inverted_index
1.0.0
搜索周围人说的短语可能很困难。这个数据集的动态更新怎么样?可扩展存储和低延迟?我这个项目的主要目标是构建一个满足这些要求并允许实时了解推文中存在的最新趋势的系统。
按照倒排索引的想法,我实现了一个应用程序,可以实时查找具有特定内容的推文,将它们存储在本地文件系统中,并允许在初始化客户端连接后立即进行基于单词的搜索。
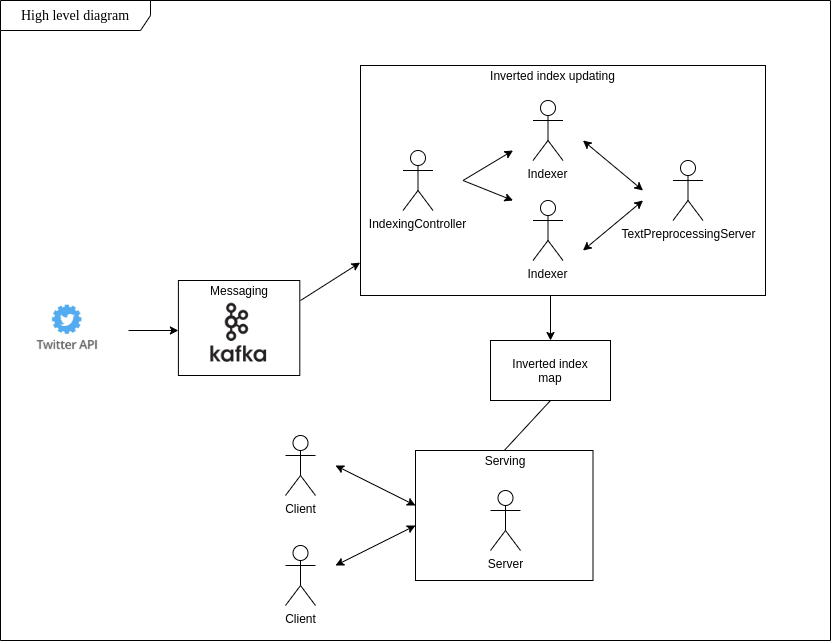
为了运行该应用程序,您需要:
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' 为客户端和服务器创建 Dockerfile:
./gradlew clean build createClientDockerfile createMainDockerfile
这将在根目录中生成 app_server.Dockerfile 和 app_client.Dockerfile。
开始申请:
docker-compose up
启动客户端会话:
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
开始输入感兴趣的单词。服务器将以“dataset_v2//tweet_N.txt”格式返回推文的位置。例如:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
请参阅未决问题以获取建议功能(和已知问题)的列表。
根据 MIT 许可证分发。请参阅LICENSE了解更多信息。


