cleanrl
v1.0.0 CleanRL Release ?
CleanRL 是一个深度强化学习库,提供高质量的单文件实现以及研究友好的功能。该实施干净简单,但我们可以使用 AWS Batch 对其进行扩展以运行数千个实验。 CleanRL 的突出特点是:
ppo_atari.py只有 340 行代码,但包含有关 PPO 如何与 Atari 游戏配合使用的所有实现细节,因此对于那些不想阅读整个模块化库的人来说,这是一个很好的参考实现。您可以在我们的 JMLR 论文和文档中阅读有关 CleanRL 的更多信息。
著名的 CleanRL 相关项目:
对 Gymnasium 的支持:Farama-Foundation/Gymnasium 是下一代
openai/gym,将继续维护并引入新功能。请参阅他们的公告了解更多详情。我们正在迁移到gymnasium,可以在 vwxyzjn/cleanrl#277 中跟踪进度。
️ 注意:CleanRL不是模块化库,因此不适合导入。以重复代码为代价,我们使 DRL 算法变体的所有实现细节都易于理解,因此 CleanRL 有其自身的优点和缺点。如果您想要 1) 了解算法变体的所有实现细节或 2) 其他模块化 DRL 库不支持的原型高级功能(CleanRL 的代码行数最少,因此它为您提供出色的调试体验,并且您不需要),则应考虑使用 CleanRL。不需要像有时在模块化 DRL 库中那样进行大量子类化)。
先决条件:
要在本地运行实验,请尝试以下操作:
git clone https://github.com/vwxyzjn/cleanrl.git && cd cleanrl
poetry install
# alternatively, you could use `poetry shell` and do
# `python run cleanrl/ppo.py`
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
# open another terminal and enter `cd cleanrl/cleanrl`
tensorboard --logdir runs要使用 wandb 进行实验跟踪,请运行
wandb login # only required for the first time
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
--track
--wandb-project-name cleanrltest如果您不使用poetry ,您可以使用requirements.txt安装CleanRL:
# core dependencies
pip install -r requirements/requirements.txt
# optional dependencies
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-mujoco.txt
pip install -r requirements/requirements-mujoco_py.txt
pip install -r requirements/requirements-procgen.txt
pip install -r requirements/requirements-envpool.txt
pip install -r requirements/requirements-pettingzoo.txt
pip install -r requirements/requirements-jax.txt
pip install -r requirements/requirements-docs.txt
pip install -r requirements/requirements-cloud.txt
pip install -r requirements/requirements-memory_gym.txt要在其他游戏中运行训练脚本:
poetry shell
# classic control
python cleanrl/dqn.py --env-id CartPole-v1
python cleanrl/ppo.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
# atari
poetry install -E atari
python cleanrl/dqn_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/sac_atari.py --env-id BreakoutNoFrameskip-v4
# NEW: 3-4x side-effects free speed up with envpool's atari (only available to linux)
poetry install -E envpool
python cleanrl/ppo_atari_envpool.py --env-id BreakoutNoFrameskip-v4
# Learn Pong-v5 in ~5-10 mins
# Side effects such as lower sample efficiency might occur
poetry run python ppo_atari_envpool.py --clip-coef=0.2 --num-envs=16 --num-minibatches=8 --num-steps=128 --update-epochs=3
# procgen
poetry install -E procgen
python cleanrl/ppo_procgen.py --env-id starpilot
python cleanrl/ppg_procgen.py --env-id starpilot
# ppo + lstm
poetry install -E atari
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
您还可以使用 Gitpod 中托管的预构建开发环境:
| 算法 | 实施的变体 |
|---|---|
| ✅ 近端策略梯度(PPO) | ppo.py ,文档 |
ppo_atari.py ,文档 | |
ppo_continuous_action.py ,文档 | |
ppo_atari_lstm.py ,文档 | |
ppo_atari_envpool.py ,文档 | |
ppo_atari_envpool_xla_jax.py ,文档 | |
ppo_atari_envpool_xla_jax_scan.py ,文档) | |
ppo_procgen.py ,文档 | |
ppo_atari_multigpu.py ,文档 | |
ppo_pettingzoo_ma_atari.py ,文档 | |
ppo_continuous_action_isaacgym.py ,文档 | |
ppo_trxl.py ,文档 | |
| ✅ 深度 Q 学习 (DQN) | dqn.py ,文档 |
dqn_atari.py ,文档 | |
dqn_jax.py ,文档 | |
dqn_atari_jax.py ,文档 | |
| ✅ 分类 DQN (C51) | c51.py ,文档 |
c51_atari.py ,文档 | |
c51_jax.py ,文档 | |
c51_atari_jax.py ,文档 | |
| ✅ 软演员评论家 (SAC) | sac_continuous_action.py ,文档 |
sac_atari.py ,文档 | |
| ✅ 深度确定性策略梯度(DDPG) | ddpg_continuous_action.py ,文档 |
ddpg_continuous_action_jax.py ,文档 | |
| ✅ 双延迟深度确定性策略梯度(TD3) | td3_continuous_action.py ,文档 |
td3_continuous_action_jax.py ,文档 | |
| ✅ 阶段性政策梯度(PPG) | ppg_procgen.py ,文档 |
| ✅ 随机网络蒸馏(RND) | ppo_rnd_envpool.py ,文档 |
| ✅ Q匕首 | qdagger_dqn_atari_impalacnn.py ,文档 |
qdagger_dqn_atari_jax_impalacnn.py ,文档 |
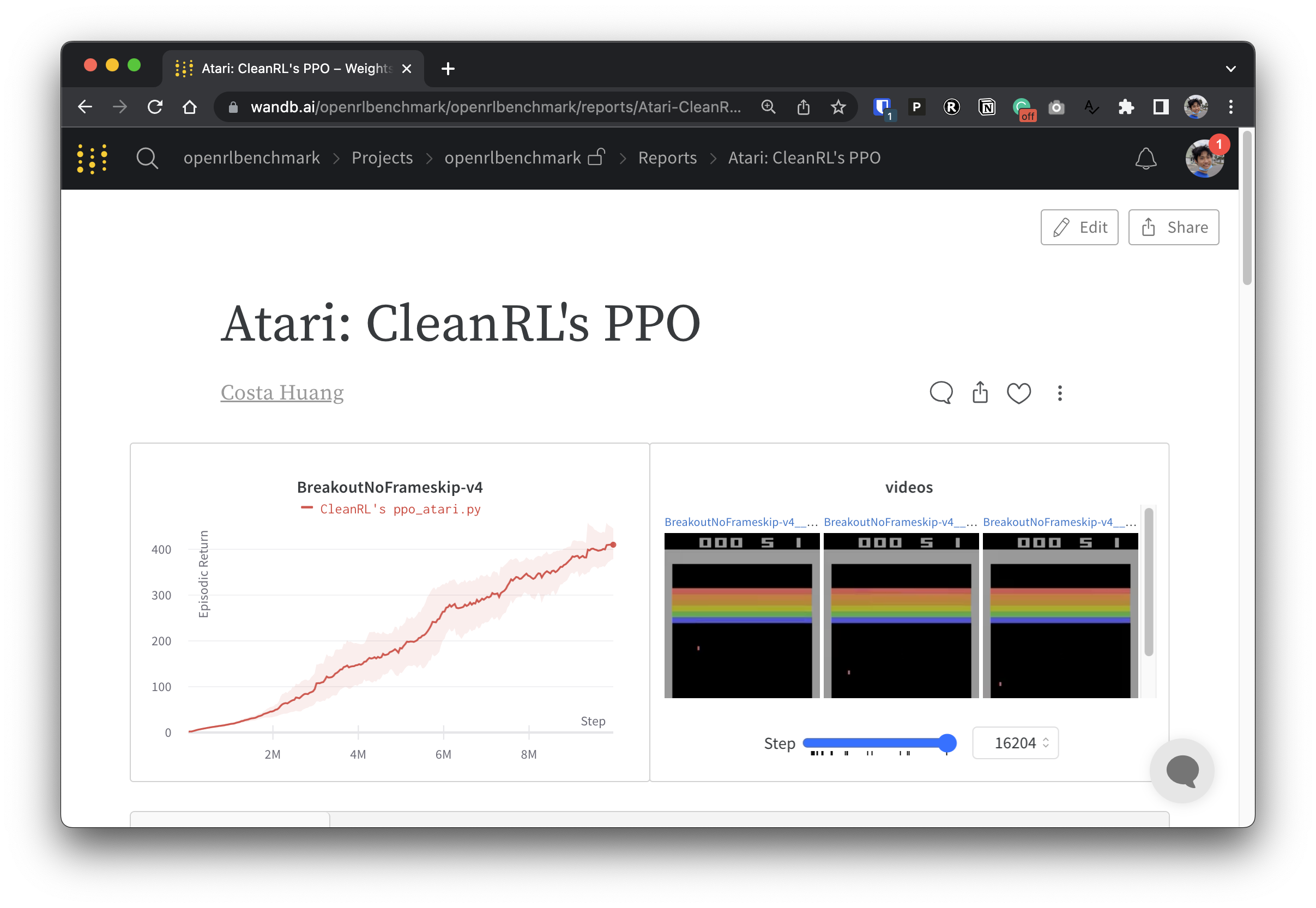
为了使我们的实验数据透明,CleanRL 参与了一个名为 Open RL Benchmark 的相关项目,其中包含来自流行 DRL 库(例如我们的、Stable-baselines3、openai/baselines、jaxrl 等)的跟踪实验。
查看 https://benchmark.cleanrl.dev/ 获取一系列权重和偏差报告,其中展示了跟踪的 DRL 实验。这些报告是交互式的,研究人员可以轻松查询 GPU 利用率和代理游戏视频等信息,这些信息通常很难在其他 RL 基准测试中获取。未来,Open RL Benchmark 可能会提供一个数据集 API,供研究人员轻松访问数据(请参阅存储库)。
我们有一个 Discord 社区来提供支持。欢迎提问。也欢迎在 Github 上发布问题和 PR。我们过去的视频记录也可以在 YouTube 上找到
如果您在工作中使用 CleanRL,请引用我们的技术论文:
@article { huang2022cleanrl ,
author = { Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo } ,
title = { CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms } ,
journal = { Journal of Machine Learning Research } ,
year = { 2022 } ,
volume = { 23 } ,
number = { 274 } ,
pages = { 1--18 } ,
url = { http://jmlr.org/papers/v23/21-1342.html }
}CleanRL 是一个由项目支持的社区,我们的贡献者在各种硬件上运行实验。


