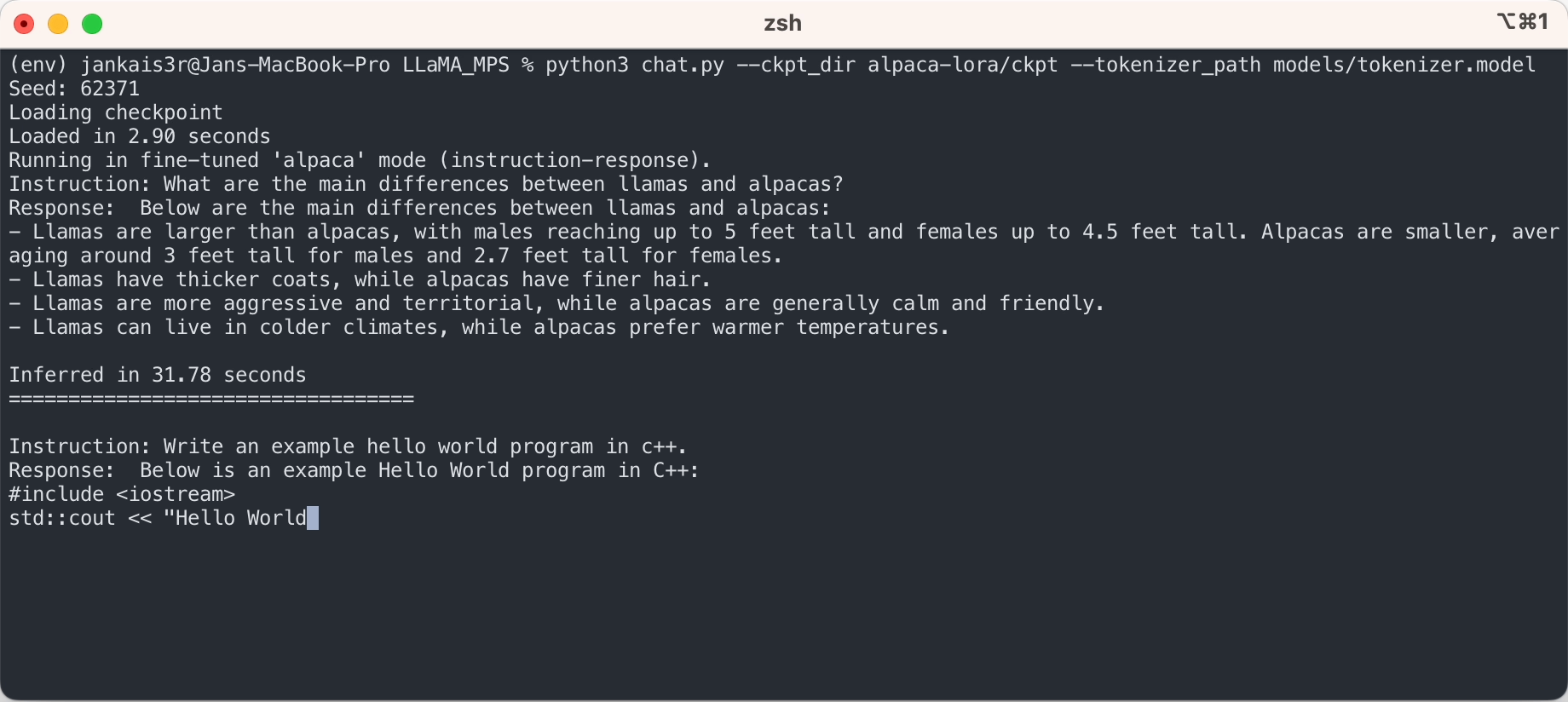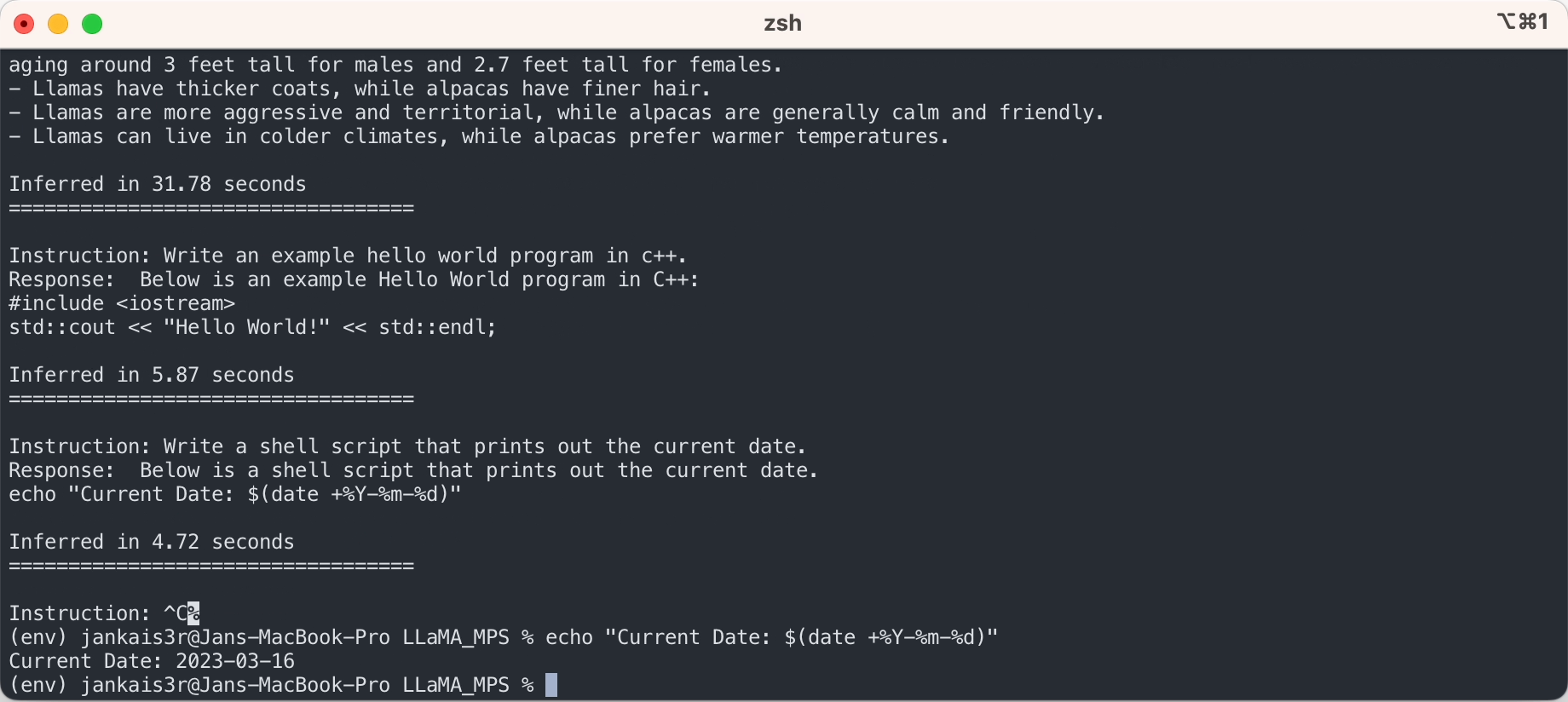
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
上述步骤将让您在“自动完成”模式下对原始 LLaMA 模型运行推理。
如果您想使用斯坦福羊驼的微调权重尝试类似于 ChatGPT 的“指令-响应”模式,请按照以下步骤继续设置:
3.下载微调后的权重(7B/13B可用)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. 运行推理
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| 模型 | 推理期间启动内存 | 检查点转换期间的峰值内存 | 重新分片期间的峰值内存 |
|---|---|---|---|
| 7B | 16 GB | 14GB | 不适用 |
| 13B | 32GB | 37GB | 45GB |
| 30B | 66GB | 76GB | 125GB |
| 65B | ??国标 | ??国标 | ??国标 |
每个型号的最低规格(由于交换而缓慢):
每个型号的推荐规格:
- 最大批量大小
如果您有空闲内存(例如,在 64 GB Mac 上运行 13B 模型时),您可以使用--max_batch_size=32参数来增加批处理大小。默认值为1 。
- 最大序列长度
要增加/减少生成文本的最大长度,请使用--max_seq_len=256参数。默认值为512 。
- 使用重复惩罚
该示例脚本对生成重复内容的模型进行惩罚。这应该会带来更高质量的输出,但会稍微减慢推理速度。使用--use_repetition_penalty=False参数运行脚本以禁用惩罚算法。
对于 Apple Silicon 用户来说,LLaMA_MPS 的最佳替代方案是 llama.cpp,它是一个 C/C++ 重新实现,纯粹在 SoC 的 CPU 部分上运行推理。由于编译后的 C 代码比 Python 快得多,因此它实际上可以在速度上击败 MPS 实现,但代价是功耗和热效率要差得多。
在决定哪种实现更适合您的用例时,请参阅以下比较。
| 执行 | 总运行时间 - 256 个令牌 | 令牌/秒 | 内存使用峰值 | 峰值 SoC 温度 | 峰值 SoC 功耗 | 每 1 Wh 代币 |
|---|---|---|---|---|---|---|
| LLAMA_MPS (13B fp16) | 75秒 | 3.41 | 30GB | 79℃ | 10瓦 | 1,228.80 |
| 骆驼.cpp (13B fp16) | 70年代 | 3.66 | 25GB | 106℃ | 35瓦 | 376.16 |


